Paper: Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases
SIGMOD best paper: https://sigmod.org/sigmod-awards/sigmod-best-paper-award/
CXL and PolarDB-CXL#
What is CXL#
CXL: An open industry standard, a high-speed interconnect specification formulated by the CXL Consortium (founded in 2019 by tech giants Intel, AMD, ARM, etc.). It represents the evolutionary direction of computing architecture. Currently at CXL 4.0.
| Feature | CXL 1.0/1.1 | CXL 2.0 | CXL 3.0/3.1 | CXL 4.0 (latest) |
|---|---|---|---|---|
| Release | March/Sept 2019 | October 2020 | August 2022 / November 2023 | November 2025 |
| Base Protocol | PCIe 5.0 (32 GT/s) | PCIe 5.0 (32 GT/s) | PCIe 6.0 (64 GT/s) | PCIe 7.0 (128 GT/s) |
| Max Bandwidth | 1TB/s | 1TB/s | 2TB/s | 4TB/s+ |
| Topology Scale | Point-to-point / simple star | Single switch (≤32 nodes) | Multi-level Fabric (4096 nodes) | Ultra-large-scale Fabric |
From my research, two descriptions of CXL left the deepest impression:
- Memory as a Service
- Near-memory computing and expansion
CXL switch: A switching chip, physical hardware. Many vendors are working on industrial implementations. The paper specifically references products from XConn Tech: CXL 2.0 switch. Note that as of November 22, 2025, XConn only has CXL 2.0 switches, no 3.0 products. However, there are products on the market supporting 3.0+ standards, such as Panmnesia CXL 3.2 Fabric Switch.
PolarCXLMem: According to the paper, “the first CXL-switch-based disaggregated memory system.” But the paper also states “we leverage the world’s first CXL switch[50]” — specifically referring to the XConn tech CXL 2.0 switch — and then says “PolarCXLMem is the first CXL-switch-based disaggregated memory.” This can be interpreted in two ways:
- The first disaggregated memory system based on CXL switches
- The first disaggregated memory system based on XConn tech CXL 2.0 switches
PolarDB-CXL: The paper doesn’t actually use this term, but the industry uses it. It represents “integrate PolarCXLMem into the multi-primary version of PolarDB, known as PolarDB-MP” — essentially “the CXL-upgraded version of PolarDB-MP.” The paper repeatedly uses lengthy phrases but never uses the term polardb-cxl. For convenience, this article uses polardb-cxl to represent its essential meaning.
RDMA vs CXL#
PolarDB-MP uses RDMA architecture, while PolarDB-CXL uses CXL architecture:
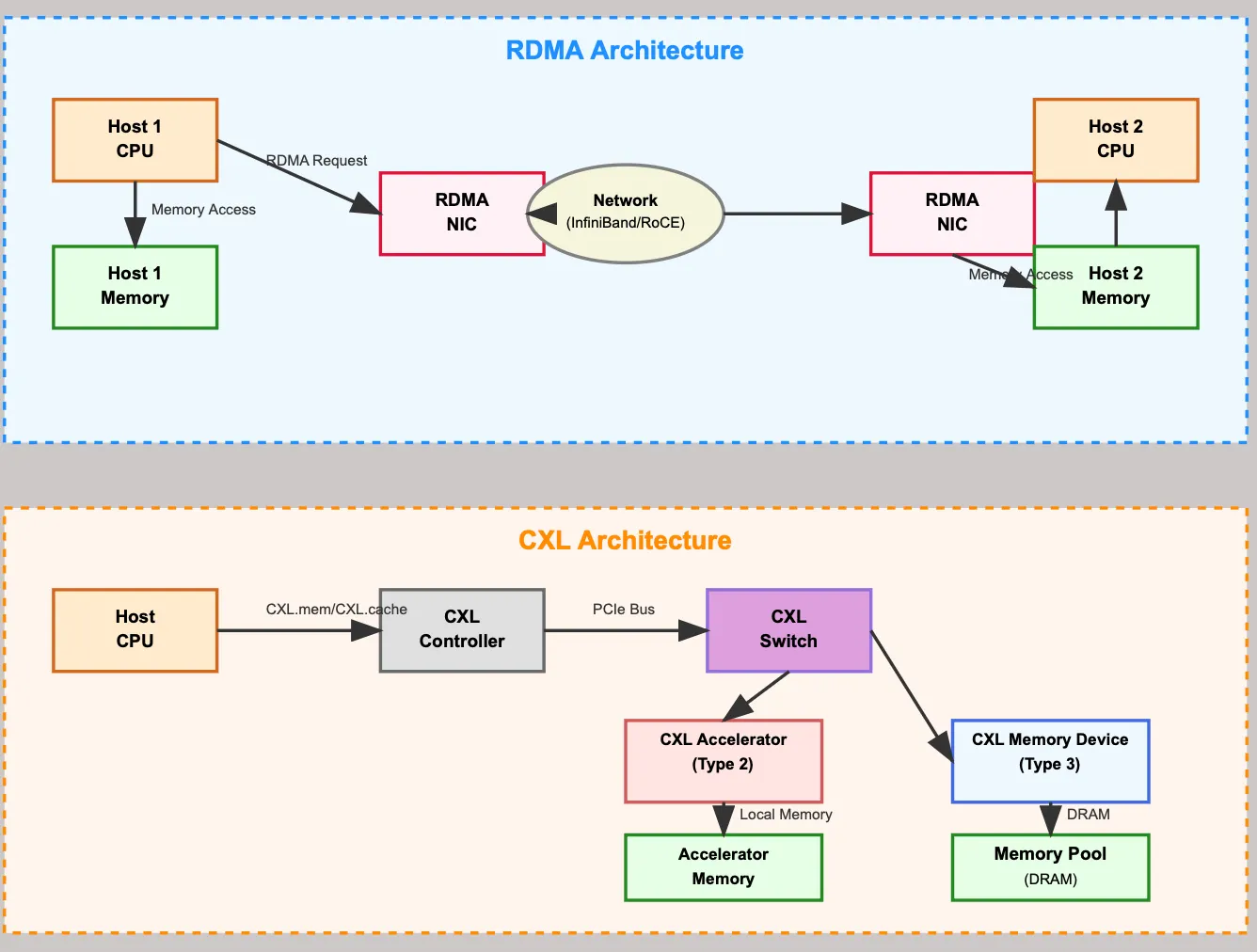
RDMA architecture is a cross-host distributed interconnect architecture, while CXL architecture is a single-host expanded interconnect architecture.
Key differences:
