PostgreSQL Transactions
To guarantee ACID properties, an RDBMS must implement concurrency control. PostgreSQL, like Oracle and MySQL (InnoDB), uses MVCC (Multi-Version Concurrency Control) for concurrency control. MVCC works by continuously generating new versions of objects as data changes while allowing queries to access a bounded range of older versions. It captures a snapshot of data at a given point in time and selects one version to read.
Oracle and MySQL both use undo segments to record old versions of objects. PostgreSQL has no undo. Instead, during DML operations it writes historical data directly into the original table (UPDATE creates a new row, DELETE marks the row) and records additional columns — xmin and xmax — in the table to store transaction IDs. By comparing transaction IDs and other metadata, PostgreSQL implements its MVCC mechanism.
Among relational databases, PostgreSQL’s transaction mechanism is truly distinctive. Understanding it is key to grasping how PostgreSQL operates under the hood.
Transaction Isolation Levels#
Most relational databases support multiple transaction isolation levels. Under different isolation levels, concurrent transaction behavior varies.
Setting the Transaction Isolation Level#
PostgreSQL supports four isolation levels (though only three are actually effective):
{ SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }Isolation level parameters
default_transaction_isolation: sets the default isolation level for all transactions globally.
transaction_isolation: displays the isolation level of the current session.
The default isolation level is read committed.
Changing the global default isolation level
Modify the default_transaction_isolation parameter and reload:
postgres=# alter system set default_transaction_isolation to 'serializable';
ALTER SYSTEM
postgres=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres=# show transaction_isolation;
transaction_isolation
-----------------------
serializableAfter the change, every new transaction will use the default_transaction_isolation isolation level.
Setting the session isolation level
Note: transaction_isolation only displays the current session’s isolation level. This parameter cannot be modified directly.
lzldb=# alter system set transaction_isolation to 'REPEATABLE READ';
ERROR: parameter "transaction_isolation" cannot be changedUse SET SESSION to change the session’s isolation level:
lzldb=# SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET
lzldb=# show transaction_isolation ;
-[ RECORD 1 ]---------+----------------
transaction_isolation | repeatable readSetting the transaction-level isolation level
PostgreSQL allows specifying the isolation level for an individual transaction. You can set it when starting the transaction:
lzldb=# BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN
lzldb=# start TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTIONOr use set transaction after starting a transaction:
lzldb=# begin;
BEGIN
lzldb=*# set transaction ISOLATION LEVEL REPEATABLE READ;
SETANSI-92 Transaction Isolation Levels#
The ANSI SQL-92 standard defines four isolation levels:
Serializable
All transactions in the system execute serially, without interfering with each other. Executing transactions one after another avoids all data inconsistency scenarios.
Early implementations used exclusive locks to control concurrent transactions. Serial execution caused queuing and dramatically reduced system concurrency. After ANSI-92, more serializable implementation methods emerged, greatly improving both concurrency and performance.
Repeatable Read
Once a transaction begins, all data read during the transaction cannot be modified by other transactions. Repeatable Read is MySQL’s default isolation level.
Note: in ANSI SQL, Repeatable Read can experience phantom reads, but PostgreSQL’s Repeatable Read does not.
Read Committed
A transaction can read data committed by other transactions. If a transaction reads a piece of data multiple times and that data happens to be modified and committed by another transaction in between, the current transaction will see different values for the same data. This is the default isolation level for both Oracle and PostgreSQL.
At this isolation level, both “non-repeatable read” and “phantom read” scenarios can occur.
Read Uncommitted
A transaction can read data that has been modified but not yet committed by other transactions. Since uncommitted data can still be rolled back, reading such data leads to “dirty reads.”
At this isolation level, “dirty read” scenarios can occur.
PostgreSQL does not have a Read Uncommitted isolation level. Setting Read Uncommitted is treated as Read Committed.
Standard concurrency phenomena and isolation level matrix
| Isolation Level | Dirty Read | Non-repeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted | Possible | Possible | Possible |
| Read Committed | Impossible | Possible | Possible |
| Repeatable Read | Impossible | Impossible | Possible |
| Serializable | Impossible | Impossible | Impossible |
PostgreSQL concurrency phenomena and isolation level matrix
| Isolation Level | Dirty Read | Non-repeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted | Impossible | Possible | Possible |
| Read Committed | Impossible | Possible | Possible |
| Repeatable Read | Impossible | Impossible | Impossible |
| Serializable | Impossible | Impossible | Impossible |
A Brief History of Transaction Isolation Levels#
The isolation levels and anomaly phenomena defined by ANSI SQL-92 have had a profound impact on the database industry. Even today, over 30 years later, most engineers’ understanding of transaction isolation levels still revolves around them, and many real-world database isolation level implementations still follow them. However, the post-ANSI-92 era has seen much discussion and even criticism regarding isolation levels. Here is a summary of the key historical developments:
1992: The database industry was in a chaotic state regarding transactions, so ANSI defined the SQL-92 standard — the widely known 4 isolation levels and 4 anomaly phenomena.
1995: Snapshot Isolation and other isolation levels were proposed, along with more anomaly phenomena. Microsoft engineers proposed the Snapshot Isolation level and criticized ANSI SQL-92, noting that the standard was vaguely defined and many isolation levels and anomalies were left undefined. See A Critique of ANSI SQL Isolation Levels. By this point, there were more than 4 isolation levels and more anomaly phenomena, including write skew.
1999: Due to the proliferation of lock-based isolation levels, Atul Adya’s paper organized these phenomena and mapped the various isolation levels back to ANSI SQL-92 based on anomaly phenomena and functionality.
2005: Because most databases claimed to be serializable but were actually Snapshot Isolation, Alan Fekete et al proposed Making Snapshot Isolation Serializable — achieving serializability on top of Snapshot Isolation by eliminating its anomalies.
2008: Fekete extended serializability and proposed a database-level implementation called Serializable Snapshot Isolation (SSI).
2012: PostgreSQL became the first database to implement SSI. See the PostgreSQL SSI implementation paper.
Isolation levels and anomaly phenomena from the 1995 Critique of ANSI SQL Isolation Levels:
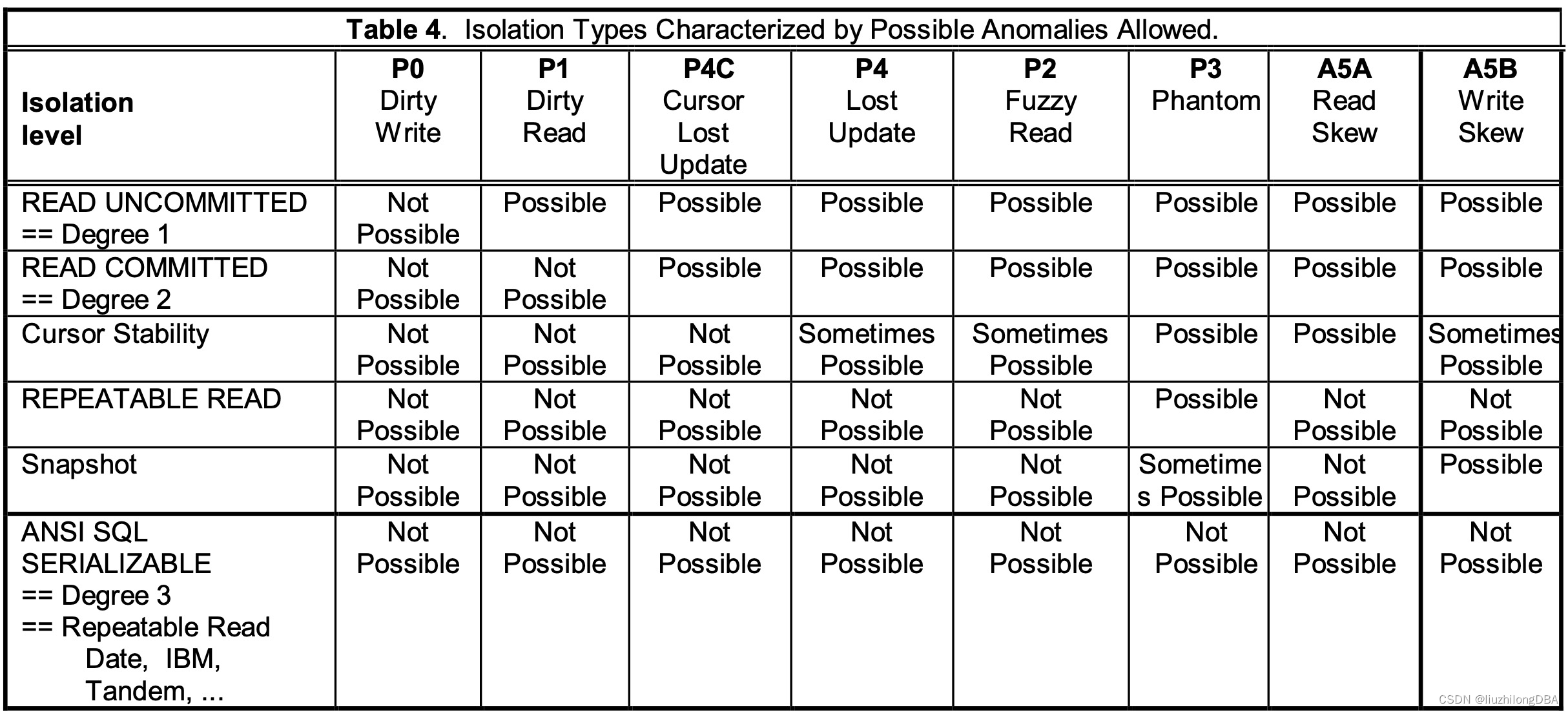
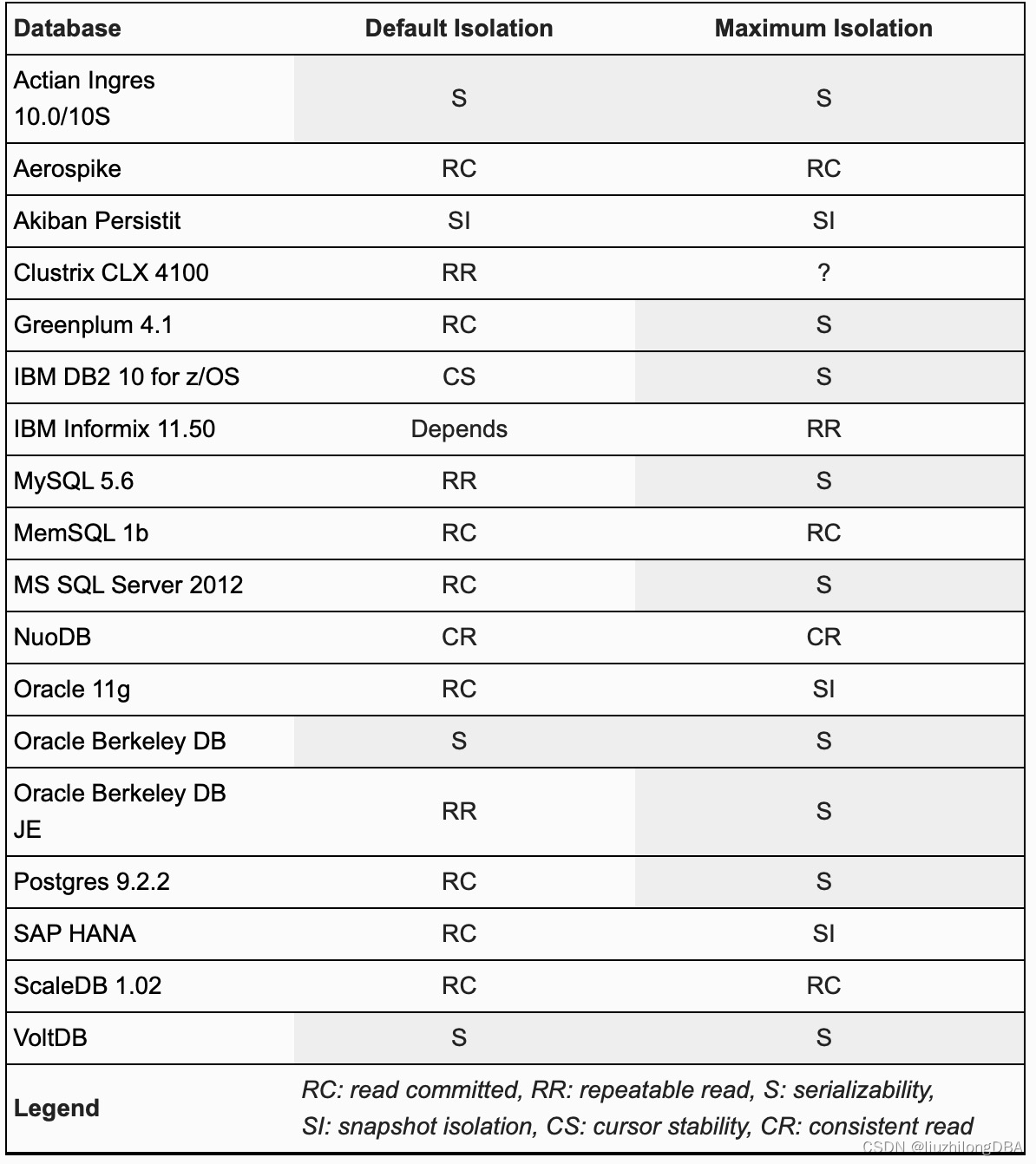
Isolation Levels Supported by Various Databases#
Many databases claim “full ACID” compliance, but without serializability, ACID cannot be fully realized (especially consistency). Yet many databases claim ACID support even without serializability. The truth is, most do not fully implement it — including the veteran Oracle.
Serializable#
There are many misconceptions about serializability.
