Preface#
PostgreSQL Database Technology Summit Chengdu Stop#
Recently (June 17, 2023), the “PostgreSQL Database Technology Summit Chengdu Stop” organized by the PostgreSQL branch of the China Open Source Software Promotion Alliance was successfully held. I had the honor of participating as a speaker and gained a lot from it.

(Summit review and all PPT downloads: PPT downloads are here | PostgreSQL Technology Summit Chengdu Stop Review)
My Sharing#
My technical sharing topic was: Database History and SSI. I’ve noticed that many domestic technical blogs describe transactions inaccurately, which can confuse beginners. Additionally, many colleagues aren’t very familiar with transaction history and SSI in PostgreSQL. This time, I collected and summarized accurate definitions of transactions, transaction history, and SSI theoretical foundations from Wikipedia, official SQL standards, and various papers. The main thread of the sharing goes from transaction history to anomalies not present in the SQL-92 standard, to how these anomalies can be eliminated, gradually progressing to how SSI is implemented in PostgreSQL. The entire sharing is divided into 4 parts: Transaction Fundamentals, Transaction History, SSI Theoretical Knowledge, and SSI in PostgreSQL.
Transaction Fundamentals#
Before understanding transaction history and SSI, let’s review and revisit some basic transaction knowledge. The entire chapter will revolve around discussing transactions, and basic transaction knowledge will lead into the problems in transaction history.
What is a Transaction?#
Original meaning of transaction: A transaction is an exchange, a deal. Exchange is the original meaning of transaction, and what we call transactions in databases comes from this word. Database transaction: A transaction is the basic unit of work in a relational database. For example: Deleting data from table A and inserting data into table B — we can wrap these two actions into one transaction. Both must complete. But due to unexpected factors, the transaction might fail or be canceled halfway through execution. In that case, all operations in the entire transaction must roll back to the state before the transaction — A doesn’t delete and B doesn’t insert.
ACID#
ACID is an important characteristic of database transactions. It determines whether a transaction is reliable and trustworthy.
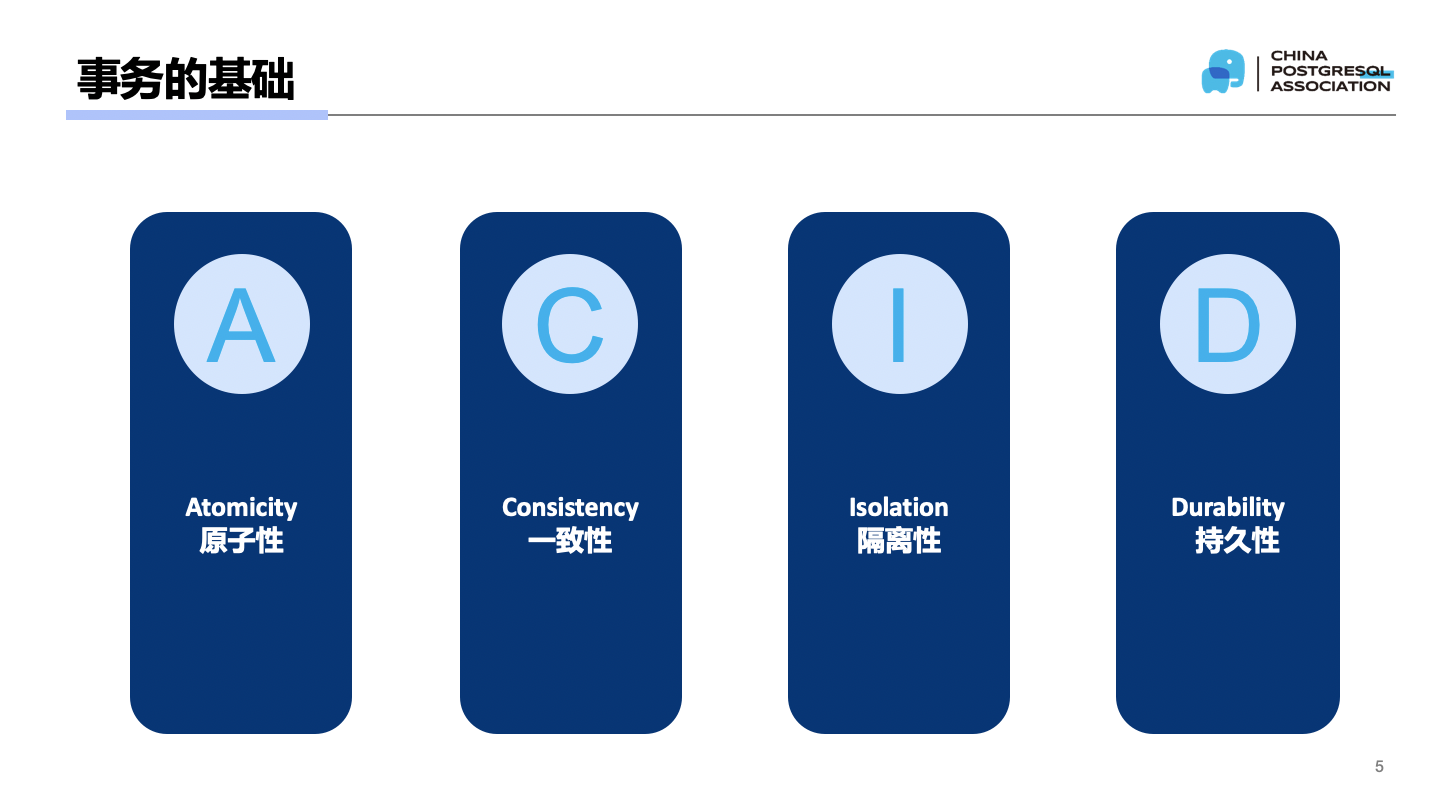