| Dimension | RDMA Architecture | CXL Architecture |
|---|---|---|
| Topology | Multi-host + network switch distributed arch | Single-host + CXL switch expanded arch |
| Communication | Network (InfiniBand/RoCE) | PCIe bus (CXL based on PCIe physical layer) |
| Core Components | RDMA NIC (dedicated NIC) | CXL Controller, CXL Switch |
| Resource Ownership | “Remote resources” across independent hosts | “Expanded resources” within the host architecture |
CXL’s Advantages#
CXL’s advantages over RDMA:
Low latency: CXL connects to host or device memory via PCIe; RDMA requires protocol interface conversion between InfiniBand and PCIe.
Instruction support: CXL provides native load/store instructions, allowing the CPU to directly manipulate remote CXL device memory as if it were local memory. RDMA requires reading from remote memory to local memory, processing locally, then writing back to remote memory.
Simplified applications: RDMA requires special interfaces and drivers, needing professionals to design complex programs; CXL provides transparent memory space, greatly simplifying application design.
Memory fusion: CXL 3.0 supports physical hardware-level memory pooling.
Problems with PolarDB-MP and the value CXL provides:
CXL’s critique of MP:
- Memory pages are 4-16K, so even when only a small amount of data transfer is needed, data must move between local and shared memory, causing read/write amplification.
- Maintaining local memory adds extra memory overhead, reducing throughput.
- Recovery is very time-consuming.
- RDMA is far better than TCP/IP, but under high concurrency, it suffers from “doorbell register implicit contention” and “cache thrashing” issues.
- The database itself must maintain shared memory.
Benefits CXL brings:
- Eliminates the “shared memory - local memory” hierarchical memory structure, also eliminating the maintenance overhead and read/write amplification. Because CXL load/store to local memory is fast enough, it allows directly storing all buffer pages.
- Uses cache lines (64B) as the minimum transfer unit between CPU cache and main memory, rather than PolarDB-MP’s 4K pages.
- Saves main memory. DRAM costs are very high, roughly 40-50% of server/rack costs.
- Simplifies system design. Minimal modifications to existing systems are important for commercial database stability.
- PolarRecv: An instant recovery system built on CXL. After a database crash, data and metadata remain on CXL, allowing direct reads of consistent state from CXL memory, so recovery is very fast. (This seems similar to how PG’s page cache helps fast startup after a crash.)
