Walsender Blocking Shutdown Symptoms#
Production shutdown log output:
2024-12-06 17:00:02.036 CST,,,447560,,65693cde.6d448,1320,,2023-12-01 09:54:38 CST,,0,LOG,00000,"received fast shutdown request",,,,,,,,,"","postmaster"
2024-12-06 17:00:02.295 CST,,,447560,,65693cde.6d448,1322,,2023-12-01 09:54:38 CST,,0,LOG,00000,"background worker ""logical replication launcher"" (PID 448996) exited with exit code 1",,,,,,,,,"","postmaster"
2024-12-06 17:00:10.627 CST,,,448990,,65693ce0.6d9de,213833,,2023-12-01 09:54:40 CST,,0,LOG,00000,"checkpoint complete: wrote 426844 buffers (5.1%); 0 WAL file(s) added, 0 removed, 5 recycled; write=91.427 s, sync=0.055 s, total=91.508 s; sync files=761, longest=0.028 s, average=0.001 s; distance=2197531 kB, estimate=2680783 kB",,,,,,,,,"","checkpointer"
2024-12-06 17:00:10.628 CST,,,448990,,65693ce0.6d9de,213834,,2023-12-01 09:54:40 CST,,0,LOG,00000,"shutting down",,,,,,,,,"","checkpointer"
...
--checkpointer finished checkpoint and is in shutting down state, pm has not exited
--160s later pm receives immediate shutdown, triggered by health check script
2024-12-06 17:02:43.348 CST,,,447560,,65693cde.6d448,1323,,2023-12-01 09:54:38 CST,,0,LOG,00000,"received immediate shutdown request",,,,,,,,,"","postmaster"
2024-12-06 17:02:43.370 CST,"logicaluser","lzldb",283840,"10.33.77.159:39865",6751a2dc.454c0,7,"idle",2024-12-05 20:55:56 CST,89/847309655,0,WARNING,57P02,"terminating connection because of crash of another server process","The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.","In a moment you should be able to reconnect to the database and repeat your command.",,,,,,,"Debezium Streaming","walsender"
2024-12-06 17:02:43.370 CST,"logicaluser","lzldb",157641,"10.33.77.159:39407",67408354.267c9,7,"idle",2024-11-22 21:12:52 CST,9/3193590104,0,WARNING,57P02,"terminating connection because of crash of another server process","The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.","In a moment you should be able to reconnect to the database and repeat your command.",,,,,,,"Debezium Streaming","walsender"
2024-12-06 17:02:43.370 CST,"logicaluser","lzldb",157916,"10.33.77.159:57038",67408356.268dc,7,"idle",2024-11-22 21:12:54 CST,115/3293293502,0,WARNING,57P02,"terminating connection because of crash of another server process","The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.","In a moment you should be able to reconnect to the database and repeat your command.",,,,,,,"Debezium Streaming","walsender"
2024-12-06 17:02:43.370 CST,"repuser","",164392,"30.151.40.19:41641",66b25869.28228,3,"streaming 42D3B/1732C5F0",2024-08-07 01:07:53 CST,296/0,0,WARNING,57P02,"terminating connection because of crash of another server process","The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.","In a moment you should be able to reconnect to the database and repeat your command.",,,,,,,"standby_6666","walsender"
2024-12-06 17:02:43.371 CST,,,447560,,65693cde.6d448,1324,,2023-12-01 09:54:38 CST,,0,LOG,00000,"archiver process (PID 448994) exited with exit code 2",,,,,,,,,"","postmaster"
2024-12-06 17:02:43.371 CST,"logicaluser","lzldb",57755,"10.33.77.159:38918",67125534.e19b,7,"idle",2024-10-18 20:31:48 CST,243/902018192,0,WARNING,57P02,"terminating connection because of crash of another server process","The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.","In a moment you should be able to reconnect to the database and repeat your command.",,,,,,,"Debezium Streaming","walsender"
2024-12-06 17:02:43.372 CST,"logicaluser","lzldb",157915,"10.33.77.159:43433",67408356.268db,7,"idle",2024-11-22 21:12:54 CST,60/3248014863,0,WARNING,57P02,"terminating connection because of crash of another server process","The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.","In a moment you should be able to reconnect to the database and repeat your command.",,,,,,,"Debezium Streaming","walsender"
--pm finished shutting down
2024-12-06 17:02:57.534 CST,,,447560,,65693cde.6d448,1325,,2023-12-01 09:54:38 CST,,0,LOG,00000,"database system is shut down",,,,,,,,,"","postmaster"
2024-12-06 17:03:49.536 CST,,,211844,,6752bdf3.33b84,1,,2024-12-06 17:03:47 CST,,0,LOG,00000,"ending log output to stderr",,"Future log output will go to log destination ""csvlog"".",,,,,,,"","postmaster"17:00:02 postmaster receives fast shutdown
17:00:10 checkpoint completed, checkpointer stopped
17:02:43 postmaster receives immediate shutdown
17:02:43 1 physical and 5 logical replication walsenders stopped
17:02:57 postmaster stopped
17:03:49 postmaster receives startup task
From the above, it’s clear that walsender was blocking the shutdown.
Shutdown and Signals#
Before diving into source code, we need to understand signals and signal registration in PG.
Common Signals in PG#
OS signals:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
...Common signals used in PG:
-1or-SIGHUP: Hangup signal. In PG, typically tells the process to reload configuration.-2or-SIGINT: Interrupt signal (usuallyCtrl+C). In PG, usually corresponds to cancel command.-3or-SIGQUIT: In PG, usually means forced exit (die).-9or-SIGKILL: Unconditional termination signal.-15or-SIGTERM: Termination signal, the signal used bypg_terminate_backend. In PG, usually means graceful exit.-10or-SIGUSR1: Custom signal.-12or-SIGUSR2: Custom signal.-17orSIGCHLD: Signal used by the pm process. When a child process exits, pm receives this signal to trigger child process reaping.
The specific meaning of signals registered by each type of PG process can be found by reading the respective process source code.
Shutdown Defined by pg_ctl#
There are several ways to shut down a PG database. At the bottom level, they all boil down to sending a signal to the postmaster process.
| signal | pg_ctl | Meaning |
|---|---|---|
SIGTERM | Smart Shutdown | Disallow new connections, but allow existing sessions to finish their work normally. Only shuts down after all sessions terminate. |
SIGINT | Fast Shutdown | Server disallows new connections and sends SIGTERM to all existing child processes, aborting current transactions and exiting quickly. Waits for almost all child processes (some are not needed) to exit, then shuts down. |
SIGQUIT | Immediate Shutdown | Sends SIGQUIT to all child processes and waits for them to terminate. If any child process has not terminated within 5 seconds, they are sent SIGKILL. |
Note: pg_ctl has no parameter for sending SIGKILL (kill -9), but you can send SIGKILL directly to pm — though it’s definitely not recommended. When sending SIGKILL to pm, pm won’t do any cleanup of child processes, shared memory, or semaphores. Since SIGQUIT to pm has fallback logic for SIGKILL-ing child processes, SIGQUIT to pm basically guarantees pm will stop.
