Paper: Anarchy in the Database: A Survey and Evaluation of Database Management System Extensibility
GitHub: https://github.com/cmu-db/ext-analyzer
PGConf: The trouble with extensions (PGConf.dev 2025)
Why This Paper#
This is a survey of database extensions (mainly Postgres), covering the implementation approaches of extensions across different databases, existing problems, and most importantly, compatibility. The most significant finding: an evaluation of over 400 PostgreSQL extensions shows that 16.8% of extensions have compatibility issues with at least one other extension, potentially leading to system failures.
Analysis tools and results are on GitHub; Marco Slot’s presentation is at PGConf.
Extension Categories#
Extension Classification#
The extension classification chapter is particularly lengthy — a single diagram actually clarifies everything.
Extensions across 6 databases:

- PostgreSQL (1986): Written in C, designed from the beginning as an extensible architecture. Consequently, PostgreSQL has the richest and most diverse extensible ecosystem.
- MySQL (1994): Written in C++, best known for its storage engine plugin architecture.
- MariaDB (2009): A fork of MySQL, also C++ based, supporting more extensions than the original MySQL.
- SQLite (2000): Embedded database written in C, adaptable to various hardware devices and operating systems.
- Redis (2009): In-memory key-value store written in C++, uniquely extensible — only supports running above the DBMS key-value storage layer.
- DuckDB (2018): Embedded analytical database written in C++, with a rapidly emerging extensible ecosystem.
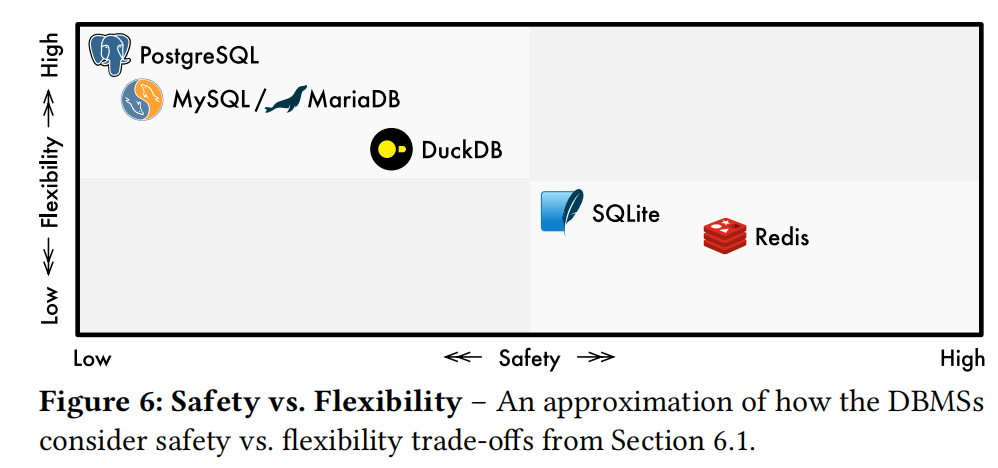
Flexibility and Security#
Extension security and flexibility are a trade-off — PG extensions are the most flexible but least secure; Redis is the most secure but least flexible:
How PostgreSQL Extensions Are Typically Implemented#
PG generally has two ways to implement extensions:
- Through handler functions, such as UDFs, UDTs, external tables, storage engines, and index access methods.
- Through hooks. Hooks are declared as function pointers in global variables; if a hook is set, it will call these pointers instead of its own code.
Implementations may use both approaches — they’re not mutually exclusive. The other 5 databases have generally similar implementations, but none of them have hook-based implementations.
