PostgreSQL Logical Replication#
 (https://www.pgconf.asia/JA/2017/wp-content/uploads/sites/2/2017/12/D2-A7-EN.pdf)
(https://www.pgconf.asia/JA/2017/wp-content/uploads/sites/2/2017/12/D2-A7-EN.pdf)
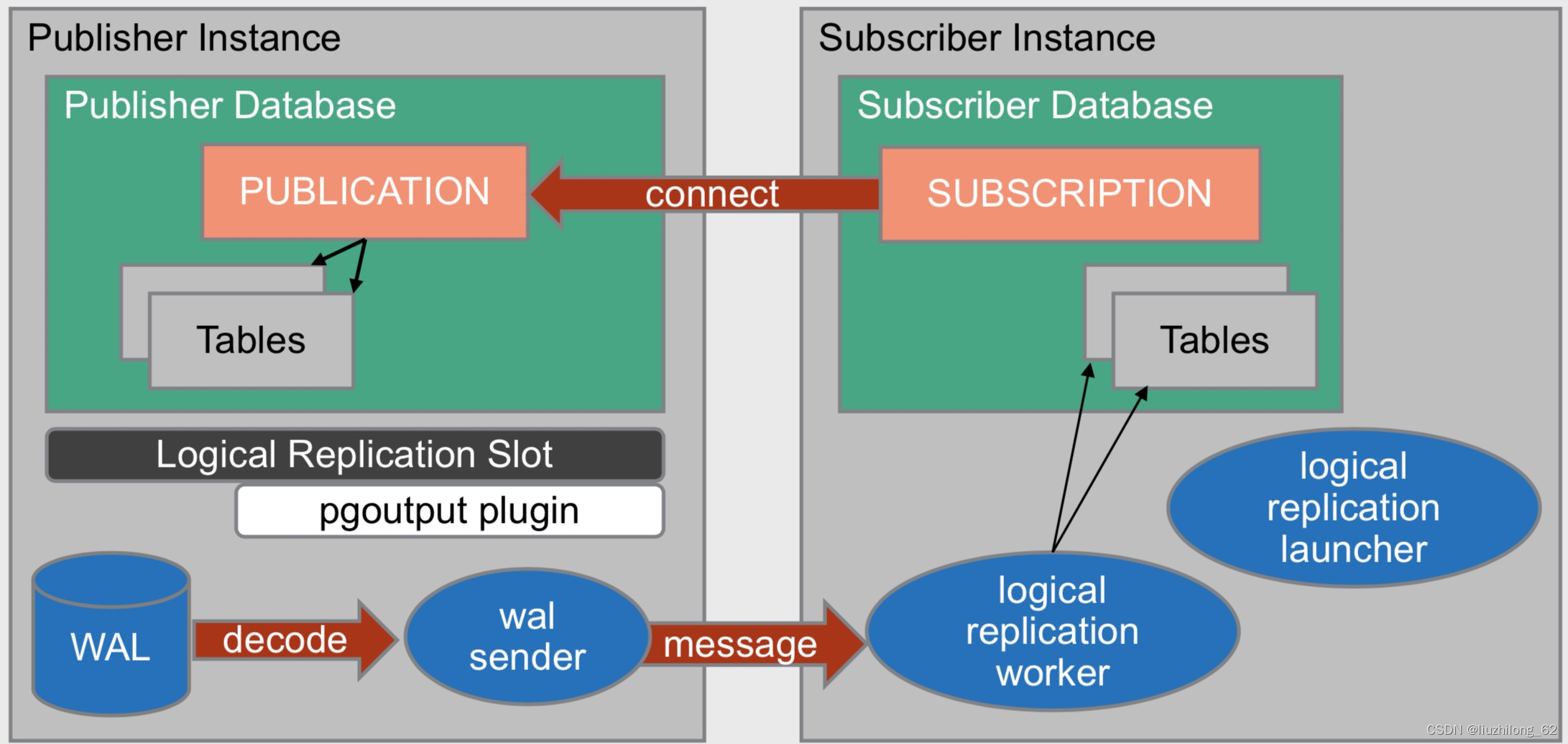
PostgreSQL places all logical decoding related matters entirely within the database’s replication slots for management — an all-inclusive approach. Early versions had somewhat limited logical replication support, but in recent major versions, logical replication has been one of the primary functional improvements.