In the source code, there are only 3 shutdown states, corresponding to shutdown modes:
/* Startup/shutdown state */
#define NoShutdown 0
#define SmartShutdown 1
#define FastShutdown 2
#define ImmediateShutdown 3These states appear frequently in shutdown routine source code, generally checked via the Shutdown variable:
Shutdown >= FastShutdownpm Signals#
When pm receives the corresponding signal, it handles it accordingly:
void
PostmasterMain(int argc, char *argv[])
{...
pqsignal_pm(SIGHUP, SIGHUP_handler); /* reread config file and have
* children do same */
pqsignal_pm(SIGINT, pmdie); /* send SIGTERM and shut down */
pqsignal_pm(SIGQUIT, pmdie); /* send SIGQUIT and die */
pqsignal_pm(SIGTERM, pmdie); /* wait for children and shut down */
pqsignal_pm(SIGALRM, SIG_IGN); /* ignored */
pqsignal_pm(SIGPIPE, SIG_IGN); /* ignored */
pqsignal_pm(SIGUSR1, sigusr1_handler); /* message from child process */
pqsignal_pm(SIGUSR2, dummy_handler); /* unused, reserve for children */
pqsignal_pm(SIGCHLD, reaper); /* handle child termination */pmdie: The three shutdown signals call thepmdiefunction.pmdieis the key shutdown function, analyzed in detail below.reaper: During shutdown, handles child process exit cleanup. When a child process exits, it sendsSIGCHLDto pm, which entersreaperto clean up the child. Each child process cleanup has its own logic — for instance, normal exit of the checkpointer process checks whether archiver and walsender have completed their respective tasks.sigusr1,sigusr2:sigusr1_handleris the standard routine forSIGUSR1. Each child process handlesSIGUSR1differently.SIGUSR2is entirely custom per child process; some child processes don’t even register this signal.
Walsender Signals#
When a child process is forked, it first registers signals.
WalSndSignals registers signals for the walsender process:
/* Set up signal handlers */
void
WalSndSignals(void)
{
/* Set up signal handlers */
pqsignal(SIGHUP, SignalHandlerForConfigReload);
pqsignal(SIGINT, StatementCancelHandler); /* query cancel */
pqsignal(SIGTERM, die); /* request shutdown */
pqsignal(SIGQUIT, quickdie); /* hard crash time */
InitializeTimeouts(); /* establishes SIGALRM handler */
pqsignal(SIGPIPE, SIG_IGN);
pqsignal(SIGUSR1, procsignal_sigusr1_handler);
pqsignal(SIGUSR2, WalSndLastCycleHandler); /* request a last cycle and
* shutdown */
}Note SIGUSR1 and SIGUSR2.
Checkpointer Signals#
CheckpointerMain registers checkpointer signals:
void
CheckpointerMain(void)
{
...
//checkpointer blocks SIGTERM, the actual stop signal is SIGUSR2
pqsignal(SIGHUP, SignalHandlerForConfigReload);
pqsignal(SIGINT, ReqCheckpointHandler); /* request checkpoint */
pqsignal(SIGTERM, SIG_IGN); /* ignore SIGTERM */
pqsignal(SIGQUIT, SignalHandlerForCrashExit);
pqsignal(SIGALRM, SIG_IGN);
pqsignal(SIGPIPE, SIG_IGN);
pqsignal(SIGUSR1, procsignal_sigusr1_handler);
pqsignal(SIGUSR2, SignalHandlerForShutdownRequest);Note SIGUSR1 and SIGUSR2, and also note that checkpointer does not register SIGTERM.
Shutdown Source Code Analysis#
pm Signal Handling and State Machine#
The pmdie function handles different postmaster signals, including SIGCHLD sent by child processes to pm and shutdown signals sent by pg_ctl. The main logic of pm signal handling is converting the signal into a pmState state machine state transition, then entering PostmasterStateMachine for processing.
pmdie:
/*
* pmdie -- signal handler for processing various postmaster signals.
*/
static void
pmdie(SIGNAL_ARGS)
{
int save_errno = errno;
...
switch (postgres_signal_arg)
{
case SIGTERM://Smart Shutdown
...
if (pmState == PM_RUN)
connsAllowed = ALLOW_SUPERUSER_CONNS;
...
//smart shutdown does not process pmstate, hands directly to state machine
//at this point normal pmState = PM_RUN
PostmasterStateMachine();
break;
case SIGINT://Fast Shutdown
...
else if (pmState == PM_RUN ||
pmState == PM_HOT_STANDBY)
{
/* Report that we're about to zap live client sessions */
ereport(LOG,
(errmsg("aborting any active transactions")));
pmState = PM_STOP_BACKENDS;
}
//Fast Shutdown transitions pmstate to PM_STOP_BACKENDS
//then hands to state machine
PostmasterStateMachine();
break;
case SIGQUIT://Immediate Shutdown
...
TerminateChildren(SIGQUIT);//abort all children with SIGQUIT, wait for them to exit
pmState = PM_WAIT_BACKENDS;
/* set stopwatch for them to die */
AbortStartTime = time(NULL);
//Immediate Shutdown transitions pmstate to PM_WAIT_BACKENDS
//process children before entering state machine
//first interrupt children with SIGQUIT, wait for them to exit
//then use SIGKILL on remaining children
//finally non-consistent exit
PostmasterStateMachine();
break;
}
...
}Before entering the state machine handler, let’s look at the postmaster states:
typedef enum
{
PM_INIT, /* postmaster starting */
PM_STARTUP, /* waiting for startup subprocess */
PM_RECOVERY, /* in archive recovery mode */
PM_HOT_STANDBY, /* in hot standby mode */
PM_RUN, /* normal "database is alive" state */
PM_STOP_BACKENDS, /* need to stop remaining backends */
PM_WAIT_BACKENDS, /* waiting for live backends to exit */
PM_SHUTDOWN, /* waiting for checkpointer to do shutdown
* ckpt */
PM_SHUTDOWN_2, /* waiting for archiver and walsenders to
* finish */
PM_WAIT_DEAD_END, /* waiting for dead_end children to exit */
PM_NO_CHILDREN /* all important children have exited */
} PMState;Since shutdown normally happens from the running state, we only need to focus on states at PM_RUN and below.
