How Did a Primary Key Query Access Multiple Data Pages?#
Continuing from the previous article: A Classic Case of Long Transactions, Table Bloat, and LIMIT Problems, there was one point not explained in detail:
Why does a query using the primary key generate so many shared hits? Why does index bloat cause access to multiple data pages? Can’t data outside the page be located through the corresponding index entry? This relates to index version management — indexes do carry some version information, but not much. Let’s first review PostgreSQL’s btree index structure.
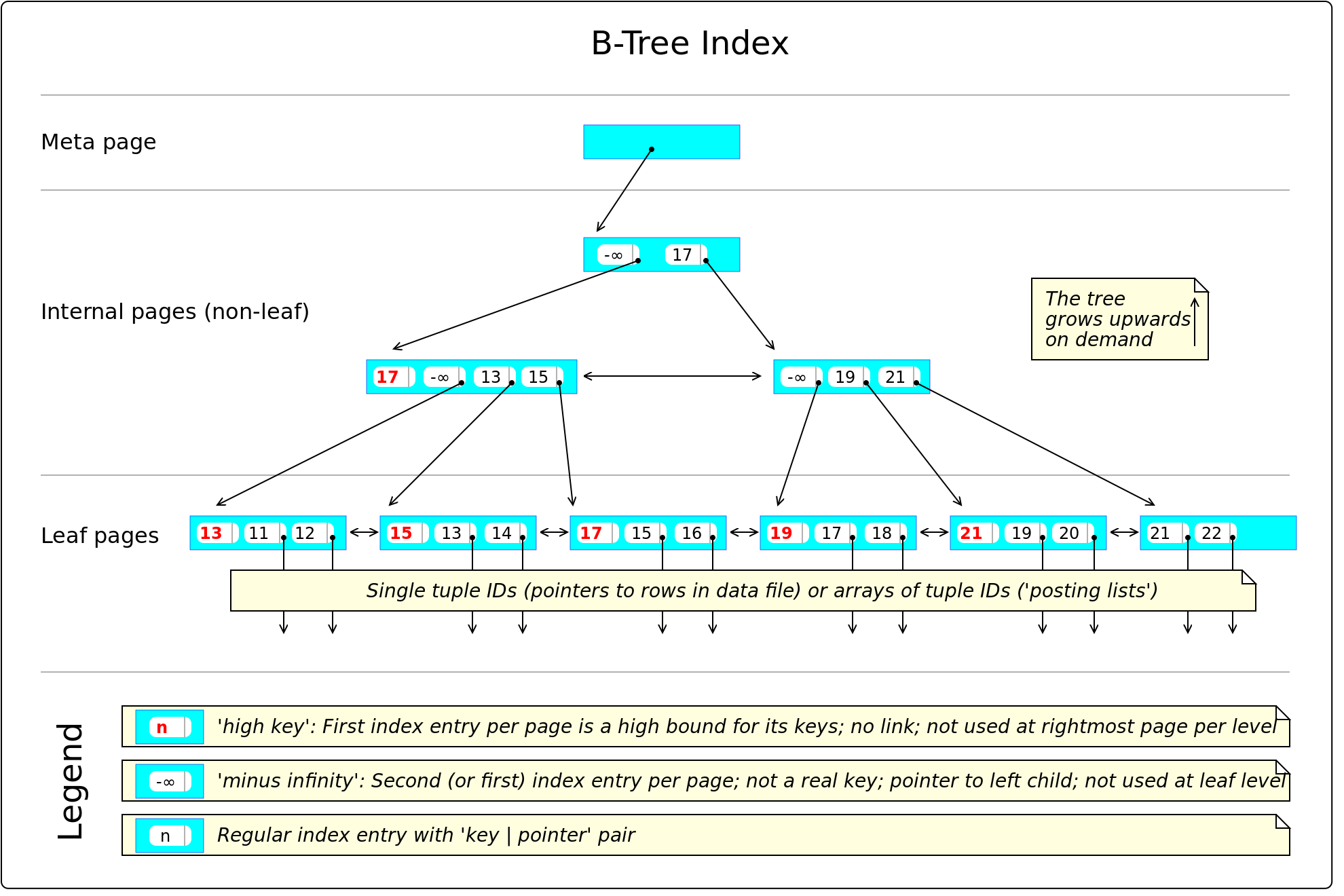 (https://en.wikibooks.org/wiki/PostgreSQL/Index_Btree)
(https://en.wikibooks.org/wiki/PostgreSQL/Index_Btree)
This PG btree wiki diagram doesn’t explain how dead tuples and dead index entries are accessed — it lacks version information. For now, you don’t need to understand every detail of this structure; just know that a btree structure like this exists.