DRAM vs RDMA vs CXL:
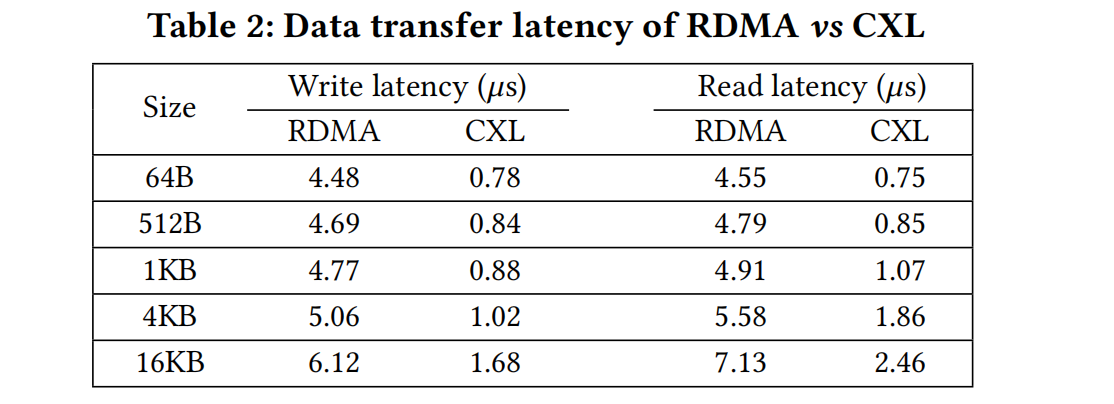
When data volume is small, RDMA has significantly higher latency than CXL; with larger data, RDMA’s latency improves slightly. Local DRAM access is slightly better than CXL access.
Overall, CXL memory access latency is slightly higher than DRAM but better than RDMA.
Regarding CXL’s higher latency vs DRAM, the paper explains: “database buffer pool operations are more sensitive to bandwidth than latency” — for database memory, bandwidth matters more than latency.
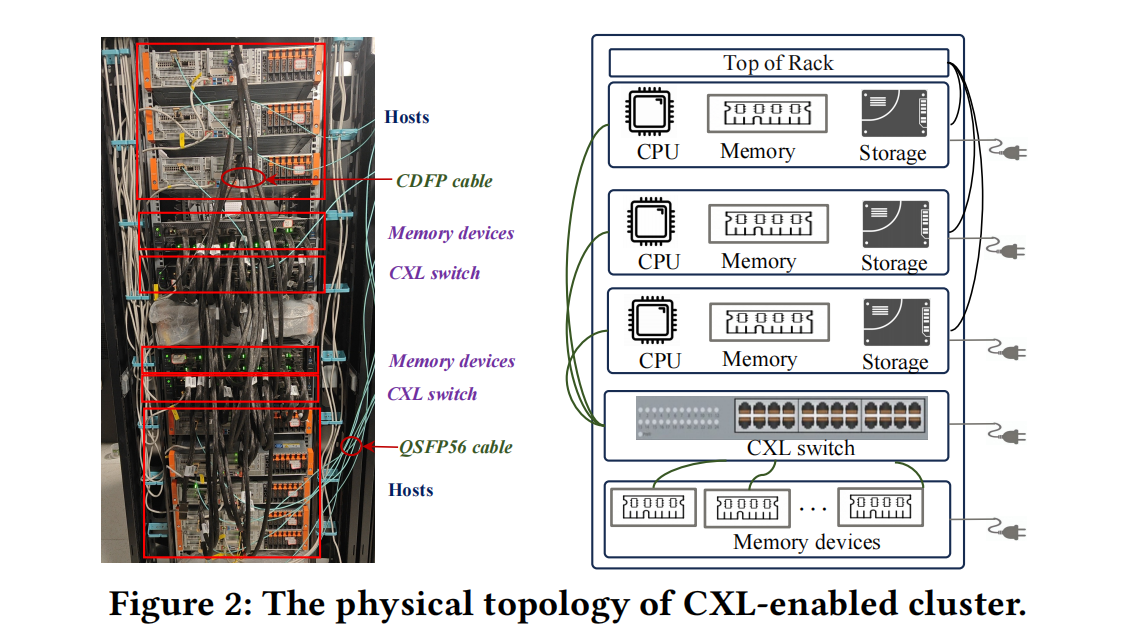
Custom Rack#
Self-developed physical prototype rack. The left rack integrates two CXL switch-enabled clusters, each connected to memory devices and hosts; the right rack integrates one CXL switch connected to memory devices and hosts.
PolarCXLMem#
The CXL 2.0 switch supports memory pooling, but the drivers don’t fully support it, so PolarCXLMem still designed its own CXL memory allocation and usage — it’s not fully transparent. PolarCXLMem processes CXL memory into a multi-tenant model, with different host nodes allocated different CXL memory regions.