PostmasterStateMachine execution has a sequential logic:
/*
* Advance the postmaster's state machine and take actions as appropriate
*
* This is common code for pmdie(), reaper() and sigusr1_handler(), which
* receive the signals that might mean we need to change state.
*/
static void
PostmasterStateMachine(void)
{
//smart shutdown, pmState should be PM_RUN at this point
if (pmState == PM_RUN || pmState == PM_HOT_STANDBY)
{
...
if (connsAllowed == ALLOW_NO_CONNS)
{
//After all normal backends exit, transition pmState to PM_STOP_BACKENDS
if (CountChildren(BACKEND_TYPE_NORMAL) == 0)
pmState = PM_STOP_BACKENDS;
}
}
//PM_STOP_BACKENDS stops some core child processes, some will continue running
//autovacuum, bgwriter, walwriter, startup, walreceiver will stop
//walsender, checkpointer, archiver, stats, and syslogger will keep running
//smart shutdown later phase enters this logic, fast shutdown enters directly
if (pmState == PM_STOP_BACKENDS)
{
...
//Note this line about walsender!
/* Signal all backend children except walsenders */
SignalSomeChildren(SIGTERM,
BACKEND_TYPE_ALL - BACKEND_TYPE_WALSND);
/* and the autovac launcher too */
if (AutoVacPID != 0)
signal_child(AutoVacPID, SIGTERM);
/* and the bgwriter too */
if (BgWriterPID != 0)
signal_child(BgWriterPID, SIGTERM);
/* and the walwriter too */
if (WalWriterPID != 0)
signal_child(WalWriterPID, SIGTERM);
/* If we're in recovery, also stop startup and walreceiver procs */
if (StartupPID != 0)
signal_child(StartupPID, SIGTERM);
if (WalReceiverPID != 0)
signal_child(WalReceiverPID, SIGTERM);
/* checkpointer, archiver, stats, and syslogger may continue for now */
//Transition pmState from PM_STOP_BACKENDS to PM_WAIT_BACKEND
//PM_WAIT_BACKEND means waiting for backends to exit
pmState = PM_WAIT_BACKENDS;
}
/*
* If we are in a state-machine state that implies waiting for backends to
* exit, see if they're all gone, and change state if so.
*/
//
//smart shutdown, fast shutdown later phase enters this logic
//immediate shutdown when entering state machine, directly enters this logic
if (pmState == PM_WAIT_BACKENDS)
{
//During crash recovery and immediate shutdown, checkpointer needs proper exit
//archiver, stats, and syslogger don't need handling since they don't touch shared memory
//Walsenders also don't need handling; they exit after checkpoint record is written, just like archiver
if (CountChildren(BACKEND_TYPE_ALL - BACKEND_TYPE_WALSND) == 0 &&
StartupPID == 0 &&
WalReceiverPID == 0 &&
BgWriterPID == 0 &&
(CheckpointerPID == 0 ||
(!FatalError && Shutdown < ImmediateShutdown)) &&
WalWriterPID == 0 &&
AutoVacPID == 0)
{
if (Shutdown >= ImmediateShutdown || FatalError)
{
//ImmediateShutdown waits for dead end processes to finish
pmState = PM_WAIT_DEAD_END;
/*
* We already SIGQUIT'd the archiver and stats processes, if
* any, when we started immediate shutdown or entered
* FatalError state.
*/
}
else
{
//smart, fast shutdown goes here
//regular child processes have all exited, now notify checkpointer to do shutdown checkpoint
Assert(Shutdown > NoShutdown);
//If checkpointer process doesn't exist, start one
if (CheckpointerPID == 0)
CheckpointerPID = StartCheckpointer();
/* And tell it to shut down */
if (CheckpointerPID != 0)
{
//Send SIGUSR2 to Checkpointer
//pmState = PM_SHUTDOWN
signal_child(CheckpointerPID, SIGUSR2);
pmState = PM_SHUTDOWN;
}
else
{
//Failing to start Checkpointer is a serious problem
FatalError = true;
pmState = PM_WAIT_DEAD_END;
/* Kill the walsenders, archiver and stats collector too */
//Comment says kill walsender, but it actually doesn't; at least not via SIGQUIT
SignalChildren(SIGQUIT);
if (PgArchPID != 0)
signal_child(PgArchPID, SIGQUIT);
if (PgStatPID != 0)
signal_child(PgStatPID, SIGQUIT);
}
}
}
}
//The pmdie function and state machine function won't create PM_SHUTDOWN_2 state, but reaper will
//When reaper handles checkpointer exit, it sets pmState = PM_SHUTDOWN_2; at the end of reaper, it enters the state machine function, which is here
if (pmState == PM_SHUTDOWN_2)
{
/*
* PM_SHUTDOWN_2 state ends when there's no other children than
* dead_end children left. There shouldn't be any regular backends
* left by now anyway; what we're really waiting for is walsenders and
* archiver.
*/
//PM_SHUTDOWN_2 essentially waits for walsender and archiver
//only changes pmState
if (PgArchPID == 0 && CountChildren(BACKEND_TYPE_ALL) == 0)
{
pmState = PM_WAIT_DEAD_END;
}
}
if (pmState == PM_WAIT_DEAD_END)
{
//PM_WAIT_DEAD_END means BackendList is completely empty
if (dlist_is_empty(&BackendList) &&
PgArchPID == 0 && PgStatPID == 0)
{
/* These other guys should be dead already */
Assert(StartupPID == 0);
Assert(WalReceiverPID == 0);
Assert(BgWriterPID == 0);
Assert(CheckpointerPID == 0);
Assert(WalWriterPID == 0);
Assert(AutoVacPID == 0);
/* syslogger is not considered here */
pmState = PM_NO_CHILDREN;
}
}
//PM_NO_CHILDREN is the last shutdown state, meaning normal shutdown can proceed
if (Shutdown > NoShutdown && pmState == PM_NO_CHILDREN)
{
if (FatalError)
{
ereport(LOG, (errmsg("abnormal database system shutdown")));
//Abnormal pm exit
ExitPostmaster(1);
}
...
//Normal pm exit
ExitPostmaster(0);
}
}
...
}reaper is the process reaping function. When a child process exits, it sends SIGCHLD to pm, and pm cleans up the process via the reaper function. Each process type — backend, startup, checkpointer, etc. — has its own cleanup flow.
Here we only look at checkpointer cleanup. Also, reaper has no cleanup logic for walsender:
if (pid == CheckpointerPID)
{
CheckpointerPID = 0;
//Checkpointer exited normally, and pmState is PM_SHUTDOWN: waiting for checkpoint completion
if (EXIT_STATUS_0(exitstatus) && pmState == PM_SHUTDOWN)
{
/*
* OK, we saw normal exit of the checkpointer after it's been
* told to shut down. We expect that it wrote a shutdown
* checkpoint. (If for some reason it didn't, recovery will
* occur on next postmaster start.)