To investigate the btree version access problem, let’s run a test:
create table tab1(a bigserial,b char(1000));
create index idx_tab1_a on tab1(a);
alter table tab1 set (autovacuum_enabled = off); --disable autovacuum
alter table tab1 alter column b set storage PLAIN; --disable toastlzldb=> insert into tab1(b) values('zzzzzzzzz');
INSERT 0 1
--View tuple info on the data page
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 111875 | 0 | 0 | {HEAP_HASVARWIDTH,HEAP_XMAX_INVALID} | {}
--View index entry info on the index page (note: index page 0 is the meta page, has no data)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------+---------+-------+------+-------------------------+------+-------+-----------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) | Only one row inserted: data page 0 has only 1 tuple, index page 1 has only one entry pointing to ctid(0,1).
lzldb=> update tab1 set b='xxxxxxx' ;
UPDATE 1
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-------------------------------------------------------------------+----------------
(0,2) | 1 | LP_NORMAL | 111875 | 111876 | 0 | {HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,2) | 2 | LP_NORMAL | 111876 | 0 | 0 | {HEAP_HASVARWIDTH,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
(2 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------+---------+-------+------+-------------------------+------+-------+-----------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) | After updating one row: data page 0 has 2 tuples. Only ctid(0,2) is alive. The tuple at lp=1 is “dead” but lp_flags is still “NORMAL”! Index page 1 still has only one entry pointing to ctid(0,1), which is the “dead” tuple. This is the principle of HOT (Heap-Only Tuple): when updating within the same page, the index entry is not updated. The index follows the ctid chain from the dead tuple to find the truly alive data tuple.
Let’s update 10 times in a loop, producing 2 data pages and 1 index page:
DO $$
begin
FOR i IN 1..10 LOOP
update tab1 set b=md5(i::text);
END LOOP;
end $$;;After updates:
--First data page
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flag
s
--------+----+-------------+--------+--------+-------+--------------------------------------------------------------------------------------+--------------
--
| 1 | LP_REDIRECT | | | | |
(0,3) | 2 | LP_NORMAL | 111876 | 111877 | 0 | {HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,4) | 3 | LP_NORMAL | 111877 | 111877 | 0 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,5) | 4 | LP_NORMAL | 111877 | 111877 | 1 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,6) | 5 | LP_NORMAL | 111877 | 111877 | 2 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,7) | 6 | LP_NORMAL | 111877 | 111877 | 3 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,1) | 7 | LP_NORMAL | 111877 | 111877 | 4 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
(7 rows)
--Second data page
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',1)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------------------------------------+----------------
(1,2) | 1 | LP_NORMAL | 111877 | 111877 | 5 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED} | {}
(1,3) | 2 | LP_NORMAL | 111877 | 111877 | 6 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,4) | 3 | LP_NORMAL | 111877 | 111877 | 7 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,5) | 4 | LP_NORMAL | 111877 | 111877 | 8 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,5) | 5 | LP_NORMAL | 111877 | 0 | 9 | {HEAP_HASVARWIDTH,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}On the first data page (page 0), the LP_REDIRECT status directly tells us the page definitely has HOT chains. At lp=1 there is no other information — not even ctid, data, or infomask. You cannot trace through this lp to find the final data. For the first index entry, it’s sufficient to access ctid(0,1); there is no desired data row in this page. But data page 2 has no LP_REDIRECT, and the index can find the live tuple (1,5) within the page by following the ctid chain from ctid(1,0).
Source code explanation of line pointer states:
/*
*lp_flags has these possible states. An UNUSED line pointer is available
*for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* unused (should always have lp_len=0) */
#define LP_NORMAL 1 /* used (should always have lp_len>0) */
#define LP_REDIRECT 2 /* HOT redirect (should have lp_len=0), actually not HOT but cross-page redirect indicator */
#define LP_DEAD 3 /* dead, may or may not have storage *///Explanation of LP_REDIRECT
Redirecting line pointer
A line pointer that points to another line pointer and has no
associated tuple. It has the special lp_flags state LP_REDIRECT,
and lp_off is the OffsetNumber of the line pointer it links to.
This is used when a root tuple becomes dead but we cannot prune
the line pointer because there are non-dead heap-only tuples
further down the chain.Looking back more carefully, the lp status of what we consider “dead” tuples is LP_NORMAL, not LP_DEAD. This is important because we’ll revisit this point later.
Continuing to examine the index page:
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------+---------+-------+------+-------------------------+------+-------+-----------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (1,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1,1) | Because an additional page was created, HOT no longer applies. The index is updated. The index page has only 2 entries, both alive (dead=f), each pointing to the first tuple of its respective page: (0,1) and (1,1). For cross-page updates, the index page is also updated, with each index entry pointing to its own page. Note: at this point the table has only 1 row of data, but the index has 2 entries, both alive. This is why a primary key scan accesses multiple data pages.
Let’s update more data to produce multiple index pages:
DO $$
begin
FOR i IN 1..10000 LOOP
update tab1 set b=md5(i::text);
END LOOP;
end $$;--First index page
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------------+---------+-------+------+-------------------------+------+----------+-------------------------
1 | (1278,4097) | 24 | f | f | 01 00 00 00 00 00 00 00 | | (1277,1) |
2 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) | {"(0,1)","(1,1)"}
3 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (222,1) | {"(222,1)","(223,1)"}
4 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (444,1) | {"(444,1)","(445,1)"}
5 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (666,1) | {"(666,1)","(667,1)"}
6 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (888,1) | {"(888,1)","(889,1)"}
--Second index page
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',2);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+----------+---------+-------+------+-------------------------+------+----------+-----------
1 | (1278,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1278,1) |
2 | (1279,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1279,1) |
3 | (1280,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1280,1) |
4 | (1281,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1281,1) |
...
152 | (1429,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1429,1) |
153 | (1430,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1430,1) |
(153 rows)
--Third index page
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',3);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+----------+---------+-------+------+-------------------------+------+----------+-----------
1 | (1,0) | 8 | f | f | | | |
2 | (2,4097) | 24 | f | f | 01 00 00 00 00 00 00 00 | | (1277,1) | There are 3 index pages total. Page 1 is the root node. Pages 2 and 3 are leaf nodes. The dead status of all their index entries is “f”.
