AI rate: This article has approximately 60% AI involvement, with about 20 rounds of battling with AI
Recommendation reason: Contains some reflections and insights on AI Ops, hence recommended
Writing in the AI Era#
For authors who write blogs or WeChat public accounts, AI may be a fatal blow, because AI writing is simply too easy. As someone who writes articles myself, I have many internal struggles about how AI affects writing habits, and it pains me too. Let me revisit some earlier thoughts on writing:
Why write?
- For myself: To consolidate knowledge. Output is what strengthens input. Glancing at something once versus writing it out are completely different experiences — writing can take several times longer than just reading. For example, when you see a profound and seemingly familiar sentence, rewriting it yourself reveals countless details within it.
- For myself: To leverage others’ biases constructively. Mainly to use readers’ expectations as motivation to persist in writing and to enhance the credibility of content. Knowledge you consume yourself may be “good enough,” but writing for a public audience forces you to weigh every word and take responsibility for others. (Relatively speaking — not actual word-by-word scrutiny.)
- For myself: To build reputation. This depends heavily on writing quality.
- For others/the community: To spread knowledge. Good things should be shared and used by everyone — this is at the core of the PostgreSQL open-source community. Encouraging sharing, not hoarding, is a principle I’ve always upheld.
- Building connections: This wasn’t my goal, but I have indeed met some friends through it.
Human writing was already difficult; in the AI era, human writing is essentially Hell Mode — like walking against the current without a destination, unable to see any light, while everyone else is heading the opposite direction. I’ve certainly experienced AI-powered interpretation, translation, and article generation, but it never feels like mine, or it loses the original purpose of training myself. Or, at a deeper level, I want to feel the vitality of the work.
The DBA community’s articles can be described as a mixed bag — people write about everything. I’ve always preferred substantive, content-rich articles focused on PostgreSQL internals and operations, like those by Cancan and Xiangbo — I eagerly anticipate every piece and read them carefully. Generally, content-oriented articles don’t get much traffic (both Cancan and Xiangbo have complained about this on their public accounts…), and I’m quite easygoing about it myself.
However, my previous article “PG Operations Database Operations Experience 2025” gained a surprising number of followers, which truly astonished me. So I’ve been pondering this question for days: Why would a non-AI-written, non-comprehensive, DBA-focused, knowledge-oriented article attract so much interest? What does AI mean for DBAs?
Reflections on Operations#
The Essence of Operations and AI Ops#
Operations involve many things. To narrow the scope of discussion, I’ll focus on just one small part of operations work — incident response — to interpret the essence of DB Ops. First, my position: “Operations is not merely a technical problem.”
Many people argue that since both humans and AI make mistakes, AI can be given authority to act boldly — specifically, if AI’s error rate ≤ human error rate, replacement is justified. I thought the same two years ago, but I no longer do. Because the real-world environment is far more complex, with at least the following factors to consider:
- The consensus problem. There is consensus that a DBA might accidentally delete data, but another consensus is easily overlooked: in normal circumstances, the team assumes the DBA won’t delete data. How to understand this? For example, when hiring a DBA, a responsible team will assess whether the person is mentally stable, then default to assuming they won’t delete data, and maintain this assumption throughout long-term work. At the very least, I don’t constantly worry that my colleague will drop the database. But when “hiring” an AI DBA, it has no mental state, and no one assumes it won’t delete data. “It will delete data” is everyone’s consensus, creating deployment resistance.
- The importance of data. C-end (consumer) data and B-end (business) data have different importance levels. Retail, internet, government, and financial industry data also differ in criticality. The more an industry values data, the more sensitive it is to data reliability and business continuity. A personal computer has no business continuity and only one person cares about data reliability, but in the financial industry, business continuity can directly trigger widespread social concern — financial data reliability simply cannot be questionable. AI Ops deployment must consider system criticality; it cannot be rolled out across all domains simultaneously.
- The management system. For example, in financial systems, DBAs hold high privileges and are governed by a set of management procedures. So shouldn’t an AI DBA also have corresponding management procedures before it can be deployed? What about abnormal login detection, or abnormal backend access? How does it request permissions, and for how long? What level of permission in what scenario? These are all unresolved issues.