Advantages of the PG approach:
- Very flexible: it exposes the logical decoding interface to users, with multiple types of decoding methods available.
- Users can subscribe to only the data they need based on their requirements.
Disadvantages of the PG approach:
- The number of concepts to learn and the learning cost are relatively higher compared to MySQL. Just the basic concepts — publication, subscription, walsender, replication slots, output plugins, etc. — I believe many people haven’t fully grasped their definitions and relationships.
- Does the hardest work and takes the hardest hits. All logical decoding problems are exposed within the database: WAL backlog, large transactions, long transactions, reorder transaction sorting, privilege issues, streaming transmission — these are all problems PG has to deal with.
MySQL’s binlog#
 (https://blog.fasterinfo.top/6243.html)
(https://blog.fasterinfo.top/6243.html)
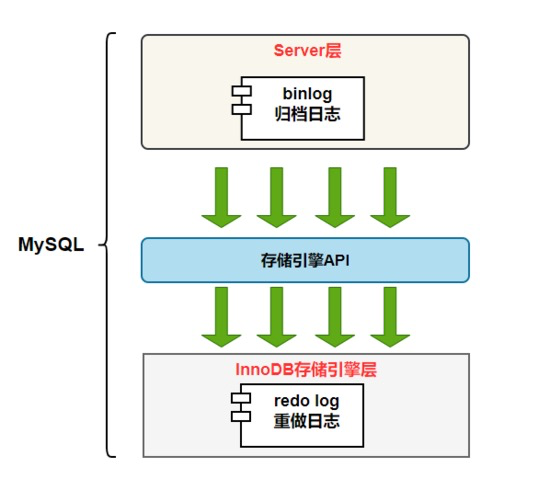
MySQL places all decoded logical data locally — in binlog files. The approach is simple. MySQL’s binlog is roughly equivalent to PostgreSQL with full-table logical replication enabled and written locally.
Advantages of the MySQL approach:
- Simple and straightforward: MySQL doesn’t expose the logical decoding interface directly to users. Instead, it provides already-decoded files directly to users, who don’t need to care about how parsing works — just read the binlog files.
- Mature ecosystem. I personally believe MySQL’s mature ecosystem is closely tied to binlog. During the internet era, PG’s logical replication was still weak, while binlog was extremely simple. Downstream parsing of binlog to put data onto other platforms became a common pattern.
Disadvantages of the MySQL approach:
- All data must be decoded; no customizable subscription. Poor flexibility.
- Two-phase commit. Because MySQL’s primary-standby replication heavily depends on binlog, binlog data must be fully flushed to binlog files at commit time. A single commit must write two (or two kinds of) logs — binlog and redolog. Dual log writes are one of MySQL’s eternal pain points.