Now let’s return to the SQL, using the primary key index:
lzldb=> explain (analyze,buffers) select * from tab1 where a=1;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tab1 (cost=4.39..56.41 rows=14 width=4012) (actual time=2.594..2.596 rows=1 loops=1)
Recheck Cond: (a = 1)
Heap Blocks: exact=1
Buffers: shared hit=1437 dirtied=1026
-> Bitmap Index Scan on idx_tab1_a (cost=0.00..4.39 rows=14 width=0) (actual time=0.152..0.153 rows=1431 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=6
Planning:
Buffers: shared hit=5
Planning Time: 0.087 ms
Execution Time: 2.614 msWhen querying by primary key, shared hit is 1437, roughly matching the ~1430 table pages. Since indexes lack version information and the dead status of index entries hasn’t been updated, PostgreSQL follows all live index entries to find version information in the data pages. This is why a primary key index scan can be extremely slow.
kill index item#
Since indexes don’t store visibility information (i.e., MVCC version info), the visibility of the tuple pointed to by an index determines the index visibility itself. This is also why index-only scans in PostgreSQL still access data pages. Of course, with the visibility map (VM), the VM records which data pages are all-visible and all-frozen, so index-only scans won’t access those pages — they’re already visible.
Even without VACUUM, the PostgreSQL kernel has a method for handling this kind of index bloat — kill index item. This feature is sometimes called Simple deletion or index deletion (terminology from src/backend/access/nbtree/README). Essentially, it marks index entries corresponding to tuples that are already LP_DEAD as dead, without changing the existing index structure.
Source code function _bt_killitems:
* _bt_killitems - set LP_DEAD state for items an indexscan caller has
* told us were killedThis clearly states that index scans trigger kill item operations (meaning SELECT can also trigger this operation to update the index). This is easy to test. Since our previous data has already been index-scanned, let’s rebuild data for testing.
create table tab2(a bigserial,b char(100));
create index idx_tab2_a on tab2(a);
create index idx_tab2_b on tab2(b);
alter table tab2 set (autovacuum_enabled = off); --disable autovacuum
alter table tab2 alter column b set storage PLAIN; --disable toast
--Insert 1 row and update repeatedly
insert into tab2(b) values('00000');
DO $$
begin
FOR i IN 1..10000 LOOP
update tab2 set b=i::text;
END LOOP;
end $$;--Table pages
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',2)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------------+----------------
(2,2) | 1 | LP_NORMAL | 509 | 509 | 115 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,3) | 2 | LP_NORMAL | 509 | 509 | 116 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,4) | 3 | LP_NORMAL | 509 | 509 | 117 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,5) | 4 | LP_NORMAL | 509 | 509 | 118 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,6) | 5 | LP_NORMAL | 509 | 509 | 119 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,7) | 6 | LP_NORMAL | 509 | 509 | 120 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,8) | 7 | LP_NORMAL | 509 | 509 | 121 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
...
--Index a pages
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+-----------+---------+-------+------+------+---------+-----------------------
1 | (66,4097) | 24 | f | f | | (66,6) |
2 | (16,8414) | 1352 | f | f | f | (44,5) | {"(44,5)","(44,6)"}
3 | (16,8414) | 1352 | f | f | f | (47,53) | {"(47,53)","(47,54)"}
4 | (16,8414) | 1352 | f | f | f | (51,43) | {"(51,43)","(51,44)"}
5 | (16,8414) | 1352 | f | f | f | (55,33) | {"(55,33)","(55,34)"}
6 | (16,8414) | 1352 | f | f | f | (59,23) | {"(59,23)","(59,24)"}
7 | (16,8360) | 1024 | f | f | f | (63,13) | {"(63,13)","(63,14)"}
--Index b pages
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_b',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+---------+---------+-------+------+------+---------+-----------
1 | (57,1) | 112 | f | t | | |
2 | (0,34) | 112 | f | t | f | (0,34) |
3 | (5,41) | 112 | f | t | f | (5,41) |
4 | (56,53) | 112 | f | t | f | (56,53) |
5 | (56,54) | 112 | f | t | f | (56,54) |
6 | (56,55) | 112 | f | t | f | (56,55) |
7 | (56,56) | 112 | f | t | f | (56,56) |
8 | (56,57) | 112 | f | t | f | (56,57) | Now query the table with a sequential scan, then examine the data tuple and index entry states:
lzldb=> explain (analyze,buffers) select * from tab2;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on tab2 (cost=0.00..204.14 rows=3114 width=412) (actual time=1.077..1.079 rows=1 loops=1)
Buffers: shared hit=173 dirtied=173
Planning Time: 0.042 ms
Execution Time: 1.090 ms
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',4)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+----------+--------+--------+-------+-----------+----------------
| 1 | LP_DEAD | | | | |
| 2 | LP_DEAD | | | | |
| 3 | LP_DEAD | | | | |
| 4 | LP_DEAD | | | | |
| 5 | LP_DEAD | | | | |
| 6 | LP_DEAD | | | | |
| 7 | LP_DEAD | | | | |
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+-----------+---------+-------+------+------+---------+-----------------------
1 | (66,4097) | 24 | f | f | | (66,6) |
2 | (16,8414) | 1352 | f | f | f | (44,5) | {"(44,5)","(44,6)"}
3 | (16,8414) | 1352 | f | f | f | (47,53) | {"(47,53)","(47,54)"}
4 | (16,8414) | 1352 | f | f | f | (51,43) | {"(51,43)","(51,44)"}
5 | (16,8414) | 1352 | f | f | f | (55,33) | {"(55,33)","(55,34)"}
6 | (16,8414) | 1352 | f | f | f | (59,23) | {"(59,23)","(59,24)"}
7 | (16,8360) | 1024 | f | f | f | (63,13) | {"(63,13)","(63,14)"}
(7 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_b',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+---------+---------+-------+------+------+---------+-----------
1 | (57,1) | 112 | f | t | | |
2 | (0,34) | 112 | f | t | f | (0,34) |
3 | (5,41) | 112 | f | t | f | (5,41) |
4 | (56,53) | 112 | f | t | f | (56,53) |
5 | (56,54) | 112 | f | t | f | (56,54) |
6 | (56,55) | 112 | f | t | f | (56,55) |
7 | (56,56) | 112 | f | t | f | (56,56) | Data tuples: all pages except the last were marked LP_DEAD. Index entries: nothing changed.