- AI’s own security. For instance, the paper STRATUS mentions prompt injection attacks, for which there is currently no effective solution. If someone injects a “drop database” prompt, it might just execute it. But humans basically don’t have this problem — if you tell a DBA “drop database,” they’ll just ask you what you’re trying to do.
- The responsibility problem. Operations engineering is not a “knowledge problem” but a “responsibility problem.” One of the core tasks of operations is to make irreversible decisions about the system within limited time during an incident, and take responsibility for those actions. AI can replace “formalizable operations” but cannot replace “judgments that must bear consequences” — at least not yet.
- Full of noise. Operations is an “open system,” not a closed reasoning system. Databases run in extremely complex environments, while AI’s reasoning premise is that the world can be described in text. But the real operations world is filled with noise, contingency, and undocumented behaviors.
- Situational pressure. Real business environments include recovery time pressure, organizational and customer emotional management, etc. The book Google SRE describes a common recovery scenario: customers asking when it will be restored, leadership asking why failover hasn’t happened, engineers gathering various information under pressure while calling people to confirm recovery procedures. AI cannot feel this pressure. The first two questions are fundamentally not technical problems, but they must be answered. In real scenarios, the answers at that moment are likely to be rough at best.
Let’s imagine what conditions would be needed for fully automated AI operations to truly happen:
- AI won’t destroy critical data — at least, the vast majority of people need to reach this consensus about AI.
- Complete management procedures are needed, including how to grant AI permissions, just like how we grant DBA permissions.
- Solve the problem of AI itself being attacked. Not just LLMs, but the entire IT system encompassing AI.
- A no-blame operations culture (or eliminating operations altogether is another approach).
- Accept erroneous judgments. Form consensus around the existence of noise and environment, and tolerate AI Ops iteration cycles.
- If recovery takes too long or the blast radius expands, don’t allow human intervention — because if human intervention is required, that person is still the operator (semi-automated AI Ops?).
- Pressure-free recovery context. This means leaders, customers, and public opinion don’t need responses, or they trust some AI’s response. This is a human transformation, not an IT system transformation.
AIOps and Agent Research Results#
The Tsinghua AIDB repository’s directory contains many AI4DB papers — too many for a person to read. I used NotebookLM to summarize the paper categories:
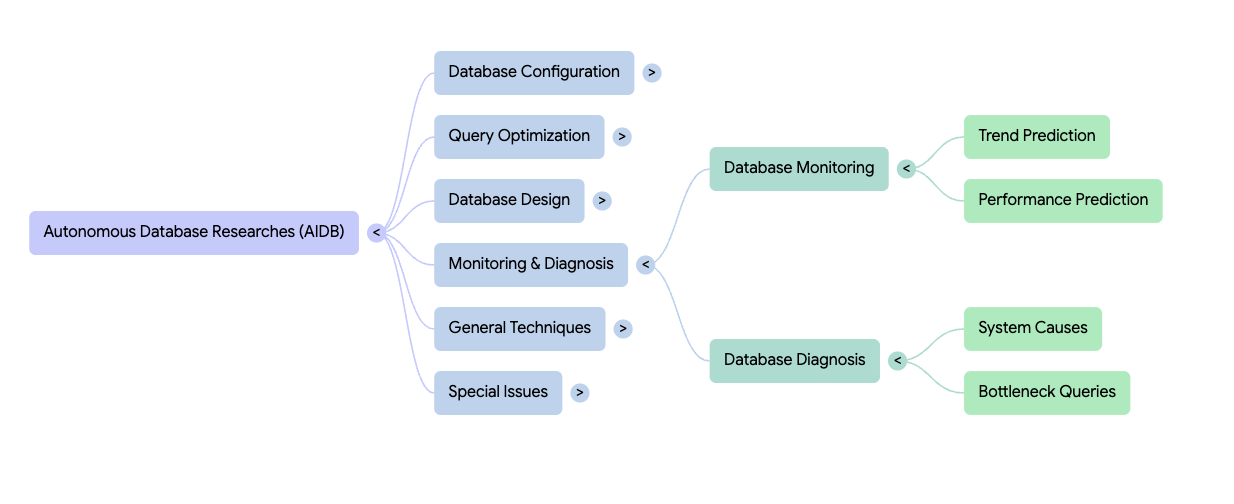
Again, to narrow the scope (mainly to reduce my own effort), let’s focus on database diagnostics content.
