Paper: PolarDB-MP: A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory
SIGMOD best paper: https://sigmod.org/sigmod-awards/sigmod-best-paper-award/
Foreword and Abstract#
The paper opens with the problem: primary-replica architecture’s write throughput is limited by the primary. Shared-nothing architecture offers scalable multi-primary clusters that can solve the single-primary limitation, but this architecture suffers performance bottlenecks due to distributed transaction overhead. Recently, shared-storage-based cloud-native multi-primary databases have emerged, but under high-conflict scenarios, they face high conflict resolution costs and low data fusion efficiency.
So the problem is: single-primary primary-replica, shared-nothing, and shared-storage cloud-native multi-primary architectures all have their own issues.
This paper proposes PolarDB-MP, a novel multi-primary cloud-native database combining disaggregated shared memory with shared storage. (Since multi-primary cloud-native databases already exist, it needs to be “novel.”)
PolarDB-MP’s basic characteristics:
- All nodes can equally access all data, allowing transactions to be processed independently on a single node, without traditional distributed transaction mechanisms.
- Shared storage: PolarStore and PolarFS, or other compatible shared storage solutions.
- Built on disaggregated shared memory.
- Low-latency communication via RDMA (Remote Direct Memory Access).
- LLSN (Local Logical Sequence Number): Used to establish partial order for WAL logs generated by different nodes, combined with custom recovery strategies to ensure consistency and efficiency during abnormal recovery.
- Core component PMFS (Polar Multi-Primary Fusion Server) responsible for:
- Transaction Fusion — transaction ordering and visibility management
- Buffer Fusion — distributed shared buffer mechanism
- Lock Fusion — cross-node concurrency control
Classification#
The classification is mainly to understand PolarDB-MP’s historical position and the “first” qualifier:
PolarDB-MP is the first multi-primary cloud-native database that utilizes disaggregated shared memory and shared storage for transaction coordination and buffer fusion
Competitor Weaknesses#
Shared-nothing products: The paper doesn’t call out individual products, just one line: transactions accessing across multiple partitions require significant additional overhead for distributed transactions.
Oracle:
- Expensive distributed lock management
- Expensive network overhead
- Reliance on sophisticated hardware (alien tech)
- Difficult to migrate to cloud, or higher TCO (including maintenance and labor costs) compared to cloud-native databases after migration
AWS Aurora-MM:
- Uses optimistic transaction model; high transaction abort rates under conflicts
- In some scenarios, 4-node throughput is lower than single-node
Huawei Taurus-MM:
- Pessimistic transaction model. Relies on page storage and log replay to ensure cache consistency, with high overhead in concurrency control and data synchronization.
- Under 50% shared data read-write workload, 8 nodes only achieve 1.5x single-node performance improvement
The Oracle critique here is mainly plausible-sounding trash talk, while Aurora-MM and Taurus-MM have original vendor citations:
- Aurora-MM “in some scenarios, 4-node throughput is lower than single-node”
- Taurus-MM “under 50% shared data read-write workload, 8 nodes only achieve 1.5x single-node performance improvement”
Transaction Fusion#
Transaction Fusion Overview#
How does multi-primary ensure consistent data views?
Snapshot isolation is a common MVCC implementation. A characteristic of snapshot isolation is that queries or transactions must maintain their consistent data view during execution. But in multi-primary architecture, local nodes cannot guarantee consistent data views due to remote data updates.
To solve this, general multi-primary shared-storage architectures introduce global transaction mechanisms (Aurora-MM or Taurus-MM). PolarDB-MP introduces an innovative technique — transaction fusion within PMFS. Each node only maintains local transaction information, which can be accessed by other nodes via RDMA. In contrast to global transactions, transaction fusion is decentralized.