Now query again using index a:
lzldb=> explain (analyze,buffers) select * from tab2 where a=1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Index Scan using idx_tab2_a on tab2 (cost=0.28..68.56 rows=16 width=412) (actual time=1.282..1.510 rows=1 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=190 dirtied=8
Planning Time: 0.058 ms
Execution Time: 1.525 ms
(5 rows)
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+----------+--------+--------+-------+-----------+----------------
| 1 | LP_DEAD | | | | |
| 2 | LP_DEAD | | | | |
| 3 | LP_DEAD | | | | |
| 4 | LP_DEAD | | | | |
| 5 | LP_DEAD | | | | |
| 6 | LP_DEAD | | | | |
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+-----------+---------+-------+------+------+---------+-----------------------
1 | (66,4097) | 24 | f | f | | (66,6) |
2 | (16,8414) | 1352 | f | f | t | (44,5) | {"(44,5)","(44,6)"}
3 | (16,8414) | 1352 | f | f | t | (47,53) | {"(47,53)","(47,54)"}
4 | (16,8414) | 1352 | f | f | t | (51,43) | {"(51,43)","(51,44)"}
5 | (16,8414) | 1352 | f | f | t | (55,33) | {"(55,33)","(55,34)"}
6 | (16,8414) | 1352 | f | f | t | (59,23) | {"(59,23)","(59,24)"}
7 | (16,8360) | 1024 | f | f | t | (63,13) | {"(63,13)","(63,14)"}
(7 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_b',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+---------+---------+-------+------+------+---------+-----------
1 | (57,1) | 112 | f | t | | |
2 | (0,34) | 112 | f | t | f | (0,34) |
3 | (5,41) | 112 | f | t | f | (5,41) |
4 | (56,53) | 112 | f | t | f | (56,53) |
5 | (56,54) | 112 | f | t | f | (56,54) |
6 | (56,55) | 112 | f | t | f | (56,55) |
7 | (56,56) | 112 | f | t | f | (56,56) | The dead tuples in index a have all been marked dead=t, while dead tuples in index b remain dead=f because we haven’t scanned index b.
Now query through index a again:
lzldb=> explain (analyze,buffers) select * from tab2 where a=1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Index Scan using idx_tab2_a on tab2 (cost=0.28..68.56 rows=16 width=412) (actual time=0.020..0.021 rows=1 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=10
Planning Time: 0.059 ms
Execution Time: 0.033 msBecause the index entries for dead tuples in index a have been marked dead=t, there’s no need to check version information on data pages to determine whether tuples are “alive.”
Why is shared hit=10 here, still somewhat high? Because kill index item only marks dead index entries without changing the index structure, so the number of index pages hasn’t decreased. These 10 shared hits correspond to 10 index pages (including the meta page).
lzldb=> analyze tab2;
ANALYZE
lzldb=> select relname,relpages,reltuples from pg_class where relname='idx_tab2_a';
relname | relpages | reltuples
------------+----------+-----------
idx_tab2_a | 10 | 1Bottom-Up deletion#
In PG14, the trigger condition for index deletion was enhanced. As mentioned earlier, index deletion is triggered by scanning the index. In PG14, index deletion can also be triggered when an index page split is imminent, to find free index space and reduce the probability of page splits.
This feature reduces index splits and thus also reduces index bloat, mitigating the problems caused by index bloat.
For specific testing, see: INDEX BLOAT REDUCED IN POSTGRESQL V14
index deduplication#
PG13 introduced the index deduplication feature, which brings the GIN index posting list concept into btree indexes to reduce the space occupied by duplicate btree index entries and mitigate index split issues.
Previously, btree index entries pointed to only one ctid (as we saw in the tests above). With deduplicate index items, one index entry can have a posting list, and one posting list can hold multiple ctids.