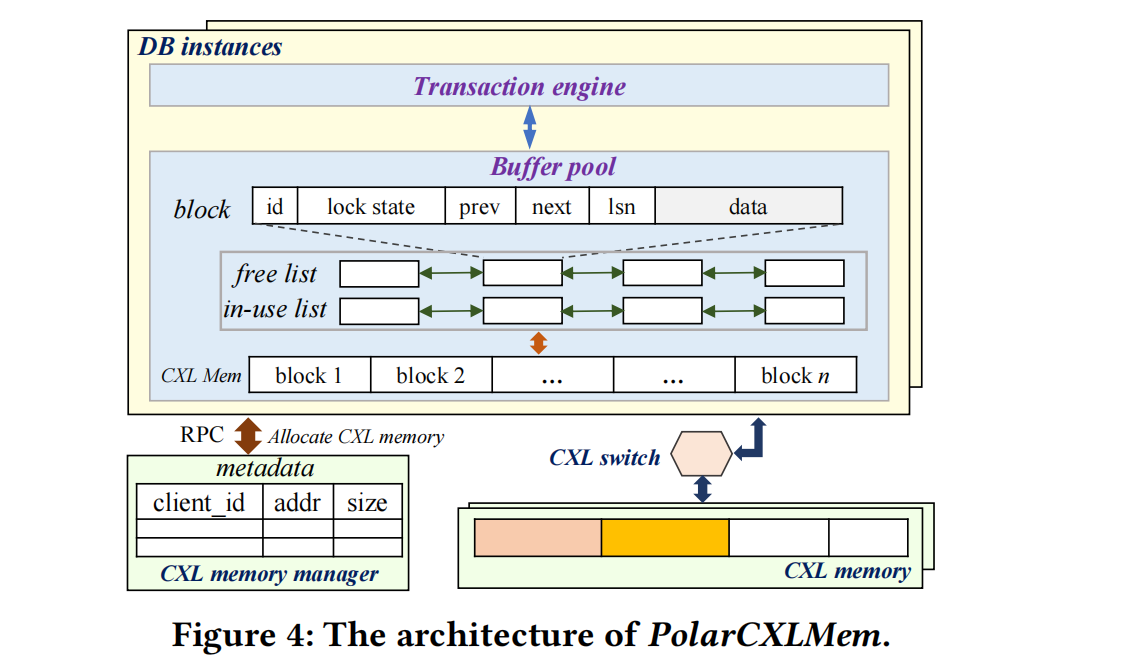
PolarCXLMem characteristics:
- Nodes have their own CXL memory regions; different nodes’ CXL memory does not overlap.
- The buffer pool is allocated at database startup (by the CXL mem manager in the diagram) and does not change during runtime.
- The memory unit structure in CXL mem is a block, which stores page data and page metadata, including: id (page id), lock state (whether the page is locked for update), prev/next (LRU doubly-linked list), lsn (latest log sequence number of the page).
- Free list / in-use list is used for LRU.
Question: PG’s page header has lsn, starting free space pointer, prune xid, etc. What does PolarDB-CXL’s page header structure look like?
PolarRecv#
PolarDB-MP was designed based on RDMA, where data pages are written locally, and the disaggregated shared memory doesn’t contain the latest version of data pages. This means after a host crash, you must scan and apply all redo log files (the paper says redo, not WAL) or pages from a small amount of shared memory.
CXL switches have independent power, so even if the host crashes, the latest data remains in CXL memory. PolarRecv leverages this to dramatically speed up database recovery after host crashes.
However, while CXL switch memory is transparent and persistent, directly using it after a crash still requires handling these issues:
- LRU lists may be inconsistent at crash time
- B-tree SMO (B-tree structure changes), such as index splits, may be inconsistent at crash time
- Pages being updated at crash time may be inconsistent
- The redo log buffer uses local DRAM. When the redo log hasn’t been flushed to disk at crash time, the page LSN in the CXL buffer pool may be greater than the LSN in the redo log file, directly violating the ARIES principle
PolarRecv’s design strategies:
- Use mutex to protect the LRU structure. The mutex lock state indicates whether LRU was being modified at crash time. If so, LRU must be rebuilt; if not, use the LRU directly from CXL memory.
- During B-tree SMO, a mini-transaction protects index pages. This mini-transaction is a two-phase lock corresponding to page locks. It’s only flushed to the redo log when the mini-transaction commits. So during recovery, if an index page is found with a write lock, recover from the redo logs.
- PolarCXL’s read/write locks are stored in CXL memory. If a write lock still exists, it means the update was in an intermediate state at crash time and not completed. In this case, honestly read the page from the redo log file rather than reading an inconsistent page from CXL memory.
- During recovery, first obtain the maximum LSN from the redo log, then check the lock and LSN of pages in CXL memory. If a page’s LSN in CXL memory is greater than the max LSN, rebuild the page using redo log information rather than using the CXL memory version.