Local Transactions and TIT Table#
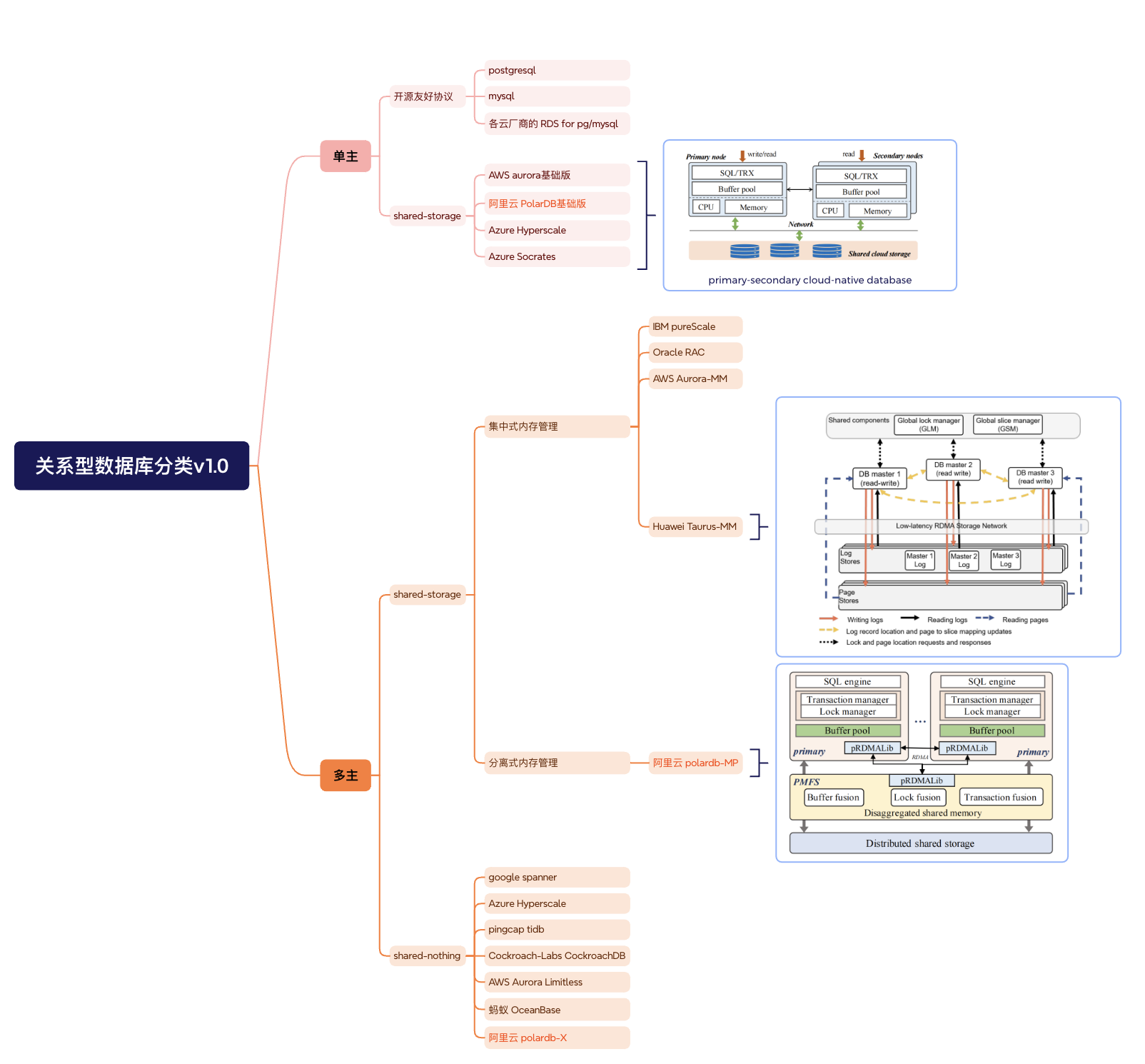
Each node in PolarDB-MP maintains a small amount of memory to store local transaction information (accessible by other nodes via RDMA). This local transaction information is stored in the transaction Information Table (TIT).
