Problem Description#
PostgreSQL UPDATE statement throws error: too many range table entries
Original SQL:
with t as (select id from LZLTAB where id=8723 limit 100 )
update LZLTAB set
STATUS = '00',
FILE_ID = null,
DATE_UPDATED = localtimestamp(0)
where id in (select id from t)If we rewrite UPDATE as SELECT, it succeeds:
with t as (select id from LZLTAB where id=8723 limit 100 )
select * from LZLTAB where id in (select id from t)
id | date_created
------+----------------------------+...
8723 | 2023-06-21 18:02:21.161687
(1 row) Primary key and partitions — 400 partitions total:
Partition key: RANGE (partition_key)
Indexes:
"pk_lzl" PRIMARY KEY, btree (id, partition_key)
...
Partitions: lzl_p20230601 FOR VALUES FROM ('20230601') TO ('20230602'),
lzl_p20230602 FOR VALUES FROM ('20230602') TO ('20230603'),
lzl_p20230603 FOR VALUES FROM ('20230603') TO ('20230604')The SQL logic has many optimization opportunities, but we won’t discuss those here. The focus is on why UPDATE fails and why SELECT and UPDATE behave differently.
EXPLAIN UPDATE throws this error:
explain with t as (selec tid from LZLTAB where id=8723 limit 100 )
update LZLTAB set
STATUS = '00',
FILE_ID = null,
DATE_UPDATED = localtimestamp(0)
where id in (select id from t);
ERROR: 54000: too many range table entries
LOCATION: add_rte_to_flat_rtable, setrefs.c:451
Time: 18341.171 ms (00:18.341)EXPLAIN took 18 seconds, then threw the error.
Source Code Analysis#
The error directly points to the source location: LOCATION: add_rte_to_flat_rtable, setrefs.c:451
Find the source at src/backend/optimizer/plan/setrefs.c.
The comment explains that setrefs.c handles post-processing of a completed plan tree:
/*
*Post-processing of a completed plan tree: fix references to subplan
* vars, compute regproc values for operators, etc
*/Find the function at line 451:
/*
* Add (a copy of) the given RTE to the final rangetable
*
* In the flat rangetable, we zero out substructure pointers that are not
* needed by the executor; this reduces the storage space and copying cost
* for cached plans. We keep only the ctename, alias and eref Alias fields,
* which are needed by EXPLAIN, and the selectedCols, insertedCols,
* updatedCols, and extraUpdatedCols bitmaps, which are needed for
* executor-startup permissions checking and for trigger event checking.
*/
static void
add_rte_to_flat_rtable(PlannerGlobal *glob, RangeTblEntry *rte)
{
...
/*
* Check for RT index overflow; it's very unlikely, but if it did happen,
* the executor would get confused by varnos that match the special varno
* values.
*/
if (IS_SPECIAL_VARNO(list_length(glob->finalrtable)))
ereport(ERROR,
(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
errmsg("too many range table entries")));
...
}errmsg() is at line 451. From the comments, add_rte_to_flat_rtable() is related to RTE. What is RTE? We’ll analyze below.
The error check uses IS_SPECIAL_VARNO(). Searching for this macro in src/include/nodes/primnodes.h:
/*
* Var - expression node representing a variable (ie, a table column)
*
* In the parser and planner, varno and varattno identify the semantic
* referent, which is a base-relation column unless the reference is to a join
* USING column that isn't semantically equivalent to either join input column
* (because it is a FULL join or the input column requires a type coercion).
* In those cases varno and varattno refer to the JOIN RTE. (Early in the
* planner, we replace such join references by the implied expression; but up
* till then we want join reference Vars to keep their original identity for
* query-printing purposes.)
...
*/
#define INNER_VAR 65000 /* reference to inner subplan */
#define OUTER_VAR 65001 /* reference to outer subplan */
#define INDEX_VAR 65002 /* reference to index column */
#define IS_SPECIAL_VARNO(varno) ((varno) >= INNER_VAR)The comment above is a bit dense, but one phrase is key: In those cases varno and varattno refer to the JOIN RTE. varno is related to RTE.