*
* At this point we should have no normal backend children
* left (else we'd not be in PM_SHUTDOWN state) but we might
* have dead_end children to wait for.
*
* If we have an archiver subprocess, tell it to do a last
* archive cycle and quit. Likewise, if we have walsender
* processes, tell them to send any remaining WAL and quit.
*/
Assert(Shutdown > NoShutdown);
//Wake archiver for the last time
if (PgArchPID != 0)
signal_child(PgArchPID, SIGUSR2); //pgarch SIGUSR2=pgarch_waken_stop
//Wake walsender for the last time
SignalChildren(SIGUSR2);//walsender SIGUSR2=WalSndLastCycleHandler
//Here PM_SHUTDOWN_2 is set
//At this point Checkpointer has exited normally; we should wait for pgarch and walsender to finish their last task
//This is PM_SHUTDOWN_2 state
pmState = PM_SHUTDOWN_2;
...
}
else
{
//checkpointer abnormal exit is considered a crash
HandleChildCrash(pid, exitstatus,
_("checkpointer process"));
}
continue;
}
...
//At the end reaper still enters the state machine function
PostmasterStateMachine();
...
}Checkpointer and Walsender Process Exit#
Checkpointer main loop handling requests and shutdown:
void
CheckpointerMain(void)
{
/*
* Loop forever
*/
for (;;)
{
bool do_checkpoint = false;
int flags = 0;
pg_time_t now;
int elapsed_secs;
int cur_timeout;
/* Clear any already-pending wakeups */
ResetLatch(MyLatch);
/*
* Process any requests or signals received recently.
*/
//Process recent sync requests and signals
AbsorbSyncRequests();
HandleCheckpointerInterrupts();Checkpointer shutdown function:
/*
* Process any new interrupts.
*/
static void
HandleCheckpointerInterrupts(void)
{
...
if (ShutdownRequestPending)
{
/*
* From here on, elog(ERROR) should end with exit(1), not send control
* back to the sigsetjmp block above
*/
ExitOnAnyError = true;
ShutdownXLOG(0, 0);//This writes the shutdown checkpoint
proc_exit(0);//Normal exit code 0
}
}Checkpointer exit needs to wait for ShutdownXLOG to complete.
ShutdownXLOG:
/*
* This must be called ONCE during postmaster or standalone-backend shutdown
*/
void
ShutdownXLOG(int code, Datum arg)
{
...
//Here's the checkpointer "shutting down" log, usually always seen
ereport(IsPostmasterEnvironment ? LOG : NOTICE,
(errmsg("shutting down")));
/*
* Signal walsenders to move to stopping state.
*/
//Initialize walsender stopping
WalSndInitStopping();
//Wait for all walsenders to be in stopping state
WalSndWaitStopping();
if (RecoveryInProgress())
CreateRestartPoint(CHECKPOINT_IS_SHUTDOWN | CHECKPOINT_IMMEDIATE);
else
{
/*
* If archiving is enabled, rotate the last XLOG file so that all the
* remaining records are archived (postmaster wakes up the archiver
* process one more time at the end of shutdown). The checkpoint
* record will go to the next XLOG file and won't be archived (yet).
*/
if (XLogArchivingActive() && XLogArchiveCommandSet())
RequestXLogSwitch(false);
//This is the shutdown checkpoint creation function
CreateCheckPoint(CHECKPOINT_IS_SHUTDOWN | CHECKPOINT_IMMEDIATE);
}
ShutdownCLOG();
ShutdownCommitTs();
ShutdownSUBTRANS();
ShutdownMultiXact();
}Checkpointer notifies all walsenders to begin stopping:
/*
* Signal all walsenders to move to stopping state.
*
* This will trigger walsenders to move to a state where no further WAL can be
* generated. See this file's header for details.
*/
void
WalSndInitStopping(void)
{
int i;
for (i = 0; i < max_wal_senders; i++)
{
WalSnd *walsnd = &WalSndCtl->walsnds[i];
pid_t pid;
SpinLockAcquire(&walsnd->mutex);
pid = walsnd->pid;
SpinLockRelease(&walsnd->mutex);
if (pid == 0)
continue;
SendProcSignal(pid, PROCSIG_WALSND_INIT_STOPPING, InvalidBackendId);
}
}Walsender receives the signal via the SendProcSignal function, with signal SIGUSR1:
/*
* SendProcSignal
* Send a signal to a Postgres process
*
* Providing backendId is optional, but it will speed up the operation.
*
* On success (a signal was sent), zero is returned.
* On error, -1 is returned, and errno is set (typically to ESRCH or EPERM).
*
* Not to be confused with ProcSendSignal
*/
int
SendProcSignal(pid_t pid, ProcSignalReason reason, BackendId backendId)
{
else
{
/*
* BackendId not provided, so search the array using pid. We search
* the array back to front so as to reduce search overhead. Passing
* InvalidBackendId means that the target is most likely an auxiliary
* process, which will have a slot near the end of the array.
*/
int i;
for (i = NumProcSignalSlots - 1; i >= 0; i--)
{
slot = &ProcSignal->psh_slot[i];
if (slot->pss_pid == pid)
{
/* the above note about race conditions applies here too */
/* Atomically set the proper flag */
slot->pss_signalFlags[reason] = true;
/* Send signal */
return kill(pid, SIGUSR1);
}
}
}
errno = ESRCH;
return -1;
}Walsender’s SIGUSR1 registration:
pqsignal(SIGUSR1, procsignal_sigusr1_handler);
pqsignal(SIGUSR2, WalSndLastCycleHandler); /* request a last cycle and
* shutdown */sigusr1 classifies handling by signal reason:
/*
* procsignal_sigusr1_handler - handle SIGUSR1 signal.
*/
void
procsignal_sigusr1_handler(SIGNAL_ARGS)
{
...
if (CheckProcSignal(PROCSIG_WALSND_INIT_STOPPING))
HandleWalSndInitStopping();
...
}The handler for PROCSIG_WALSND_INIT_STOPPING is HandleWalSndInitStopping:
/*
* Handle PROCSIG_WALSND_INIT_STOPPING signal.
*/
void
HandleWalSndInitStopping(void)
{
Assert(am_walsender);
/*
* If replication has not yet started, die like with SIGTERM. If
* replication is active, only set a flag and wake up the main loop. It
* will send any outstanding WAL, wait for it to be replicated to the
* standby, and then exit gracefully.