Atomicity: All operations within a transaction either complete entirely or cancel entirely. Like atoms in chemistry — indivisible and unsplittable. If a transaction encounters a problem midway and fails to execute, the entire transaction must roll back. Consistency: When a transaction completes, all data remains in a consistent state. This definition is actually somewhat vague. Transactions generally operate on data, and the state of data in the database gets updated. Due to transaction operations, data transitions from one state to another. This state must be reasonable and legitimate — the data logic must be consistent with real-world logic. This might be abstract, so here’s an example: Say A has 100 yuan, B has 200 yuan, their combined total is 300 yuan. Now B transfers 100 yuan to A. Then A has 200 yuan, B has 100 yuan, and their combined total is still 300 yuan. Key point: The data changes in this virtual world should remain consistent with real-world logic. Isolation: The result of executing multiple transactions concurrently must be the same as executing them separately one after another. For example, with 2 transactions, executing them serially one after another must produce the same result as executing them in parallel. (This is the official understanding from Wikipedia and the definition in the SQL standard — please remember this definition, as it’s the focus of this article.) Durability: After a transaction completes, changes to data are permanent. If updated data is placed in memory and disappears when the machine powers off, then it should go to disk. But is disk storage safe? What if the disk fails? We could have a high-availability architecture writing multiple copies of data. Extending further, we could have geographic-level disaster recovery. But if we push further — what if multiple regions all fail? From an architectural perspective, this question seems to have no answer. But from the user’s perspective, it’s actually easier to understand. For example, when a user deposits money — they put the cash in, and their account should display that amount. This number is permanent for the user. The user believes that even if the sky falls, their account should have this number. That is the meaning of durability.
ANSI SQL-92 Standard#

In 1992, the American National Standards Institute ANSI SQL-92 standard defined 4 isolation levels and 3 anomaly phenomena.
Although the database industry today mostly follows ISO international standards,
 this 1992 American standard had a huge impact on the database industry. I believe many database practitioners are familiar with the 4 isolation levels.
this 1992 American standard had a huge impact on the database industry. I believe many database practitioners are familiar with the 4 isolation levels.
Isolation Levels in the SQL-92 Standard#
ANSI SQL-92 defines 4 isolation levels:
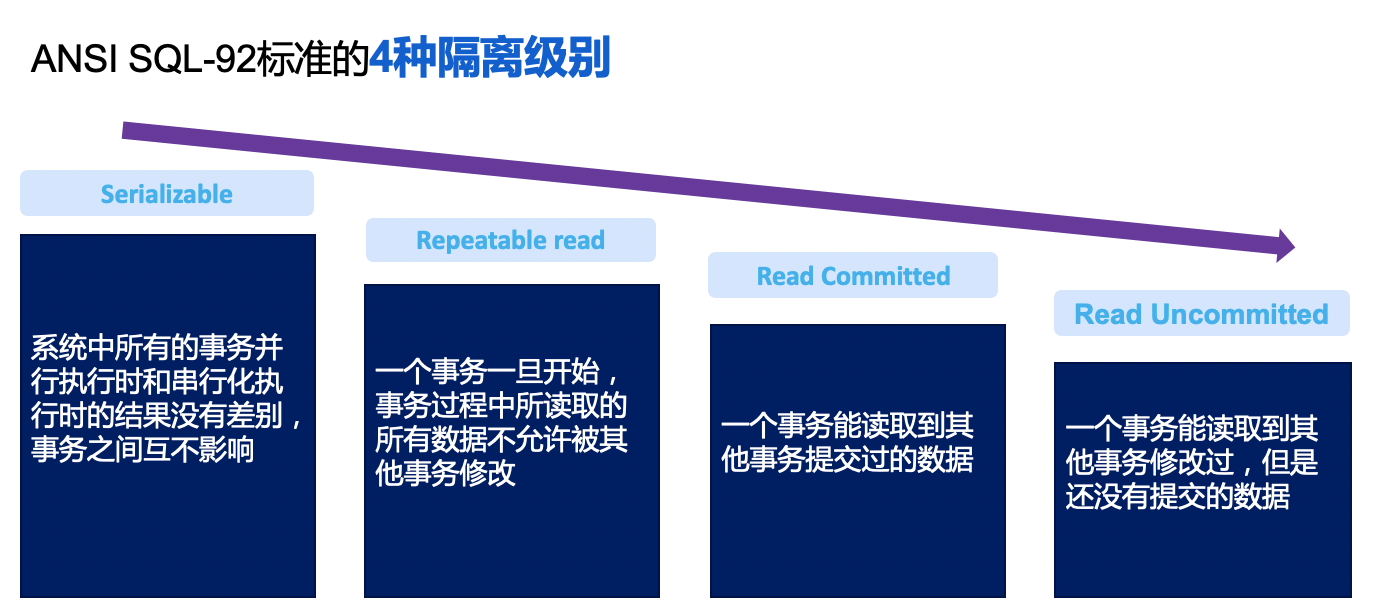 Transaction isolation levels from high to low. Notice Serializable: when all transactions in the system execute in parallel, there is no difference from executing them serially — transactions do not affect each other. Doesn’t this resemble the definition of Isolation in ACID?