Oracle Logical Replication#
 (https://www.oracle-scn.com/oracle-goldengate-integrated-capture/)
(https://www.oracle-scn.com/oracle-goldengate-integrated-capture/)
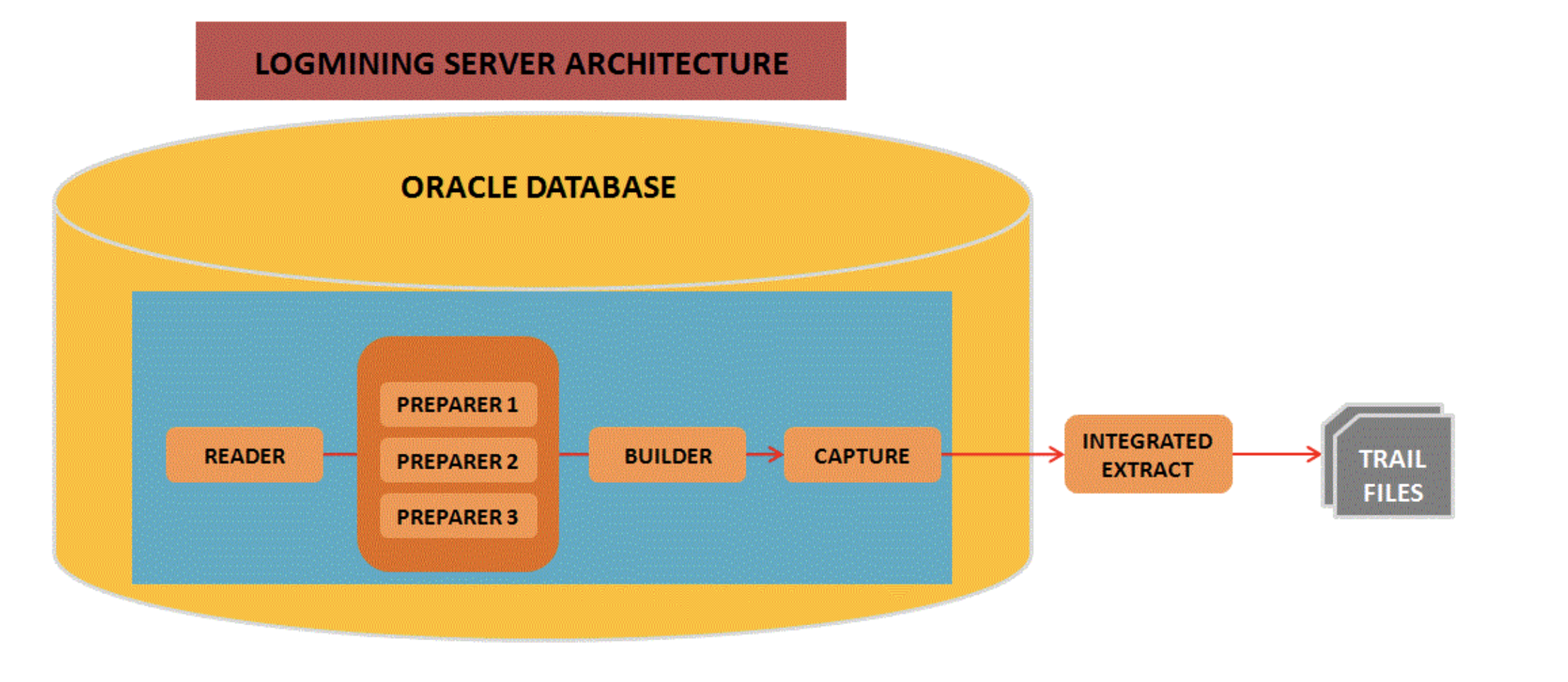
Oracle itself does have logical Data Guard functionality, but virtually no one uses it. Here we’ll only discuss LogMiner. The Oracle database itself provides an interface like LogMiner for parsing logs (e.g., OGG integrated capture mode), but has zero replication link management itself — it relies on third-party tools to create and manage replication links.
Advantages of the Oracle approach:
- Only provides a parsing interface, no replication link management. For the database itself, this is very hassle-free.
- Pay and you get a solution. Just buy the powerful OGG directly. Don’t say Oracle hasn’t provided a logical replication solution — we not only have one, it’s powerful and highly recognized.
Disadvantages of the Oracle approach:
- Relies on third-party software to manage replication links.
In summary, PG’s logical replication is an all-in-one, do-everything approach — very much in the open-source, technical spirit. MySQL’s approach is simple, crude, but effective — somewhat “one-step-to-finish.” Oracle’s approach is: provide an interface and leave everything else to third parties, but from the customer’s perspective, there is a mature solution available.