The representation of posting lists is almost identical to the posting lists used by GIN
Like GIN posting tree(list) (the btree posting list may not exactly follow this structure — needs further study):
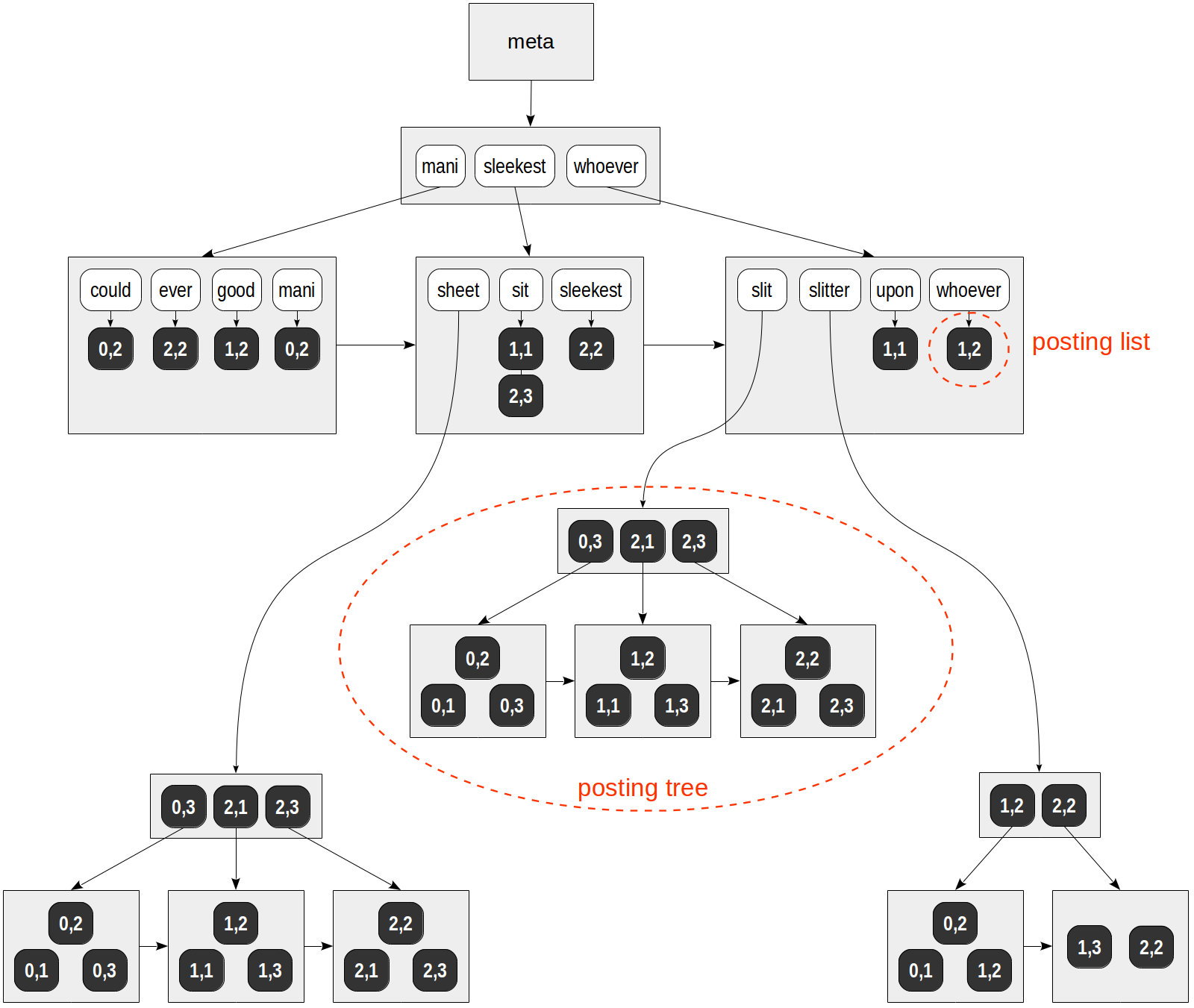 (https://postgrespro.com/blog/pgsql/4261647)
(https://postgrespro.com/blog/pgsql/4261647)
Testing index deduplication:
create table tab3(same char(100),diff char(100));
create index idx_tab3_same on tab3(same);
create index idx_tab3_diff on tab3(diff);
insert into tab3 select 10000::text,i::text from generate_series(10000, 99999) as i;lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab3_same',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+------------+---------+-------+------+------+----------+-----------------------
1 | (104,4097) | 120 | f | t | | (104,10) |
2 | (112,8398) | 1352 | f | t | f | (69,19) | {"(69,19)","(69,20)"}
3 | (112,8398) | 1352 | f | t | f | (75,21) | {"(75,21)","(75,22)"}
4 | (112,8398) | 1352 | f | t | f | (81,23) | {"(81,23)","(81,24)"}
5 | (112,8398) | 1352 | f | t | f | (87,25) | {"(87,25)","(87,26)"}
6 | (112,8398) | 1352 | f | t | f | (93,27) | {"(93,27)","(93,28)"}
7 | (112,8344) | 1024 | f | t | f | (99,29) | {"(99,29)","(99,30)"}
(7 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab3_diff',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+--------+---------+-------+------+------+--------+-----------
1 | (5,1) | 112 | f | t | | |
2 | (3,23) | 112 | f | t | f | (3,23) |
3 | (3,24) | 112 | f | t | f | (3,24) |
...
62 | (5,15) | 112 | f | t | f | (5,15) |
63 | (5,16) | 112 | f | t | f | (5,16) |
(63 rows) The tids column in the bt_page_items function is essentially the posting list. The same field was inserted with identical data and produced deduplication in the index; the diff field had no duplicate data and produced no deduplication.