The meaning of serializable: if each transaction is itself correct (satisfying certain integrity conditions), then any schedule that executes those transactions serially is also correct (the transactions still satisfy their conditions). “Serial” means transactions do not overlap in time and cannot interfere with each other — they are fully isolated.
In the 1970s, serializability was achieved through Strict Two-Phase Locking (SS2PL), where reads and writes block each other until the transaction ends. SS2PL sacrifices high availability but eliminates anomaly phenomena.
Beyond SS2PL, there are other ways to achieve serializability, such as Serializable Snapshot Isolation (SSI).
To guarantee no anomalies, serializability sacrifices some concurrency (how much depends on the implementation), but it can truly guarantee data consistency (the “C” in ACID). In other words, databases that do not implement serializability do not fully support ACID.
Serializability has been mathematically proven achievable, but the real database world is somewhat “abnormal.” In practice, serializability is the highest transaction isolation level and the one strongly recommended by academics and experts. However, the vast majority of databases run at Read Committed or Snapshot Isolation.
Why Do Weaker Isolation Levels Cause Academic Problems but Few Real-World Disasters?#
Anomalies in non-serializable isolation levels generally require high concurrency. Low-concurrency databases rarely encounter problems.
When anomalies do occur, some applications may not detect them or may not consider them important.
It is possible that data becomes anomalous but the application simply returns an error and enters exception-handling logic.
Cost is too high. Not only is the development cost of serializable isolation high for the database, but applications also need to adapt. Simply understanding this complex theory is no easy task.
Higher isolation levels lose some performance. Extensive rework may not be worth it; applications must choose between “high concurrency” and “freedom from anomalies.”
Business logic is built around mechanisms, not rules. Applications have somewhat adapted to the anomalies of weaker isolation levels, especially Read Committed or Snapshot Isolation.
Snapshot Isolation#
ANSI SQL-92 did not define Snapshot Isolation (SI). This isolation level emerged as the database industry evolved.
Quoting the Wikipedia definition: a transaction executing under Snapshot Isolation operates on a snapshot of the database taken at the start of the transaction. When the transaction ends, it will only commit successfully if the values it updated have not been externally changed since the snapshot was taken. Write conflicts thus cause transaction aborts.
As the name implies, Snapshot Isolation uses snapshots. It exists in databases that use MVCC, where the multi-version concurrency mechanism supports concurrent transaction execution.
The 1992 ANSI SQL-92 standard was defined based on database locks, so it did not define Snapshot Isolation. The concept only emerged with the 1995 Critique.
Serializable Snapshot Isolation#
Due to the widespread adoption of Snapshot Isolation and the academic goal that databases should achieve serializability, Serializable Snapshot Isolation (SSI) was born. As the name suggests, it achieves serializability on top of Snapshot Isolation.
Because of the ambiguity of the ANSI-92 standard, although Snapshot Isolation was not defined, many databases actually use it. Snapshot Isolation also has certain anomaly phenomena (including write skew), and SSI was created to resolve them.
Mainstream databases implement concurrency control via S2PL or MVCC. Under S2PL, write operations block reads and writes from other transactions, so there is no write skew. MVCC, however, allows reads and writes not to block each other — only write-write conflicts. In concurrent read-write patterns, this leads to write skew. Starting from PostgreSQL 9.1, SSI has been embedded into Snapshot Isolation (PostgreSQL only has Snapshot Isolation, even at the serializable level), resolving write skew and other anomalies.
Write Skew#
When certain conflicts form a cycle, serialization anomalies occur. One of the easier ones to understand is write skew.
Write skew only happens in read-write patterns (not write-write or write-read), and only under concurrent conditions. A dependency cycle forms when a preceding transaction’s write depends on a later transaction’s write.
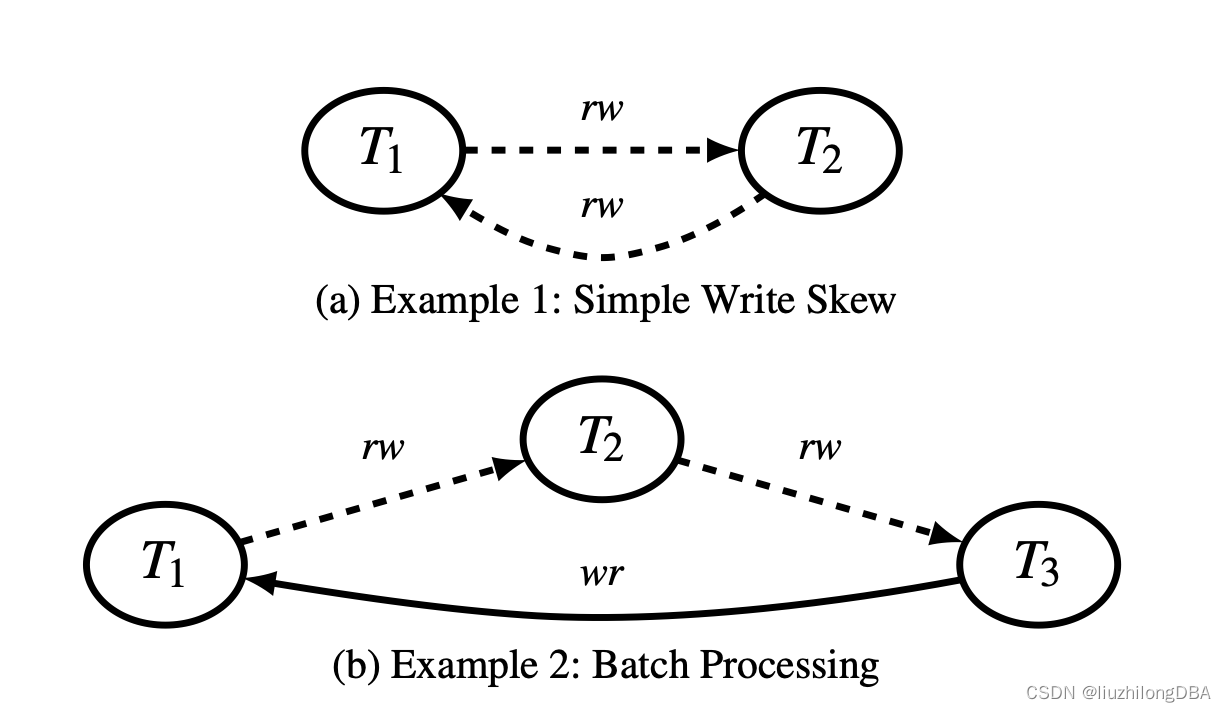
There are many real-world cases of write skew. Let’s understand it through the classic black-and-white ball problem:
A bag contains 10 balls: 5 white and 5 black. Two transactions, P and Q, are running. P changes all black balls to white; Q changes all white balls to black. There are two possible serial executions: P then Q, or Q then P. In both cases, the final result is either 10 white balls or 10 black balls. However, Snapshot Isolation allows another outcome:
- Transaction P picks up 5 black balls
- Transaction Q picks up 5 white balls
- Transaction P changes all the balls in hand to white and puts them back
- Transaction Q changes all the balls in hand to black and puts them back
Now the bag still has 5 black and 5 white balls — an outcome impossible in any serial execution. Yet this is valid under Snapshot Isolation: each transaction maintains a consistent view of the database, and its write set does not overlap with any concurrent transaction’s write set. Hence, the black and white balls are swapped.
The black-and-white ball problem illustrates: the result under Snapshot Isolation is inconsistent with the result under serial execution. Write skew occurs under Snapshot Isolation, and the data outcome does not match expectations.
SSI in PostgreSQL#
PostgreSQL was the first database to implement SSI. Here is the black-and-white ball example using the Wikipedia code:
create table dots
(
id int not null primary key,
color text not null
);
insert into dots
with x(id) as (select generate_series(1,10))
select id, case when id % 2 = 1 then 'black'
else 'white' end from x;| set default_transaction_isolation = ‘serializable’; | set default_transaction_isolation = ‘serializable’; |
|---|---|
| begin; update dots set color = ‘black’ where color = ‘white’; | |
| begin; update dots set color = ‘white’ where color = ‘black’; | |
| commit | |
| commit | |
| (PostgreSQL SSI: first committer succeeds, second throws an error) | ERROR: could not serialize access due to read/write dependencies among transactions DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt. HINT: The transaction might succeed if retried. |
(At Read Committed and Repeatable Read, no error is thrown; the black and white balls simply swap colors. Test results omitted.)
Strict Two-Phase Locking (S2PL) can also achieve serializability, but S2PL requires heavy read-write locks held until transaction commit. S2PL severely impacts concurrency performance, and users generally won’t accept reads and writes blocking each other, so PostgreSQL does not use S2PL.
SSI is an alternative approach to serializability. It still uses Snapshot Isolation but additionally checks for anomaly phenomena. The two approaches also handle anomalies differently: when one occurs, S2PL blocks transactions, while SSI aborts a transaction to break the cycle.
One reason people avoid serializability is that it supposedly reduces database performance. This is understandable — SSI, which performs “anomaly checks,” must be slower than weaker isolation levels that do no such checking. However, with advances in SSI implementation theory and PostgreSQL’s optimizations for read-only transactions, SSI’s performance is now on par with SI.
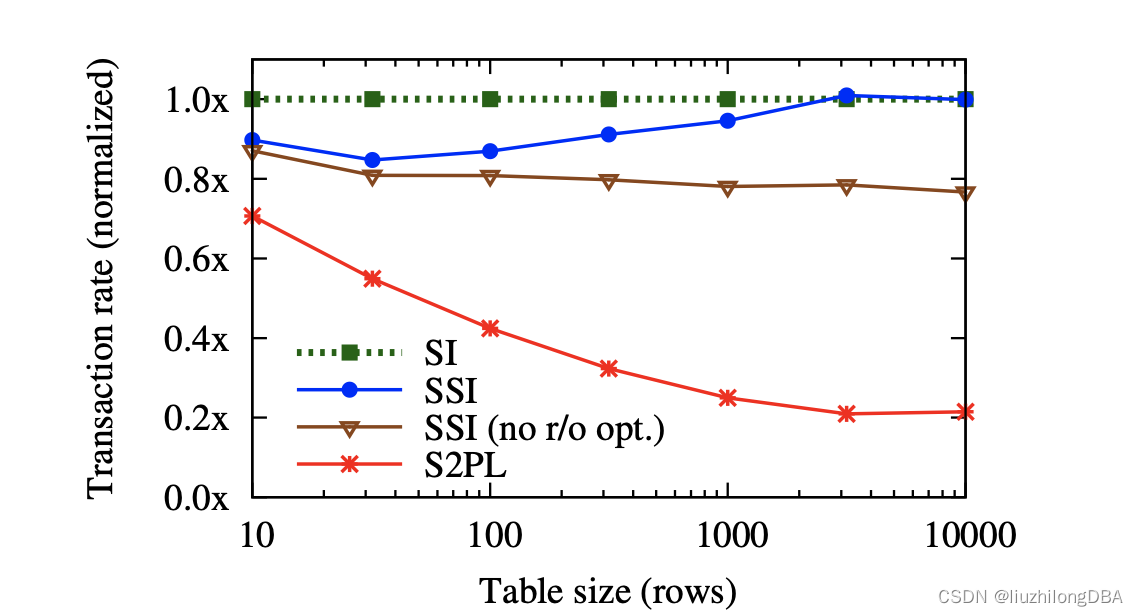
Serializability greatly simplifies applications’ consistency concerns. PostgreSQL 9.1 has implemented SSI with optimizations. Let’s hope applications will one day truly adopt the serializable isolation level.
Transaction Isolation Level References#
https://wiki.postgresql.org/wiki/SSI
https://en.wikipedia.org/wiki/Serializability
https://en.wikipedia.org/wiki/Snapshot_isolation
https://justinjaffray.com/what-does-write-skew-look-like/
http://www.bailis.org/blog/when-is-acid-acid-rarely/
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf — 1995 paper on SI isolation levels and critique of SQL-92
https://www.cse.iitb.ac.in/infolab/Data/Courses/CS632/2009/Papers/p492-fekete.pdf — SSI paper
https://drkp.net/papers/ssi-vldb12.pdf — PostgreSQL SSI implementation
https://ristret.com/s/f643zk/history_transaction_histories — History of transaction isolation levels
Transaction Processing#
Transaction Blocks#
Transactions can be implicit or explicit. An implicit transaction is a standalone SQL statement that auto-commits upon completion. An explicit transaction requires an explicit declaration; multiple SQL statements grouped together form a transaction block.
Transaction blocks begin with begin, begin transaction, or start transaction.
They end with COMMIT, END, or ABORT, ROLLBACK, where COMMIT=END and ABORT=ROLLBACK.
BEGIN;
select * from lzl1 limit 1;
update lzl1 set a=2;
END;If an error occurs during a transaction block, the transaction can only be rolled back due to atomicity:
lzldb=# begin;
BEGIN
lzldb=*# select * from lzl2;
ERROR: relation "lzl2" does not exist
LINE 1: select * from lzl2;
^
lzldb=!# commit;
ROLLBACKTransaction Processing Functions#
Transaction processing functions are organized into three layers: top-level transaction functions, middle-level transaction functions, and bottom-level transaction functions.