When varno>=65000, the error is thrown. (We won’t go into the differences between INNER_VAR, OUTER_VAR, and INDEX_VAR here since their values are close and don’t affect the analysis.)
What is RTE?
Descriptions of RTE (rangetable or RangeTblEntry) can be found throughout the execution plan source code, and the error is clear: ERROR: 54000: too many range table entries — it’s about RTE. So what is RTE?
In src/include/nodes/parsenodes.h, there’s a description of RTE:
/*--------------------
* RangeTblEntry -
* A range table is a List of RangeTblEntry nodes.
*
* A range table entry may represent a plain relation, a sub-select in
* FROM, or the result of a JOIN clause. (Only explicit JOIN syntax
* produces an RTE, not the implicit join resulting from multiple FROM
* items. This is because we only need the RTE to deal with SQL features
* like outer joins and join-output-column aliasing.) Other special
* RTE types also exist, as indicated by RTEKind.
*
* Note that we consider RTE_RELATION to cover anything that has a pg_class
* entry. relkind distinguishes the sub-cases.
*/Simply put, an RTE is a “table” in the execution plan — it can be a concrete table or a generated “table” like a subquery, join result, etc. The RTE limit of 65000 means too many RTEs were generated in the execution plan.
Viewing the UPDATE Execution Plan#
Since we now know what RTE is, looking at the SQL execution plan may help. But since the original SQL (400 partitions) couldn’t generate an execution plan, let’s create a 30-partition table and hopefully EXPLAIN it to observe the plan.
30-partition table with the same UPDATE statement:
explain with t as (select id from lzl where id=8723 limit 100 )
update lzl set
STATUS = '00',
FILE_ID = null,
DATE_UPDATED = localtimestamp(0)
where id in ( select id from t);Generated execution plan:
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Update on lzl (cost=155.48..4980.00 rows=600 width=3042)
Update on lzl_p20230601 lzl_1
Update on lzl_p20230602 lzl_2
...
Update on lzl_p20230630 lzl_30
-> Hash Semi Join (cost=155.48..166.00 rows=20 width=3042)
Hash Cond: (lzl_1.id = t.id)
-> Seq Scan on lzl_p20230601 lzl_1 (cost=0.00..10.20 rows=20 width=2912)
-> Hash (cost=155.10..155.10 rows=30 width=40)
-> Subquery Scan on t (cost=0.14..155.10 rows=30 width=40)
-> Limit (cost=0.14..154.80 rows=30 width=8)
-> Append (cost=0.14..154.80 rows=30 width=8)
-> Index Only Scan using lzl_p20230601_pkey on lzl_p20230601 lzl_32 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
-> Index Only Scan using lzl_p20230602_pkey on lzl_p20230602 lzl_33 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
...
-> Index Only Scan using lzl_p20230630_pkey on lzl_p20230630 lzl_61 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
...
-> Hash Semi Join (cost=155.48..166.00 rows=20 width=3042)
Hash Cond: (lzl_30.id = t_29.id)
-> Seq Scan on lzl_p20230630 lzl_30 (cost=0.00..10.20 rows=20 width=2912)
-> Hash (cost=155.10..155.10 rows=30 width=40)
-> Subquery Scan on t_29 (cost=0.14..155.10 rows=30 width=40)
-> Limit (cost=0.14..154.80 rows=30 width=8)
-> Append (cost=0.14..154.80 rows=30 width=8)
-> Index Only Scan using lzl_p20230601_pkey on lzl_p20230601 lzl_931 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
-> Index Only Scan using lzl_p20230602_pkey on lzl_p20230602 lzl_932 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
...
-> Index Only Scan using lzl_p20230630_pkey on lzl_p20230630 lzl_960 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
(2041 rows)The execution plan is extremely long — 2041 rows in total. This plan is very inefficient: every time a partition is updated, the predicate conditions are run against the partitioned table all over again. Since the SQL lacks a partition key, each run scans all partitions. For a 30-partition table, each partition is scanned 30 times, totaling 900 partition scans.