AIOps has made decent academic progress. AIOps research integrates machine learning, reinforcement learning, and large language models into database management, covering key tasks such as parameter tuning, index recommendations, query optimization, and fault diagnosis. The goal is to build “self-driving” database systems with self-awareness and self-healing capabilities. While significantly improving complex workload performance and operational efficiency, this also drives the DBA’s transformation from low-efficiency manual intervention to high-level architectural supervision.
Regarding whether “DBAs will be eliminated,” current research trends and industry practices (especially self-driving databases and LLM applications) show that the DBA role is undergoing a profound transformation from “manual operator” to “senior manager/supervisor,” rather than simple replacement. The DBA’s core value will shift toward managing AI operations strategies, ensuring data security and compliance, and handling extreme anomaly scenarios that AI cannot resolve.
Another AI Ops Frontier Survey article describes Agents this way:
“This shows that AI Agents are not a silver bullet. To apply Agents, we need not only progress at the model and agent level, but also sufficient support capabilities from the entire operational system — such as Kubernetes-like declarative interfaces, good observability, and reversible operation design. Stratus’s preliminary experiments demonstrate the potential of Agents in automated operations, but there remain enormous gaps in performance, reliability, and security before production deployment.”
The development domain, fueled by the booming vibe coding movement, is clearly advancing much faster than AI in operations. I’d also love to have a confirm/redo operations remote control — the problem is, it doesn’t exist yet. Even if we fantasize about “vibe maintaining” one day, I doubt many ops people would turn on yolo mode.
The Value of a DBA#
Is a DBA’s Value Just Being the Decision-Maker and Scapegoat?#
Endorsement indeed seems to be something AI cannot solve. So is the DBA’s value just being the decision-maker and scapegoat? After all, a DBA’s knowledge is far less than AI’s — it’s just that AI can’t make the final call.
1. Instantaneous Context
“The DBA’s knowledge is far less than AI’s” — this is true for general knowledge (like how to optimize a SQL query, or the meaning of a configuration parameter). But AI lacks instantaneous runtime context. AI knows database principles, but it doesn’t know the accumulated historical debt hiding behind the load balancer during the sudden traffic spike of your company’s Double Eleven (Singles’ Day). The DBA possesses unstructured experience about “this specific machine, this specific business, these specific people.” In the face of extreme failures, AI offers the “highest-probability suggestion,” while the DBA offers “the operation that best preserves the system’s life under this specific pressure.”
2. The Last Gate of a Chaotic System
The database is the most fragile and least fault-tolerant part of all IT architectures (code can be rolled back, but data loss can bankrupt a company). AI’s logic is extrapolation based on historical data. When encountering unprecedented underlying hardware bad sectors, extremely rare distributed deadlocks, or novel hacker attack methods, AI’s “suggestions” often fail or even cause secondary damage. The core of “making the call” is not “which solution to choose,” but “hedging against risk.” This kind of control over extreme situations is something current AI cannot provide.
3. Chain of Trust
The DBA is the maintainer of the chain of trust: for example, if you let AI audit AI, then who audits the AI’s audit logic? At the levels of data security, compliance, and ethics, there must be a human with the highest privileges who can be held accountable as the endpoint of the trust chain.
Let’s flip the perspective: if DBAs really were just “less knowledgeable decision-makers and scapegoats,” then enterprises would have long ago transferred DBA decision-making authority to SREs, architecture committees, or even AI and other responsible entities. But the reality is, at truly critical moments, enterprises still call “that person.” This shows the question was never “who is smarter,” but who can bear the consequences for the organization amid uncertainty. The DBA is the last human in this chaotic database system who holds the authority to stop losses, the responsibility, and the terminal point of trust.