All 4 isolation levels can satisfy all-or-nothing execution of transactions. They only differ in their definitions of isolation. All isolation levels can have atomicity, consistency, and durability, but different isolation levels have different isolation characteristics. By definition, only Serializable fully satisfies ACID.
Transaction isolation levels from high to low. Notice Serializable: when all transactions in the system execute in parallel, there is no difference from executing them serially — transactions do not affect each other. Doesn’t this resemble the definition of Isolation in ACID?
All 4 isolation levels can satisfy all-or-nothing execution of transactions. They only differ in their definitions of isolation. All isolation levels can have atomicity, consistency, and durability, but different isolation levels have different isolation characteristics. By definition, only Serializable fully satisfies ACID.
Anomaly Phenomena in the SQL-92 Standard#
The SQL-92 standard defines 3 anomaly phenomena. There are many definitions online, but many are not entirely accurate. Here we directly extract the definitions of the 3 anomaly phenomena from the SQL-92 standard document:
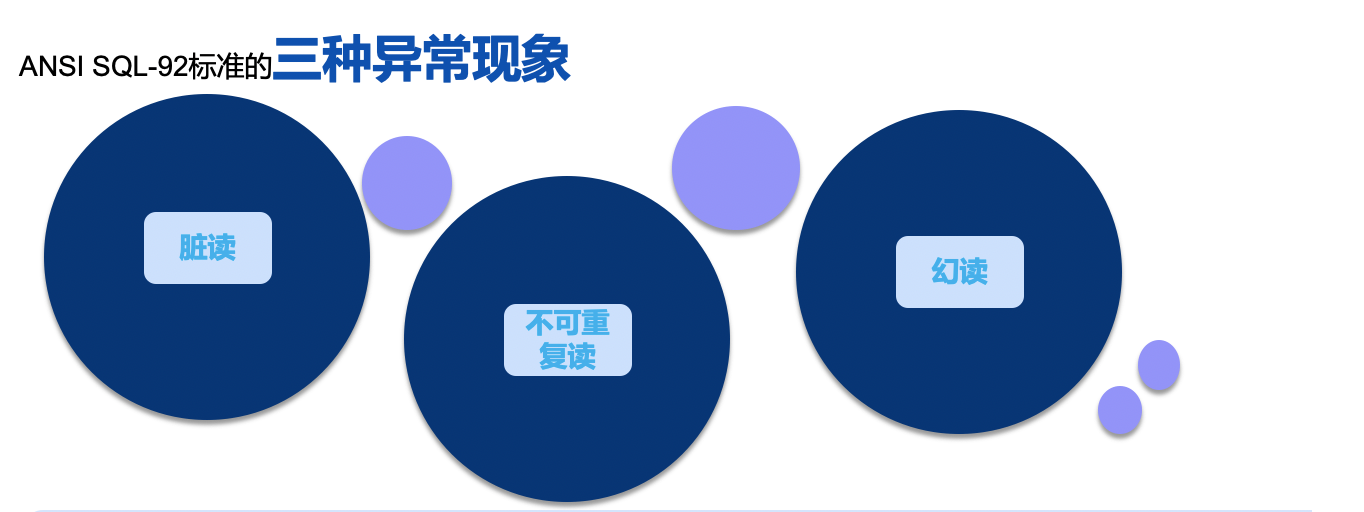
Dirty Read: Transaction T1 updates a row. Transaction T2 can read this row before T1 commits. If T1 executes a rollback, T2 will have read a row that was never committed. Dirty reads have an obvious problem — the user may not know whether the money has actually arrived. Before the transaction completes, the user can query and see money transferred into the account, but if the transaction fails and rolls back for some reason, the money disappears again. This is hard for users to understand.
Non-repeatable Read: Transaction T1 reads a row. Transaction T2 updates or deletes that row and commits. If T1 reads that row again, it will find the row has been changed or deleted. Phantom Read: Transaction T1 reads N rows matching certain conditions. Transaction T2 executes SQL that generates rows satisfying these conditions. When T1 reads again, it finds inconsistent row results. The difference between non-repeatable read and phantom read is: one is caused by other transactions updating or deleting leading to inconsistent reads within the same transaction; the other is caused by other transactions inserting leading to inconsistent reads within the same transaction.