TIT table contents:
- Transaction object pointer
- Commit timestamp (CTS) assigned by the global timestamp coordinator (TSO)
- version, representing different transactions in the same slot
- ref, indicating whether this transaction is being waited on by other transactions for lock release (probably PLock or RLock)
How Transactions Proceed#
When a transaction begins, a local transaction id (presumably txid) is assigned, and the TIT slot stores the transaction object pointer, ref initialized to 0, and CTS initialized to CSN_INIT.
PolarDB-MP uses a global transaction ID to identify a transaction: global transaction ID = (node_id, trx_id, slot_id, version). The global transaction ID does not include CTS. To know the commit order of transactions, such as when constructing a transaction visibility view, you need to go through the global transaction ID, via RDMA, to the target node to find CTS (similar to PG’s pg_xact_commit_timestamp() function, which finds the corresponding transaction commit time from local files using the transaction id).
If trx_id is the transaction ID in PG, then node_id + trx_id can identify the global uniqueness of a transaction, or node_id + slot_id + version could also work to some extent (when slot id is not reused, e.g., at a given moment it uniquely identifies a transaction). Of course, the extra information combined is also unique. After all, this information is key to PolarDB-MP’s transaction fusion implementation.
Each transaction constructs a visibility view using the global transaction ID and CTS. The visibility view concept is consistent with PG: the current read view can read data rows committed before the read view, and the latest version rows.
Accessing Remote CTS#
Since CTS is local (in TIT or on the local filesystem), obtaining the reading transaction’s CTS is an interesting task:

1.1 If a row’s CTS is CSN_INIT/CTS_INIT, meaning the transaction is still active, return the maximum CTS to indicate it’s invisible to all transactions except itself.
If a row’s CTS is not CSN_INIT/CTS_INIT, meaning the transaction has committed, and it’s in the local TIT, directly return CTS.
If a row has no CTS, obtain CTS via the row’s g_trx_id.
2.1 If the transaction belongs to the local node (g_trx_id has node id), read from local filesystem to local TIT.
2.2 If the transaction doesn’t belong to the local node, read from remote filesystem to remote TIT via RDMA.
3.1 If slot.version != g_trx_id.version, the transaction must have committed, so the row is definitely visible to all transactions. Return minimum CTS to indicate visibility to all transactions.
3.2 If slot.version = g_trx_id.version, refer to 1.1, 1.2.
PolarDB-MP’s transaction visibility concept is very similar to PG’s, except PG uses txid instead of CTS to indicate transaction ordering and doesn’t need to consider remote access.
Row Update Transactions#
Additionally, row updates are also very similar:
When PolarDB-MP updates a row, besides updating the data itself, it must also:
- Update the row’s global transaction ID (g_trx_id) (if it’s an in-row update, then it modifies PG’s row header).
- Update the row’s CTS. (The paper doesn’t specify whether this is in the row header or filesystem. If similar to PG, it should be in the
commit_tsdirectory on the filesystem. Polar not confirmed.)
Questions About Transaction Fusion (Things I Didn’t Understand)#
g_trx_id is row metadata written to disk. If nodes are added or removed, does the node_id in the data row’s g_trx_id need updating? If not, which node should the row be loaded into when read next time?
A new row’s CTS is stored on local node A. If another node B updates this row, is the new CTS on node A or B?
“assigned a read view, which consists of its own g_trx_id and the current CTS.” Do read-only transactions also get assigned a g_trx_id when constructing a read view?
Without a doubt, a parameter like track_commit_timestamp must be forcibly enabled.
If there are many writes on node A and reads on node B, B’s reads will access A’s TIT data via RDMA — does this generate significant network IO? Should this be considered when designing read-write separation or multi-node reads and writes? The original paper might answer this — “Multi-primary architectures inherently require synchronizing large amounts of data and messages between nodes to support concurrent access across multiple nodes. As network technology develops (InfiniBand, RDMA) and achieves commercial deployment, the network bottleneck becomes less significant.”