Top-level transaction functions handle transaction block commands like BEGIN, COMMIT, ROLLBACK, SAVEPOINT, etc.:
| BeginTransactionBlock | Start a transaction block |
|---|---|
| EndTransactionBlock | End a transaction block |
| UserAbortTransactionBlock | User-initiated transaction abort |
| DefineSavepoint | Create a savepoint |
| RollbackToSavepoint | Roll back to a savepoint |
| ReleaseSavepoint | Release a savepoint |
Middle-level transaction functions: every SQL statement calls middle-level functions before and after execution, including after detecting an exception:
| StartTransactionCommand | Start a transaction command |
|---|---|
| CommitTransactionCommand | Complete a transaction command (not commit) |
| AbortCurrentTransaction | Abort the current transaction |
Bottom-level transaction functions: the actual transaction processing functions, responsible for maintaining transaction state, allocating and reclaiming transaction resources, etc.:
| StartTransaction | Start a transaction |
|---|---|
| CommitTransaction | Commit a transaction |
| AbortTransaction | Rollback/abort a transaction |
| CleanupTransaction | Clean up a transaction |
| StartSubTransaction | Start a subtransaction |
| CommitSubTransaction | Commit a subtransaction |
| AbortSubTransaction | Rollback/abort a subtransaction |
| CleanupSubTransaction | Clean up a subtransaction |
These functions are fairly easy to distinguish. Aside from a few special functions (top-level savepoint-related, middle-level abort function), the three layers are organized as: *Block (transaction block functions), *Command (command functions), and *Transaction (actual transaction processing functions). Savepoints/subtransactions are treated as transaction-block-level functions (subtransactions can be rolled back within a transaction block, so placing them at the block level makes sense), and abort is treated as a command-level function.
Transaction Block States#
Top-level and middle-level functions jointly control the transaction block state; bottom-level functions control the transaction state.
Both transaction block states and transaction states are in src/backend/access/transam/xact.c:
typedef enum TBlockState
{
/* states not in a transaction block */
TBLOCK_DEFAULT, /* idle state; entering or exiting a transaction returns to this state */
TBLOCK_STARTED, /* just entered a transaction block; transitions from TBLOCK_DEFAULT; short-lived */
/* transaction block states */
TBLOCK_BEGIN, /* start a transaction block; at this point data block is started, entering block-level state */
TBLOCK_INPROGRESS, /* active transaction; after BEGIN, the block stays in this state until transaction ends */
TBLOCK_IMPLICIT_INPROGRESS, /* active transaction with an implicit BEGIN */
TBLOCK_PARALLEL_INPROGRESS, /* active transaction in parallel execution */
TBLOCK_END, /* received COMMIT command */
TBLOCK_ABORT, /* transaction failed, waiting for ROLLBACK */
TBLOCK_ABORT_END, /* transaction failed, received ROLLBACK */
TBLOCK_ABORT_PENDING, /* active transaction, received ROLLBACK */
TBLOCK_PREPARE, /* active transaction, received PREPARE (explicit 2PC) */
/* subtransaction states (still transaction-block level) */
TBLOCK_SUBBEGIN, /* start a subtransaction */
TBLOCK_SUBINPROGRESS, /* active subtransaction */
TBLOCK_SUBRELEASE, /* received RELEASE (release savepoint) */
TBLOCK_SUBCOMMIT, /* parent transaction COMMIT while subtransaction is still running (SUBINPROGRESS) */
TBLOCK_SUBABORT, /* failed subtransaction, waiting for rollback command */
TBLOCK_SUBABORT_END, /* failed subtransaction, received rollback command */
TBLOCK_SUBABORT_PENDING, /* active subtransaction, received rollback command */
TBLOCK_SUBRESTART, /* active subtransaction, received rollback to command */
TBLOCK_SUBABORT_RESTART /* failed subtransaction, received ROLLBACK TO command */
} TBlockState;Most states are self-explanatory. A note on rollback vs. abort: their subsequent behavior is similar — both need to clean up transaction resources and exit the current transaction. Yet PostgreSQL separates them into two behaviors with two states: TBLOCK_ABORT and TBLOCK_ABORT_END (and similarly for subtransactions). Why?
src/backend/access/transam/README offers a detailed explanation:
Scenario 1 Scenario 2 1) User types BEGIN1) User types BEGIN2) User executes some commands 2) User executes some commands 3) User doesn’t like what she sees, types ABORT3) The transaction system aborts for some reason (syntax error, etc.) In Scenario 1, we want to abort the transaction and return to the default state.
In Scenario 2, more commands may follow that are still part of the current transaction block. We must ignore these commands until we see
COMMITorROLLBACK.
AbortCurrentTransactionhandles internal transaction aborts;UserAbortTransactionBlockhandles user-initiated aborts. Both rely onAbortTransactionto do all the real work. The only difference is what state we enter afterAbortTransactionfinishes:* AbortCurrentTransaction leaves us in TBLOCK_ABORT
* UserAbortTransactionBlock leaves us in TBLOCK_ABORT_END
Bottom-level transaction abort processing has two phases:
* As soon as we realize the transaction has failed,
AbortTransactionis executed. This should release all shared resources (locks, etc.) to avoid unnecessarily increasing latency for other backends.* When we finally see the user’s
COMMITorROLLBACK,CleanupTransactionis executed; this function cleans up resources and gets us completely out of the transaction. In particular, we cannot destroyTopTransactionContextbefore this point.
Transaction States#
Transaction states are straightforward (note: these are different from transaction block states):
typedef enum TransState
{
TRANS_DEFAULT, /* idle */
TRANS_START, /* transaction started */
TRANS_INPROGRESS, /* active transaction */
TRANS_COMMIT, /* transaction commit */
TRANS_ABORT, /* abort transaction */
TRANS_PREPARE /* prepare transaction (2PC) */
} TransState;Transaction State Flow#
Each command in a transaction block calls transaction functions, which in turn transition the transaction and transaction block states.
Let’s use the simplest transaction block as an example (from the README):
1)BEGIN
2)SELECT * FROM foo
3)INSERT INTO foo VALUES (...)
4)COMMITCommand call relationships:
/ StartTransactionCommand; -- middle-level: start transaction command
/ StartTransaction; -- bottom-level: actually start the transaction
1)< ProcessUtility; -- ProcessUtility handles the BEGIN command
\ BeginTransactionBlock; -- top-level: start transaction block
\ CommitTransactionCommand; -- middle-level: complete command
/ StartTransactionCommand; -- middle-level: start transaction command
2) / PortalRunSelect; -- execute SELECT statement
\ CommitTransactionCommand; -- middle-level: complete command
\ CommandCounterIncrement; -- middle-level: command counter increment
/ StartTransactionCommand; -- middle-level: start transaction command
3) / ProcessQuery; -- execute INSERT statement
\ CommitTransactionCommand; -- middle-level: complete command
\ CommandCounterIncrement; -- command counter +1
/ StartTransactionCommand; -- middle-level: start transaction command
/ ProcessUtility; -- ProcessUtility handles COMMIT command
4) < EndTransactionBlock; -- top-level: end transaction block
\ CommitTransactionCommand; -- middle-level: complete command
\ CommitTransaction; -- bottom-level: actually commit the transaction
- Every command in a transaction block begins with the middle-level
StartTransactionCommandand ends withCommitTransactionCommand. - Between these two middle-level functions is where the actual command processing occurs.
The transaction block state for 2) SELECT and 3) INSERT is TBLOCK_INPROGRESS. The state transitions for BEGIN and COMMIT:
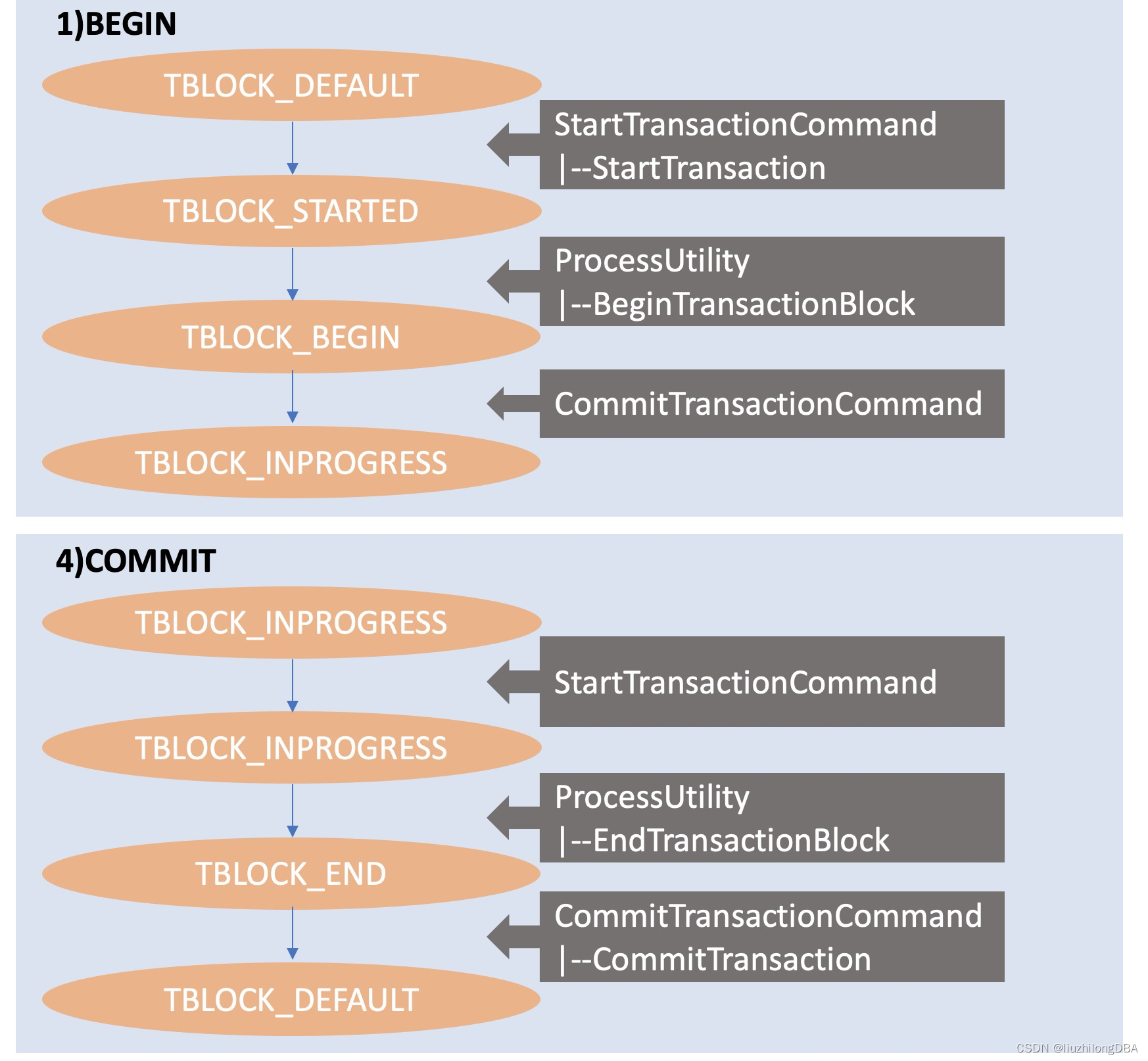
Transaction Function References#
PostgreSQL Internals (book)
src/backend/access/transam/README
Transaction ID#
Every transaction in PostgreSQL is assigned a transaction ID. Transaction IDs come in two forms: virtual transaction IDs and persistent transaction IDs. Understanding transaction IDs is crucial for grasping transactions, data visibility, transaction ID wraparound, and more.
Virtual Transaction ID#
Read-only transactions are not assigned a transaction ID — transaction IDs are a precious resource. A simple SELECT, for instance, won’t consume one. However, to identify transactions for purposes such as shared locks, a non-persistent transaction ID is needed. This is the virtual transaction ID (VXID).
VXID consists of two parts: a backend ID and a backend-local counter.
Source: src/include/storage/lock.h
typedef struct
{
BackendId backendId; /* backendId from PGPROC */
LocalTransactionId localTransactionId; /* lxid from PGPROC */
} VirtualTransactionId;(PGPROC is a structure storing process information; we’ll cover it later.)
You can see VXID in pg_locks. Querying pg_locks itself is a SQL statement, so it generates a VXID:
lzldb=# begin;
BEGIN
lzldb=*# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/16 | AccessShareLock
virtualxid | 4/16 | 4/16 | ExclusiveLock
(2 rows)
lzldb=*# savepoint p1;
SAVEPOINT
lzldb=*# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/16 | AccessShareLock
virtualxid | 4/16 | 4/16 | ExclusiveLock
lzldb=*# rollback;
ROLLBACK
lzldb=# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/17 | AccessShareLock
virtualxid | 4/17 | 4/17 | ExclusiveLockAfter \q (disconnect) and immediately logging back in, the counter continues: 4/19.
Opening another window gives backendID+1:
lzldb=# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 5/3 | AccessShareLock
virtualxid | 5/3 | 5/3 | ExclusiveLockFrom these tests we can observe:
- The VXID’s backend ID is not the actual process PID; it’s simply an incrementing number.
- Both the VXID’s backend ID and command counter are incrementing.
- Subtransactions do not have their own VXID; they use the parent transaction’s VXID.
- VXID also has wraparound, but it’s not a serious issue since it isn’t persisted — after an instance restart, VXID starts counting from scratch.
Persistent Transaction ID#
32-bit TransactionId#
When a data-modifying transaction begins, the transaction manager assigns it a unique identifier: TransactionId. TransactionId is a 32-bit unsigned integer, capable of storing 2^32 = 4,294,967,296 — about 4.2 billion — transactions. The range of a 32-bit unsigned integer is 0 ~ 2^32 - 1.
Three special transaction IDs
src/include/access/transam.h defines several special transaction IDs:
#define InvalidTransactionId ((TransactionId) 0)
#define BootstrapTransactionId ((TransactionId) 1)
#define FrozenTransactionId ((TransactionId) 2)
#define FirstNormalTransactionId ((TransactionId) 3)
#define MaxTransactionId ((TransactionId) 0xFFFFFFFF)- 0: Invalid TransactionId
- 1: Bootstrap Transaction ID, used only during database initialization. Older than all normal transactions.