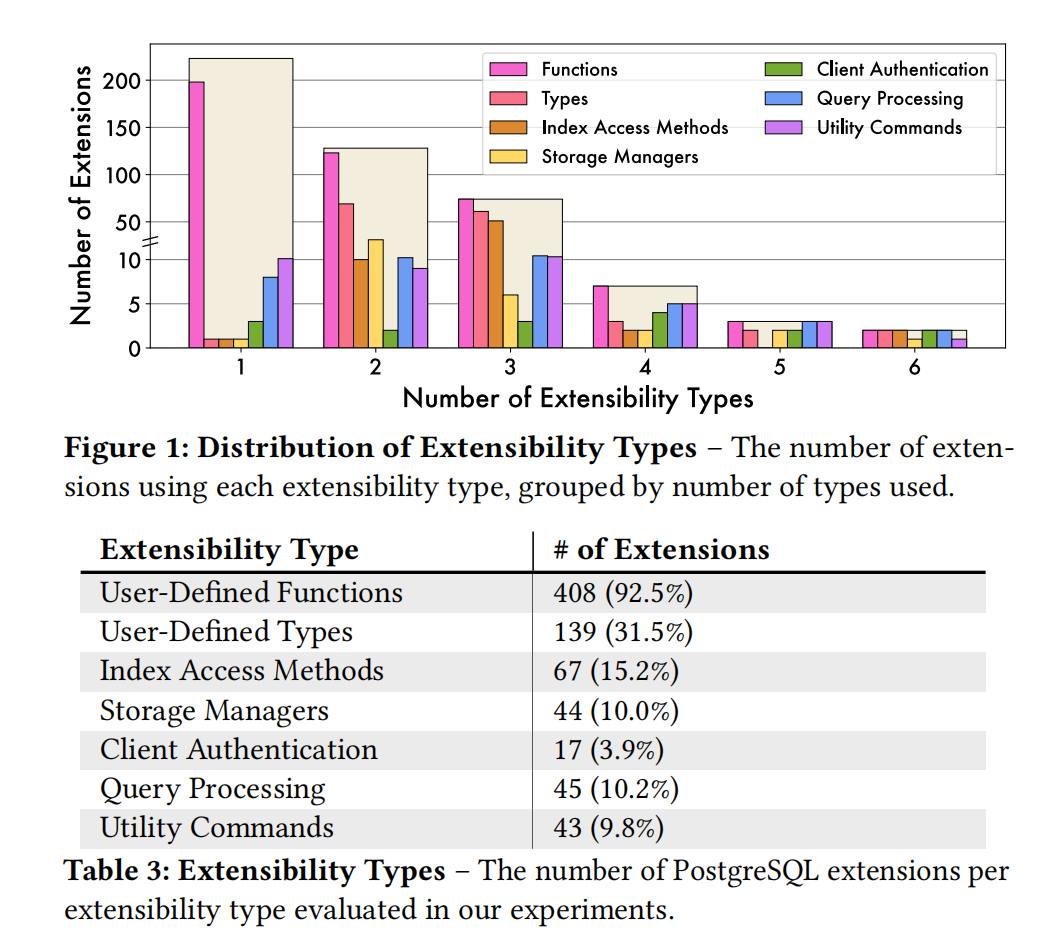
Extensions may use different implementation approaches, e.g., function + types + index AM — this is the number of extensibility types. From Figure 1, we can see that extensions with 1-3 types are the most common, and the most-used implementation approach is function.
From Table 3, 92.5% of extensions use UDFs — after all, it’s a user-facing feature, easiest to develop with the lowest barrier to entry. The least used is client authentication, as this scenario itself is uncommon.
Extension Code Copy Rate#
The paper also conducted an interesting survey: the extent to which extension code is copied from built-in code:
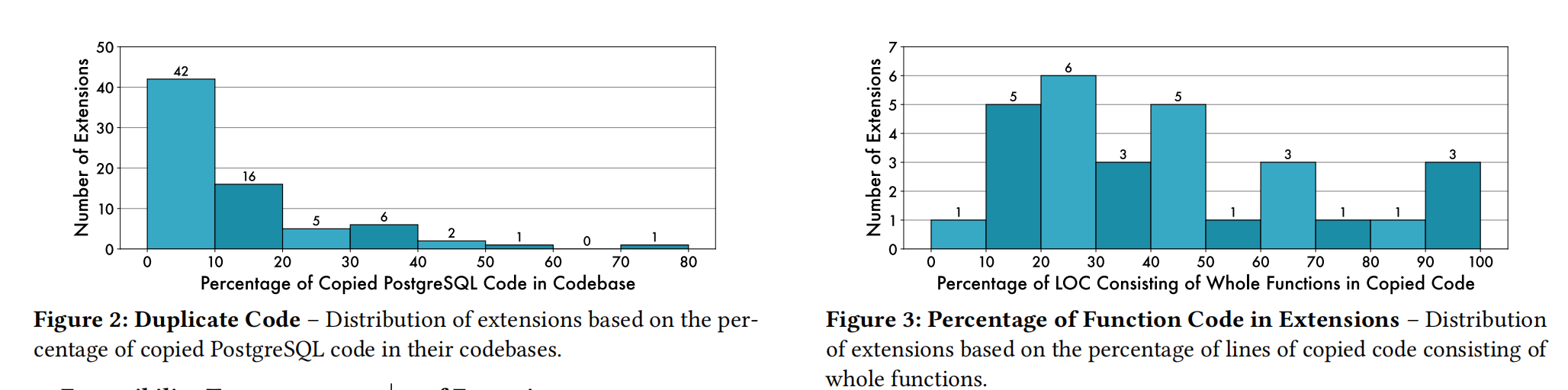
Out of 441 extensions, 16.6% — 73 extensions — contain at least one line copied from PG source code. The detailed distribution is shown in the left chart above.