Global timestamps could become a bottleneck in distributed systems. PolarDB-SCC is a shared-storage-based timestamp solution that appears to perform well. Due to time constraints, I’ll set this aside for now.
Buffer Fusion#
Buffer Fusion Introduction#
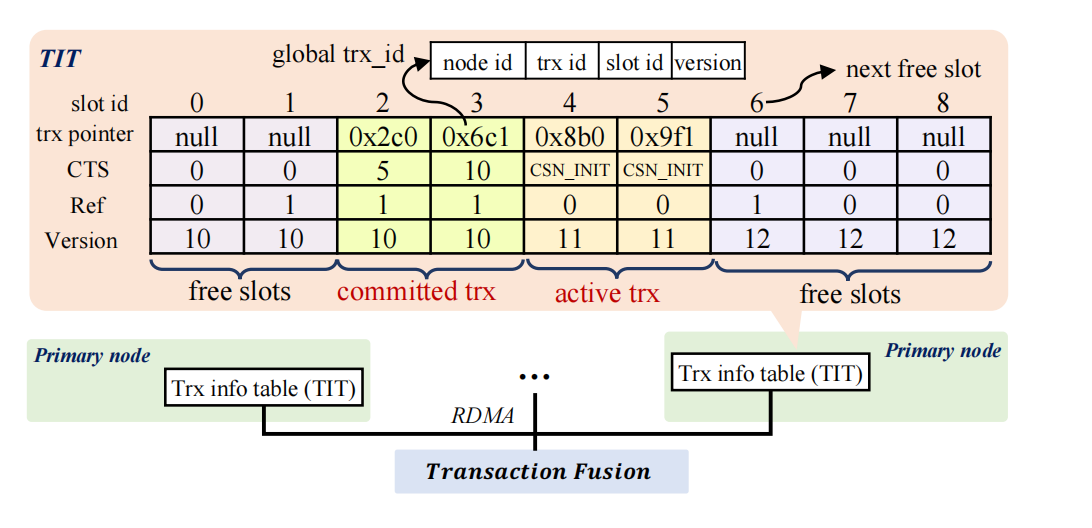
Each node in PolarDB-MP can update any data page, leading to substantial data transfer. Buffer Fusion’s distributed buffer pool (DBP) is designed to solve this problem. Each node has a local buffer pool (LBP), which is a subset of DBP.
How Buffer Fusion Works#
LBP has two new metadata items for pages:
- valid: whether the page has been updated by another node
- r_addr: pointer to the page in DBP
When accessing a page from LBP, the current node must first check if the page is valid. If invalid, it must access DBP via r_addr. After DBP stores a new version of the page, buffer fusion invalidates all remote pages. In LBP, dirty pages are periodically flushed to DBP in the background or after releasing the PLock lock.
Page access steps:
1.1 If the page is in LBP and valid, access directly. 1.2 If the page is in LBP and invalid, access DBP via RDMA. 2. If the page is in neither LBP nor DBP, read from shared storage. 3. The page is loaded from a node into LBP and registered in DBP.
PolarDB’s buffer fusion key component is disaggregated shared memory. It appears to be a/group of physical hardware or an integrated component built on top of it, separate from compute nodes. This differs significantly from memory in traditional distributed systems.
It’s also different from transaction fusion: transaction fusion requires accessing remote nodes with the same architecture, while buffer fusion doesn’t require accessing remote nodes with the same architecture — it separately accesses the disaggregated shared storage component.
Questions About Buffer Fusion (Things I Didn’t Understand)#
Disaggregated shared memory seems like a component separate from standard hosts — so what exactly is it?
Lock Fusion#
Lock Types in Lock Fusion#
Buffer fusion solves how nodes access remote data; lock fusion solves concurrent access control.