From the execution plan, we can see that initially 30 RTEs were allocated for UPDATE up to lzl_30. Then each hash match per partition scan also allocated 30 RTEs — for example, the hash under lzl_1 has partition scans from lzl_32 to lzl_61. Why 32 instead of 31? Because the entire partition scan is a subquery and also an RTE, named t (and t, t1-t_29), totaling 30. So the total RTEs generated in the plan are 30+30+30×30=960.
Looking at the SELECT execution plan, it’s very different from UPDATE:
explain with t as (select id from lzl where id=8723 limit 100 )
select STATUS ,FILE_ID ,DATE_UPDATED from lzl where id in ( select id from t); Hash Semi Join (cost=155.48..467.05 rows=90 width=98)
Hash Cond: (lzl.id = lzl_31.id)
-> Append (cost=0.00..309.00 rows=600 width=106)
-> Seq Scan on lzl_p20230601 lzl_1 (cost=0.00..10.20 rows=20 width=106)
-> Seq Scan on lzl_p20230602 lzl_2 (cost=0.00..10.20 rows=20 width=106)
...
-> Seq Scan on lzl_p20230630 lzl_30 (cost=0.00..10.20 rows=20 width=106)
-> Hash (cost=155.10..155.10 rows=30 width=8)
-> Limit (cost=0.14..154.80 rows=30 width=8)
-> Append (cost=0.14..154.80 rows=30 width=8)
-> Index Only Scan using lzl_p20230601_pkey on lzl_p20230601 lzl_32 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
-> Index Only Scan using lzl_p20230602_pkey on lzl_p20230602 lzl_33 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
...
-> Index Only Scan using lzl_p20230630_pkey on lzl_p20230630 lzl_61 (cost=0.14..5.16 rows=1 width=8)
Index Cond: (id = 8723)
(96 rows)No repeated (Cartesian product-style) table access — RTEs only go up to 61. This is also why SELECT succeeds on 400 partitions, because 400×400 accesses is simply too many.
So regarding the original SQL where UPDATE fails and SELECT succeeds, we can conclude:
- For 400 partitions with SELECT, the execution plan has 801 RTEs, which doesn’t exceed
INNER_VAR(65000), so it can generate a plan and execute. - For 400 partitions with UPDATE, the execution plan has 160,160,400 RTEs, far exceeding
INNER_VAR(65000), so the plan cannot be generated and throws the RTE overflow error.
The cause is mostly analyzed, but the significant difference between SELECT and UPDATE plans is still puzzling. Let’s compare Oracle and MySQL execution plans horizontally.
Oracle Behavior#
Oracle partitioned table with local index:
CREATE TABLE lzl (
id number NOT NULL,
partition_key number DEFAULT 0 NOT NULL,
...
)
PARTITION BY RANGE (partition_key)
(
PARTITION lzl_p20230601 VALUES LESS THAN ('20230602'),
PARTITION lzl_p20230602 VALUES LESS THAN ('20230603'),
...
PARTITION lzl_p20230630 VALUES LESS THAN ('20230631'));
create index PKLZL on lzl(id, partition_key) local;
alter table lzl add constraint pklzl primary key (id, partition_key) using index pklzl;Execution plan:
with t as (select id from lzl where id=8723 and rownum<= 100 )
select STATUS ,FILE_ID ,DATE_UPDATED from lzl where id in ( select id from t)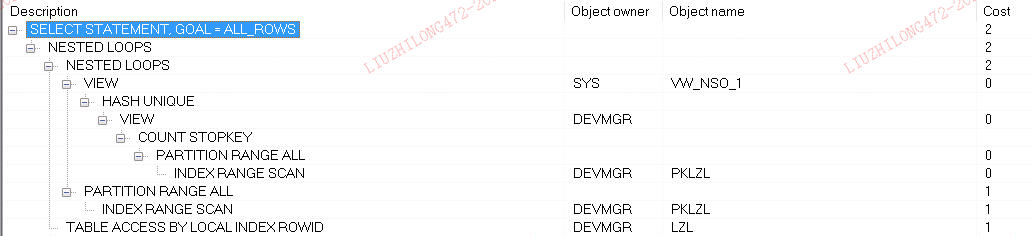
update lzl set
STATUS = '00',
FILE_ID = null,
DATE_UPDATED = sysdate
where id in (select id from lzl where id=8723 and rownum<= 100)
In Oracle, both SELECT and UPDATE use NESTED LOOP, accessing all partitions (PARTITION RANGE ALL). So in Oracle, regardless of SELECT or UPDATE, table t is the driving table. Because of IN, results are sorted and deduplicated. So Oracle’s plan is not 30×30 accesses but depends on the result set size in the driving table — n rows means n×30 partition accesses. Since driving table t has minimal data, this plan is fine.