So is every decision made by the DBA? Obviously not. The DBA does not hold “objective decision-making authority” but rather “risk veto power” — they cannot decide whether the business should take risks, but they can determine which risks the system cannot bear. In simple, low-risk, rollback-able scenarios, decisions are often made automatically by processes or systems; only when decisions enter high-risk, irreversible territory where responsibility must converge is the DBA pushed to the forefront.
The Uniqueness of the Postgres DBA#
For the specific group of Postgres (PG) DBAs, this uniqueness is even more pronounced.
In modern technical organizations, DBAs do not naturally hold architectural decision-making authority, nor do they monopolize index or parameter formulation. Architects can design solutions, developers can write SQL, and AI can even provide seemingly comprehensive best-practice recommendations. But these decisions mostly occur at the abstraction layer, design layer, and probability layer — they assume the system is rollback-able, replay-able, and correctable.
Postgres’s uniqueness lies in the fact that it hands a great deal of freedom to its users, and these freedoms ultimately translate into long-term side effects in real systems: write amplification, I/O pattern changes, Vacuum imbalance, WAL bloat, and unpredictable performance degradation. These side effects cannot be fully rehearsed at the design stage, cannot be subcontracted to a single role, and cannot simply be “withdrawn” after an incident occurs. When the system enters an unstoppable, unreplayable state, the only person still responsible for the overall outcome is often the DBA.
Therefore, the value of a Postgres DBA lies not in “making decisions for others” (though you certainly can), but in continuously managing the real-world consequences of all decisions after they have already been made. “Architects define the ideal, developers implement functionality, AI predicts the future; and the DBA guards reality.”
This ability to guard reality is based on the PG DBA having sufficient understanding of Postgres, sufficient understanding of the system’s real environment, sufficient understanding of the system’s history, and sufficient immediate context. In the AI era, one more thing needs to be added: sufficient understanding of AI.
Why Keep Learning#
In the past two years, I’ve heard “learning is useless” rhetoric more than ever before. I generally scoff at such talk. Let me take this opportunity to properly address it.
Does foundational database knowledge still have value? The answer is: its value is higher than ever. Let’s interpret this from three angles: the right to explain, active learning, and why I keep revisiting the classics.
1. The Right to Explain
Foundational knowledge enables three things:
- Identifying “systemic inevitable failure points” in advance
- Clearly articulating the judgment logic
- Transforming “I’m going with my gut” into “this is the system-determined outcome”
The true meaning of learning database fundamentals is not to “do more work,” but to:
- Delineate responsibility boundaries
- Enhance discourse power
- Let the system endorse your judgments
2. Active Learning Becomes an Even Rarer Ability
In the AI era, the “technical barrier” to knowledge acquisition approaches zero. Active learning ability is scarce. Why is “active learning” even rarer in the AI era? This is counter-intuitive but very real. AI makes “passive learning” extremely comfortable — ask and answer anytime, no long-term investment required, no need to endure cognitive discomfort. But the result is that more and more people stay in the “instant gratification layer,” unwilling to learn foundational knowledge anymore. When everyone else is regressing, you find yourself advancing faster.
3. Why Do I Keep Re-reading Classics like The Internals of PostgreSQL?
Technical people need to read books because books don’t just give answers — they help build a cognitive model that can be run repeatedly and continuously refined. AI is currently better at answering questions rather than shaping such models. AI struggles to become this kind of “long-term dialogue partner” — its answers are unstable.
From another perspective, looking at the value of books through cognitive economics + information theory + token cost: First, you don’t need to battle with AI back and forth. The real cost of battling is not money, but your attention and context-maintenance ability. Second, the hundreds of thousands of words in a book require neither massive prompt input nor excessive token expenditure from you. Third, the knowledge in books has been repeatedly verified by authors and readers — it is already compressed knowledge, the easiest to learn. So: Classic books = extremely low token cost to obtain high-density, human-repeatedly-verified, focused knowledge in compressed form.