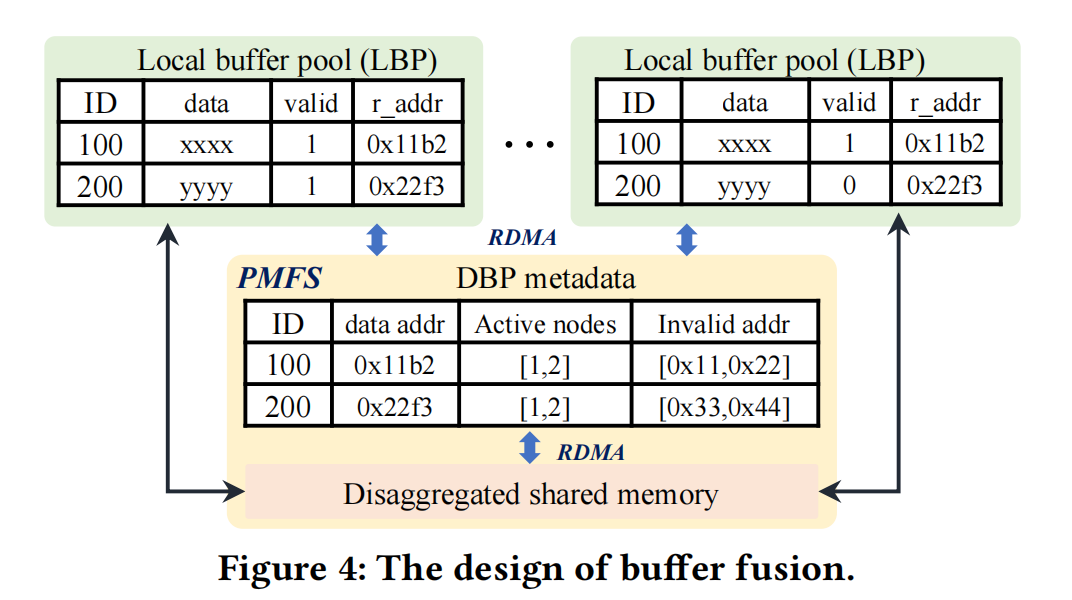
Buffer fusion has two types of locks:
- page-locking (PLock): Similar to latches, controlling atomic access and internal structure consistency. Single-node page access doesn’t use PLock.
- row-locking (RLock): Responsible for cross-node transaction control, following the two-phase lock protocol.
PLock Access Flow#
(The paper doesn’t say where lock fusion occurs. Since PLock is a page-level latch and page fusion happens on shared memory, I’ll assume lock fusion also occurs on shared memory, as this is easier to understand.)
- Before updating/reading a page, the local lock manager checks whether the local node already holds the corresponding X/S PLock (or higher-level lock). 1.1 If yes, execute in place. 1.2 If no, acquire PLock through Lock Fusion.
- Lock fusion checks for conflicts before responding; if a conflict exists, the request waits.
- When PLock is released by a node, it notifies Lock Fusion, which updates PLock’s state and notifies other nodes to continue their operations.
PLock Lazy Releasing#
According to the PLock access flow above, a PLock is immediately released after local operations complete. This may not be optimal — according to temporal locality: “a data item or instruction accessed at a given time is likely to be accessed again in the near future.” Lazy releasing minimizes PLock lock RPC access load.
The principle is simple: PLock is not immediately released after use on the local node; it’s only released when ref reaches 0.
When other nodes need PLock, Lock Fusion also sends negotiation messages to intervene when the local node is holding the lock; the local node must communicate with Lock Fusion rather than autonomously handling PLock. Lock Fusion uses a “first-in-first-out” strategy to resolve cross-node lock ownership, again until the local node’s ref = 0, at which point other nodes can acquire the lock.
Lazy releasing is an effective distributed lock solution, balancing local lock optimization with global lock allocation.
RLock Overview#
RLock uses the global transaction ID for determination (similar to PG). According to the transaction fusion content, the global transaction ID contains node id, transaction id, slot id, version. So when a local node reads a row, it can directly obtain the lock information on the row, know where the lock is (node id), and know if the lock is active.