*/
if (!replication_active)
kill(MyProcPid, SIGTERM);
else
got_STOPPING = true;//If walsender is active, initstopping just sets a flag for the main loop to handle
}The “main loop” mentioned in the comment is somewhat ambiguous. Walsender has a main loop ServerLoop, but in reality only the loop in WalSndWaitForWal has checks for got_STOPPING.
The WalSndWaitForWal function is the main loop for walsender waiting for new WAL records. Since WAL records are initially generated in memory, walwriter flushes them based on certain conditions, not all the time. WalSndWaitForWal compares the currently sent LSN with the flushed LSN to determine whether new WAL needs to be sent. In other words, unflushed WAL is not transmitted; only flushed WAL is passed downstream.
WalSndWaitForWal code segment about stopping:
/*
* Wait till WAL < loc is flushed to disk so it can be safely sent to client.
*
* Returns end LSN of flushed WAL. Normally this will be >= loc, but
* if we detect a shutdown request (either from postmaster or client)
* we will return early, so caller must always check.
*/
static XLogRecPtr
WalSndWaitForWal(XLogRecPtr loc)
{
...
for (;;)
{
...
//After receiving got_STOPPING, do one flush of WAL
//This is necessary! Because walwriter may have already shut down at this point, WAL may not be flushed yet
if (got_STOPPING)
XLogBackgroundFlush();
/* Update our idea of the currently flushed position. */
if (!RecoveryInProgress())
RecentFlushPtr = GetFlushRecPtr();
else
RecentFlushPtr = GetXLogReplayRecPtr(NULL);
//Break out of the for loop
//After getting new RecentFlushPtr, still need to send
if (got_STOPPING)
break;
...
}
/* reactivate latch so WalSndLoop knows to continue */
SetLatch(MyLatch);
return RecentFlushPtr;
}Back to walsender main loop: WalSndLoop(XLogSendLogical):
/* Main loop of walsender process that streams the WAL over Copy messages. */
static void
WalSndLoop(WalSndSendDataCallback send_data)
{
...
for (;;)
{
/* Clear any already-pending wakeups */
ResetLatch(MyLatch);
...
//Process replies from downstream
ProcessRepliesIfAny();
/*
* If we have received CopyDone from the client, sent CopyDone
* ourselves, and the output buffer is empty, it's time to exit
* streaming.
*/
//Exit loop when streaming is done
if (streamingDoneReceiving && streamingDoneSending &&
!pq_is_send_pending())
break;
//If output buffer has pending data, send it
if (!pq_is_send_pending())
send_data();
else
WalSndCaughtUp = false;
/* Try to flush pending output to the client */
if (pq_flush_if_writable() != 0)
WalSndShutdown();//Downstream not writable, downstream closed, normal walsender shutdown, exit code 0
/* If nothing remains to be sent right now ... */
if (WalSndCaughtUp && !pq_is_send_pending())
{
/*
* If we're in catchup state, move to streaming. This is an
* important state change for users to know about, since before
* this point data loss might occur if the primary dies and we
* need to failover to the standby. The state change is also
* important for synchronous replication, since commits that
* started to wait at that point might wait for some time.
*/
//Data transmission is done, but commit info still needs to be sent
if (MyWalSnd->state == WALSNDSTATE_CATCHUP)
{
ereport(DEBUG1,
(errmsg("\"%s\" has now caught up with upstream server",
application_name)));
WalSndSetState(WALSNDSTATE_STREAMING);
}
//Received SIGUSR2, meaning shutdown checkpoint is done.
//Send the shutdown checkpoint record, wait for completion, then exit
if (got_SIGUSR2)
WalSndDone(send_data);//exit code 0
}
...
}
}Let’s return to checkpointer’s ShutdownXLOG logic. The above only analyzed WalSndInitStopping(). After this signal is sent to walsender, WalSndWaitStopping executes to wait for walsender.
As long as any walsender hasn’t exited, this is an infinite loop that won’t return:
/*
* Wait that all the WAL senders have quit or reached the stopping state. This
* is used by the checkpointer to control when the shutdown checkpoint can
* safely be performed.
*/
void
WalSndWaitStopping(void)
{
for (;;)
{
int i;
bool all_stopped = true;
for (i = 0; i < max_wal_senders; i++)
{
WalSnd *walsnd = &WalSndCtl->walsnds[i];
SpinLockAcquire(&walsnd->mutex);
if (walsnd->pid == 0)
{
SpinLockRelease(&walsnd->mutex);
continue;
}
if (walsnd->state != WALSNDSTATE_STOPPING)
{
all_stopped = false;
SpinLockRelease(&walsnd->mutex);
break;
}
SpinLockRelease(&walsnd->mutex);
}
/* safe to leave if confirmation is done for all WAL senders */
if (all_stopped)
return;
pg_usleep(10000L); /* wait for 10 msec */
}
}Finally, combined with the comments in walsender.c:
* If the server is shut down, checkpointer sends us
* PROCSIG_WALSND_INIT_STOPPING after all regular backends have exited. If
* the backend is idle or runs an SQL query this causes the backend to
* shutdown, if logical replication is in progress all existing WAL records
* are processed followed by a shutdown. Otherwise this causes the walsender
* to switch to the "stopping" state. In this state, the walsender will reject
* any further replication commands. The checkpointer begins the shutdown
* checkpoint once all walsenders are confirmed as stopping. When the shutdown
* checkpoint finishes, the postmaster sends us SIGUSR2. This instructs
* walsender to send any outstanding WAL, including the shutdown checkpoint
* record, wait for it to be replicated to the standby, and then exit.- After all regular backends have exited, checkpointer sends
PROCSIG_WALSND_INIT_STOPPINGto walsenders - Walsender may enter the stopping state
- Only after all walsenders enter stopping state does checkpointer perform the shutdown checkpoint
- After the shutdown checkpoint completes, pm sends
SIGUSR2to walsender, which sends any remaining WAL including the shutdown checkpoint record itself, waits for standby to complete, then exits
Shutdown Flow Diagram#
After going through the source code, it felt like I understood but also didn’t — needed a shutdown flowchart to clarify.