- 2: Frozen Transaction ID. Older than all normal transactions.
#define TransactionIdIsNormal(xid) ((xid) >= FirstNormalTransactionId)A transaction ID >= 3 is a normal transaction ID.
The maximum transaction ID, MaxTransactionId, is 0xFFFFFFFF = 4,294,967,295 = 2^32 - 1.
So the allocatable range for normal transaction IDs is: 3 ~ 2^32 - 1.
64-bit FullTransactionId#
Transaction IDs increment sequentially. PostgreSQL has used 32-bit transaction IDs for a long time. Before PostgreSQL 7.2, when the 32-bit transaction ID was exhausted, you had to dump and restore the database. A 64-bit transaction ID, on the other hand, is practically inexhaustible. The source defines a 64-bit FullTransactionId as a struct:
/*
*A 64-bit value containing an epoch and a TransactionId.
*It is wrapped in a struct to prevent implicit conversion to TransactionId.
*Not all values represent valid normal XIDs.
*/
typedef struct FullTransactionId
{
uint64 value;
} FullTransactionId;The 64-bit value consists of an epoch and a 32-bit TransactionId, converted via these functions:
#define EpochFromFullTransactionId(x) ((uint32) ((x).value >> 32))
#define XidFromFullTransactionId(x) ((uint32) (x).value)The epoch is FullTransactionId shifted right 32 bits; the XID (TransactionId) is FullTransactionId modulo 2^32. This is like treating the 32-bit TransactionId as a “circle” that loops, while the 64-bit FullTransactionId is a “line” that keeps growing, nearly inexhaustible.
A full transaction ID can exceed 2^32:
Transaction ID Assignment#
Let’s run a few experiments to see how transaction IDs are assigned. We’ll use two functions that return transaction IDs:
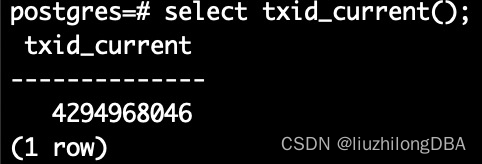
pg_current_xact_id(): returns the current transaction ID; if the current transaction has not yet been assigned one, it allocates one. (In pg12 and earlier, use txid_current().)
pg_current_xact_id_if_assigned(): returns the current transaction ID; if the current transaction has not yet been assigned one, returns NULL. (In pg12 and earlier, use txid_current_if_assigned().)
Transaction IDs are assigned sequentially:
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
612
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
613
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
614BEGIN does not immediately allocate a transaction ID:
lzldb=# begin; -- explicitly start a transaction
BEGIN
lzldb=*# select pg_current_xact_id_if_assigned () ; -- BEGIN does not immediately allocate a transaction ID
pg_current_xact_id_if_assigned
--------------------------------
(1 row)
lzldb=*# select * from lzl1; -- query immediately after BEGIN
a
---
(0 rows)
lzldb=*# select pg_current_xact_id_if_assigned () ; -- queries do not allocate transaction IDs
pg_current_xact_id_if_assigned
--------------------------------
(1 row)
lzldb=*# insert into lzl1 values(1); -- insert data, a data change
INSERT 0 1
lzldb=*# select pg_current_xact_id_if_assigned () ; -- the first non-query statement after BEGIN allocates a transaction ID
pg_current_xact_id_if_assigned
--------------------------------
611
lzldb=*# commit;
COMMIT
lzldb=# select xmin, pg_current_xact_id_if_assigned () from lzl1; -- the INSERT transaction writes to xmin
xmin | pg_current_xact_id_if_assigned
------+--------------------------------
611 Some records in system catalogs were assigned BootstrapTransactionId=1 during database initialization:
postgres=# select xmin,count(*) from pg_class where xmin=1 group by xmin;
xmin | count
------+-------
1 | 184Conclusions from the experiments:
- During database initialization, the special transaction ID 1 is assigned, visible in system catalogs.
- Transaction IDs are assigned incrementally.
- BEGIN does not immediately allocate a transaction ID; the first non-query statement after BEGIN allocates one.
- When a transaction inserts a tuple, the transaction’s txid is written into the tuple’s xmin.
Transaction ID Comparison#
PostgreSQL compares the age of transactions by their transaction IDs. src/backend/access/transam/transam.c defines four comparison functions: <, <=, >, >=:
bool TransactionIdPrecedes()
bool TransactionIdPrecedesOrEquals()
bool TransactionIdFollows()
bool TransactionIdFollowsOrEquals()They are similar. Let’s examine TransactionIdPrecedes() as the representative:
bool
TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}Key points from this source code:
TransactionIdIsNormal()is a macro defined in the header to check for normal transactions.FirstNormalTransactionIdis the constant 3. So a normal transaction ID is >= 3.
#define TransactionIdIsNormal(xid) ((xid) >= FirstNormalTransactionId)int32is a signed integer: the first bit being 0 means positive, 1 means negative. Range:-2^31 ~ 2^31 - 1.- Integer overflow: when a value exceeds the storage range (e.g.,
2^31barely overflows for int32), the value wraps around.
The transaction ID comparison code can be understood in two parts:
Non-normal transaction ID comparison:
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);When id1=2, id2=100: return(2<100), precedes is true — the normal transaction is newer.
When id1=100, id2=2: return(100<2), precedes is false — the normal transaction is newer.
So, txid 1 and 2 are older than normal transactions.
Normal transaction ID comparison:
diff = (int32) (id1 - id2);
return (diff < 0);id1 - id2 can be negative, so diff cannot be unsigned int. It must be cast to signed int. Now the crucial part:
Since int32 ranges from -2^31 to 2^31 - 1:
When id1 = 2^31 + 99, id2 = 100: id1 - id2 = 2^31 - 1. Fine — int32 can hold this. → Larger txid is newer.
When id1 = 2^31 + 100, id2 = 100: id1 - id2 = 2^31. Problem — exactly exceeds int32 storage. The value becomes 2^31 - 2^32 = -2^31 < 0. → Smaller txid is considered newer.
When id1 = 100, id2 = 2^31 + 100: id1 - id2 = -2^31. Fine — int32 can hold this. → Larger txid is newer.
When id1 = 100, id2 = 2^31 + 101: id1 - id2 = -2^31 - 1. Problem — exactly exceeds int32 storage. The value becomes -2^31 - 1 + 2^32 = 2^31 - 1 > 0. → Smaller txid is considered newer.
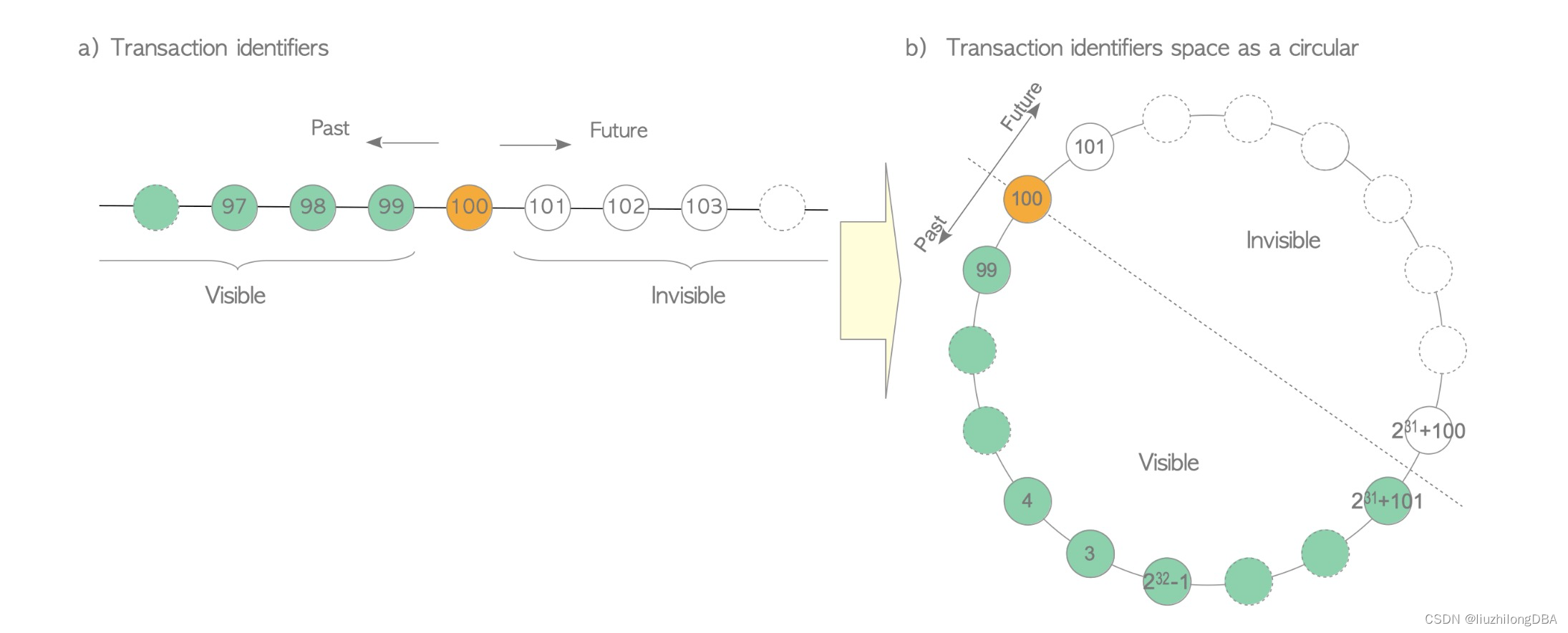
From this analysis, when integer overflow occurs, a transaction with a larger txid cannot see a transaction with a smaller txid. The overflow itself is an exceptional event, so this is acceptable. To address this, PostgreSQL divides the 4-billion transaction ID space into two halves: one half is visible, the other invisible.
For example, for transaction txid 100, the 2 billion transactions in its past are visible, and the 2 billion transactions in its future are invisible. Therefore, the maximum difference between the oldest and newest transaction IDs (the database age) in PostgreSQL is |-2^31| = 2^31, roughly 2 billion.
Transaction ID Wraparound#
What is transaction ID wraparound?
Understanding transaction ID wraparound itself is not difficult, but when I first studied it, I found two different definitions:
PostgreSQL official definition:
Because transaction IDs are limited in size (32 bits), a cluster that runs for a long time (more than 4 billion transactions) will suffer transaction ID wraparound: the XID counter wraps around to zero, and suddenly past transactions appear to be in the future — meaning they become invisible. In short, catastrophic data loss. (The data is still there, but you can’t access it.)
interdb explanation:
A tuple’s t_xmin records the minimum transaction of that tuple. If the tuple never changes, this t_xmin stays the same. Suppose tuple_1 was created by transaction txid=100, so its t_xmin=100. If the database advances by 2^31 transactions, reaching 2^31+100, tuple_1 is still visible. Then another transaction starts, advancing txid to 2^31+101. Now txid=100 is in the “future,” so tuple_1 becomes invisible. This is severe data loss — this is transaction ID wraparound.
Yes, the official documentation and some classic articles define transaction ID wraparound differently. They are indeed describing two different things. I attribute this to a translation issue: both behaviors are wraparound in English semantics. If you reconsider the meaning of “wraparound,” they are both forms of it.
However, they differ: one is when transaction IDs (2^32) are fully exhausted and wrap back to 0; the other is when the “oldest transaction ID” and “newest transaction ID” differ by more than 2^31.
- The official definition of transaction ID wraparound introduces the concept that “transaction IDs form a circle.”
- The generally understood transaction ID wraparound problem is the “circle divided into two halves, one visible, one invisible” concept — when the “more than half” threshold is crossed, that’s wraparound.
In practice, the wraparound problem you actually need to worry about is the latter: the difference between the newest and oldest transaction IDs must not exceed 2.1 billion (2^31).
How long does 2.1 billion transactions take?
2.1 billion transactions sounds like a lot, but it can still be exhausted.
For example, a PostgreSQL database with 100 TPS (not counting SELECT statements, since simple SELECTs don’t allocate transaction IDs) uses 8,640,000 transactions per day. It takes only about 2,147,483,648 / 8,640,000 ≈ 248 days to exhaust 2.1 billion transaction IDs and trigger wraparound. At 1,000 transactions per second, it takes less than one month. So transaction ID wraparound is something you must pay attention to in PostgreSQL.
Transaction ID Freezing#
To solve the serious data loss problem caused by transaction ID wraparound, PostgreSQL introduced the concept of transaction freezing.