4. Learning AI Itself
This needs no elaboration from me.
My battles with AI led me to an interesting conclusion about “why read books”:
In the AI era, knowledge is cheap, but judgment is expensive => And judgment comes from a stable, calibratable cognitive model => A stable cognitive model is itself a byproduct of “long-term high-quality knowledge intake.”
Another real-world piece of evidence supporting the “reading is useful” argument: this very article depends on books, papers, other articles, and information I’ve read. Without that foundation, this article would not exist.
Why People Still Love Reading “Human-Written” Articles#
The Psychology of Preferring Imperfection#
Human-written technical articles are inevitably riddled with flaws. Looking back at my own “Operations Experience 2024” from last year, I can find many holes. Even “Operations Experience 2025,” completed just days ago, I consider incomplete — vastly different from something AI would write. So why do readers still enjoy such flawed technical articles?
The reason may be that humans are not attracted by “information correctness,” but by “empathetically imperfect traces of a human mind.” From the book A Brief History of Intelligence, we know that the human intelligence model inherently includes self-trial-and-error exploration and observing others’ behaviors to map onto oneself — this is a learning process, innate to humans. Our brains automatically scan text for hesitation, uncertainty, logical gaps, awkward expressions, emotional leakage, etc. — all things systematically absent from AI text. In the imperfections and emotions of writing, readers can feel the author’s thinking and emotions, whereas AI merely presents results. Readers almost never have emotional resonance with AI. Generally speaking, only those who have truly experienced something leave these “unattractive” traces.
So I believe many people, like me, can identify purely AI-written technical articles at a glance (not guaranteed 100% accurate) and generally won’t have the emotional drive to read through them. But if it’s something a human has seriously written, they’ll read carefully, feeling the author’s feelings, catching their shortcomings or contextual gaps.
Of course, authors could feed prompts to mimic their previous writing style or deliberately leave flaws. But I haven’t seriously tried this — I briefly generated a few pieces and felt the emotional immersion was still quite poor. I don’t plan to explore this further; there’s not much point.
Borrowing an Expert’s ATTENTION for Free#
The core difference between AI articles and expert articles is not “how well they’re written,” but a matter of economic questioning and industry-leading Attention. Expert writing is about allocating attention on behalf of the reader; AI writing is about avoiding missing any potentially relevant information. This is not a capability issue — it’s a difference in objective functions. Truly high-value technical articles don’t tell you all the correct answers — they block 80% of what you shouldn’t be paying attention to right now.
Why do experts dare to “delete,” while AI doesn’t? Because they bear cognitive responsibility for your understanding outcomes. AI does not bear the consequences of you learning or applying things wrong. So experts deliberately filter out details that don’t need attention right now. This filtering is itself the value of expertise. For humans, the bottleneck in learning is not insufficient information, but limited attention and not knowing where to look first. An expert’s article directly hands you the result and says: just focus on this. But when facing an LLM, do you know what to look for?
This is not a denial of the value of AI articles. AI excels at “rapidly expanding the information space when you already know the problem boundaries,” while expert articles excel at “contracting the problem space for you before you’ve established a judgment framework.” The former is good for filling gaps and lateral expansion; the latter is good for building core understanding and key intuition. The truly efficient learning approach is not choosing one over the other, but first using experts to achieve Attention alignment, then using AI to do amplified search within the bounded space.
This isn’t saying AI content is useless or human-written content is useless — it’s that each has its own use.
Can AGI Solve All Problems?#
Refuting Musk#
Recently Musk has been painting big pictures again. After reading, I don’t agree.
1. Shared Prosperity or the Useless Class?
The “useless class” is a concept from Yuval Noah Harari’s Homo Deus. He argues that when AI’s productivity surpasses that of ordinary people, using AI to do work will replace having ordinary people do it. These people become the useless class. Resources will increasingly concentrate in the hands of a few elites and large corporations, and most people will lose their jobs — yet there is currently no effective policy to provide a safety net. This view happens to contradict the Musk-style shared prosperity vision. Musk believes that when AGI is realized, no one will need to worry about survival, education, or healthcare — productivity will be so high that governments will provide a safety net for most people. I currently support Harari’s view. In fact, from anecdotal perceptual statistics around us, the population of the useless class is indeed rising.