Summary of the fast shutdown flow:
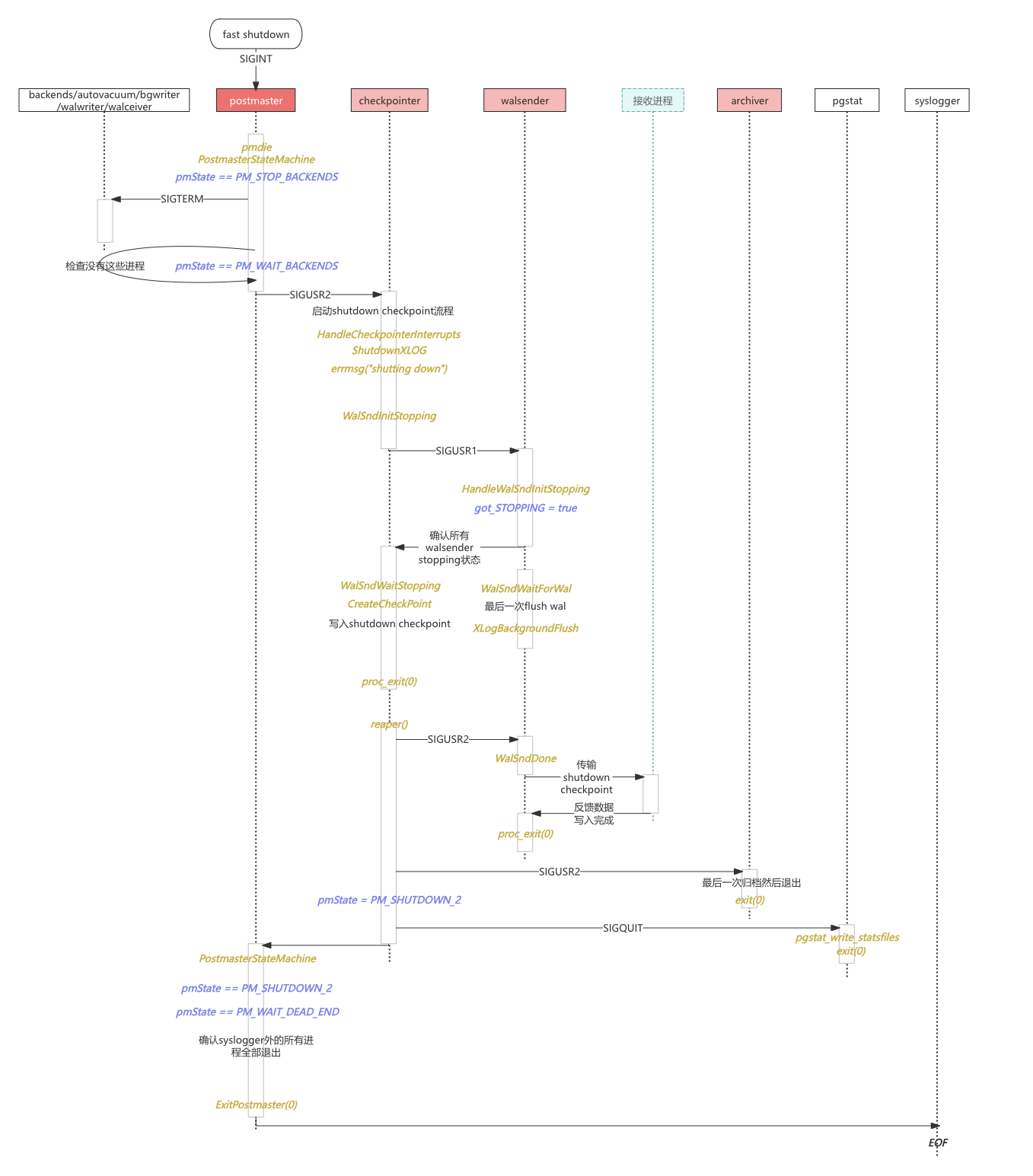
(High resolution: https://www.processon.com/view/link/6778a73a04a8344b9502637a)
- PG manages shutdown logic through signals, per-process main loops, PM state machine, and the pmdie process reaping function
- Also note: signals themselves are asynchronous. If you need to wait for the result of signal processing in a target process, you typically need other synchronization mechanisms (pipes, semaphores, shared memory, etc.). PG mainly relies on process dependencies and whether processes exit normally to determine if signals were properly handled.
- pgarch and walsender are treated as the same type of process, handled differently from others (walwriter, bgwriter). pgarch and walsender need to do an additional “last task”. The signal for the “last task” is typically defined as SIGUSR2.
- Checkpointer’s normal exit depends on pgarch and walsender exiting normally.
- pgarch’s last task is the final archive. So archiving can affect shutdown.
- Walsender’s second-to-last task is delivering the final WAL, and its last task is delivering the checkpoint shutdown info. These tasks require downstream reply messages, so walsender can affect shutdown.
Test Reproduction#
Test: Reproducing Walsender Blocking Shutdown#
After fast stop shutdown, walsender can block the shutdown.
Tested various scenarios to reproduce walsender blocking shutdown. Currently, the following conditions together make it easier to trigger abnormal shutdown:
- One walsender for publication/subscription
- One walsender for DTS
- Large number of subtransactions causing replication slot spill
This three-in-one scenario doesn’t represent the only scenario; it’s just one that was easier to reproduce after testing many.
--Reproduction commands (not extremely stable reproduction)
1.Create table
--pg
create table lzlpg(id bigserial primary key,a char(2000),b char(2000),c char(2000));
--oracle
create table lzl.lzloracle(id number primary key ,a char(2000),b char(2000),c char(2000)) tablespace FADATA;
2.Set up 2 logical replication links (1 pub/sub, 1 DTS to oracle)
3.Reduce logical_decoding_work_mem
logical_decoding_work_mem=1MB
4.Write large amounts of data (recommended: subtransaction spill)
--Insert one row at a time, each insert as a subtransaction
echo "begin;">subtx.sql
for i in {1..500000}
do
echo "savepoint p$i;">>subtx.sql
echo "insert into lzlpg(column1,column2,column3) select 'a','b','c';">>subtx.sql
done
nohup psql -d lzl -f subtx.sql &
5.Stop the database before writing completes
pg_ctl stop -D $PGDATA -m fastAt this point, with fast shutdown, the database is in an incomplete shutdown state:
~/lzl/slot]$ ps -axjf|grep 110402
150696 64964 64961 146782 pts/42 64961 S+ 6001 0:00 \_ grep --color=auto 110402
1 110402 110402 110402 ? -1 Ss 6001 0:00 /myhost/postgres/base/rasesql1.5.6/bin/postgres -D /myhost/pg8094/data
110402 110599 110599 110599 ? -1 Ss 6001 0:00 \_ postgres: lzlpg: logger
110402 117803 117803 117803 ? -1 Ss 6001 0:00 \_ postgres: lzlpg: checkpointer
110402 117807 117807 117807 ? -1 Ss 6001 0:00 \_ postgres: lzlpg: stats collector
110402 118563 118563 118563 ? -1 Rs 6001 3:29 \_ postgres: lzlpg: walsender lzl 127.0.0.1(62971) idle
110402 222918 222918 222918 ? -1 Rs 6001 2:59 \_ postgres: lzlpg: walsender dtssync 30.181.46.203(57218) idleWalsender, checkpointer, postmaster are all still there; logger and stats haven’t exited either.