SQL-92 Standard and PostgreSQL#
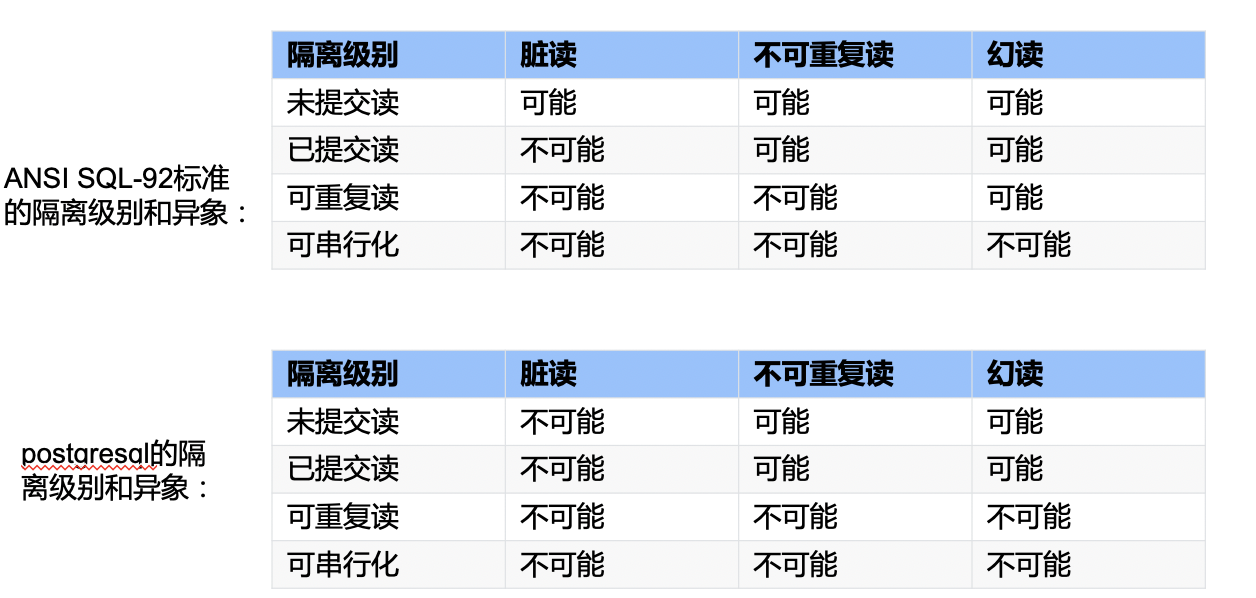 In the SQL-92 standard, isolation levels and anomaly phenomena have a stepped relationship. Except for Serializable which has no anomalies, each isolation level adds anomaly phenomena step by step. Now let’s look at the following table — this is the isolation levels and anomaly phenomena in PostgreSQL, which is different from the SQL-92 standard.
In the SQL-92 standard, isolation levels and anomaly phenomena have a stepped relationship. Except for Serializable which has no anomalies, each isolation level adds anomaly phenomena step by step. Now let’s look at the following table — this is the isolation levels and anomaly phenomena in PostgreSQL, which is different from the SQL-92 standard.
Why is PostgreSQL’s isolation level inconsistent with the SQL-92 standard?#
- Why is Read Uncommitted inconsistent with the SQL-92 standard? Read Uncommitted is simply too strange. In relational databases, it’s hard to imagine a scenario for using Read Uncommitted. It severely violates transaction isolation. PostgreSQL treats “Read Uncommitted” as “Read Committed.”
- Why is Repeatable Read inconsistent with the SQL-92 standard? PostgreSQL implements MVCC (Multi-Version Concurrency Control) through snapshots. The Repeatable Read level in PostgreSQL is actually the Snapshot Isolation level, which doesn’t have the Phantom Read anomaly.
- Although the SQL-92 standard has far-reaching influence, many databases haven’t fully implemented it.
- The ANSI SQL-92 standard has vague definitions. The SQL-92 standard is very representative in the database industry — “It’s good, but not good enough.”
Transaction History#
History of Transactions#
To understand “It’s good, but not good enough,” we need to review transaction history, going back 40 years.
 Notice the timing of the SQL-92 standard and the “Critique of SQL-92.” Although the SQL-92 standard was “flawed,” it still had a profound impact on the database industry. Subsequently, after many serializability theories were proven, PostgreSQL became the first commercial database to implement SSI.
Notice the timing of the SQL-92 standard and the “Critique of SQL-92.” Although the SQL-92 standard was “flawed,” it still had a profound impact on the database industry. Subsequently, after many serializability theories were proven, PostgreSQL became the first commercial database to implement SSI.
Critique of the SQL-92 Standard#
Shortly after the SQL-92 standard was released, some Microsoft engineers and academics critiqued it and proposed more isolation levels and anomaly phenomena.
Where the SQL-92 standard defined 4 isolation levels and 3 anomaly phenomena, the “Critique of SQL-92” had 6 isolation levels and 8 anomaly phenomena.
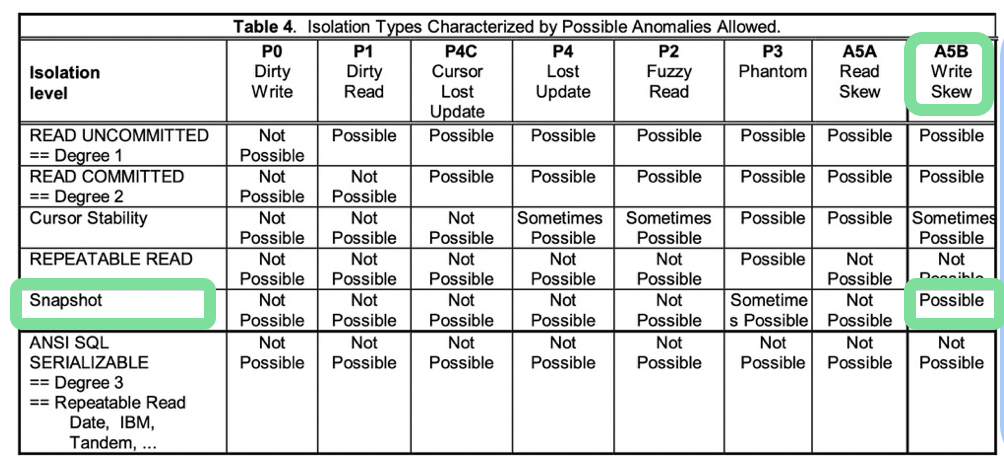
- More isolation levels and anomaly phenomena appeared — they were not defined in ANSI SQL-92.