Memory Fusion#
Because PolarCXLMem is designed based on the CXL 2.0 switch, and CXL 3.0 supports memory fusion, memory fusion design is still needed. Since each node’s buffer pool is placed in isolation in PolarCXLMem, CXL 2.0’s memory fusion is achieved through DBP metadata management — each buffer pool only stores the page’s CXL memory address, not the page itself.
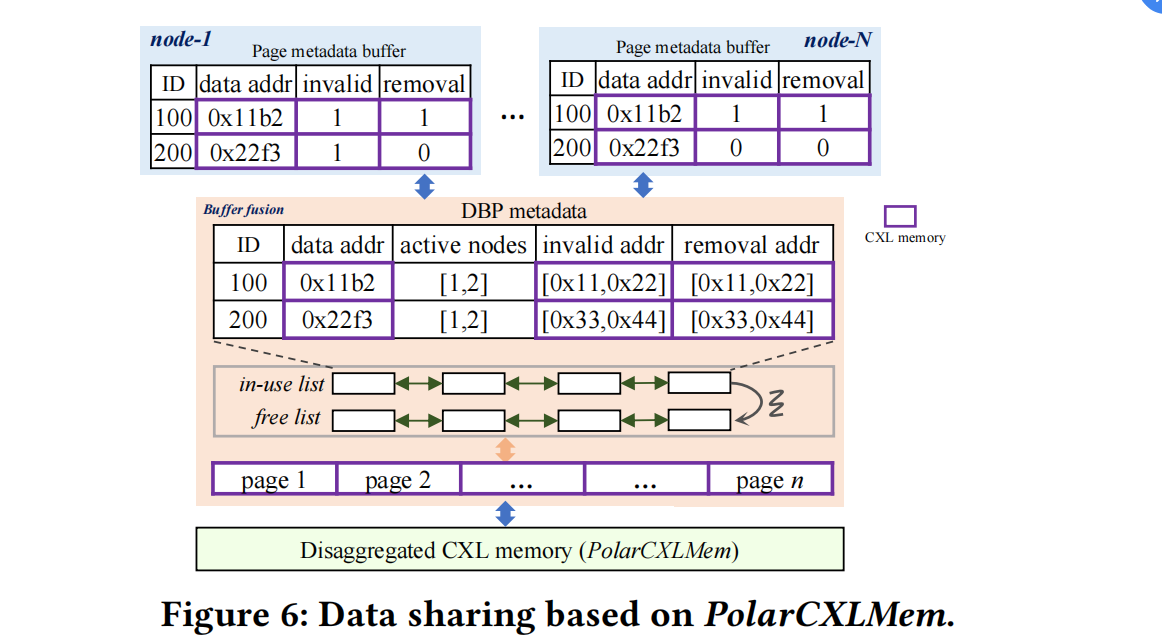
To understand this diagram, you need to distinguish between CXL memory, DBP, and local buffer:
- CXL memory is the physical hardware, CXL mem itself.
- DBP is a region carved out of CXL for managing memory fusion services.
- Local metadata buffer contains local buffer metadata and part of CXL.
Also understand that for each page in the buffer pool, there are two flags:
- invalid: After another node writes to the page, the current node needs to invalidate its local CPU cache.
- removal: When a page moves from the in-use list to the free list, all nodes must set the removal flag.
Memory fusion page access flow:
- The requested page is not in the local page metadata buffer: 1.1 Allocate a new meta record from the free list, and provide invalid and removal addresses to the memory fusion service via RPC.
The requested page is in the local page metadata buffer: 2.1 First check the removal flag. If removal is set, it means the memory fusion service has already reclaimed the page, and a new memory address must be requested from the memory fusion service via RPC. 2.2 Then check the invalid flag. If invalid is set, it means the page has been modified by another node, and the CPU cache must be invalidated to ensure consistency.
Fusion consistency:
Since CXL 2.0 doesn’t have memory fusion, CPU caches aren’t automatically updated. PolarCXL implements multi-node concurrent write control through page-level locks.
Nodes must acquire read/write locks to read/write pages. When one node is writing to a page, other nodes cannot read or write that page. After a node finishes writing, it must also:
- Flush the CPU cache to CXL mem (cache line flush) to ensure CXL mem has the latest page version.
- Set the invalid flag to ensure other nodes don’t read stale page versions from their CPU caches.
Memory fusion summary:
CXL 2.0 itself supports incomplete memory fusion, meaning the database layer still needs to design a memory fusion scheme. Memory pages are accessed via CXL addresses, rather than local/remote access to entire pages as in the RDMA approach. The local CPU cache needs the database layer to flush it to ensure node data access consistency — this is a hard limitation. This also means cross-node updates still use exclusive page-level locks (the RDMA approach also uses exclusive page-level locks).
