Source material: HN UUID v4 Collision Thread, dev.to UUID Benchmark
AI-generated ratio: 99%
TL;DR#
UUID v4 collided — someone on HackerNews actually hit a real collision. The root cause was a software stack bug, not math. v4 and v7 have no fundamental difference in collision safety. The real difference is index performance: v7 is time-ordered, B-tree is more compact, writes are 35% faster, indexes are 22% smaller. Your UUID v4 is probably fine, but if you care about index performance, switching to v7 is a cheap win.
The UUID v4 Collision Incident#
A HackerNews thread blew up — Ask HN: We just had an actual UUID v4 collision…, 479 upvotes, 347 comments.
The OP’s own words:
I know what you’re thinking… and I still can’t believe it, but… This morning, our database flagged a duplicate UUID (v4).
It wasn’t a double-insert bug. The code didn’t write it twice. Only ~15,000 rows in the table, using npm’s uuid package uuidv4(), and two rows created at different times collided on the same UUID:
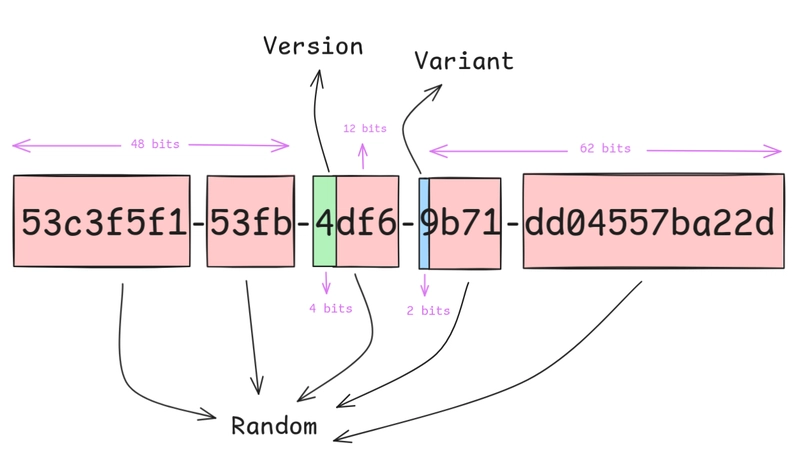
b6133fd6-70fe-4fe3-bed6-8ca8fc9386cdWhat’s the probability of a UUID v4 collision? 122 random bits, 2^122 ≈ 5.3×10^36 possibilities. With 15,000 records, collision probability is roughly 2×10^-29. Theoretically “impossible.”
But it happened.
Cause 1: Unreliable entropy sources#
HN’s top-voted comment (jandrewrogers):
UUIDv4 security depends on high-quality entropy sources. Hardware defects, software bugs, and misunderstandings of “high-quality entropy” all break this assumption. Detecting entropy source failures is expensive, so nobody checks — until a collision happens.
UUID v4 is explicitly banned in high-reliability systems because entropy source quality cannot be verified.
Cause 2: Known npm uuid package bugs#
The npm uuid package README itself warns:
This module may generate duplicate UUIDs when run in clients with deterministic random number generators, such as Googlebot crawlers.
More seriously, its internal rng() function has global mutable state. One commenter pointed out: calling rng() and sending the result effectively overwrites someone else’s random number, and you can predict it.
Related commit: 91805f665c
Community advice: use Node.js built-in crypto.randomUUID(), not the npm uuid package.
Cause 3: Linux kernel /dev/random race condition#
Another comment:
I encountered duplicate UUIDs during soak testing of a distributed system. After extensive debugging, I found it was a Linux kernel race condition bug — on multi-processor systems, two processes simultaneously reading /dev/random could, with extremely low probability (~one in a million), get the same bytes.
Cause 4: Go UUID library not checking return values#
Early Go UUID libraries called random functions without checking the return value length. “Request N bytes, got 3 bytes back” never happened on most hardware, so nobody checked — until production, where it generated thousands of duplicate UUIDs.
Cause 5: Historical AMD CPU RNG defects#
Certain AMD CPUs had built-in random number generator issues. VM environments can also “virtualize away” entropy — both time sources and entropy sources can degrade inside VMs.
v4 and v7 have no fundamental difference in collision safety. The difference is in the first 48 bits — v4 is random, v7 is a timestamp. You’re unlikely to encounter timestamp source issues, and random source issues are equally rare. The HN thread is an interesting edge case. Knowing that a tiny number of people hit it is enough — you don’t need to distrust the UUID v4 in your own systems.