MySQL Behavior#
Since MySQL only supports local indexes, just create the primary key directly:
CREATE TABLE test (
id bigint NOT NULL,
date_created timestamp ,
...
)
PARTITION BY RANGE (partition_key)
(
PARTITION lzl_p20230601 VALUES LESS THAN (20230602),
PARTITION lzl_p20230602 VALUES LESS THAN (20230603),
...
PARTITION lzl_p20230630 VALUES LESS THAN (20230631));
alter table lzl add primary key pklzl(id,partition_key);MySQL starting from 5.7 shows which partitions are scanned in the execution plan (version 8.0 here).
SELECT plan:
> explain with t as (select id from lzl where id=8723 limit 100 )
-> select STATUS ,FILE_ID ,DATE_UPDATED from lzl where id in ( select id from t);
+----+-------------+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+---------------+---------+---------+-------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+---------------+---------+---------+-------+------+----------+-----------------+
| 1 | PRIMARY | <derived3> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | Start temporary |
| 1 | PRIMARY | lzl | lzl_p20230601,lzl_p20230602,lzl_p20230603,lzl_p20230604,lzl_p20230605,lzl_p20230606,lzl_p20230607,lzl_p20230608,lzl_p20230609,lzl_p20230610,lzl_p20230611,lzl_p20230612,lzl_p20230613,lzl_p20230614,lzl_p20230615,lzl_p20230616,lzl_p20230617,lzl_p20230618,lzl_p20230619,lzl_p20230620,lzl_p20230621,lzl_p20230622,lzl_p20230623,lzl_p20230624,lzl_p20230625,lzl_p20230626,lzl_p20230627,lzl_p20230628,lzl_p20230629,lzl_p20230630 | ref | PRIMARY | PRIMARY | 8 | t.id | 1 | 100.00 | End temporary |
| 3 | DERIVED | lzl | lzl_p20230601,lzl_p20230602,lzl_p20230603,lzl_p20230604,lzl_p20230605,lzl_p20230606,lzl_p20230607,lzl_p20230608,lzl_p20230609,lzl_p20230610,lzl_p20230611,lzl_p20230612,lzl_p20230613,lzl_p20230614,lzl_p20230615,lzl_p20230616,lzl_p20230617,lzl_p20230618,lzl_p20230619,lzl_p20230620,lzl_p20230621,lzl_p20230622,lzl_p20230623,lzl_p20230624,lzl_p20230625,lzl_p20230626,lzl_p20230627,lzl_p20230628,lzl_p20230629,lzl_p20230630 | ref | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | Using index |UPDATE plan:
> explain with t as (select id from lzl where id=8723 limit 100 )
-> update lzl set
-> STATUS = '00',
-> FILE_ID = null,
-> DATE_UPDATED = localtimestamp(0) where id in ( select id from t);
+----+-------------+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+---------------+---------+---------+-------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------+---------------+---------+---------+-------+------+----------+-----------------+
| 1 | PRIMARY | <derived3> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | Start temporary |
| 1 | UPDATE | lzl | lzl_p20230601,lzl_p20230602,lzl_p20230603,lzl_p20230604,lzl_p20230605,lzl_p20230606,lzl_p20230607,lzl_p20230608,lzl_p20230609,lzl_p20230610,lzl_p20230611,lzl_p20230612,lzl_p20230613,lzl_p20230614,lzl_p20230615,lzl_p20230616,lzl_p20230617,lzl_p20230618,lzl_p20230619,lzl_p20230620,lzl_p20230621,lzl_p20230622,lzl_p20230623,lzl_p20230624,lzl_p20230625,lzl_p20230626,lzl_p20230627,lzl_p20230628,lzl_p20230629,lzl_p20230630 | ref | PRIMARY | PRIMARY | 8 | t.id | 1 | 100.00 | End temporary |
| 3 | DERIVED | lzl | lzl_p20230601,lzl_p20230602,lzl_p20230603,lzl_p20230604,lzl_p20230605,lzl_p20230606,lzl_p20230607,lzl_p20230608,lzl_p20230609,lzl_p20230610,lzl_p20230611,lzl_p20230612,lzl_p20230613,lzl_p20230614,lzl_p20230615,lzl_p20230616,lzl_p20230617,lzl_p20230618,lzl_p20230619,lzl_p20230620,lzl_p20230621,lzl_p20230622,lzl_p20230623,lzl_p20230624,lzl_p20230625,lzl_p20230626,lzl_p20230627,lzl_p20230628,lzl_p20230629,lzl_p20230630 | ref | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | Using index |MySQL’s two execution plans are identical. However, the driving table selection could be better — const should be the driving table to reduce scan count.