Why are so many extensions copying code? Because:
- Some functions in PG source are declared static, only callable within their own file, so they can only be copied.
- Due to the extension’s own requirements, functions may need slight adjustments, so they can only be copied and adjusted.
And how much were these copied functions adjusted? See the right chart above.
As can be seen, unmodified copies are actually rare.
In summary, extension code is copied from PG source out of necessity, and the overall copy rate isn’t high.
The Heavyweight! — PG Extension Compatibility#
This is the most interesting part of the paper: pairwise compatibility testing was conducted on 96 extensions, and testing found that 16.8% of extension pairs are incompatible!
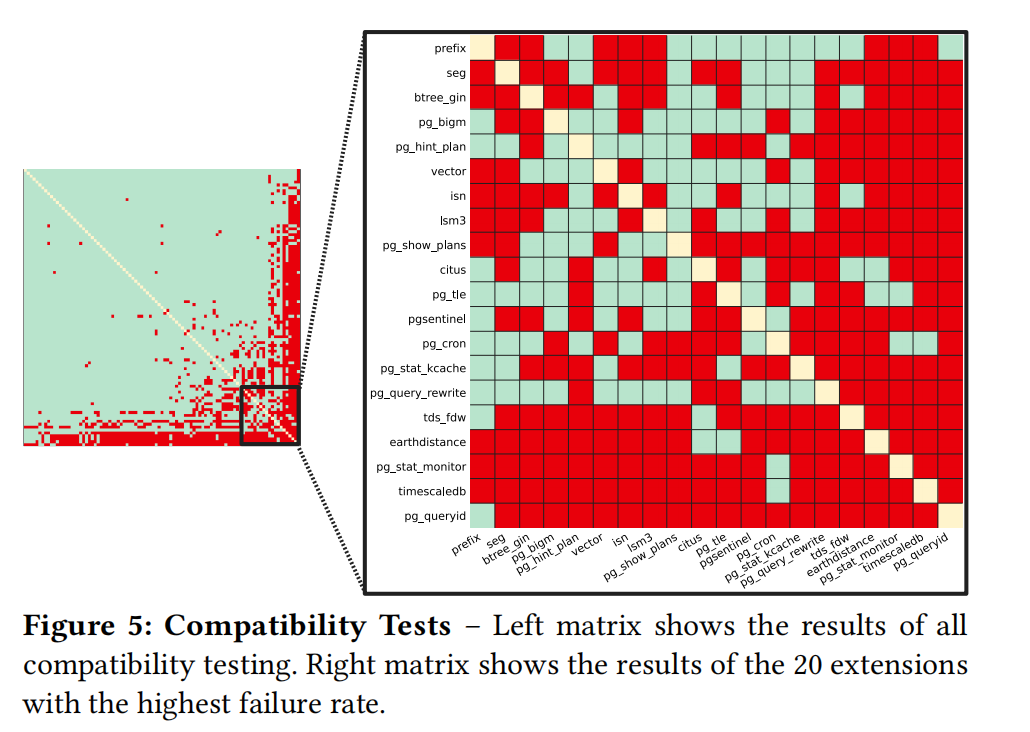
Testing methodology:
- Installation. Yes, installation alone can cause problems. The authors tested both A→B and B→A installation orders, hence the asymmetric diagram.
- Running the extension’s provided unit tests.
- pgbench. Smoke testing. pgbench is of course simple, but good results here can still indicate something.
Among the top 20 least compatible extensions, many commonly-used ones appear:
- Common extensions: pg_hint_plan, vector, pg_show_plans, pgsentinel, pg_cron, pg_stat_kcache
- Heavy extensions: citus, timescaledb
The fact that such extremely common and star extensions can have such poor compatibility is jaw-dropping.