The control file state is in production: meaning running in production, indicating the local shutdown checkpoint by checkpointer didn’t complete:
~/lzl/slot]$ pg_controldata|grep -i state
Database cluster state: in productionCheckpointer stack:
pstack 117803
#0 0x00002b879fe0b983 in __select_nocancel () from /lib64/libc.so.6
#1 0x00000000008fd04a in pg_usleep (microsec=microsec@entry=10000) at pgsleep.c:56
#2 0x00000000007610c8 in WalSndWaitStopping () at walsender.c:3209
#3 0x000000000051fa86 in ShutdownXLOG (code=code@entry=0, arg=arg@entry=0) at xlog.c:8596
#4 0x00000000007215ff in HandleCheckpointerInterrupts () at checkpointer.c:566
#5 CheckpointerMain () at checkpointer.c:343
...At this point, checkpointer is stuck in WalSndWaitStopping, meaning checkpointer is waiting for walsender processes to enter stopping state.
Walsender stack at this point:
#0 0x00000000007484fb in ReorderBufferLargestTXN (rb=<optimized out>) at reorderbuffer.c:2345
#1 ReorderBufferCheckMemoryLimit (rb=0x2b8808b94118) at reorderbuffer.c:2390
#2 ReorderBufferQueueChange (rb=0x2b8808b94118, xid=<optimized out>, lsn=1676456602544, change=change@entry=0x2b87a229f408) at reorderbuffer.c:649
#3 0x000000000073ec99 in DecodeTruncate (buf=<optimized out>, buf=<optimized out>, ctx=<optimized out>) at decode.c:872
#4 DecodeHeapOp (buf=0x7ffda7d35180, ctx=0x2b87a224b118) at decode.c:455
#5 LogicalDecodingProcessRecord (ctx=0x2b87a224b118, record=<optimized out>) at decode.c:126
#6 0x000000000075f502 in XLogSendLogical () at walsender.c:2886
#7 0x0000000000761822 in WalSndLoop (send_data=send_data@entry=0x75f4c0 <XLogSendLogical>) at walsender.c:2287
...Walsender is stuck in the transaction spill function. (Why it’s stuck is still unclear!!!)
Checkpointer process is blocked in WalSndWaitStopping:
/*
* Wait that all the WAL senders have quit or reached the stopping state. This
* is used by the checkpointer to control when the shutdown checkpoint can
* safely be performed.
*/
void
WalSndWaitStopping(void)
{
for (;;)
{
int i;
bool all_stopped = true;
for (i = 0; i < max_wal_senders; i++)
{
WalSnd *walsnd = &WalSndCtl->walsnds[i];
SpinLockAcquire(&walsnd->mutex);
if (walsnd->pid == 0)
{
SpinLockRelease(&walsnd->mutex);
continue;
}
if (walsnd->state != WALSNDSTATE_STOPPING)
{
all_stopped = false;
SpinLockRelease(&walsnd->mutex);
break;
}
SpinLockRelease(&walsnd->mutex);
}
/* safe to leave if confirmation is done for all WAL senders */
if (all_stopped)
return;
pg_usleep(10000L); /* wait for 10 msec */
}
}From the code and stack, it’s clear the condition walsnd->state != WALSNDSTATE_STOPPING is hit, causing the infinite loop.
Test: Handling the Mid-Shutdown State#
The above is an awkward mid-shutdown state. Besides kill -9, there are other better ways to achieve consistent shutdown:
- Solution 1: Shut down the downstream process
- Solution 2: Send
SIGTERMto walsender
Solution 1 test:
When the downstream exits, walsender will also exit:
static void
ProcessRepliesIfAny(void)
{...
/*
* 'X' means that the standby is closing down the socket.
*/
case 'X':
proc_exit(0);For pub/sub, execute the following on the subscriber side; even if the upstream is in mid-shutdown state, this will cause walsender to exit:
\c lzldb
alter SUBSCRIPTION sub_lzl disable;However, this depends on the downstream’s own handling; we can’t always quickly shut down the downstream receiver process of DTS and other sync tools.
Solution 2 test:
Since walsender registers the SIGTERM signal, and the select pg_terminate_backend($walsender_pid) command run while the database is running also sends SIGTERM to walsender, theoretically just sending SIGTERM to walsender should handle this, without needing kill -9.
Command:
kill -SIGTERM 62834
#same as kill -15 62834
#same as kill 62834After normal kill, pm and all other processes exit completely.
Check the control file and WAL log to confirm consistent shutdown:
- pg_controldata database state changed from
in productiontoshut down— consistent shutdown:
$ pg_controldata|grep -i state
Database cluster state: shut down- The last record in the WAL log is
CHECKPOINT_SHUTDOWN:
pg_waldump 000000010000018600000012|tail -1
pg_waldump: fatal: error in WAL record at 186/915D7920: invalid record length at 186/915D7998: wanted 24, got 0
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 186/915D7920, prev 186/915D78A8, desc: CHECKPOINT_SHUTDOWN redo 186/915D7920; tli 1; prev tli 1; fpw true; xid 0:13431045; oid 3808147; multi 3; offset 6; oldest xid 485 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 494/13431044; oldest running xid 0; shutdownTest: Reproducing Only Primary Having CHECKPOINT_SHUTDOWN#
A phenomenon in the production environment was that the local WAL had a shutdown checkpoint but the standby didn’t. In production, an immediate stop was performed during mid-shutdown, and then startup failed.
At the time, the last 2 WAL records on primary and standby looked something like:
#Primary WAL:
CHECKPOINT_ONLINE
CHECKPOINT_SHUTDOWN
#Standby WAL:
CHECKPOINT_ONLINEReproduction commands:
## 1. First reproduce walsender blocking shutdown
(skipped)
## 2. Check the last WAL record
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 188/307ABE00, prev 188/307ABDC8, desc: RUNNING_XACTS nextXid 13432445 latestCompletedXid 13432444 oldestRunningXid 13432445
## 3. pg_ctl stop -D $PGDATA -m i
## 4. Check last WAL record
Unchanged, same as 2
## 5. pg_ctl start -D $PGDATA
## 6. Check last two WAL records
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 188/307ABE00, prev 188/307ABDC8, desc: RUNNING_XACTS nextXid 13432445 latestCompletedXid 13432444 oldestRunningXid 13432445 #same as 2
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 188/307ABE38, prev 188/307ABE00, desc: CHECKPOINT_SHUTDOWN redo 188/307ABE38; tli 1; prev tli 1; fpw true; xid 0:13432445; oid 3832732; multi 3; offset 6; oldest xid 485 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 494/13432444; oldest running xid 0; shutdown #CHECKPOINT_SHUTDOWN appearsFrom this reproduction, CHECKPOINT_SHUTDOWN is actually done during startup!