- Snapshot Isolation sits between Repeatable Read and Serializable. This is also one of the reasons why PostgreSQL’s Repeatable Read and Serializable look so similar.
- The Write Skew anomaly was identified. It occurs at the Snapshot Isolation level.
Isolation Levels of Popular Databases#
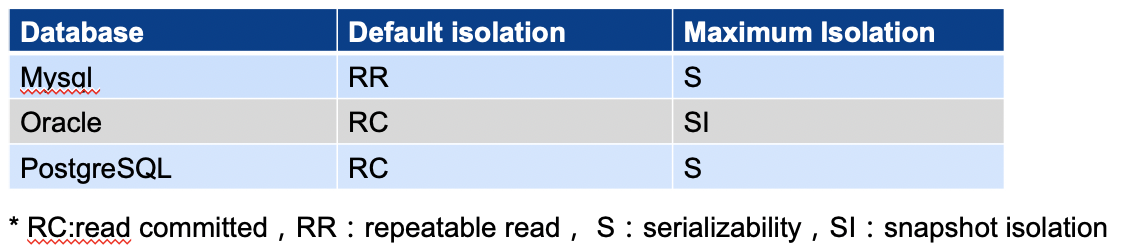
- MySQL at Serializable isolation level: reads acquire shared read locks on data, meaning reads block writes.
- Oracle can also set the Serializable isolation level and claims to support serializability, but it’s not true serializability — it’s just Snapshot Isolation.
- PostgreSQL supports Serializable. It implements serializability on top of Snapshot Isolation, fully named Serializable Snapshot Isolation (SSI), where reads and writes do not block each other.
You can see the differences among the three — only PostgreSQL’s Serializable has real substance.
Why Did Oracle Deceive Us?#
What did Oracle deceive us about? It passed off the Snapshot Isolation isolation level as the Serializable isolation level.
Why did this happen?
If we add Snapshot Isolation to the ANSI SQL-92 standard:

- The SQL-92 standard defines fewer anomaly phenomena and doesn’t define Snapshot Isolation. By the SQL-92 standard’s view, Snapshot Isolation looks similar to Serializable.
- Most relational databases follow the SQL-92 standard, including Oracle. But when better standards later emerged, they didn’t make changes.
Why Do Weak Isolation Levels Have Academic Problems but Few Serious Real-World Issues?#
- Anomaly phenomena at non-serializable isolation levels generally require high concurrency to manifest. Low-concurrency databases are unlikely to encounter problems.
- When anomaly phenomena do occur, some applications may not notice them, or may detect anomalies but find them unimportant.
- Data might be anomalous, but the application simply returns an error and enters an anomaly handling routine.
- Costs are too high. Not only is the development cost of database serializable isolation levels high, but applications also need adaptation costs for serializability. Just understanding this complex theory is no easy task.
- High-level isolation loses some performance. Extensive modification work may be thankless — applications need to choose between “high concurrency” and “no anomaly phenomena.”
- Businesses develop based on mechanisms rather than rules. Businesses somewhat adapt to the anomaly phenomena of weak isolation levels, especially Read Committed.
What’s the Point of Serializable?#
If weak isolation seems to work fine in the real world, what’s the point of Serializable? There is actually a point:
- Although applications adapt to weak isolation levels, it doesn’t mean they truly understand them.
- Using Serializable, applications can greatly reduce concerns about data anomalies.
- Except for Serializable, all other isolation levels have their own anomaly phenomena and don’t fully satisfy ACID’s Isolation property.
- Serializable can eliminate anomaly phenomena — the “termites” — fully ensuring data safety.
- Serializable has been proven theoretically achievable.
- Some serializable implementations do significantly reduce concurrency, but there are other implementations with minimal concurrency impact. For example, Serializable Snapshot Isolation (SSI).
SSI Theoretical Knowledge#
After all that about transaction fundamentals and history, we finally arrive at the concept of SSI. But before understanding SSI, we need to understand two more concepts: Serializable and Snapshot Isolation.
Serializable#
Meaning of Serializable If each transaction itself is correct (satisfying certain integrity conditions), then any serial schedule including these transactions is correct (its transactions still satisfy their conditions): “Serial” means transactions don’t overlap in time and cannot interfere with each other — i.e., there exists complete isolation between them.
Implementation of Serializable In early transaction development, Serializable was implemented through Strict Two-Phase Locking (S2PL), where reads and writes block each other until the transaction ends. This eliminated anomaly phenomena but S2PL lost high performance. Besides S2PL, there are other ways to achieve serializability, such as Serializable Snapshot Isolation (SSI).
Significance of Serializable To ensure no anomalies, Serializable sacrifices some concurrency (varying by implementation approach), but it truly guarantees ACID isolation for data. That is to say, databases that haven’t implemented serializability don’t fully support ACID properties. Serializable has been proven theoretically achievable, but the real database world is somewhat “abnormal.” In practice, Serializable is the highest transaction isolation level and is strongly recommended by academics and industry leaders, yet the vast majority of databases run at Read Committed or Snapshot Isolation levels.
Snapshot Isolation#
Definition of Snapshot Isolation Transactions executing under Snapshot Isolation operate on a snapshot of the database taken at the start of the transaction. When the transaction ends, it will only commit successfully if the values it updated haven’t been externally changed since the snapshot was taken. As the name implies, Snapshot Isolation uses snapshots, which are widely used to implement MVCC, enabling multi-version concurrency mechanisms to support concurrent transaction execution by users.