Performance Evaluation#
Multi-Node Read/Write#
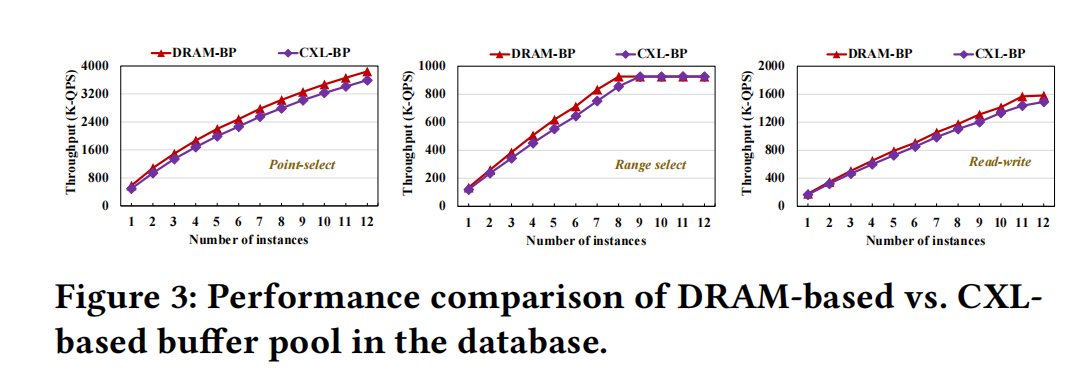
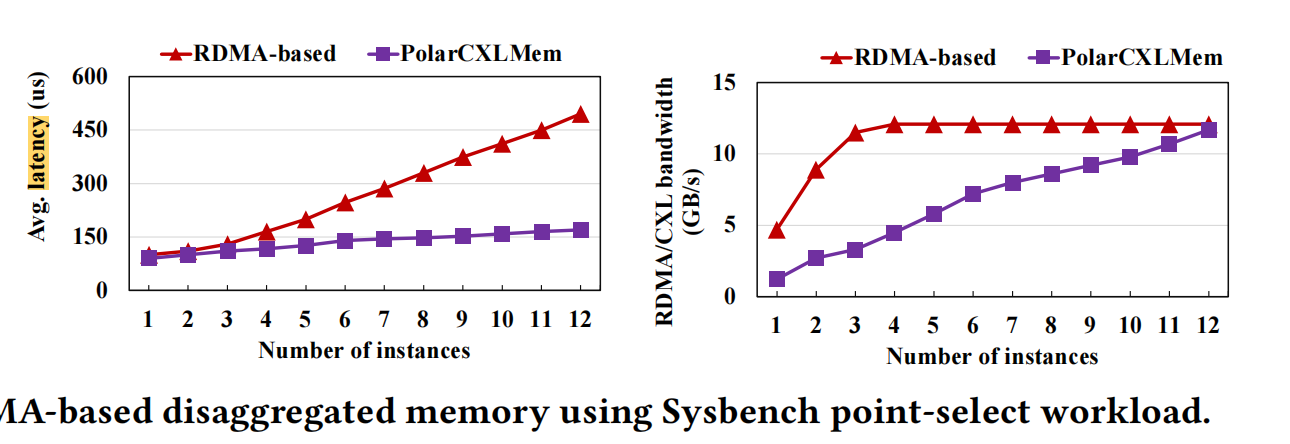
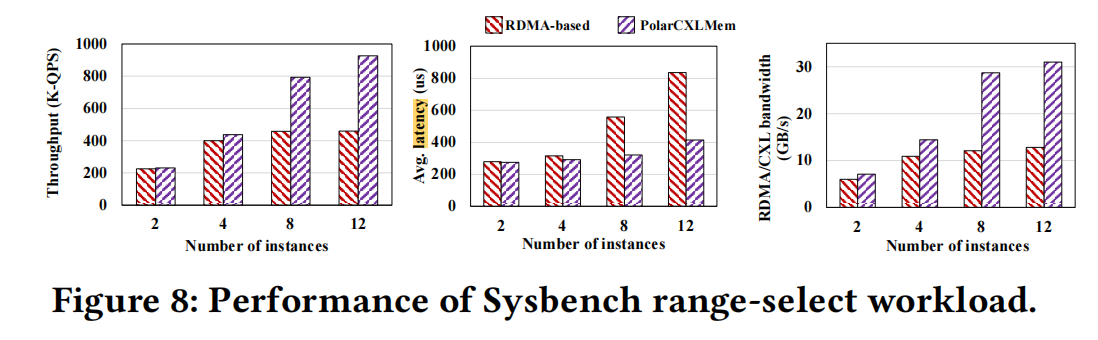
Benchmarking with 12 instances on a 192 vCPU host, comparing RDMA (PolarDB-MP) vs CXL (PolarDB-MP with PolarCXLMem) performance:
Point queries:
Range queries:
Read-write:
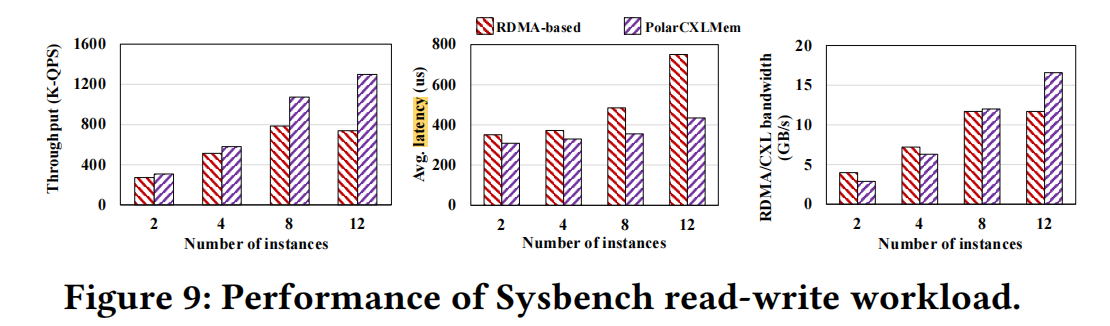
- Point queries: Read amplification is most severe for point queries. CXL’s bandwidth consumption is 3-4x lower than RDMA. When reaching 3 nodes, RDMA bandwidth is already saturated — adding more nodes doesn’t improve bandwidth.
- Range queries: Read amplification is less severe. Only at >4 nodes does it reach the bandwidth ceiling of 11GB/s, while CXL can still scale linearly with nodes.
- Read-write: Performance is similar to range queries, just with smaller differences.
PolarRecv Recovery Time#