2. Can High Productivity Create a Utopia?
One theory supporting my disagreement with the AGI utopia comes from another book, Evolutionary Psychology — Mate Selection Criteria. One particularly striking insight: Due to social division of labor and the biological drive to raise well-adapted offspring, men tend to prefer young, healthy women, while women tend to prefer healthy, resourceful men. This default filtering engraved in our genes means that humans cannot live equally — you don’t want to be the one eliminated. So if a non-comparing, non-competitive, resource-equal utopia could be sustained, productivity is merely one necessary condition among many — there are many other social problems that must be solved, which the public tends to overlook. This isn’t narrowly referring only to evolutionary psychology; some things haven’t been carefully discussed, such as the power struggles in Chimpanzee Politics, which should also be considered.
3. Calhoun’s Mouse Utopia Experiment
In 1972, animal behaviorist John B. Calhoun designed and described in detail a famous experimental environment — “Universe 25.” This was a laboratory “utopia” specially crafted for mice, striving for perfection in almost every aspect: abundant food, water, and nesting materials; regularly cleaned living environment; no predator threats; temperature maintained between 20°C and 31°C via fans and heating, stable and comfortable.
The mouse population’s march toward extinction seems somewhat insane. I’ll focus only on the process: 1) Increased violence 2) No longer pursuing the opposite sex 3) Increased homosexual behavior 4) Increased solitary behavior 5) Males grooming themselves excessively 6) Apathy, etc. Of course, this experiment has flaws. From the intelligence model described in A Brief History of Intelligence, the intelligence gap between mice and humans still spans a primate — it cannot represent human society. But at minimum, it shows that utopia triggers new social problems; people won’t just quietly live their lives.
4. An Economics-Based Society
From the perspective of modern economics, whether AGI can achieve a “shared-prosperity utopia” can be divided into two types: retaining the modern economy or not retaining it.
If we retain the modern economy, AGI can be viewed as an extremely efficient “universal factor of production.” It significantly reduces the costs of knowledge production, decision support, organizational coordination, and marginal labor, raising the ceiling of society-wide productivity. Under this premise, wealth distribution, public service provision, and social security mechanisms still rely on markets, price signals, incentive structures, and institutional constraints. AGI’s role is more about expanding the size of the “distributable pie” rather than automatically solving distribution problems. In other words, shared prosperity remains a political economy problem, not a technical one. AGI can only lower the cost of achieving goals; it cannot replace institutional design.
So, if we don’t retain the modern economy and instead try to bypass markets, prices, and incentive systems to directly rely on AGI to achieve some kind of “techno-utopia” — is it feasible?
The answer can almost certainly be determined as: no.
A utopia without a modern economy was repeatedly verified as a failure in the 1960s–70s. The fundamental reason was not that “technology wasn’t advanced enough” at the time, but that the problems of information and incentives were structurally unsolvable: Even with powerful centralized computing capability, you cannot replace the preference information transmitted by dispersed individuals through price mechanisms, nor can you sustain innovation drive, responsibility constraints, and resource allocation efficiency over the long term. AGI can improve the computational capacity of centralized decision-making, but it cannot eliminate the fundamental economic question of “who is responsible for decisions, who bears consequences, who holds the right to choose.”
Therefore, AGI is not a replacement for the modern economy, but an amplifier within the modern economy’s framework. Any “techno-utopia” that detaches from market mechanisms, incentive structures, and institutional constraints, whether AGI is introduced or not, will essentially replay the historical path of failure — just in more subtle forms and at higher cost.
Productivity (including the intellectual enhancement brought by AGI) is only one of the conditions required for utopia, and far from the most critical one. Utopia is not a computing power problem, nor an intelligence problem — it is a problem of the stability of human behavior under institutional constraints.