This matches the production sequence: 1. fast shutdown didn’t complete 2. immediate shutdown 3. startup failed.
Question 1: When during startup is CHECKPOINT_SHUTDOWN done?
Question 2: When is CHECKPOINT_ONLINE triggered? From reproduction appearances, occasionally fast shutdown results in the last WAL record being CHECKPOINT_ONLINE.
Question 1 analysis:
Doing a shutdown checkpoint at startup easily suggests the startup process. Since we’ve previously analyzed the startup process flow, we can directly locate the function StartupXLOG:
/*
* This must be called ONCE during postmaster or standalone-backend startup
*/
void
StartupXLOG(void)
{...
if (InRecovery) //Since it was a shutdown stop, instance recovery is needed
{
/*
* Perform a checkpoint to update all our recovery activity to disk.
*
* Note that we write a shutdown checkpoint rather than an on-line
* one. This is not particularly critical, but since we may be
* assigning a new TLI, using a shutdown checkpoint allows us to have
* the rule that TLI only changes in shutdown checkpoints, which
* allows some extra error checking in xlog_redo.
*
* In fast promotion, only create a lightweight end-of-recovery record
* instead of a full checkpoint. A checkpoint is requested later,
* after we're fully out of recovery mode and already accepting
* queries.
*/
if (bgwriterLaunched) //This if is clearly for standby streaming replication
{...
}
else //Primary startup goes here
CreateCheckPoint(CHECKPOINT_END_OF_RECOVERY | CHECKPOINT_IMMEDIATE);
}- Doing a shutdown checkpoint is intentional, mainly for TLI logic code robustness
- Whenever it’s not a consistent shutdown, a shutdown checkpoint is performed during startup
So, doing -m i forced shutdown and then starting up will also produce CHECKPOINT_SHUTDOWN — self-tested.
Question 2 analysis:
Tested multiple times, occasionally seen. Speculation: it just happened that before shutdown, checkpoint conditions were met and an online checkpoint was triggered — pure coincidence.
Considering that after a failed database shutdown, whether it’s a script, HA, or manual intervention, forced shutdown may be done, it’s recommended to do at least one checkpoint before shutdown.
Test: Impact of Archiving on Shutdown#
While analyzing the shutdown code, I also found that after the checkpointer process exits, reaper for checkpointer sends SIGUSR2 to pgarch for its last archive and exit:
static void
reaper(SIGNAL_ARGS)
{...
if (pid == CheckpointerPID)
{
CheckpointerPID = 0;
if (EXIT_STATUS_0(exitstatus) && pmState == PM_SHUTDOWN)
{...
/* Waken archiver for the last time */
if (PgArchPID != 0)
signal_child(PgArchPID, SIGUSR2);
...
}
...And pm’s exit depends on all processes except syslogger having exited:
if (pmState == PM_WAIT_DEAD_END)
{
if (dlist_is_empty(&BackendList) &&
PgArchPID == 0 && PgStatPID == 0)
{
/* These other guys should be dead already */
Assert(StartupPID == 0);
Assert(WalReceiverPID == 0);
Assert(BgWriterPID == 0);
Assert(CheckpointerPID == 0);
Assert(WalWriterPID == 0);
Assert(AutoVacPID == 0);
/* syslogger is not considered here */
pmState = PM_NO_CHILDREN;
}
}So in production, slow archiving was also found to affect shutdown.
Reproduction commands:
#Configure archiving
archive_mode = on
archive_command = '/bin/false ;sleep 1000'#Set archiving to always fail with sleep to bypass NUM_ARCHIVE_RETRIES logic
#Shutdown
pg_ctl stop -D $PGDATA -m fastProcesses after shutdown:
$ ps -axjf|grep 61470
72200 88406 88405 68705 pts/48 88405 S+ 6001 0:00 \_ grep --color=auto 61470
1 61470 61470 61470 ? -1 Ss 6001 0:00 /myhost/postgres/base/rasesql1.5.6/bin/postgres -D /myhost/pg8094/data
61470 61772 61772 61772 ? -1 Ss 6001 0:00 \_ postgres: lzlpg: logger
61470 63880 63880 63880 ? -1 Ss 6001 0:00 \_ postgres: lzlpg: archiver archiving 000000010000018800000007Since the checkpointer here has already fully stopped, the database is in a consistent state, so using kill -9 on archiver is fine.
One-Sentence Summary#
Q1: Why didn’t shutdown complete?
Walsender blocked shutdown. Checkpointer sent SIGUSR1 to walsender and infinitely waited for all walsender processes to enter stopping state; checkpointer got stuck at this step.
The shutdown eventually completed due to -m i forced shutdown.
Q2: Is there a graceful way to shut down from the mid-shutdown state caused by walsender blocking?
Yes. Send SIGTERM (i.e. kill, or kill -15, kill -SIGTERM) to all walsenders. Afterwards, checkpointer and postmaster will complete a clean shutdown.
Walsender registers the SIGTERM signal at startup, and testing shows no scenario where it can’t be handled.
SIGTERM is also the signal sent by pg_terminate_backend(pid), and it’s the command that should be executed to stop walsender during a standard shutdown.
Q3: Why did primary and standby differ by exactly one shutdown checkpoint?
3.1 Explanation for both primary and standby having CHECKPOINT_ONLINE:
- The primary triggering
CHECKPOINT_ONLINEwas purely coincidental - Since the physical walsender was still there, this WAL record was transmitted to the standby
3.2 Explanation for only primary having CHECKPOINT_SHUTDOWN:
- This
CHECKPOINT_SHUTDOWNwas done during primary startup - Since the primary hadn’t fully started, this WAL record wasn’t transmitted to the standby
Q4: Why does archiver block shutdown?
When reaping the checkpointer process, pm tells archiver to do one last archive, and pm depends on all processes except syslogger having exited. So if the last archive is slow or has issues, it blocks shutdown. Archive failure won’t — the archiver process exits quickly on failure.
Q5: Which processes can block shutdown?
Actually, any process not exiting can block shutdown. The question is which ones are more likely to cause trouble. From the shutdown code flow, archiver and walsender commonly block shutdown because they perform a last archive or log transmission during the shutdown phase.
References#
https://www.postgresql.org/docs/current/server-shutdown.html https://wiki.postgresql.org/wiki/Signals postgres.c postmaster.c walsender.c xlog.c checkpointer.c startup.c pgarch.c