Index Splitting#
When an index block is nearly full, index splitting occurs. Index splitting comes in two forms: 55 and 91:
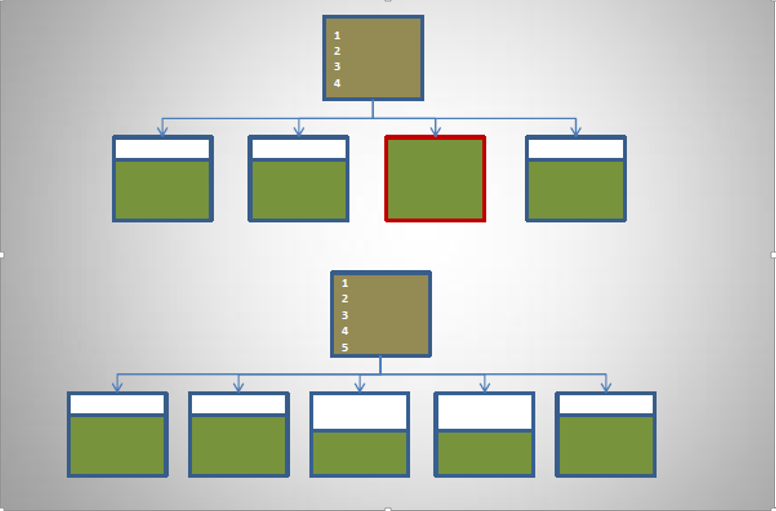
The difference between index splitting and the enq: TX - index contention wait event Whether 55 or 91 splitting, both are normal index behavior as data volume increases. Index splitting is a normal phenomenon caused by growing data volume leading to larger indexes — when an index can’t hold more data, it naturally needs more index blocks. There are hardly any scenarios with tables but no indexes (only during initial data loading would one consider inserting data first and building indexes afterward). Although index splitting consumes some resources, in today’s Oracle environments it can complete quickly. Only when there are too many indexes does it affect insert efficiency.
However, the enq: TX - index contention wait is NOT normal. enq: TX - index contention indicates that SQL statements are waiting on an index block that is currently being split. Essentially, DML concurrency is too high and all sessions are waiting on the splitting index block.
Why does enq: TX - index contention always occur on sequentially inserted columns? Although both 55 and 55 splits are possible in real scenarios, enq: TX - index contention frequently occurs with 91 splits. This is because columns like sequences and timestamps usually have indexes, and sequential inserts are common. The rightmost block is always the hot block, and subsequent inserts must wait for the split block to complete before they can proceed — this causes enq: TX - index contention. Why don’t UUID indexes cause enq: TX - index contention? Because UUID indexes are unordered — inserting causes UUID index splits, but it’s unlikely that subsequent UUID values also land on that same splitting index block. So UUID has index splitting but doesn’t form an enq wait queue leading to enq: TX - index contention.
Solutions#
Note: what we need to solve is the index split wait enq: TX - index contention, not index splitting itself. Solutions:
1. Reverse Index A reverse index stores key values in the opposite order. For example, for the value ‘1111 0001’, a normal index places it after ‘0000 0002’; with a reverse index, it’s placed before ‘0000 0002’. Think about a timestamp column — normally it’s a rightmost hot spot. After reversing, seconds, minutes, and hours sort first. One index block might contain data from different months but the same second. This way, the rightmost hot block essentially disappears — reverse indexes scatter hot spots across various index blocks. Limitations: Requires index modification; may lose index range scan capability. Sequentially growing columns cannot use index range scans (e.g., timestamp columns). In some scenarios, reverse key values might still work — requires specific analysis. Syntax:
CREATE INDEX reveridx ON tablzl (name) REVERSE;2. Hash-Partitioned Index Creating a hash-partitioned index on a regular table is equivalent to keeping the table unchanged but partitioning the index, thus scattering the rightmost hot block across partitions. For example, an 8-partition hash-partitioned index divides the index into 8 segments, creating 8 rightmost hot spots and alleviating the index split problem. Limitations: Requires index modification; affects index range query performance — requires balancing insert hot spot mitigation vs. query efficiency. Equality and IN queries can efficiently use hash-partitioned indexes. From the official documentation:
Queries involving equality and
INpredicates on index partitioning key can efficiently use global hash partitioned index to answer queries quickly
However, range scan efficiency decreases — the more partitions, the greater the decrease (though more partitions also provide better hot spot relief). This is clearly a balancing act. Tests show that with 8 partitions, logical reads for range scans increase nearly 8x. After partitioning, indexes within each partition remain ordered, and clustering factor differences are minor — the cost of scanning the index is similar, but the cost of table access increases. If a regular index has 8 entries in one block pointing to 1 data block (1 logical read), after hash partitioning across 8 partitions (1 index block each), it becomes 8 logical reads. This is why range scan index performance degrades. Syntax:
CREATE INDEX cust_last_name_ix ON customers (cust_last_name)
GLOBAL PARTITION BY HASH (cust_last_name)
PARTITIONS 4;3. Using Table Partitioning to Scatter Indexes Partition the table and create local indexes to scatter the rightmost hot spots. Limitations: The partition key cannot be the index column (otherwise it defeats the purpose); requires table modification; if existing SQL already has partition key predicates, range scan efficiency is not affected.
4. Reduce Concurrency Reducing concurrency is the ultimate weapon. Index split contention is fundamentally caused by excessively high concurrency — generally, without dozens of concurrent inserts, index split contention won’t occur.
5. Modify Index Block Size Place index blocks in 16K or 32K tablespaces. In theory, this should help because indexes can hold more data and splitting occurs less frequently. However, performance testing is needed, and other parameters may need adjustment.
6. Remove the Index Removing the index is also an option. Based on business requirements, if the index is not important, drop it. Or use range queries with partitioned tables, leveraging partition pruning instead of indexes.
Why These Approaches Don’t Work???#
- Increasing ITL transaction slots: Index block transaction slots may also be insufficient under high concurrency — this is indeed similar to index splitting, but the wait event is enq: TX - allocate ITL entry. If this wait is observed and traced to index blocks, it indicates high concurrency on the index. Reverse indexes and hash-partitioned indexes can also help, and adjusting initrans may solve the problem. However, the root causes of these two wait events differ — index splitting doesn’t always come with transaction slot issues.
- Adjusting index block PCTFREE: PCTFREE indicates that when a block’s free space falls below PCTFREE, it is no longer recorded in FREELIST and cannot accept new inserts. Consider two cases: increasing and decreasing PCTFREE. Increasing PCTFREE only worsens index splitting. Decreasing PCTFREE seems effective — similar to adjusting block size in principle — but in real scenarios PCTFREE defaults to 10%, which is already hard to reduce further, so the effect is negligible.
- Rebuilding indexes to reduce fragmentation: This is essentially unrelated — it doesn’t solve the rightmost hot block problem.
References#
https://blog.csdn.net/lihuarongaini/article/details/101299328 https://docs.oracle.com/cd/E11882_01/server.112/e41573/data_acc.htm#PFGRF94786
Acknowledgments: 豪桑, 用哥