There are two interesting points about determining transaction activity:
- From the transaction fusion flow of accessing remote CTS: if the transaction’s CTS is a valid value, or the transaction is in the same slot in TIT but not the same version, the transaction has definitely committed, so no need to check activity. If the source transaction is not active, there’s no need to wait for locks — proceed directly.
- PG has the concept of a minimum active transaction ID, which also exists in PolarDB-MP. If the transaction ID on the row is less than the global minimum active transaction ID, the source transaction must have also committed (or rolled back).
How RLock Works#
Local rows are handled locally; only conflicts are processed in Lock Fusion; cross-node row locks require RLock. “The transaction ID in the row functions as a lock indicator. So this protocol only supports exclusive (X) lock. The shared (S) lock on a row is not supported in PolarDB-MP, but it’s acceptable.” Only truly conflicting exclusive locks need RLock; shared locks don’t need RLock.
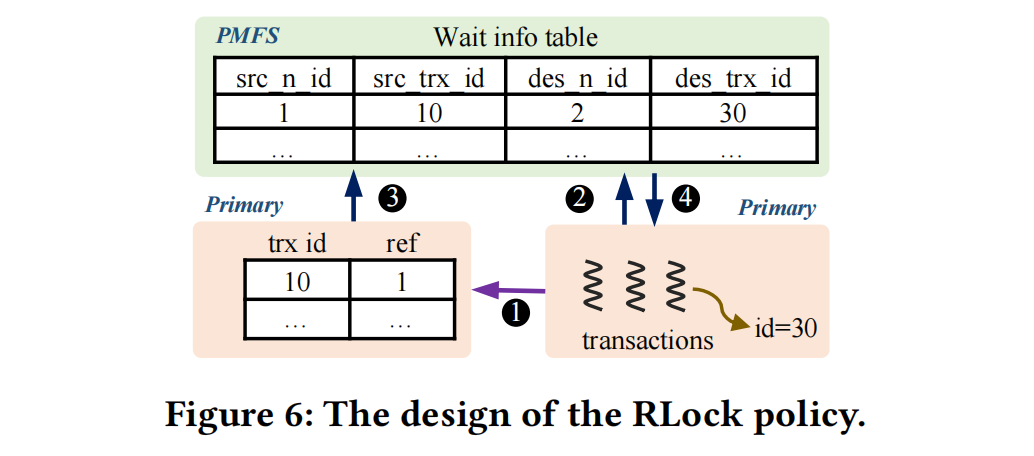
- T30 reads the row from shared storage and can determine from the row’s metadata (g_trx_id) that the transaction is active and which node it’s on.
- T30 remotely adjusts T10’s transaction ref.
- T30 sends a wait status to the Lock Fusion service.
- Lock Fusion adds wait information to the wait info table.
- T10 finishes execution and notifies Lock Fusion.
- Lock Fusion checks the wait info table, then notifies T30 it can continue.
Questions About Lock Fusion (Things I Didn’t Understand)#
“when attempting to update a row, it must already hold an X PLock lock on the page containing the row”
Updating also requires holding an exclusive PLock on the page, meaning updates on the same page block each other — doesn’t this affect concurrency? Locally, there shouldn’t be such behavior; PG doesn’t have page-exclusive locks for update scenarios.
In the “Logs ordering and recovery” chapter, there are two statements: “Thanks to the PLock design, only one transaction can update a page at a time” and “When a page is updated across two nodes, one node pushes its updated page to the DBP before releasing the PLock, allowing the next node to retrieve it from the DBP.”
Yes, during cross-node data updates, there are page-level exclusive locks.
PMFS Summary (Hot Take)#
PMFS (Polar Multi-Primary Fusion Server) is the core component implementing PolarDB-MP’s multi-primary distributed system. Among its features, the global transaction ID design is ingenious — it transforms PG’s transaction ID into one containing node information, transaction id, and transaction fusion’s slot and version information, placed in the row header. This has several benefits:
- Directly accessing a row reveals the row’s version ordering.
- Directly accessing a row reveals which node updated it.
- Directly accessing a row reveals whether cross-node locks may exist.