- vanilla: Refers to the general approach, probably similar to PG reading from local cache or disk (possibly polar redo).
- RDMA-based: Refers to PolarDB-MP where some data can be read from disaggregated shared storage.
- PolarRecv: Refers to continuing to read most data from CXL, with only a small amount of partial pages needing recovery from redo files.
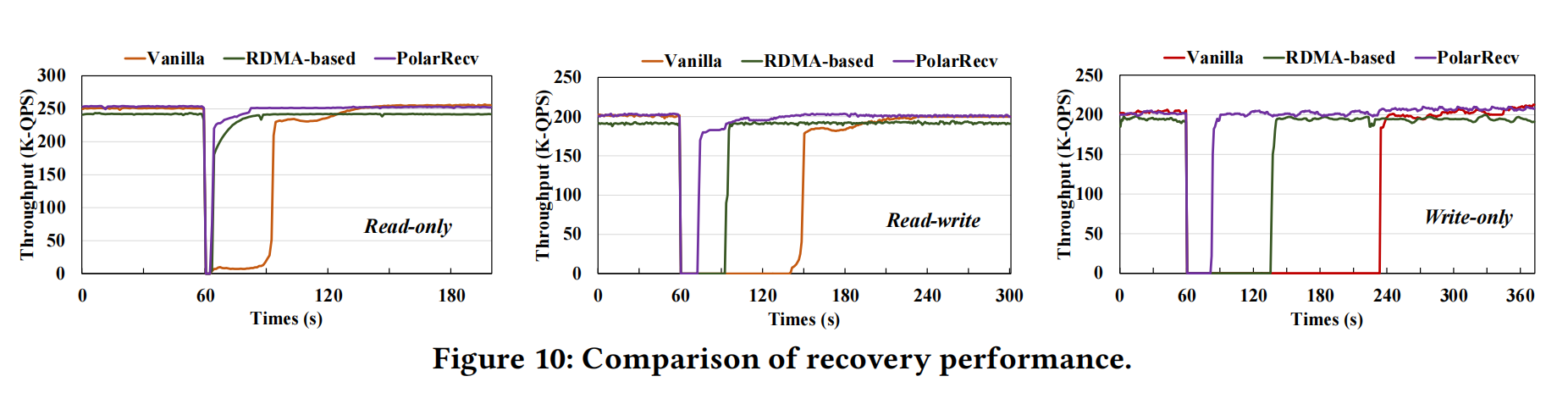
The paper discusses recovery time in 2 phases: startup/recovery and reaching pre-crash load levels. Read-only doesn’t need recovery — as long as there’s data, you can start and take load. When writes exist, recovery is needed, and the advantage of continuing to read from CXL memory becomes apparent. The difference between 1-minute, 2-minute, and 4-minute recovery times is significant — it could be the difference between business being nearly imperceptible and noticeably impacted.