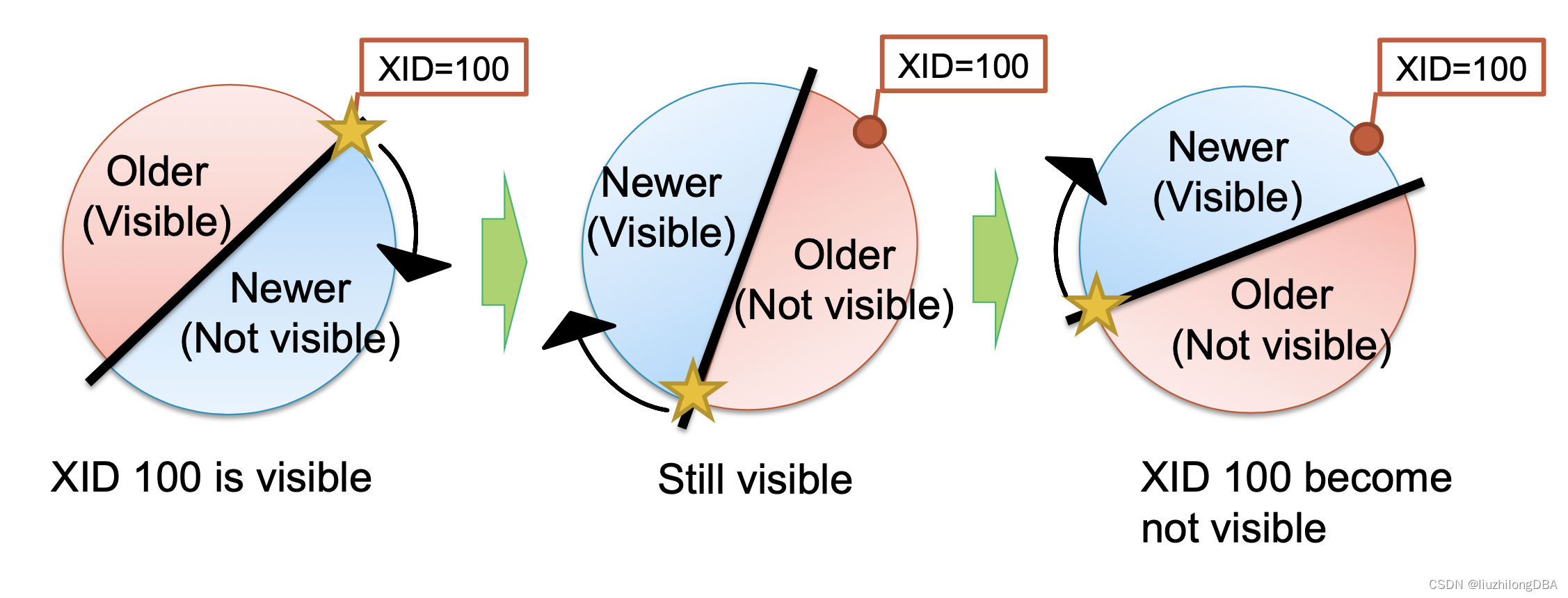
XIDs are reused cyclically and divided into two halves: one visible, one invisible. For a tuple with xid=100, if no operations are performed and transaction IDs keep advancing, the once-visible tuple will eventually become invisible.
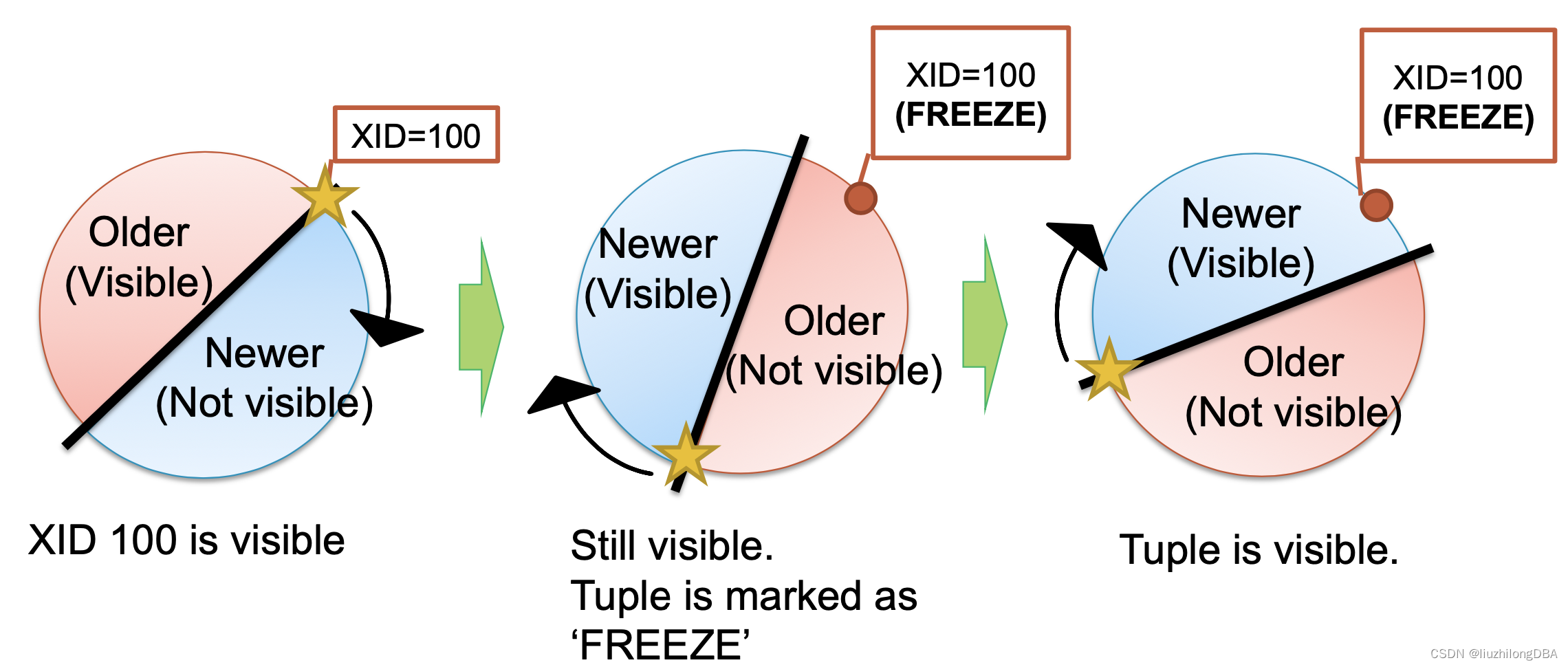
As mentioned earlier, there is a frozen transaction ID. If the tuple with xid=100 is marked with the frozen transaction ID, it will remain visible. This is the purpose of transaction freezing.
The frozen transaction ID FrozenTransactionId = 2, and it is older than all normal transactions. That means txid=2 is visible to all normal transactions (txid >= 3). When t_xmin is older than current_txid - vacuum_freeze_min_age (default 50 million), the tuple is rewritten with the frozen transaction ID 2. In version 9.4 and later, the xmin_frozen flag in t_infomask is used to indicate a frozen tuple, rather than rewriting t_xmin to 2.
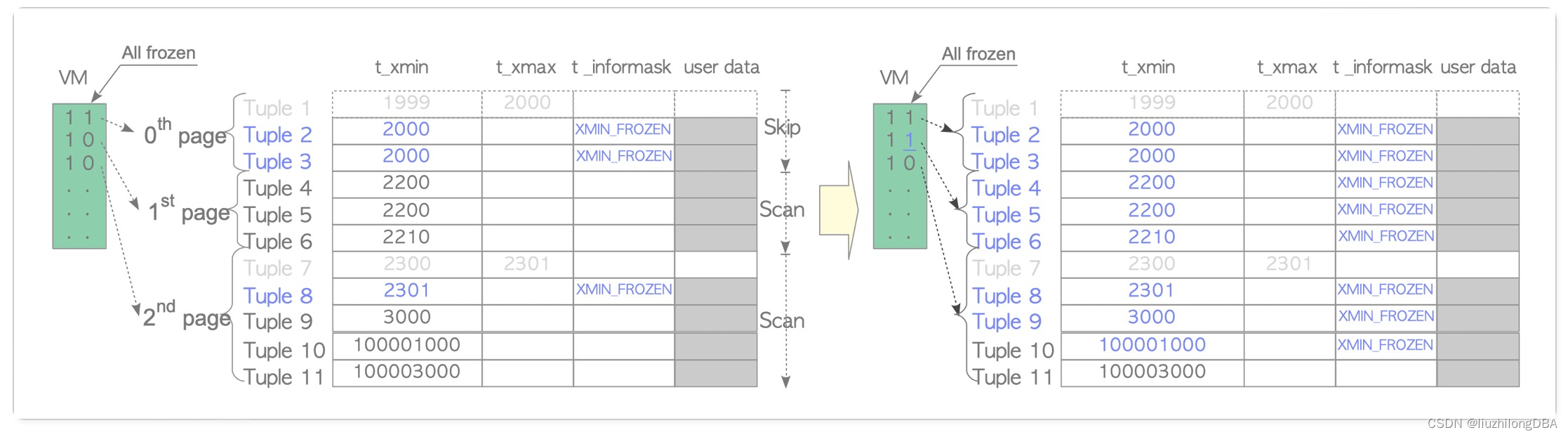
There are many optimization approaches to the transaction ID wraparound problem, but none can avoid transaction freezing. Freezing involves reading every row of every table and resetting flags — a massive I/O and CPU operation. There’s no escaping it; the database may even reject all operations until freezing completes. This is known as the “freeze bomb.” The busier the system and the higher the transaction rate, the more likely it is to trigger. (We’ll expand on freeze optimization in a future chapter.)
64-bit Transaction IDs#
The ultimate solution to transaction ID exhaustion and wraparound is using 64-bit transaction IDs. A 32-bit txid provides 2^32 IDs; a 64-bit txid provides 2^64. Even at 10,000 transactions per second — 864 million per day — it would take 58.49 million years to exhaust them. With 64-bit transaction IDs, they are practically inexhaustible. No wraparound, no freezing, no “freeze bomb”…
Why hasn’t 64-bit transaction ID been implemented yet?
Note: 64-bit transaction IDs already exist in PostgreSQL (as FullTransactionId described earlier). However, because tuple storage is limited, the xmin, xmax, etc. in tuples still use 32-bit XIDs, and transaction ID comparison still relies on 32-bit XIDs. xmin and xmax — the transaction IDs for insert and delete — are stored in each tuple’s header (we’ll cover tuple structure later), and header space is limited. A 32-bit txid is 4 bytes; a 64-bit txid is 8 bytes. Storing both xmin and xmax as 64-bit would require an extra 8 bytes, which the current header cannot accommodate. The community has discussed two approaches:
- Extend the header to store 64-bit transaction IDs directly.
- Keep the header size unchanged. Retain 64-bit transaction IDs in memory, adding an epoch concept to convert between the two.
The first approach has been essentially abandoned — compared to other systems, PostgreSQL’s tuple header is already large enough.
The second approach already has epochs and FullTransactionId-to-TransactionId conversion. The key is how to convert the TransactionId in tuples to FullTransactionId (though some extra storage for the epoch would still be needed — otherwise, how to implement it?).
See community mailing list discussions:
https://www.postgresql.org/message-id/flat/DA1E65A4-7C5A-461D-B211-2AD5F9A6F2FD%40gmail.com
The community proposed 64-bit transaction IDs as a permanent solution to the freeze problem back in 2014, and began discussing practical implementation in 2017. But after several PostgreSQL versions, it’s still vaporware. Given the sensitivity and importance of data in databases, and how many things transaction ID changes touch — one slip could mean data loss or unknown bugs — PostgreSQL is moving cautiously. However, the community is still considering it. Hopefully one day, in some PostgreSQL version, the transaction ID wraparound problem will be completely solved.
Transaction ID References#
The Internals of PostgreSQL
https://www.interdb.jp/pg/pgsql05.html
https://www.interdb.jp/pg/pgsql06.html
https://www.modb.pro/db/427012
https://www.modb.pro/db/377530
https://www.postgresql.org/docs/13/routine-vacuuming.html
https://blog.csdn.net/weixin_30916255/article/details/112365965
https://wiki.postgresql.org/wiki/FullTransactionId
https://www.bookstack.cn/read/aliyun-rds-core/bd7e1c1955b35f7d.md
https://github.com/digoal/blog/blob/master/201605/20160520_01.md
Transaction-Related Tuple Structure#
The tuple structure contains much of the information essential to PostgreSQL’s MVCC. The following sections cover xmin, xmax, t_ctid, cmin, cmax, combo CID, and tuple ID — their meanings and relationships.
Physical Structure#

HeapTupleHeaderData is the tuple header. Its structure is defined in src/include/access/htup_details.h:
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* transaction ID of inserter */
TransactionId t_xmax; /* transaction ID of deleter or locker */
union
{
CommandId t_cid; /* command ID of insert or delete */
TransactionId t_xvac; /* VACUUM FULL transaction ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
...
} DatumTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* TID of current tuple or updated tuple */
...