- Uses minimum active transactions to reduce conflict determination.
- Uses global transaction ID information to achieve distributed retrieval of transaction commit timestamps (CTS).
Additionally:
- Buffer fusion and lock fusion in PMFS appear highly dependent on the shared memory component.
- RDMA is omnipresent throughout.
Log Ordering#
Partial Order#
First, WAL is generated on each node without any concurrency control mechanism — each writes independently to shared storage. Each node’s LSN is sequential for that node, but across multiple nodes, WAL records don’t exhibit global ordering.
But is global ordering needed when writing WAL records?
From the paper, most of the time it’s not needed.
Only one case requires guaranteed global ordering during writing: cross-node updates to the same page.
However, according to the PMFS lock fusion mechanism, cross-node updates to the same page are exclusive. Lock fusion can ensure the ordering of cross-node page updates.
Recovery Ordering#
Since LLSNs from cross-node writes come from multiple nodes and are likely not in order, recovery needs to be done in order. Reading all WAL records and sorting by LLSN is a simple approach, but massive sorting is very resource-intensive.
PolarDB-MP proposes segment-wise sorting of LLSN — each segment is called a chunk, with chunk boundaries called LLSN bounds. PolarDB-MP can guarantee that an LLSN bound is always less than the next bound, then sort LLSNs within each chunk.
Questions About Log Ordering (Things I Didn’t Understand)#
“utilizing redo (write-ahead) logs for data recovery and undo logs for rolling back uncommitted changes”