The Mathematical Foundation for Why AI Cannot Solve Everything#
The following is excerpted from Wu Jun’s The Beauty of Mathematics:
“In 1900, Hilbert posed many problems, one of which was: ‘Can any (polynomial) Diophantine equation be determined, through a finite number of operations, to have integer solutions or not?’ If the universal answer to Hilbert’s question is negative, then it means that for many mathematical problems, even God doesn’t know whether an answer exists — because the Diophantine equation solving problem is only a very small part of all mathematical problems. For problems whose very answer-existence cannot be determined, the answer naturally cannot be found. It was precisely Hilbert’s contemplation of the boundaries of mathematical problems that made Turing understand the limits of computation… Matiyasevich rigorously proved that, except for a very small number of special cases, in general, it is impossible to determine through finite operations whether a Diophantine equation has integer solutions. The resolution of this problem had a far greater impact on human cognition than its mathematical influence… If even the solution’s existence is unknown, it’s even more impossible to solve them through computation.”
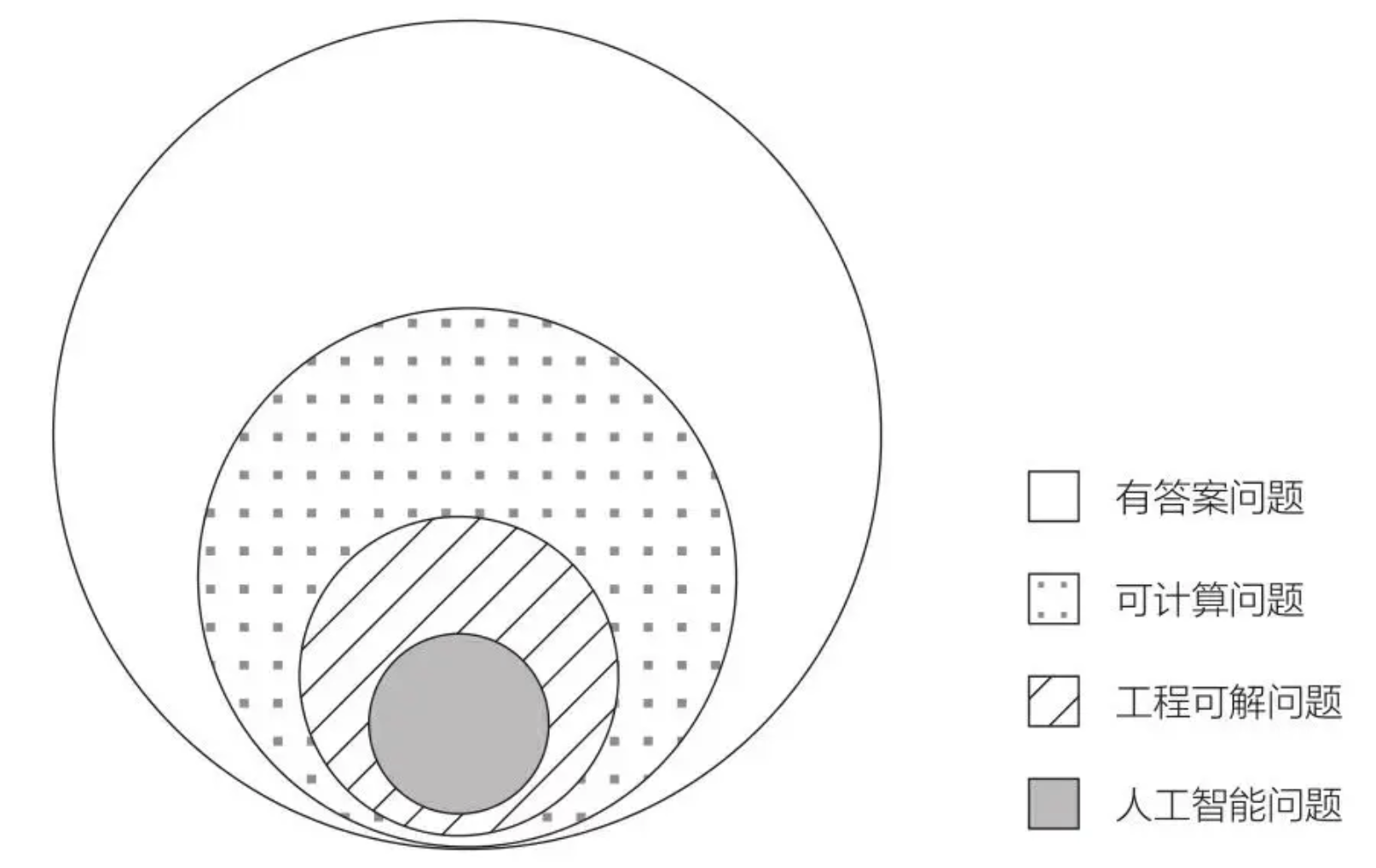
“A rational-state Turing machine can only solve a subset of problems that have answers… Many engineering problems are not artificial intelligence problems… Today, what we should worry about is not how powerful artificial intelligence or computers are, much less should we think they are omnipotent, because their boundaries have already been clearly delineated by the boundaries of mathematics… There are still many problems in the world that need to be solved by humans. How to make good use of AI tools to more effectively solve human problems is what deserves more attention.”
(See? Reading is useful, right? It explains it clearly to you directly — you probably couldn’t ask the right question or get such an accessible answer. See? Following hardcore tech content creators is useful — I filtered it for you. Hit that follow button ⭐)
Conclusion#
As a technical blogger, I rarely write about such social issues. I originally just wanted to briefly write about why my previous article got traffic, but explaining this phenomenon somewhat expanded the scope of the problem 😓.
Limitations of this article:
- Only discussed a very small part of DBA work — incident recovery — without discussing the intelligentization of other tasks.