The space difference is enormous:
lzldb=> select relname,relpages,reltuples from pg_class where relname like 'idx_tab3%';
relname | relpages | reltuples
---------------+----------+-----------
idx_tab3_diff | 1484 | 90000
idx_tab3_same | 81 | 90000Can unique indexes produce deduplication?#
Unique indexes have no duplicate data, so it seems like they wouldn’t. In practice, they can. Because even with unique indexes, when HOT can’t satisfy an update, multiple index entries are created. We can see this from the first test case in this article. Repeatedly updating a single row with UPDATE also produces deduplication, which occurs before delete index item.
Additionally, when delete index item removes a posting list index entry, it must ensure that all ctids under the posting list correspond to DEAD tuples.
Disabling deduplication#
Index deduplication was introduced in PG13. The feature is enabled by default and can be disabled at the index level. Modifying deduplicate_items on an index won’t directly change the existing index structure; it only affects newly inserted data.
alter index idx_tab3_same set (deduplicate_items=off);
create index idx_tab3_same1 on tab3(same) with (deduplicate_items=off);What does VACUUM do?#
VACUUM does many things. Here we’ll only focus on table/index bloat and space reclamation, skipping wraparound and other topics.
Let’s test with tab2, where we repeatedly updated a single row. Simple deletion has already been triggered, and table/index entries are almost all DEAD.
Run VACUUM directly:
lzldb=# vacuum verbose tab2;
INFO: vacuuming "public.tab2"
INFO: scanned index "idx_tab2_a" to remove 10000 row versions
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: scanned index "idx_tab2_b" to remove 10000 row versions
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: "tab2": removed 10000 row versions in 173 pages
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: index "idx_tab2_a" now contains 1 row versions in 10 pages
DETAIL: 10000 index row versions were removed.
7 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: index "idx_tab2_b" now contains 1 row versions in 276 pages
DETAIL: 10000 index row versions were removed.
269 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: "tab2": found 24 removable, 1 nonremovable row versions in 173 out of 173 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 526
There were 0 unused item identifiers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUMidx_tab2_a removed 10000 row versions in 10 pages, 7 index pages were deleted. Table tab2 removed 10000 row versions in 173 pages.
--First page of the table
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------+----------------
| 1 | LP_UNUSED | | | | |
| 2 | LP_UNUSED | | | | |
...
| 45 | LP_UNUSED | | | | |
--Last page of the table
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',172)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
----------+----+-----------+--------+--------+-------+-----------------------------------------------------------------------+----------------
| 1 | LP_UNUSED | | | | |
| 2 | LP_UNUSED | | | | |
...
| 23 | LP_UNUSED | | | | |
| 24 | LP_UNUSED | | | | |
(172,25) | 25 | LP_NORMAL | 509 | 0 | 9999 | {HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID,HEAP_UPDATED} | {}
--First index page
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',1);
NOTICE: page is deleted
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+----------------+---------+-------+------+------+------+-----------
1 | (4294967295,0) | 8 | f | f | | |
(1 row)
--Last index page
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',9);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+----------+---------+-------+------+------+----------+-----------
1 | (172,25) | 16 | f | f | f | (172,25) | All line pointers for dead table tuples were marked UNUSED, data was cleaned, and only one live tuple remains in NORMAL state. The table still has the same number of pages.
All dead index entries (dead=t) were cleaned. Live index entries were shifted within index pages (the last page’s index entry originally had itemoffset != 1). All emptied index pages were marked as deleted. These deleted index pages still exist, in a half-dead state.
From the nbtree README on “Deleting entire pages during VACUUM” (the original is quite long; I’ve excerpted the key parts):
We consider deleting an entire page from the btree only when it’s become completely empty of items. Page deletion always begins from an empty leaf page. An internal page can only be deleted as part of deleting an entire subtree.
An entire page is only considered for deletion when the index page is completely empty. Deletion always starts from leaf nodes; non-leaf nodes are only deleted when deleting an entire subtree.
Deleting a leaf page is a two-stage process.
In the first stage, the page is unlinked from its parent, and marked as half-dead. In the second-stage, the half-dead leaf page is unlinked from its siblings. We first lock the left sibling (if any) of the target, the target page itself, and its right sibling (there must be one) in that order. Then we update the side-links in the siblings, and mark the target page deleted.
Deleting a leaf page has two stages:
- Unlink from the parent — the leaf page is now in half-dead state
- Unlink from left and right siblings — the leaf page is now in deleted state
A deleted page cannot be recycled immediately, since there may be other processes waiting to reference it (ie, search processes that just left the parent, or scans moving right or left from one of the siblings). These processes must be able to observe a deleted page for some time after the deletion operation, in order to be able to at least recover from it (they recover by moving right, as with concurrent page splits). Searchers never have to worry about concurrent page recycling.
Because other processes may still be using the deleted page, VACUUM cannot immediately recycle these index pages.
This description matches what we observed.