PolarDB-MP has undo log files? What is this undo for?
I didn’t see anything particularly special about LLSN; the paper doesn’t detail its structure. LSN seems sufficient — maybe there are differences regarding global transaction IDs.
Evaluation#
Read-only operations are all local, so adding nodes linearly increases throughput. If read-write/write-only data is well-partitioned and doesn’t cross nodes, it’s also nearly linear.
The problem lies in shared data across read-write/write-only nodes, which is the ultimate test of distributed database performance.
The paper directly compares against Huawei’s Taurus-MM. The conclusion: PolarDB-MP’s cross-node write performance is indeed significantly better.
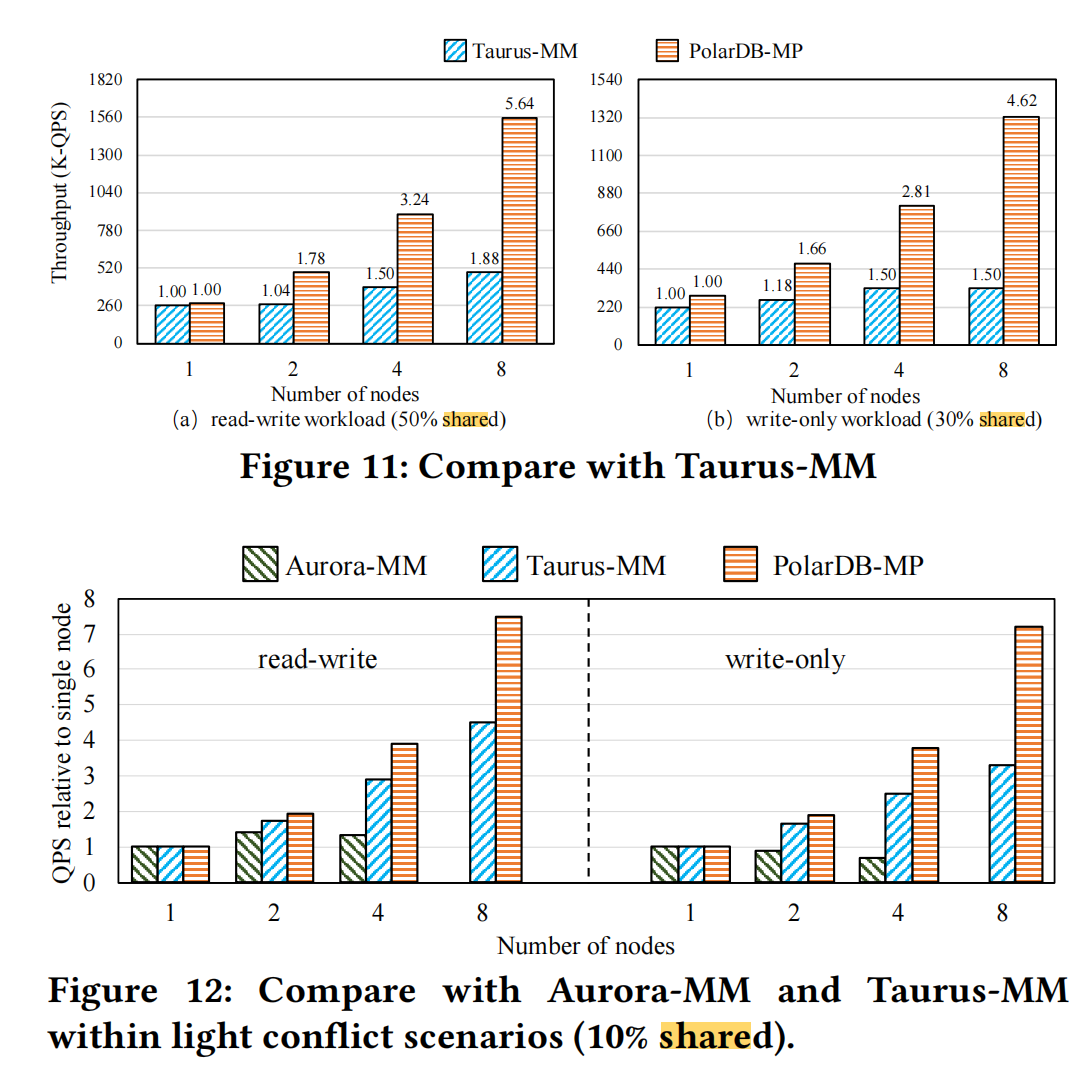
Nitpicking#
The paper mentions Taurus-MM’s performance improvement under 8-node shared data in two places, but the data is inconsistent:
The eight-node cluster only improves the throughput by 1.8× compared to the single-node version in the read-write workload with 50% shared data.
the throughput of Taurus-MM’s eight-node cluster is approximately 1.8× that of a single node under the SysBench write-only workload with 30% shared data, illustrating the trade-offs and challenges in optimizing multi-primary cloud databases
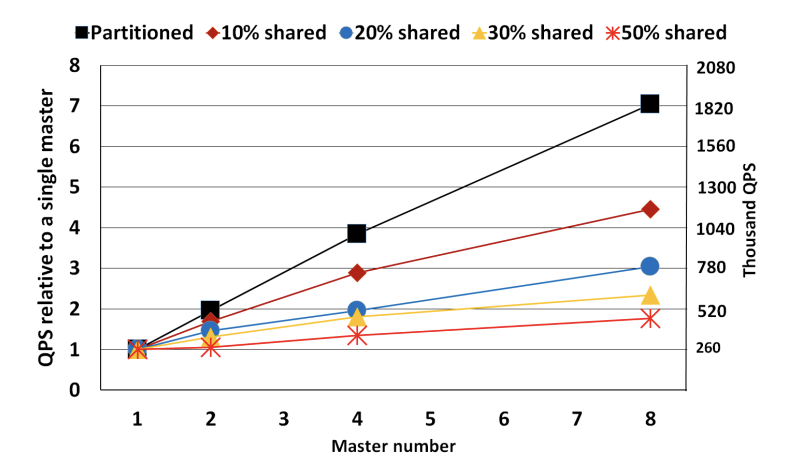
Sometimes 30% shared data, sometimes 50% — not very rigorous. The original Taurus MM paper says 50%:
Summary#
Not much to summarize — see the Foreword and Abstract and PMFS Summary sections.
Original link: https://lastdba.com/2025/11/30/论文精读polar-db-mp2024-sigmod最佳工业论文/