- GPT knows me too well and seems to be flattering me. It indeed makes very valid points, but I cannot endorse what it says. This is somewhat circular: AI helps me confirm that AI cannot endorse things — an output that inherently cannot be endorsed. From my own perspective, its reasoning is indeed good, with quotable lines throughout.
Some Ops scenarios are certainly easy to AI-ify. But through the discussion in this article, AI-ifying the incident recovery domain still faces considerable difficulty. I have never given up on using AI, nor have I ever given up on using the human brain. I simply enjoy identifying in which scenarios AI works well, in which it works poorly, and in which it cannot be used at all. This may give the article a tone that seems pessimistic about AI’s future, but my thinking is not pessimistic.
At the beginning of this article, you can see the AI rate is 50%. In reality, I also discussed similar issues with several friends and included my own thinking, so the true intellectual composition of this article is:
AI rate 50%, other human brain rate 10%, my brain rate 40%
So this article is also a typical case of “not giving up on using AI, nor giving up on using the human brain.”
Let me conclude with a few questions to briefly state my views:
Why do people still love reading human-written articles? Psychological preference and attention alignment.
Is reading useful (not just books)? Useful, and more useful than ever (bad books are more useless than ever; knowledge taste is more important than ever).
Will AIOps be realized? Yes, but it will take time, and it won’t be easy. This requires academic breakthroughs and the thinking and practice of operations (including DBAs).
Will DBAs be replaced? No. Like software developers, they will experience changes in work patterns but will not disappear.
Which DBAs will remain? “Those who understand both DB and AI, who don’t depend on AI, yet don’t give up on judgment.”
Will AGI be realized? Yes.
Will AGI achieve universal prosperity? No.
If you’d like to discuss AI Ops or the issues in this article with me, you can find me in various PG groups — I should be easy to find. You can also leave me a message.
ref#
https://github.com/TsinghuaDatabaseGroup/AIDB
https://mp.weixin.qq.com/s/urqh4NZDmkXvDllBCCdZDA
Zhao, Y., et al. (2025). “STRATUS: A Multi-agent System for Autonomous Reliability Engineering of Modern Clouds”. Advances in Neural Information Processing Systems (NeurIPS)
https://zhuanlan.zhihu.com/p/631632685
The Beauty of Mathematics (《数学之美》)