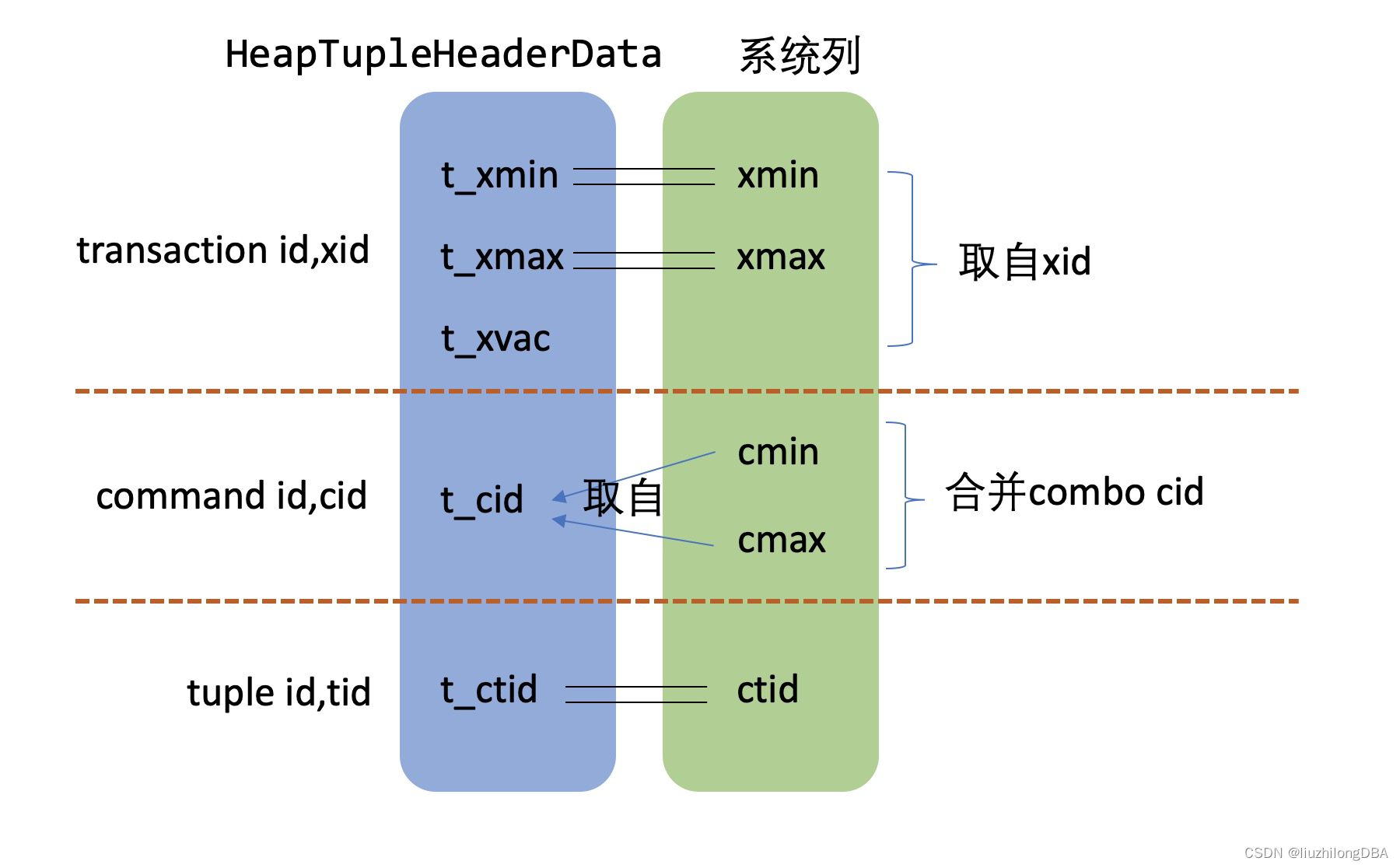
};Five definitions in HeapTupleHeaderData are critically important to MVCC. (Here, “x” = transaction, “c” = command, “t” = tuple — helpful for categorization.)
t_xmin: the transaction ID that inserted this tuple.t_xmax: the transaction ID that deleted this tuple, or the transaction ID that rolled back. If the tuple has not been deleted or updated, xmax is 0. If the delete or update was rolled back, xmax is the rolling-back transaction’s ID.t_xvac: the transaction ID set when the tuple is vacuumed. At that point, the tuple is detached from its original transaction.t_cid: the command ID (cid). A transaction can contain multiple SQL statements. Commands within a transaction are numbered starting from 0, incrementing sequentially. CommandId is a uint32 type, supporting up to2^32 - 1commands. To conserve resources, and because queries don’t affect row transaction ordering, queries do not increment cid (similar to how transaction IDs are allocated).t_ctid: stores a pointer to itself or to a newer tuple. TID identifies a tuple within a table — it is the tuple’s physical address. If a record is modified multiple times, multiple versions exist. These versions are linked via t_ctid, forming a version chain that can be followed to find the latest version.
System Columns#
Every tuple has 6 system columns (directly queryable): tableoid, xmin, xmax, cmin, cmax, ctid. tableoid is the table’s OID and doesn’t change during queries or DML. Here we focus on the remaining 5:
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
616 | 619 | 0 | 0 | (0,3)cmin: the command ID that inserted the tuple.cmax: the command ID that deleted the tuple.
xmin, xmax, and xvac are physically stored in struct HeapTupleFields. But cmin and cmax are not separate fields — they are derived from t_cid in the struct.
The source for cmin and cmax is in src/include/access/htup_details.h:
/* SetCmin is reasonably simple since we never need a combo CID */
#define HeapTupleHeaderSetCmin(tup, cid) \
do { \
Assert(!((tup)->t_infomask & HEAP_MOVED)); \
(tup)->t_choice.t_heap.t_field3.t_cid = (cid); \
(tup)->t_infomask &= ~HEAP_COMBOCID; \
} while (0)
/* SetCmax must be used after HeapTupleHeaderAdjustCmax; see combocid.c */
#define HeapTupleHeaderSetCmax(tup, cid, iscombo) \
do { \
Assert(!((tup)->t_infomask & HEAP_MOVED)); \
(tup)->t_choice.t_heap.t_field3.t_cid = (cid); \
if (iscombo) \
(tup)->t_infomask |= HEAP_COMBOCID; \
else \
(tup)->t_infomask &= ~HEAP_COMBOCID; \
} while (0)
/*
* HeapTupleHeaderGetRawCommandId will give you what's in the header whether
* it is useful or not. Most code should use HeapTupleHeaderGetCmin or
* HeapTupleHeaderGetCmax instead, but note that those Assert that you can
* get a legitimate result, ie you are in the originating transaction!
*/
#define HeapTupleHeaderGetRawCommandId(tup) \
( \
(tup)->t_choice.t_heap.t_field3.t_cid \
)Combo CID#
Before 8.3, cmin and cmax were separate. Later, considering that it’s rare for a single transaction to both insert and delete the same row, and that cmin/cmax are not needed after the transaction ends, the two were merged into a “combo command ID,” or combocid, to save header space.
combocid source: src/backend/utils/time/combocid.c
/* Key and entry structures for the hash table */
typedef struct
{
CommandId cmin;
CommandId cmax;
} ComboCidKeyData;
/* comboid structure is cmin and cmax */
static CommandId
GetComboCommandId(CommandId cmin, CommandId cmax)
{
...
/*
* The hash table is only created the first time a combo cid is used
*/
if (comboHash == NULL)
{
HASHCTL hash_ctl;
/* generate array and hash table */
comboCids = (ComboCidKeyData *)
MemoryContextAlloc(TopTransactionContext,
sizeof(ComboCidKeyData) * CCID_ARRAY_SIZE);
sizeComboCids = CCID_ARRAY_SIZE;
usedComboCids = 0;
memset(&hash_ctl, 0, sizeof(hash_ctl));
...
comboHash = hash_create("Combo CIDs",
CCID_HASH_SIZE,
&hash_ctl,
HASH_ELEM | HASH_BLOBS | HASH_CONTEXT);
}
...
}combocid is stored in a hash table. The first time a transaction uses combocid, a small block of memory is allocated to store it.
So the relationship among these command IDs is: combocid → (cmin, cmax) → (t_cid, t_cid).
Simple Relationships Among Transaction IDs and System Columns#
With all these IDs and source code, things might seem confusing. Here’s a diagram to help understand and remember the relationships among transaction IDs, command IDs, and tuple IDs:
A First Taste of Transactions#
Without any tools or extensions, let’s get a feel for how these system columns change during a transaction:
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
622 | 0 | 0 | 0 | (0,1)
lzldb=# begin ;
BEGIN
lzldb=*# update lzl1 set a=2;
UPDATE 1
-- after update, xmin+1, ctid+1; a new tuple appears
lzldb=*
select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
623 | 0 | 0 | 0 | (0,2)
lzldb=*# rollback;
ROLLBACK
-- xmax records the rollback transaction ID
-- xmin and ctid return to old values; the old tuple barely changes
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
622 | 623 | 0 | 0 | (0,1)
lzldb=# update lzl1 set a=2;
UPDATE 1
-- update again; tuple number jumps over 2 directly to 3
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
624 | 0 | 0 | 0 | (0,3)Tuple Header and Transactions#
The pageinspect Extension#
Simply looking at row changes won’t show old tuples. You need the pageinspect extension. pageinspect is a contrib module bundled with PostgreSQL that can display the detailed contents of data pages. To observe how tuples support transactions, we’ll use get_raw_page() and heap_page_items().
get_raw_page(): returns the binary content of a specified block. The fork parameter accepts main, fsm, vm, or init. main is the main data file; fsm is the free space map; vm is the visibility map; init is the initialization fork. Defaults to main if not specified.
heap_page_items(): displays all line pointers on a heap page, including rows invisible under MVCC.
Generally, get_raw_page() is passed as a parameter to heap_page_items() to display tuple headers, pointers, and the data itself.
heap_tuple_infomask_flags: converts decimal infomask/infomask2 values into their meanings (flags), outputting two columns: all individual flags and combined flags. (Infomask is covered later.)
lzldb=# create extension pageinspect;
CREATE EXTENSION
lzldb=# select t_xmin,t_xmax,t_field3 as t_cid,t_ctid from heap_page_items(get_raw_page('lzl1',0));
t_xmin | t_xmax | t_cid | t_ctid
--------+--------+-------+--------
633 | 0 | 0 | (0,1)lp (Line Pointer)#
A line pointer is essentially a row pointer number within a page, marking a tuple’s location. t_ctid looks more like a tuple ID, but ctid is simply the combination of (table page number, line pointer number). ctid can point to the next lp.
For example, after one UPDATE, a new tuple is added. The new tuple’s lp number increments by 1, the old tuple’s ctid points to the new tuple’s lp, and the new tuple’s ctid points to itself:
lzldb=# select lp,t_ctid from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid
----+--------
1 | (0,1)
(1 row)
lzldb=# update lzl1 set a=2;
UPDATE 1
lzldb=# select lp,t_ctid from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid
----+--------
1 | (0,2)
2 | (0,2)lp source: src/include/storage/itemid.h. The ItemIdData struct stores the tuple’s offset, state, and length:
typedef struct ItemIdData
{
unsigned lp_off:15, /* tuple offset within the page */
lp_flags:2, /* lp state */
lp_len:15; /* tuple length */
} ItemIdData;
typedef ItemIdData *ItemId;*
*
/* lp_off:15 is a bit-field; lp_off occupies 15 bits of the unsigned. The 3 fields together total 32 bits. So ItemIdData is an int, 4 bytes, 32 bits. */lp_flags defines 4 states:
/*
*lp_flags has these possible states. An UNUSED line pointer is available
*for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* lp not in use, tuple length lp_len always 0 */
#define LP_NORMAL 1 /* lp in use, tuple length lp_len always > 0 */
#define LP_REDIRECT 2 /* HOT redirect to another lp (should have lp_len=0) */
#define LP_DEAD 3 /* dead lp, vacuumable */lzldb=# select lp,lp_flags,lp_off,lp_len from heap_page_items(get_raw_page('lzl1',0));
lp | lp_flags | lp_off | lp_len
----+----------+--------+--------
1 | 1 | 8160 | 28Infomask#
Infomask provides information about transactions, locks, tuple state, etc. — such as committed, aborted, lock, HOT info, and more. There are two infomask fields in the header: infomask and infomask2. They store different information.
infomask and infomask2#
infomask source is in src/include/access/htup_details.h:
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */infomask Flag Meanings#
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* tuple has null values */
#define HEAP_HASVARWIDTH 0x0002 /* tuple has variable-width attributes, e.g. varchar */
#define HEAP_HASEXTERNAL 0x0004 /* tuple has TOAST storage */
#define HEAP_HASOID_OLD 0x0008 /* tuple has OID */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* tuple has FOR KEY SHARE lock */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo CID */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* tuple has FOR UPDATE lock */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* inserting transaction committed */
#define HEAP_XMIN_INVALID 0x0200 /* inserting transaction invalid or aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* deleting transaction committed */
#define HEAP_XMAX_INVALID 0x0800 /* deleting transaction invalid or aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is an updated version of a row */
#define HEAP_MOVED_OFF 0x4000 /* moved elsewhere by pre-9.0 VACUUM FULL; kept for binary upgrade compatibility */
#define HEAP_MOVED_IN 0x8000 /* moved from elsewhere, opposite of HEAP_MOVED_OFF; kept for compatibility */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */infomask2 Flag Meanings#
#define HEAP_NATTS_MASK 0x07FF /* 11 bits for the number of columns (MaxHeapAttributeNumber is 1600) */
/* bits 0x1800 are available */
#define HEAP_KEYS_UPDATED 0x2000 /* tuple updated or deleted */
#define HEAP_HOT_UPDATED 0x4000 /* tuple updated, new tuple is HOT */
#define HEAP_ONLY_TUPLE 0x8000 /* HOT tuple */
#define HEAP2_XACT_MASK 0xE000 /* visibility-related bits */
#define HEAP_TUPLE_HAS_MATCH HEAP_ONLY_TUPLE
/* flag temporarily used in Hash Join, only for Hash table tuples that don't need visibility info; we can reuse a visibility flag instead of a separate bit */infomask Bit Calculation#
Converting hex to binary makes it easier to understand the bit meanings:
-- convert hex 1600 to binary
lzldb=# select x'1600'::bit(16);
bit
------------------
0001011000000000infomask:
0000000000000001 0x0001 HEAP_HASNULL
0000000000000010 0x0002 HEAP_HASVARWIDTH
0000000000000100 0x0004 HEAP_HASEXTERNAL
0000000000001000 0x0008 HEAP_HASOID_OLD
0000000000010000 0x0010 HEAP_XMAX_KEYSHR_LOCK
0000000000100000 0x0020 HEAP_COMBOCID
0000000001000000 0x0040 HEAP_XMAX_EXCL_LOCK
0000000010000000 0x0080 HEAP_XMAX_LOCK_ONLY
0000000001010000 0x0050 HEAP_XMAX_SHR_LOCK bitwise OR: (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)=10|40=50
0000000001010000 0x0050 HEAP_LOCK_MASK bitwise OR: (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)=50|40|10=50
0000000100000000 0x0100 HEAP_XMIN_COMMITTED
0000001000000000 0x0200 HEAP_XMIN_INVALID
0000001100000000 0x0300 HEAP_XMIN_FROZEN bitwise OR: (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)=100|200=300
0000010000000000 0x0400 HEAP_XMAX_COMMITTED
0000100000000000 0x0800 HEAP_XMAX_INVALID
0001000000000000 0x1000 HEAP_XMAX_IS_MULTI
0010000000000000 0x2000 HEAP_UPDATED
0100000000000000 0x4000 HEAP_MOVED_OFF
1000000000000000 0x8000 HEAP_MOVED_IN
1100000000000000 0xC000 HEAP_MOVED bitwise OR: (HEAP_MOVED_OFF | HEAP_MOVED_IN)=4000|8000=C000
1111111111110000 0xFFF0 HEAP_XACT_MASKinfomask2:
0000011111111111 0x07FF HEAP_NATTS_MASK PostgreSQL max columns is 1600 = 0000011001000000, so 11 bits suffice for column count
0001100000000000 0x1800 available bits, apparently unused
0010000000000000 0x2000 HEAP_KEYS_UPDATED
0100000000000000 0x4000 HEAP_HOT_UPDATED
1000000000000000 0x8000 HEAP_ONLY_TUPLE
1110000000000000 0xE000 HEAP2_XACT_MASKHow to Compute Infomask?#
Infomask flags are hexadecimal. pageinspect returns them as decimal. Use to_hex() to convert from decimal to hexadecimal:
lzldb=# select lp,t_ctid,to_hex(t_infomask) infomask,to_hex(t_infomask2) infomask2 from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid | infomask | infomask2
----+--------+----------+-----------
1 | (0,1) | 2b00 | 1infomask=2b00 — still a bit opaque. Convert to binary and match against the flag meanings: 0010101100000000 = HEAP_UPDATED + HEAP_XMAX_INVALID + HEAP_XMIN_FROZEN.