Although after VACUUM, the index still has the same number of pages:
relname | relpages | reltuples
------------+----------+-----------
idx_tab2_a | 10 | 1
tab2 | 173 | 1The index scan no longer needs to access deleted pages:
lzldb=> explain (analyze,buffers) select * from tab2 where a=1; QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Index Scan using idx_tab2_a on tab2 (cost=0.12..8.14 rows=1 width=109) (actual time=0.011..0.012 rows=1 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=2
Planning Time: 0.056 ms
Execution Time: 0.025 msBefore VACUUM, shared hit=10. After VACUUM, the number of index pages hasn’t changed — still 10, with 8 pages deleted but not directly recycled, so shared hit=2. Why 2 is easy to understand: “meta page” + “the one surviving leaf page.”
Placing deleted pages in the FSM#
Recycling a page is decoupled from page deletion. A deleted page can only be put in the FSM to be recycled once there is no possible scan or search that has a reference to it; until then, it must stay in place with its sibling links undisturbed, as a tombstone that allows concurrent searches to detect and then recover from concurrent deletions (which are rather like concurrent page splits to searchers)
What is “Placing deleted pages in the FSM”? After an index page is deleted, it isn’t directly recycled. During index splits or new page allocation, it’s hard to find deleted pages for reuse. Placing deleted pages in the FSM puts these recyclable pages into the index’s corresponding FSM file, making it easy to find available free pages.
As mentioned earlier, during the first VACUUM, those deleted pages are unlinked but still occupy space. Before PG14:
We implement the technique by waiting until all active snapshots and registered snapshots as of the page deletion are gone
One condition for deletion: all active snapshots and snapshots related to the deleted pages must have ended. So long transactions definitely affect placing.
Placing an already-deleted page in the FSM to be recycled when needed doesn’t actually change the state of the page. The page will be changed whenever it is subsequently taken from the FSM for reuse. The deleted page’s contents will be overwritten by the split operation (it will become the new right sibling page).
Additionally, putting an already-deleted page into the FSM file doesn’t change the page’s state — this is just to quickly locate available free pages.
Prior to PostgreSQL 14, VACUUM would only place old deleted pages that it encounters during its linear scan (pages deleted by a previous VACUUM operation) in the FSM. Newly deleted pages were never placed in the FSM, because that was assumed to always be unsafe. PostgreSQL 14 added the ability for VACUUM to consider if it’s possible to recycle newly deleted pages at the end of the full index scan where the page deletion took place
Before PG14, deleted pages produced by the first VACUUM were not placed in the FSM. Only “old” deleted pages would be placed in the FSM file. Starting from PG14, the first VACUUM also considers placing deleted pages in the FSM.
Test (my version is PG13):
The tab2 test above just ran one VACUUM. Although deleted pages were produced, the index has no corresponding FSM file:
lzldb=> select * from pg_relation_filepath('idx_tab2_a');
pg_relation_filepath
----------------------
base/16384/16437
[postgres@lzlhost data]$ ll base/16384/16437*
-rw------- 1 postgres postgres 81920 Apr 5 11:04 base/16384/16437Now run VACUUM again:
lzldb=> vacuum tab2;
[postgres@lzlhost data]$ ll base/16384/16437*
-rw------- 1 postgres postgres 81920 Apr 5 11:04 base/16384/16437
-rw------- 1 postgres postgres 24576 Apr 5 15:52 base/16384/16437_fsmThe index immediately generated an FSM file.
Flowchart: Index Bloat and Cleanup#
Please note:
- The diagram below does not include table FSM/VM information
- The diagram below does not include deduplication information
- Version is PG13
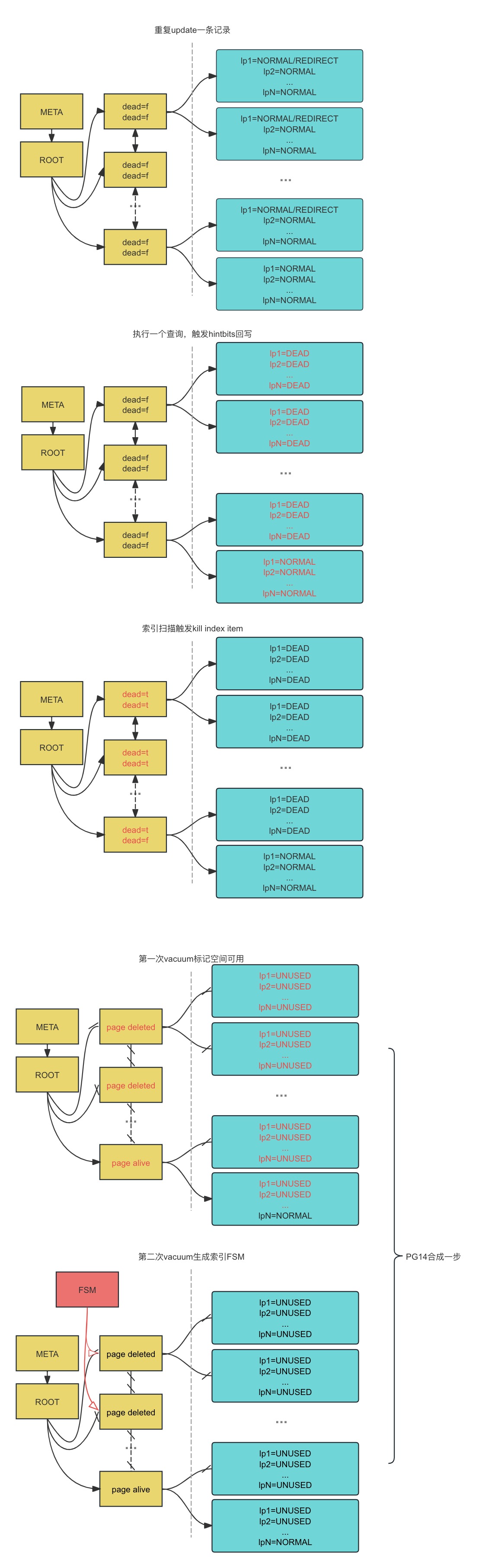
fillfactor#
Above we covered various kernel-supported methods for reducing index bloat. Beyond these approaches that require little active participation, you can also adjust table and index fillfactor to control bloat.
