Problem Description#
The n_distinct statistic was severely inaccurate.
This problem appeared across multiple databases. For example:
A table with 200 million rows and a true DISTINCT count of 8 million had a statistics DISTINCT value of only 40,000.
Analysis#
Sampling Model#
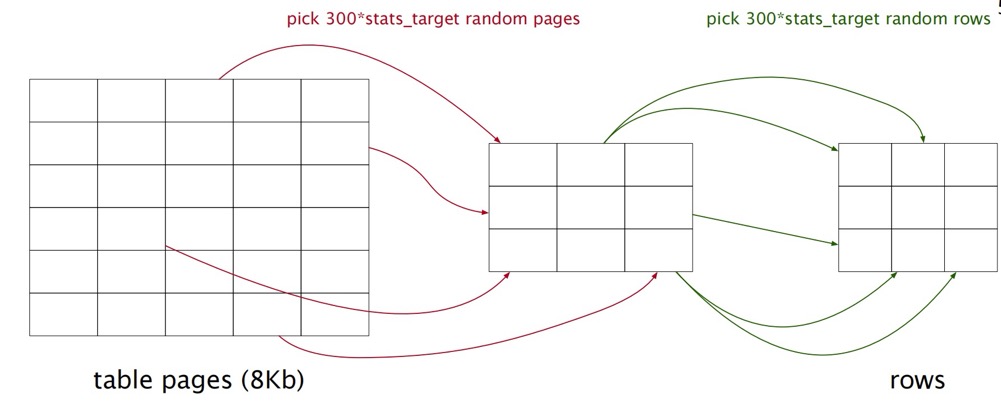
The default default_statistics_target=100 means 30,000 rows are sampled from 30,000 pages.
analyze verbose tablzl1;
INFO: 00000: analyzing "public.tablzl1"
LOCATION: do_analyze_rel, analyze.c:332
INFO: 00000: "tablzl1": scanned 30000 of 22963751 pages, containing 1061942 live rows and 3953 dead rows; 30000 rows in sample, 812872389 estimated total rows
LOCATION: acquire_sample_rows, analyze.c:1340Note “scanned 30000” and “30000 rows in sample”.
DISTINCT Estimation Algorithm#
The DISTINCT estimation algorithm in analyze.c:
/*----------
* Estimate the number of distinct values using the estimator
* proposed by Haas and Stokes in IBM Research Report RJ 10025:
* n*d / (n - f1 + f1*n/N)
* where f1 is the number of distinct values that occurred
* exactly once in our sample of n rows (from a total of N),
* and d is the total number of distinct values in the sample.
* This is their Duj1 estimator; the other estimators they
* recommend are considerably more complex, and are numerically
* very unstable when n is much smaller than N.
*
* In this calculation, we consider only non-nulls. We used to
* include rows with null values in the n and N counts, but that
* leads to inaccurate answers in columns with many nulls, and
* it's intuitively bogus anyway considering the desired result is
* the number of distinct non-null values.
*
* We assume (not very reliably!) that all the multiply-occurring
* values are reflected in the final track[] list, and the other
* nonnull values all appeared but once. (XXX this usually
* results in a drastic overestimate of ndistinct. Can we do
* any better?)
*----------
*/
int f1 = nonnull_cnt - summultiple;
int d = f1 + nmultiple;
double n = samplerows - null_cnt;
double N = totalrows * (1.0 - stats->stanullfrac);
double stadistinct;n*d / (n - f1 + f1*n/N)
n= number of sample rows (rows scanned)d= number of distinct values found in the samplef1= number of values appearing exactly once in the sampleN= total number of rows in the table
Algorithm paper: https://hugepdf.com/download/download-extended-version-of-this-paper_pdf
The paper is rather dense, so let’s work through some assumptions to understand this DISTINCT algorithm:
- Assume all values appear exactly once, and the table is large (n « N), so f1 = d, n/N ≈ 0
d*d / (d - d + d*0) = d²/0 — this would evaluate to -1.