Meaning: the tuple was updated, xmax is invalid (0), xmin is frozen (visible to all transactions).
infomask2=1 — the first 11 bits of binary (first 2047 in decimal, for up to 1600 columns) represent the number of user columns. So 1 means the tuple has only 1 column.
Manually computing infomask is tedious. Starting from pg13, pageinspect provides the heap_tuple_infomask_flags function to decode infomask and infomask2. Individual bits are shown as raw_flags; combined multi-bit flags are shown as combined_flags:
lzldb=# SELECT t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('lzl1', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+------------------------------------------------------------------------+--------------------
(0,1) | {HEAP_XMIN_COMMITTED,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID,HEAP_UPDATED} | {HEAP_XMIN_FROZEN}Commit Log (CLOG)#
PostgreSQL uses the commit log (CLOG) to store transaction status. PostgreSQL writes the transaction to WAL before completion — that’s what WAL means. If a transaction aborts, its status is written to both WAL and CLOG so that during instance recovery, PostgreSQL knows the transaction was not committed.
When transaction status is needed — for example, when determining visibility — PostgreSQL reads the CLOG.
Transaction status
Source: src/include/access/clog.h
#define TRANSACTION_STATUS_IN_PROGRESS 0x00
#define TRANSACTION_STATUS_COMMITTED 0x01
#define TRANSACTION_STATUS_ABORTED 0x02
#define TRANSACTION_STATUS_SUB_COMMITTED 0x03The CLOG defines four transaction states: IN_PROGRESS, COMMITTED, ABORTED, SUB_COMMITTED.
Transaction status size
Source: src/backend/access/transam/clog.c
/* We need two bits per xact, so four xacts fit in a byte */
#define CLOG_BITS_PER_XACT 2
#define CLOG_XACTS_PER_BYTE 4
#define CLOG_XACTS_PER_PAGE (BLCKSZ * CLOG_XACTS_PER_BYTE)
#define CLOG_XACT_BITMASK ((1 << CLOG_BITS_PER_XACT) - 1)Transaction status is very small — only 2 bits per transaction. One byte can store 4 transaction states. A standard page can hold 8K * 4 = 32,768 transaction states.
CLOG persistence
When PostgreSQL shuts down or checkpoints, CLOG data is written to the pg_clog directory. In version 10.0 and later, pg_clog was renamed to pg_xact.
[pg@lzl pg_xact]$ ll
total 8
-rw------- 1 pg pg 8192 Mar 28 23:33 0000On disk, CLOG files are named 0000, 0001, etc. CLOG files are 256KB in size, while in-memory pages storing transaction states are 8KB. So the 0000 file’s size will always be a multiple of 8192. After 32 CLOG pages are written, the next page goes into the 0001 file. PostgreSQL reads transaction states from pg_xact into memory at startup.
During system operation, not all transaction states need to be retained in CLOG files forever, so VACUUM periodically deletes no-longer-needed CLOG files.
Hint Bits#
What Are Hint Bits?#
Hint bits mark whether the transaction that created or deleted a row has committed or aborted. Without hint bits, determining transaction visibility requires accessing on-disk pg_clog or pg_subtrans — a relatively expensive operation. If a tuple has hint bits set, you can determine the tuple’s state just by reading the page — no extra access needed.
The source code uses SetHintBits() to set hint bits:
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
InvalidTransactionId);SetHintBits only sets 2 bits in infomask, for 4 hint bit flags (these 2 bits also combine into HEAP_XMIN_FROZEN — it’s clear that hint bits exist purely to mark transaction state):
#define HEAP_XMIN_COMMITTED 0x0100 /* inserting or updating transaction committed */
#define HEAP_XMIN_INVALID 0x0200 /* inserting or updating transaction invalid or aborted */
#define HEAP_XMAX_COMMITTED 0x0400 /* deleting or updating transaction committed */
#define HEAP_XMAX_INVALID 0x0800 /* deleting or updating transaction invalid or aborted */Queries Can Cause Writes#
When a transaction starts, PostgreSQL DML transactions record the transaction ID and status (like t_xmin) in the tuple header. But when the transaction ends, nothing is done to the header. Instead, a subsequent DML, DQL, or VACUUM that scans the relevant tuple triggers SetHintBits (this happens in HeapTupleSatisfiesMVCC() when a new snapshot accesses data — we’ll cover visibility rules later).
Before SetHintBits is triggered, PostgreSQL looks up transaction status in the CLOG. After SetHintBits is triggered, it reads the hint bits in the data page’s tuple header.
For example, an INSERT statement:
lzldb=# insert into lzl1 values(1);
INSERT 0 1
lzldb=# SELECT t_ctid, raw_flags, combined_flags
lzldb-# FROM heap_page_items(get_raw_page('lzl1', 0)),
lzldb-# LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
lzldb-# WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+---------------------+----------------
(0,1) | {HEAP_XMAX_INVALID} | {}
(1 row)
lzldb=# select * from lzl1; -- just a single query
a
---
1
(1 row)
lzldb=# SELECT t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('lzl1', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+-----------------------------------------+----------------
(0,1) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {} After one query, t_infomask changed — the tuple header changed.
After INSERT, SetHintBits only had HEAP_XMAX_INVALID, because INSERT only updates xmin. Whether the transaction commits or aborts (exits or rolls back), xmax is unused and can be set to HEAP_XMAX_INVALID along with the transaction.
But the transaction may commit or abort (exit/rollback). Since transaction completion does not update the tuple, HEAP_XMIN_COMMITTED cannot be set upon completion. During visibility checking (heapam_visibility.c), the visibility check updates the transaction state by calling SetHintBits on t_infomask. Thus, the query updated HEAP_XMIN_COMMITTED.
Hint bits advantage: completing (or failing) data modifications in a transaction produces no writes to the tuple. Commit and rollback are very fast.
Hint bits disadvantage: if a transaction updates many rows, the next query performing visibility checks may need to read transaction states from pg_clog and update many pages.
Do Hint Bits Generate WAL?#
When checksums are enabled or wal_log_hints is true, if the first operation to make a page dirty after a checkpoint is updating hint bits, a WAL record is generated — specifically, a Full Page Image — to prevent partial writes that would cause checksum mismatches.
Therefore, with checksums enabled or wal_log_hints set to true, even a SELECT can modify page hint bits, which may generate WAL — increasing WAL storage to some extent. If you observe SELECT triggering disk writes, check whether CHECKSUM or wal_log_hints is enabled.
Why Are Hint Bits Deferred?#
In src/backend/access/heap/heapam_visibility.c, within the HeapTupleSatisfiesMVCC() visibility function, a comment explains why hint bits are deferred:
/*
*While insert/delete operations are still running, hint bits on tuples are not updated,
*even if the transaction has committed or aborted.
*In high-concurrency scenarios, sharing data structures can cause contention,
*and this doesn't affect visibility decisions anyway.
*Hint bits are only set the first time a fresh snapshot accesses data after transaction completion.
*So HeapTupleSatisfiesMVCC always runs TransactionIdIsCurrentTransactionId and XidInMVCCSnapshot
*to determine whether the tuple belongs to the current transaction.
*In older versions, PostgreSQL tried to update hint bits immediately (even while transactions were running),
*but this caused more contention on the PGXACT array.
*/Simply put: immediate hint bit updates perform very poorly. So transaction status is first stored in CLOG to reduce PGXACT contention and improve performance. Deferred hint bits are why later queries may update tuple headers.
Tuple DML Operations#
Now that we’ve built up knowledge of tuple headers, system columns, CLOG, and hint bits, let’s see how PostgreSQL performs INSERT, UPDATE, and DELETE.
Observing DML Transactions#
We’ll observe PostgreSQL’s DML transaction behavior by examining tuple header fields: lp, lp_flags, ctid, xmin, xmax, cid (cmin, cmax), infomask, and infomask2.
We’ll use the following query:
select t_ctid,lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('lzl1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;(A side note: some sources like to write SELECT '(0,'||lp||')' AS ctid. This is misleading — lp and ctid are different things. lp is like a row number; ctid points to a line pointer number. lp can be different from ctid.)
For readability, create a view:
create view vlzl1 as select t_ctid,lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('lzl1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;Now the query looks like:
lzldb=# \x
Expanded display is on.
lzldb=# select * from vlzl1;
-[ RECORD 6 ]--+-------
t_ctid | (0,6)
lp | 6
lp_flags | LP_NORMAL
t_xmin | 653
t_xmax | 0
t_cid | 0
raw_flags | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE}
combined_flags | {}INSERT#
Truncate the table, then insert a row:
lzldb=# begin ;
BEGIN
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# insert into lzl1 values(2);
INSERT 0 1
lzldb=*# commit;
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 664 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 664 | 0 | 1 | {HEAP_XMAX_INVALID} | {}- ctid points to (page 0, lp 1), i.e., to itself.
- lp (line pointer number) increments.
- Both tuples share the same xmin — they were inserted by the same transaction.
- xmax is 0 (invalid transaction ID). Infomask only indicates xmax is invalid: this tuple has not yet “experienced” a delete transaction.
- cid increments from 0: 0 for the first command, 1 for the second.
DELETE#
lzldb=# begin;
BEGIN
lzldb=*# delete from lzl1 where a=1;
DELETE 1
lzldb=*# commit;
COMMIT
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 664 | 665 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
(0,2) | 2 | LP_NORMAL | 664 | 0 | 1 | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}The first tuple was deleted. The tuple wasn’t physically removed — only a few attributes were marked:
- ctid unchanged, still points to itself.
- xmax updated to the delete transaction ID.
- Infomask shows
HEAP_KEYS_UPDATED, indicating the tuple was deleted (actually,HEAP_KEYS_UPDATEDmeans either deleted or updated). - Although only the first tuple was modified, the second tuple’s infomask was also updated with
HEAP_XMIN_COMMITTED.
UPDATE#
lzldb=# begin;
BEGIN
lzldb=# update lzl1 set a=3;
UPDATE 1
lzldb=*# commit;
COMMIT
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-------------------------------------------------------------+----
(0,1) | 1 | LP_NORMAL | 664 | 665 | 0 | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_KEYS_UPDATED} | {}
(0,3) | 2 | LP_NORMAL | 664 | 666 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 666 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}An UPDATE doesn’t modify the tuple in place. Instead, it marks the old tuple as unavailable and inserts a new one:
- lp=2 is the old tuple from the update transaction. t_xmax is the update transaction ID. Infomask adds
HEAP_HOT_UPDATED, indicating the tuple is HOT. ctid points to the new tuple. - lp=3 is the new tuple from the update. It’s equivalent to an inserted tuple, but xmin matches the old tuple’s xmax. Infomask has the extra flag
HEAP_UPDATED, indicating this is the updated version. - Additionally, the invisible deleted tuple at lp=1 had its infomask updated with
HEAP_XMAX_COMMITTEDby an unrelated subsequent update transaction.
Rollback#
lzldb=# truncate table lzl1;
TRUNCATE TABLE
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(1); -- INSERT
INSERT 0 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 679 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
(1 row)
lzldb=*# rollback; -- INSERT rolled back
ROLLBACK
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 679 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
lzldb=# select * from lzl1;
a
---
(0 rows)
-- After INSERT and rollback, the tuple header shows no changes.
lzldb=# insert into lzl1 values(2);
INSERT 0 1
lzldb=# begin ;
BEGIN
lzldb=*# delete from lzl1 ; -- DELETE
DELETE 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 685 | 686 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
(2 rows)
lzldb=*# rollback; -- DELETE rolled back
ROLLBACK
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 685 | 686 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
-- After DELETE and rollback, the tuple header shows no changes.
lzldb=*# update lzl1 set a=100 ; -- UPDATE
UPDATE 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------+---------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,3) | 2 | LP_NORMAL | 685 | 688 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 688 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
(3 rows)
lzldb=*# rollback; -- UPDATE rolled back
ROLLBACK
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------+---------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,3) | 2 | LP_NORMAL | 685 | 688 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 688 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
-- After UPDATE and rollback, the tuple header shows no changes.- When a transaction rolls back, tuple information does not change at all. This is why PostgreSQL’s MVCC doesn’t worry about running out of rollback segments — rollback is purely a visibility operation, not a data update.