Fillfactor is essentially the waterline for tables or indexes. When INSERTING data, once the page reaches the fillfactor line, insertion moves to the next page. Fillfactor is designed to leave room for UPDATE operations, preventing UPDATE from frequently seeking new pages.
Although both tables and indexes have fillfactor with the same goal (accommodating UPDATE), the details differ significantly:
- Tables: If a table page still has space, UPDATE can happen within that page without needing to request a new page or go to another page with free space. Moreover, due to PostgreSQL’s unique HOT feature, in-page updates don’t update indexes, which naturally slows index bloat.
- Indexes: Different data rows or cross-page updates to the same row generate new index entries. Fillfactor leaves headroom in index pages, greatly reducing index split problems.
Of course, fillfactor settings are closely tied to your workload. If data is like logs — monotonically increasing with zero updates — then setting both table and index fillfactor to 100 is reasonable. But most production tables have updates, and table/index fillfactor should not be 100. For frequent UPDATE workloads, fillfactor should be set even lower.
However, PostgreSQL’s default fillfactor values are:
- Table default fillfactor=100
- Index default fillfactor=90
With table fillfactor=100, HOT is completely unusable! Any UPDATE immediately seeks a new data page and creates a new index entry in the index’s 10% headroom. Eventually, update-heavy workloads constantly update indexes, and even 90 fillfactor on the index can’t hold up, leading to index splits…
Here’s a fillfactor test — two tables differ only in fillfactor, updating the same amount of data, comparing the final shared hit difference:
create table tab4(a bigserial,b char(100));
create index idx_tab4_a on tab4(a);
alter index idx_tab4_a set (deduplicate_items=off); --disable index deduplication
alter table tab4 alter column b set storage PLAIN; --disable toast
alter table tab4 set (autovacuum_enabled = off); --disable autovacuum--tab5 has the same definition as tab4, except table and index fillfactor are adjusted
alter table tab5 set (fillfactor=70);
alter index idx_tab5_a set (fillfactor=80);insert into tab4(b) values('lllllllllll');
--Repeatedly update one row
DO $$
begin
FOR i IN 1..10000 LOOP
update tab4 set b=md5(i::text) where a=1;
END LOOP;
end $$;;--Primary key query with default fillfactor
lzldb=> explain (analyze,buffers) select * from tab4 where a=1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tab4 (cost=4.28..53.88 rows=16 width=412) (actual time=0.894..0.895 rows=1 loops=1)
Recheck Cond: (a = 1)
Heap Blocks: exact=1
Buffers: shared hit=174
-> Bitmap Index Scan on idx_tab4_a (cost=0.00..4.28 rows=16 width=0) (actual time=0.023..0.023 rows=173 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=1
Planning Time: 0.057 ms
Execution Time: 0.913 ms
(9 rows)
--Primary key query with lowered fillfactor
lzldb=> explain (analyze,buffers) select * from tab5 where a=1;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tab5 (cost=4.39..56.41 rows=14 width=4012) (actual time=3.367..3.369 rows=1 loops=1)
Recheck Cond: (a = 1)
Heap Blocks: exact=1
Buffers: shared hit=1434
-> Bitmap Index Scan on idx_tab5_a (cost=0.00..4.39 rows=14 width=0) (actual time=0.195..0.195 rows=1429 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=5
Planning Time: 0.059 ms
Execution Time: 3.390 msAfter lowering fillfactor, the reduction in shared hits is very significant, and Execution Time improves several times over. In fact, both data pages and index pages decreased.
So, on update-heavy production tables, lowering table and index fillfactor can mitigate bloat problems.
Summary#
Although index bloat always accompanies table bloat, their principles differ. HOT doesn’t update index entries; cross-page updates create new index entries.
Lowering table and index fillfactor can slow bloat in update-heavy production tables, ultimately also slowing down SQL queries like primary key lookups.
There are also several kernel-level features for improving index space efficiency:
- Cleaning dead index entries during index scans (index tuple deletion)
- Cleaning dead index entries during index splits (Bottom-Up index tuple deletion)
- Vacuum marking pages of entirely dead index entries (Deleting entire pages during VACUUM)
- Quickly locating recycled index pages during index splits (Placing deleted pages in the FSM)
references#
src/backend/access/nbtree/README https://mp.weixin.qq.com/s/GBN7dFQU72BfzvLSzlLmYA pg事务:事务相关元组结构 https://www.cybertec-postgresql.com/en/killed-index-tuples/ https://www.cybertec-postgresql.com/en/index-bloat-reduced-in-postgresql-v14/?spm=a2c6h.12873639.article-detail.8.2f153438mIV8JK https://www.cybertec-postgresql.com/en/b-tree-index-improvements-in-postgresql-v12/ https://www.cybertec-postgresql.com/en/b-tree-index-deduplication/