Emergence of Snapshot Isolation ANSI SQL-92 did not define Snapshot Isolation (SI). This isolation level emerged as the database industry evolved. The 1992 ANSI SQL-92 standard was defined based on database locks, so there was no definition for the Snapshot Isolation level. It wasn’t proposed until the 1995 “Critique” appeared.
SSI#
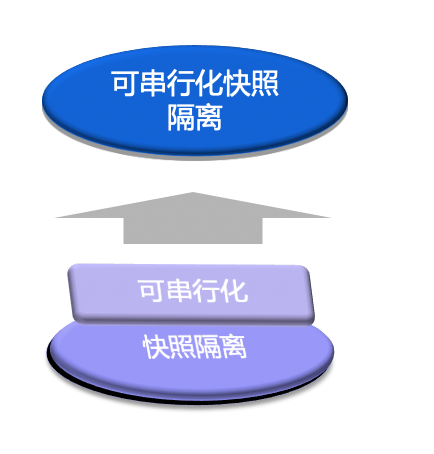
Serializable Snapshot Isolation (SSI) Given the widespread use of Snapshot Isolation and the academic goal that databases should achieve the Serializable isolation level, Serializable Snapshot Isolation (SSI), as the name suggests, implements serializability on top of Snapshot Isolation.
Why SSI? Due to the vagueness of the ANSI SQL-92 standard, although it didn’t define Snapshot Isolation, many databases actually use it. And Snapshot Isolation also has some anomaly phenomena (including Write Skew). SSI emerged to address these anomaly phenomena.
Advantages of SSI over S2PL Traditional serializability is implemented through S2PL. Under S2PL, write operations block other transactions’ reads and writes. Although it achieves serializability without Write Skew anomalies, it generates many lock conflicts, reducing concurrency performance. In contrast, MVCC implemented through snapshots has non-blocking reads and writes, with only write-write conflicts. SSI built on this foundation has much less impact on concurrency compared to traditional S2PL.
PostgreSQL Implements SSI PostgreSQL began implementing SSI in version 9.1, becoming the first commercial database to implement SSI.
Three Types of Dependencies#
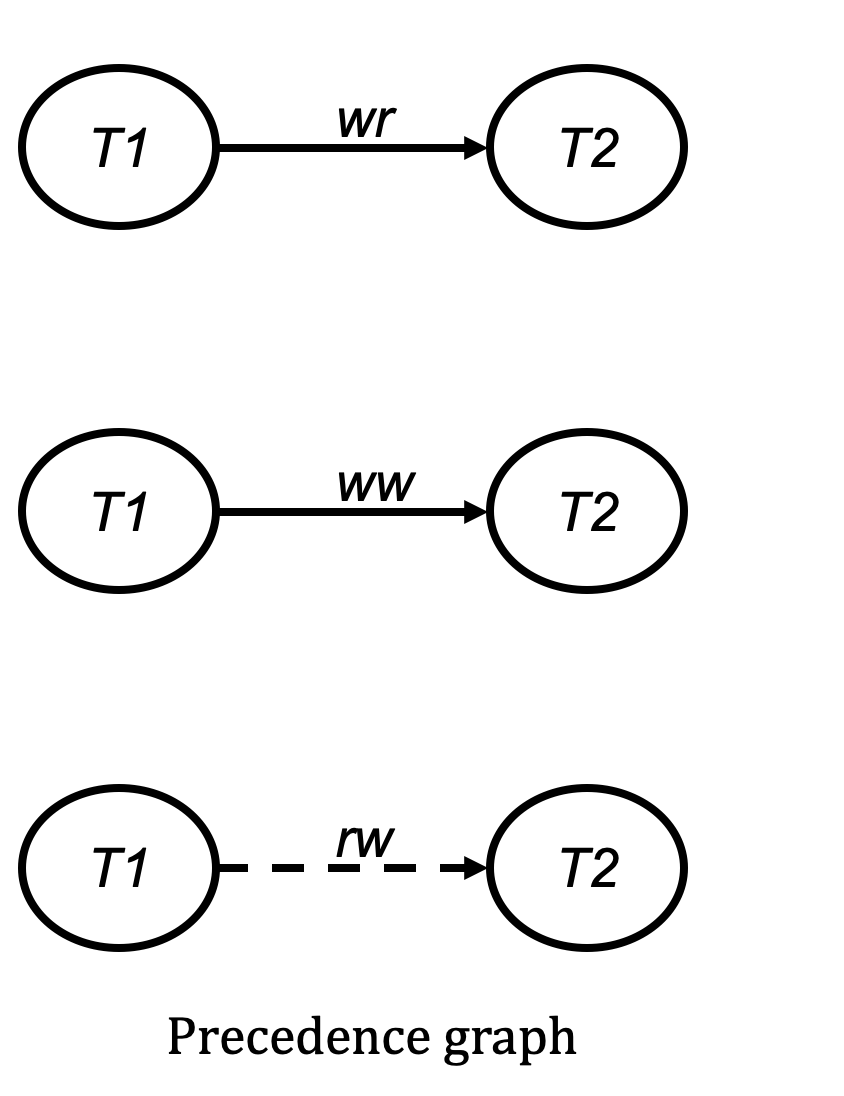 Read-Write Dependency (wr): Transaction T1 writes a version of a data item, and transaction T2 reads this version, meaning T1 precedes T2.
Write-Write Dependency (ww): Transaction T1 writes a version of a data item, and transaction T2 replaces this version with a new one, meaning T1 precedes T2.