Bug?#
Bug Description#
https://postgrespro.com/list/thread-id/2482006
This bug is easy to find via the error. It was submitted by digoal (德哥) back in 2020, followed by discussion between two source code experts. The discussion is lengthy, but to summarize: PG does not support unlimited partitions, which is understandable in the real world — too many partitions can cause rapid performance degradation. However, the community still felt the limit needed adjustment and discussed the INNER_VAR, Var.varno values in the source code.
Misleading Nature#
The bug title is somewhat misleading: BUG #16302: too many range table entries - when count partition table(65538 childs)
The bug seems to say the number of partition child tables can’t exceed 65,538. The discussion also mentions PG can handle up to 64K relations in a query — a query cannot have more than 64K relations.
This is odd because our table has 400 partitions and still throws the error. In fact, both descriptions above are not entirely accurate. The 64K limit refers to the “tables” in the execution plan, which doesn’t exactly equal real tables. Of course, if tables or partitions exceed this count, there will be problems. But even without exceeding 64K, issues can arise, as in our case with only 400 partitions.
Fix#
The bug was submitted for version 12.2; our environment is 13.2.
This bug is fixed in PG15. The source in src/include/nodes/primnodes.h is different:
#define INNER_VAR (-1) /* reference to inner subplan */
#define OUTER_VAR (-2) /* reference to outer subplan */
#define INDEX_VAR (-3) /* reference to index column */
#define ROWID_VAR (-4) /* row identity column during planning */
#define IS_SPECIAL_VARNO(varno) ((int) (varno) < 0)As discussed in the community, PG15 not only changed VAR values to negative numbers but also converted varno to 32-bit (4 billion), compared to the previous 16-bit (65,536).
And in the function that previously threw the error, add_rte_to_flat_rtable() in src/backend/optimizer/plan/setrefs.c, the error code has been completely removed! The entire PG15 source code no longer contains too many range table entries!
Summary#
- PG still has room for improvement in partitioned table optimization. PG treats child partitions as regular tables, unlike Oracle and MySQL. Oracle treats child partitions as segments distinct from tables. This causes PG to output the access method for every partition in the execution plan (when pruning doesn’t occur), making plans extremely long when there are many partitions. Oracle just writes
PARTITION RANGE ALL. MySQL also prints all partitions but doesn’t treat each partition’s access as a subquery, reducing plan complexity. - Even when partitions haven’t reached 64K, you can still get
too many range table entries. This limit is actually on execution plan RTE count, not partition count (though if partition count reaches this number, RTE count will too, as mentioned — PG prints access methods for all partitions). - The
too many range table entrieserror is resolved in PG15. - For versions below 15, don’t create too many partitions! You can also leverage partition pruning to reduce accessed partitions — in this case, simply adding a partition key condition to the WHERE clause would work.