What’s even more chilling: this is just simple pairwise testing. Running 3-10 extensions should be the production norm, and production environments are far more complex and variable than the paper’s three testing methods.
Finally, the paper identifies the reason for poor extension compatibility: extensions that use more components, extension types, and hooks are more likely to be incompatible with other extensions.
Nitpicking#
- It’s really still about Postgres
The paper’s title says DBMS, but it’s mainly about PG compatibility. MySQL, Redis, etc. compatibility is only covered in the survey, with no experimental data at all. (Though the survey is interesting — you can learn how MySQL and Redis extensions are implemented.)
On the other hand, this paper has a kind of alternative “general-specific-general” feel: “DBMS-Postgres-DBMS” 😅
- Insufficient compatibility testing
PG has 400+ extensions, but only 96 were tested for compatibility, and only 1-on-1 compatibility testing, without tests involving 3 or more extensions. The compatibility testing isn’t particularly comprehensive.
Conclusion#
PG extensions are indeed numerous and flexible — you’d struggle to find functionality that PG extensions don’t support. But the extensions themselves are almost in a state of “anarchy” — both extension development and usage have problems.
From the compatibility results, extension compatibility is quite poor — even the installation order affects compatibility. Multiple extensions also depend on hook execution order; for example, two extensions both requiring themselves to execute last becomes awkward. “Having everything” doesn’t mean “install everything.”
Extension Security Issues#
PG extensions have virtually no security management, whether from inherently unsafe extensions or user privilege escalation through extensions.
If an extension contains unsafe languages, only the OS can restrict its behavior, not the DBMS.
If an extension can access user space, the OS layer cannot manage it.
Extensions implemented through queries (e.g., UDFs) generally won’t bypass ACL policies. While UDFs are more secure, they’re not absolutely secure, as UDFs with admin privileges can exist.
A single hook may not be restricted by ACL, because in PostgreSQL, ACL is only enforced at the planning and execution layers. PG provides
SECURITY LABELto restrict access control for objects (including extensions).
Philosophical Thoughts on Software Management#
“If an extension contains unsafe languages, only the OS can restrict its behavior, not the DBMS.”
This statement itself isn’t wrong, but it carries an implication of “your directory could be deleted.” To counter this, consider the following:
If you use this software, you trust it, just like PG itself (but even when using PG, you create a postgres OS user rather than using root directly). As for extensions, treat them as part of the PG software. PG is trusted and can be installed directly in production because of its industry reputation. The same goes for extensions — choose reputable extensions rather than using them indiscriminately. This is essentially the difference between PostgreSQL community gatekeeping and extension provider gatekeeping. For cloud service providers, many extensions aren’t supported — the cloud provider assumes the gatekeeping function and the responsibility of taking the blame.
Version Convergence#
PG extension versions have these characteristics:
- The same extension may have different extension packages for different database versions.
- Extensions have different versions.
This means that without version management, you’ll end up with unmanageable numbers of software versions. To address this, limiting specific PG versions to installing specific extension versions is a good approach. As for extension upgrades needed for certain requirements, implement them through PG version upgrades. This strategy sacrifices some flexibility to ensure stability. I personally think it’s worthwhile — the need to upgrade extensions itself isn’t common, but it can reduce many software management issues and unknown compatibility problems.
Consider Compatibility When Using Extensions#
Since extension compatibility isn’t great, managing extensions becomes especially important — we don’t want the database returning strange results or even crashing while running.
- Extension management strategy: 1. Install necessary extensions. 2. Create needed extensions on demand. 3. Don’t install obscure extensions.
- Search the compatibility matrix. While PG compatibility testing isn’t perfect, it’s still valuable. Since the paper isn’t directly searchable for the compatibility matrix, you can “ctrl+f” search the ext-analyzer compatibility table to preliminarily assess whether extensions you need have good compatibility.
Trivia#
In the 1976 INGRES paper, UDFs were already implemented through extensions. Even POSTGRES carried forward this functionality in its 1986 initial release. Oracle’s UDF implementation came in Oracle 7, released in 1992 — much later than PG.


The SQL standard didn’t include UDFs until 1996 — a full 20 years after INGRES’s UDF. Stonebraker indeed wasn’t very focused on driving standards.
Original link: https://lastdba.com/2026/01/03/论文精读插件无政府状态/