Shared Data Updates#
The focal point of distributed database performance combat is updates to shared data. After PolarDB-MP crushed Taurus-MM, PolarDB-CXL also crushed PolarDB-MP:
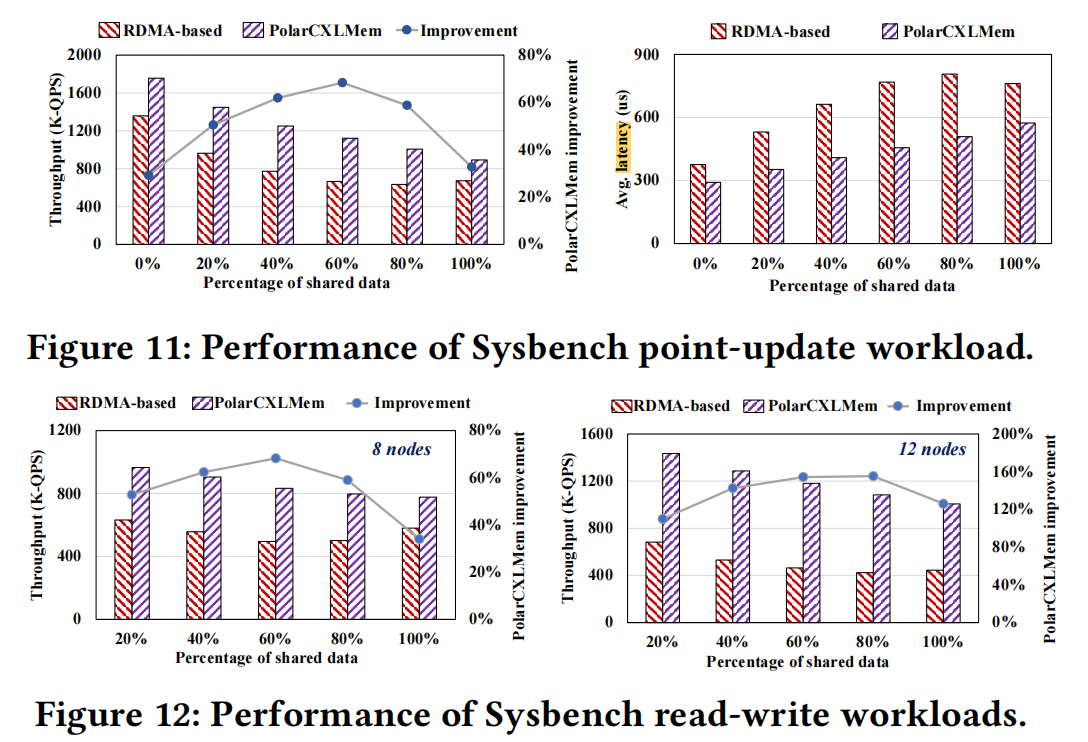
At 0% shared data, the RDMA-based solution just accesses local buffers, and PolarDB-CXL just treats CXL as a memory pool. Even so, CXL-based still performs better, mainly due to the read/write amplification and bandwidth ceiling issues of the RDMA-based solution mentioned earlier.
From the performance comparison chart above, it’s clear that PolarDB-CXL significantly outperforms PolarDB-MP. The data is very clear. However, note that when shared data >60%, PolarDB-CXL’s performance improvement becomes less significant, mainly because:
- Page-level locks become the bottleneck.
- As lock contention intensifies, processes enter sleep states, and frequent context switching further exacerbates resource contention.
Summary#
PolarDB-CXL advantages:
- Eliminates RDMA’s “local-remote” hierarchical memory structure design.
- Resolves RDMA’s read/write amplification problem.
- Provides a CXL-based memory pool.
- PolarRecv, based on CXL persistent memory, enables faster database crash recovery.
- Benchmarking shows PolarDB-MP CXL outperforms PolarDB-MP RDMA.
PolarDB-CXL disadvantages:
- Cross-node updates still use page-level locks, which remain the main performance bottleneck in shared data update scenarios.
- The CXL 2.0 switch seems a bit dated — by the time the paper was published, switch devices supporting 3.2 were already available, and CXL 4.0 was announced in November 2025. We can predict future databases built on newer CXL standard switch devices.
- The paper quality isn’t actually as high as the MP paper — it mainly revolves around solutions for the CXL 2.0 switch physical hardware, which differs from the extensive database-layer design found in the PolarDB-MP paper.
Original link: https://lastdba.com/2025/11/30/论文精读polar-db-cxl2025-sigmod最佳工业论文/