Read-Write Anti-dependency (rw): Transaction T1 writes a version of a data item, and transaction T2 reads the version before this one, meaning T2 precedes T1.
Read-Write Dependency (wr): Transaction T1 writes a version of a data item, and transaction T2 reads this version, meaning T1 precedes T2.
Write-Write Dependency (ww): Transaction T1 writes a version of a data item, and transaction T2 replaces this version with a new one, meaning T1 precedes T2.
Read-Write Anti-dependency (rw): Transaction T1 writes a version of a data item, and transaction T2 reads the version before this one, meaning T2 precedes T1.
Write Skew Theory#
When certain conflicts form a cycle, serialization anomalies occur. That is to say, some concurrently executing transactions are theoretically non-serializable. One of the more easily understood examples is Write Skew. Write skew only occurs in the rw model — ww and wr won’t cause write skew — and transactions must be under concurrent conditions for it to appear.
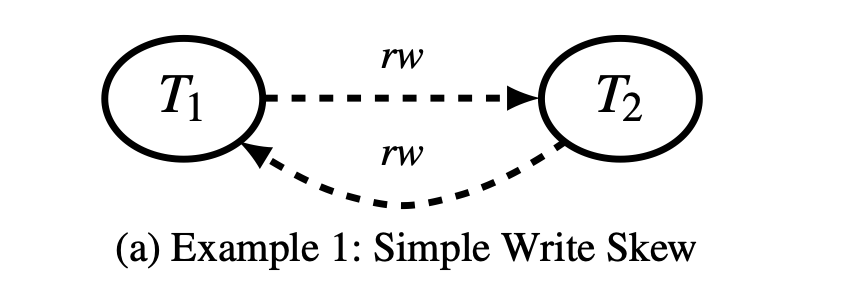 Simple Write Skew: Transaction T1 has an rw anti-dependency on T2, and T2 also has an rw anti-dependency on T1. The concurrent execution of these two transactions is non-serializable.
Simple Write Skew: Transaction T1 has an rw anti-dependency on T2, and T2 also has an rw anti-dependency on T1. The concurrent execution of these two transactions is non-serializable.
Real-World Write Skew Problems#
Many real-world cases can produce Write Skew anomalies. Let’s use the classic black-and-white ball problem to understand Write Skew:
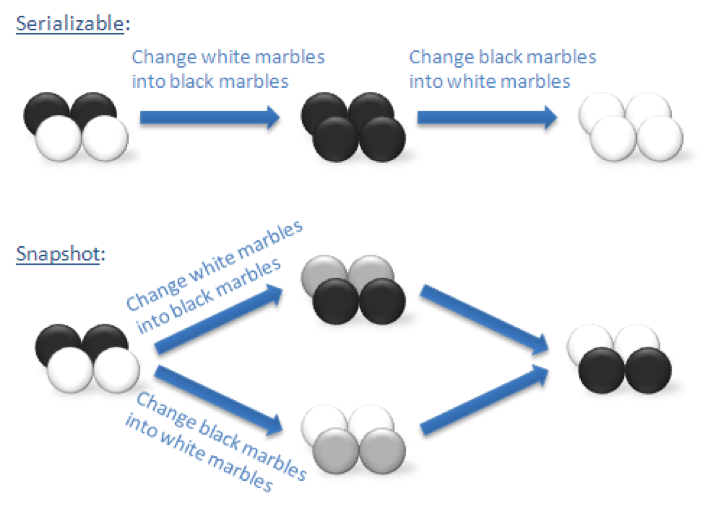 There are 4 balls in a bag: 2 white and 2 black. Now there are two transactions, P and Q. P changes all black balls to white, Q changes all white balls to black. There can be two serial executions: <P, Q> or <Q, P>. In both cases, the final result is 4 white balls or 4 black balls.
However, Snapshot Isolation allows another result:
Transaction P takes out 2 black balls
Transaction Q takes out 2 white balls
Transaction P changes all black balls in hand to white and puts them back
Transaction Q changes all white balls in hand to black and puts them back
Now the bag still has 2 black balls and 2 white balls. This is impossible in any serial execution.
But this is valid under Snapshot Isolation: each transaction maintains a consistent view of the database, and its write set doesn’t overlap with any concurrent transaction’s write set, resulting in the white and black balls exchanging.
There are 4 balls in a bag: 2 white and 2 black. Now there are two transactions, P and Q. P changes all black balls to white, Q changes all white balls to black. There can be two serial executions: <P, Q> or <Q, P>. In both cases, the final result is 4 white balls or 4 black balls.
However, Snapshot Isolation allows another result:
Transaction P takes out 2 black balls
Transaction Q takes out 2 white balls
Transaction P changes all black balls in hand to white and puts them back
Transaction Q changes all white balls in hand to black and puts them back
Now the bag still has 2 black balls and 2 white balls. This is impossible in any serial execution.
But this is valid under Snapshot Isolation: each transaction maintains a consistent view of the database, and its write set doesn’t overlap with any concurrent transaction’s write set, resulting in the white and black balls exchanging.
We can also make the problem more concrete and practical. Here’s a rough example: Suppose I have several bank cards, half frozen and half unfrozen. At one terminal, I execute freezing all cards. At another terminal, I immediately execute unfreezing all cards. From an intent perspective, my cards should all be unfrozen. But a strange phenomenon occurs: previously frozen cards become unfrozen, and previously unfrozen cards become frozen. As a customer, I would be confused.