- Assume all values appear exactly once, and the table is small (n = N), so f1 = d, n/N = 1
n*d / (n - d + d*1) = d — the sampled distinct count, which equals the number of sampled rows.
- Assume no values appear exactly once in the sample, i.e., f1 = 0
n*d / (n - f1 + f1*n/N) = n*d / n = d — just the distinct count in the sample.
If a column is populated by inserting several rows of the same value, then several rows of another value, like:
11, 2, 2, 2, 2, 3, 3, 3, …
3.1 Small table, all 30,000 rows sampled, true distinct = 10,000 (assumed): estimated distinct = d = 10,000
3.2 Large table, sample contains both repeating values and singletons (some repeating values only have one row captured), i.e., n = 30,000, n/N ≈ 0
n*d / (n - f1 + f1*n/N) = n*d / (n - f1) = 30000*d/(30000-f1) — the larger the distinct count in the sample, the larger the estimated distinct; the larger the number of singletons, the larger the estimated distinct.
Summary:
- DISTINCT estimation is directly related to the distinct count and singleton count in the sample
- If the singleton count = 0, then larger samples yield larger estimated distinct values
Verification#
Since the default maximum sample size is 30,000 rows, for tables larger than this, the estimator is likely to underestimate DISTINCT. Note: the data should not have too many unique values.
Testing a table with different sample sizes:
Table: reltuples = 800 million, relpages = 20 million, size = 175GB, true column distinct = 100 million
| target statistics | pages sampling ratio (approx) | tuples sampling ratio (approx) | n_distinct | execution time |
|---|---|---|---|---|
| 50 | 0.00075 | 0.00001875 | 60k | 2s |
| 100 | 0.0015 | 0.0000375 | 110k | 5s |
| 1000 | 0.015 | 0.000375 | 1.03M | 58s |
| 3000 | 0.045 | 0.001125 | 2.68M | 3min 1s |
| 10000 | 0.15 | 0.00375 | 6.75M | 7min 21s |
(maximum target statistics is 10000)
A rough conclusion: n_distinct and ANALYZE execution time grow proportionally with the sample size.
n_distinct grows with sample size, while pages and tuples estimates remain consistently accurate.
Solution#
For extremely large tables, consider partitioning or optimizing based on actual SQL patterns.
You can also adjust the statistics target. The default default_statistics_target=100 means 30,000 rows from 30,000 pages.
Temporary fix:
set default_statistics_target=3000;
analyze tab1;Long-term fix:
alter table tab1 alter column col1 set STATISTICS 3000;Notes:
- Column-level statistics target has the highest priority, overriding
default_statistics_target - Maximum statistics target is 10000
- The table’s sampling target is determined by the maximum column target:
/*
* Determine how many rows we need to sample, using the worst case from
* all analyzable columns. We use a lower bound of 100 rows to avoid
* possible overflow in Vitter's algorithm. (Note: that will also be the
* target in the corner case where there are no analyzable columns.)
*/
targrows = 100;
for (i = 0; i < attr_cnt; i++)
{
if (targrows < vacattrstats[i]->minrows)
targrows = vacattrstats[i]->minrows;
}
for (ind = 0; ind < nindexes; ind++)
{
AnlIndexData *thisdata = &indexdata[ind];
for (i = 0; i < thisdata->attr_cnt; i++)
{
if (targrows < thisdata->vacattrstats[i]->minrows)
targrows = thisdata->vacattrstats[i]->minrows;
}
}If ANALYZE collects more or fewer rows than expected, check pg_statistic for per-column stattarget settings:
select attrelid::regclass,attname,attstattarget from pg_attribute where attrelid = 'tab1'::regclass and attstattarget not in (-1,0);Summary#
For large tables where columns are non-unique but have high distinct counts (a realistic scenario), the sampling algorithm underestimates the DISTINCT value, and this is positively correlated with the sampling ratio. The default sampling ratio is too small for large tables. You can increase it, but even the maximum is not that large.