When choosing v4 vs v7, what you should really look at isn’t collisions — it’s index performance.
UUID v7 Performance Comparison in PG 16#
UUID v7 has one concrete advantage over v4 in PostgreSQL: temporal clustering, more B-tree-friendly. v4 can bloat and v7 can bloat too — the difference is simply that v7’s first 48 bits are time-ordered, so inserts concentrate on the right side of the B-tree, reducing page splits.
Umang Sinha’s benchmark ran a rigorous comparison on a PG 16 Docker container (8 cores, 16GB, NVMe).
Test Conditions#
CREATE TABLE uuid_v4_test (id UUID PRIMARY KEY, payload TEXT);
CREATE TABLE uuid_v7_test (id UUID PRIMARY KEY, payload TEXT);| Parameter | Value |
|---|---|
| Data volume | 10 million rows per table |
| Batch size | 10,000 rows per batch |
| Client | Go + pq driver |
| UUID generation | Pre-generated in memory, not timed |
Performance Results#
| Metric | UUID v4 | UUID v7 | Improvement |
|---|---|---|---|
| Write 10M rows | 5 min 35 sec | 3 min 38 sec | 35% faster |
| Table + index total size | 3618 MB | 3443 MB | 5% smaller |
| B-tree index size | 776 MB | 602 MB | 22% smaller |
| Point lookup | 0.167 ms | 0.038 ms | 4.4x faster |
| Range scan | 8.283 ms | 3.791 ms | 2.2x faster |
Why Such a Big Difference#
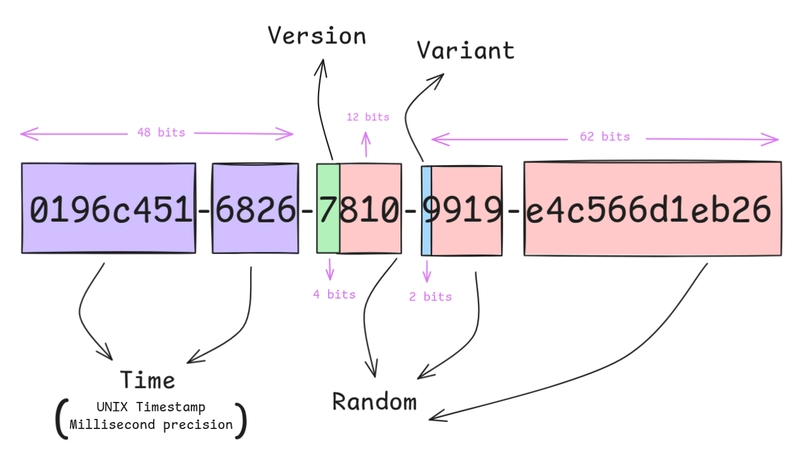
UUID v4 is fully random. Newly inserted UUIDs scatter randomly across the B-tree index, causing massive page splits and severe index fragmentation. UUID v7 has a millisecond-precision timestamp in the first 48 bits, so newly generated UUIDs are naturally ordered — writes cluster on the right side of the B-tree, page splits drop dramatically, and the index is much more compact.
The 22% smaller index isn’t magic — it’s reduced fragmentation. Point lookups being 4x faster isn’t surprising either — fewer B-tree levels, higher cache hit rates.
Summary#
UUID v4 and v7 are identical in collision safety — both depend on entropy source quality, one fills the first 48 bits with random numbers, the other with a timestamp. Collisions are edge cases that a tiny number of people hit in specific environments. Your environment is probably fine — that basic judgment doesn’t change.
What you really should think about is index performance. v7’s temporal property makes B-trees more compact, with measured results of 35% faster writes, 22% smaller indexes, and 2-4x faster queries. If your system writes UUIDs at high volume, switching to v7 saves meaningful storage and CPU.
PG 18 will natively support gen_uuid_v7(). For now, generate UUIDs at the application layer. Whichever version you use, always add a UNIQUE constraint.
This article was originally published in Chinese on lastdba.com.