The black-and-white ball problem illustrates: Snapshot Isolation execution results are inconsistent with Serializable execution results. Under Snapshot Isolation, a Write Skew anomaly occurs, and data results don’t match expectations.
SSI in PostgreSQL#
How PostgreSQL Handles SSI#
It’s actually simple — cancel the pivot transaction that forms the “dangerous structure.” We first set the isolation level to Serializable for both. The table has some white balls and some black balls.
| T1 | T2 |
|---|---|
| set default_transaction_isolation = ‘serializable’; | set default_transaction_isolation = ‘serializable’; |
| begin; update dots set color = ‘black’ where color = ‘white’; | |
| begin; update dots set color = ‘white’ where color = ‘black’; | |
| commit; | |
| commit; | |
ERROR: could not serialize access due to read/write dependencies among transactions DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt. HINT: The transaction might succeed if retried. |
Transaction 1 changes all white to black, Transaction 2 changes all black to white, then both commit. The first transaction to commit succeeds, the second fails. The error says: could not serialize access due to read/write dependencies among transactions, canceled on identification as a pivot. If you retry the transaction, it might succeed. Of course it would succeed here — the other transaction has already completed, so one transaction alone cannot form a dependency cycle. At other isolation levels like Repeatable Read or Read Committed, these two transactions would execute without any error, running normally, but the data results would differ from SSI’s results.
PostgreSQL SSI Implementation Optimizations#
PostgreSQL implements Serializable SSI on top of Snapshot Isolation and has made many optimizations to improve concurrency at high isolation levels. PostgreSQL’s SSI optimizations mainly include 3 points: Safe Snapshots: Read-only transactions that won’t create cyclic structures don’t need conflict detection, reducing checking overhead and memory burden.
Deferrable Transactions: Deferrable transactions can be retried. When a “dangerous structure” is detected, the deferrable transaction is canceled and then attempted again. Deferrable transactions need to be explicitly declared.
Detection Granularity Escalation: Multiple fine-grained locks can be combined into coarse-grained locks to reduce memory overhead.
Optimization Results — Performance Benchmark Comparison:
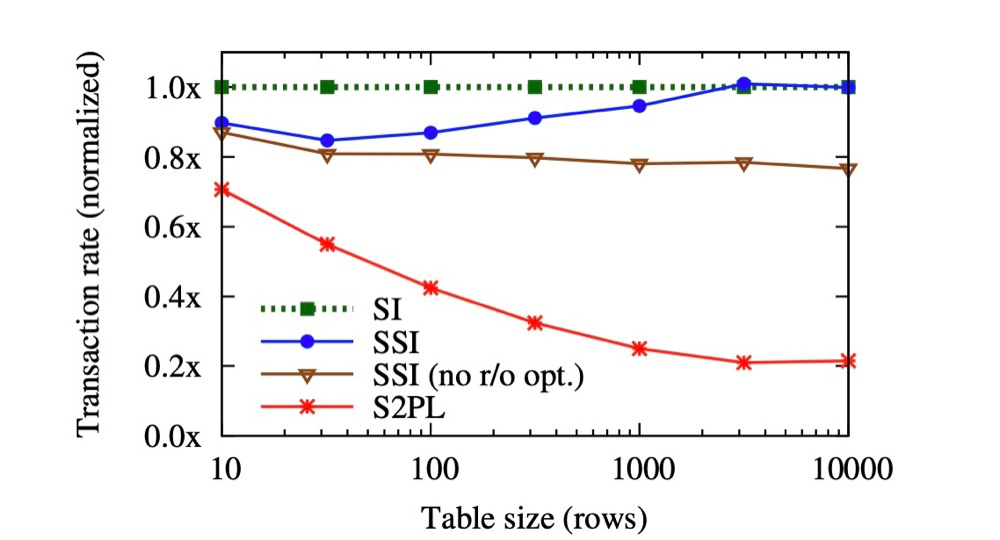 The green line is the Snapshot Isolation baseline. The blue line shows PostgreSQL’s SSI performance, which is already very close to Snapshot Isolation. The brown line is SSI without read-only transactions — all data-changing transactions — showing how much read-only transaction optimization improves performance. In typical business systems, read-only transactions outnumber change transactions. The red line is serializability implemented through Strict Two-Phase Locking — the performance is abysmal.
The green line is the Snapshot Isolation baseline. The blue line shows PostgreSQL’s SSI performance, which is already very close to Snapshot Isolation. The brown line is SSI without read-only transactions — all data-changing transactions — showing how much read-only transaction optimization improves performance. In typical business systems, read-only transactions outnumber change transactions. The red line is serializability implemented through Strict Two-Phase Locking — the performance is abysmal.
The table below shows concurrency pressure and transaction failure rates. Since some transactions need to be canceled to break cycles, Serializable inevitably cancels more transactions than weak isolation. This table also shows that PostgreSQL’s SSI has far higher concurrency and transaction success rates than Strict Two-Phase Locking.
Optimization Results — Request Volume and Failure Rate:

Summary#
- Serializable can simplify system development problems. Developers don’t need to worry about transaction anomalies under concurrency, especially in today’s increasingly high-concurrency systems.
- PostgreSQL’s Serializable is clearly better than the Strict Two-Phase Locking model. Not only better performance, but also lower transaction abort probability.
- PostgreSQL is the first commercial database to implement SSI, while many traditional relational databases don’t support serializability at all. PostgreSQL has taken a big step forward.
- PostgreSQL not only implemented SSI but also made many optimizations on top of it, such as read-only transaction and memory optimizations, with significant results.