- xmax doesn’t change after rollback either, which means a non-zero xmax doesn’t necessarily indicate the tuple was deleted — the delete or update transaction may have rolled back.
- However, once visibility checking occurs, even without data changes, all tuples’ infomask will be updated with
HEAP_XMIN_INVALID. Non-HOT tuples getHEAP_XMIN_INVALID, and HOT-referenced tuples naturally get it too.
References for Tuple and Transaction#
Books:
- The Internals of PostgreSQL
- PostgreSQL in Action
- PostgreSQL Internals: Deep Dive into Transaction Processing
- PostgreSQL Database Kernel Analysis
https://edu.postgrespro.com/postgresql_internals-14_parts1-2_en.pdf
Official resources:
https://en.wikipedia.org/wiki/Concurrency_control
https://wiki.postgresql.org/wiki/Hint_Bits
https://www.postgresql.org/docs/current/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND
https://www.postgresql.org/docs/10/storage-page-layout.html
https://www.postgresql.org/docs/13/pageinspect.html3
Essential PostgreSQL transaction reads (interdb):
https://www.interdb.jp/pg/pgsql05.html
https://www.interdb.jp/pg/pgsql06.html
Source code experts:
https://blog.csdn.net/Hehuyi_In/article/details/102920988
https://blog.csdn.net/Hehuyi_In/article/details/127955762
https://blog.csdn.net/Hehuyi_In/article/details/125023923
PostgreSQL snapshot optimization performance comparison:
Other resources:
https://brandur.org/postgres-atomicity
https://mp.weixin.qq.com/s/j-8uRuZDRf4mHIQR_ZKIEg
Snapshots in PostgreSQL#
A snapshot is a data structure that records the instantaneous state of the database. PostgreSQL’s snapshot stores: the minimum and maximum transaction IDs among all active transactions, the list of currently active transactions, the current transaction’s command ID, and more.
Snapshot data is stored in the SnapshotData struct type. Source: src/include/utils/snapshot.h
typedef struct SnapshotData
{
SnapshotType snapshot_type; /* snapshot type */
TransactionId xmin; /* txid < xmin are visible to the snapshot */
TransactionId xmax; /* txid >= xmax are invisible to the snapshot */
/* list of active transactions at snapshot time. Only includes txids between xmin and xmax */
TransactionId *xip;
uint32 xcnt; /* xip_list stored in xip[] */
/* list of active subtransactions at snapshot time */
TransactionId *subxip;
int32 subxcnt; /* subtransactions stored in subxip[] */
bool suboverflowed; /* whether subtransactions overflowed; overflows occur with many subtransactions */
bool takenDuringRecovery; /* is this a recovery snapshot? */
bool copied; /* whether the snapshot is a copy (RR and serializable copy their snapshots); false if static */
CommandId curcid; /* command ID in the transaction; CID < curcid is visible */
...
TimestampTz whenTaken; /* timestamp when snapshot was taken */
XLogRecPtr lsn; /* LSN when snapshot was taken */
} SnapshotData;
typedef struct SnapshotData *Snapshot;The most important snapshot information is xmin, xmax, and xip_list. Use pg_current_snapshot() (in pg12 and earlier, txid_current_snapshot()) to display the current transaction’s snapshot.
Note: snapshot xmin/xmax are different from tuple xmin/xmax — they have different meanings.
lzldb=*# select pg_current_snapshot();
pg_current_snapshot
---------------------
100:104:100,102| xmin | Earliest active txid. All txids older than xmin have either committed (visible) or aborted (dead tuples). |
|---|---|
| xmax | First unassigned txid. xmax = latestCompletedXid + 1. All txid >= xmax have not yet started and are invisible to the current snapshot. |
| xip_list | Stored in array xip[]. Since transactions can start and finish out of order (a later-started transaction may finish earlier), xmin and xmax alone cannot fully express all active transactions at snapshot time. xip_list stores the active transactions at snapshot time. |
Snapshot Types#
Beyond MVCC snapshots, PostgreSQL defines several other snapshot types in src/include/utils/snapshot.h:
typedef enum SnapshotType
{
/* Tuple is visible if and only if it satisfies MVCC snapshot visibility rules.
* The most important snapshot type — used to implement MVCC.
* Tuple visibility is judged based on snapshot xmin, xmax, xip_list, curcid, etc.
* If a command changed data, the current MVCC snapshot won't see it; a new MVCC snapshot is needed.
*/
SNAPSHOT_MVCC = 0,
/* Tuple is visible if its transaction committed.
* In-progress transactions are invisible.
* Data changes from the current command are visible to the SELF snapshot.
*/
SNAPSHOT_SELF,
/*
* Any tuple is visible.
*/
SNAPSHOT_ANY,
/*
* Visible if the TOAST tuple is valid. TOAST visibility depends on the main table tuple's visibility.
*/
SNAPSHOT_TOAST,
/*
* Data changes from the current command are visible to the DIRTY snapshot.
* The DIRTY snapshot preserves version info for in-progress tuples.
* Snapshot xmin is set to the xmin of other in-progress transactions' tuples; xmax is similar.
*/
SNAPSHOT_DIRTY,
/* HISTORIC_MVCC snapshot follows MVCC rules, used for logical decoding.
*/
SNAPSHOT_HISTORIC_MVCC,
/*
Determines whether dead tuples are visible to certain transactions.
*/
SNAPSHOT_NON_VACUUMABLE
} SnapshotType;Snapshots and Isolation Levels#
Different isolation levels acquire snapshots differently:
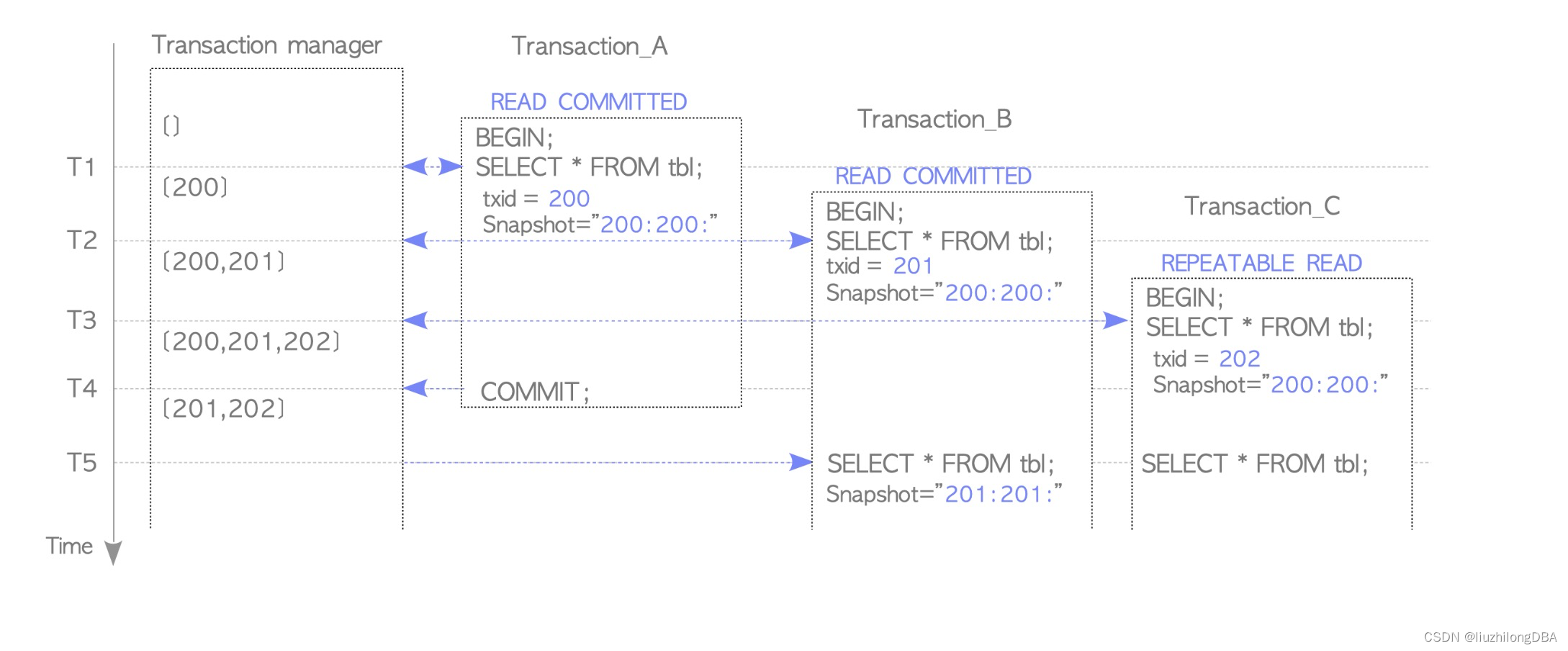
Read Committed requires a new snapshot for each SQL statement in the transaction, while Repeatable Read uses only one snapshot for the entire transaction. The function that acquires snapshots is GetTransactionSnapshot().
Process-Level Transaction Structures#
When PostgreSQL acquires snapshot data, it needs to scan the transaction state of all backend processes.
Before understanding the GetSnapshotData() function, we need to understand several backend process structures: PGPROC, PGXACT, PROC_HDR (PROCGLOBAL), and ProcArray.
These process-related structures contain process and lock information. Here we only study the transaction-related parts. Source code examples are based on pg13.
PGPROC Struct#
Source: src/include/storage/proc.h
// Every backend process stores a PGPROC struct in memory.
// Think of this as the backend process's main structure.
struct PGPROC
{
...
LocalTransactionId lxid; /* local id of top-level transaction currently
* being executed by this proc, if running;
* else InvalidLocalTransactionId */
...
struct XidCache subxids; /* cached subtransaction XIDs */
...
/* clog group transaction status update */
bool clogGroupMember; /* whether this proc uses clog group commit */
pg_atomic_uint32 clogGroupNext; /* atomic int, pointing to the next group member proc */
TransactionId clogGroupMemberXid; /* xid to be committed */
XidStatus clogGroupMemberXidStatus; /* status of the xid to be committed */
int clogGroupMemberPage; /* which page the xid to be committed belongs to */
XLogRecPtr clogGroupMemberLsn; /* LSN of the commit log for the xid to be committed */
};
/* NOTE: "typedef struct PGPROC PGPROC" appears in storage/lock.h. Not written with the struct itself. */PGXACT Struct#
// Before 9.2, PGXACT information was inside PGPROC. Stress testing showed that on multi-CPU systems,
// separating them makes GetSnapshotData faster by reducing the number of cache lines fetched.
typedef struct PGXACT
{
TransactionId xid; /* id of top-level transaction currently being
* executed by this proc, if running and XID
* is assigned; else InvalidTransactionId */
// appears to be the current process's xmax
TransactionId xmin; /* excluding lazy vacuum; minimum xid at transaction start;
vacuum cannot remove tuples with xid >= xmin */
uint8 vacuumFlags; /* vacuum-related flags, see above */
bool overflowed; // whether PGXACT overflowed
uint8 nxids;
} PGXACT;PGXACT stores relatively simple information — the backend’s xmin, xmax, and other transaction-related fields. PGPROC leans toward storing basic backend info; some less frequently accessed transaction info remains in PGPROC, but the core process transaction info is in PGXACT.
PROC_HDR (PROCGLOBAL) Struct#
Every backend process has a proc struct. In high-concurrency scenarios, scanning all proc structs to find transaction info is time-consuming. An instance-level structure is needed to store all proc info — this is PROCGLOBAL.
The source typically uses the struct type PROC_HDR to define a struct pointer to PROCGLOBAL. PROC_HDR stores global proc info: the full array of proc structs, free procs, etc.
Source: src/include/storage/proc.h
typedef struct PROC_HDR
{
/* pgproc array (not including dummies for prepared txns) */
PGPROC *allProcs;
/* pgxact array (not including dummies for prepared txns) */
PGXACT *allPgXact;
...
/* Current shared estimate of appropriate spins_per_delay value */
int spins_per_delay;
/* The proc of the Startup process, since not in ProcArray */
PGPROC *startupProc;
int startupProcPid;
/* Buffer id of the buffer that Startup process waits for pin on, or -1 */
int startupBufferPinWaitBufId;
} PROC_HDR;ProcArray Struct#
ProcArray is in procarray.c, which maintains the PGPROC and PGXACT structures for all backends.
Source: src/backend/storage/ipc/procarray.c
typedef struct ProcArrayStruct
{
int numProcs; /* number of procs */
int maxProcs; /* size of proc array */
// handling assigned xids
int maxKnownAssignedXids; /* allocated size of array */
int numKnownAssignedXids; /* current # of valid entries */
int tailKnownAssignedXids; /* index of oldest valid element */
int headKnownAssignedXids; /* index of newest element, + 1 */
slock_t known_assigned_xids_lck; /* protects head/tail pointers */
/*
* Highest subxid that has been removed from KnownAssignedXids array to
* prevent overflow; or InvalidTransactionId if none. We track this for
* similar reasons to tracking overflowing cached subxids in PGXACT
* entries. Must hold exclusive ProcArrayLock to change this, and shared
* lock to read it.
*/
TransactionId lastOverflowedXid;
/* oldest xmin of any replication slot */
TransactionId replication_slot_xmin;
/* oldest catalog xmin of any replication slot */
TransactionId replication_slot_catalog_xmin;
/* pgprocnos, equivalent to allPgXact[] array indices, used to look up allPgXact[]; this array has PROCARRAY_MAXPROCS entries */
int pgprocnos[FLEXIBLE_ARRAY_MEMBER];
} ProcArrayStruct;
static ProcArrayStruct *procArray;Acquiring a Snapshot#
GetTransactionSnapshot()#
Snapshots are acquired via GetTransactionSnapshot().
Source: src/backend/utils/time/snapmgr.c
// GetTransactionSnapshot() allocates the appropriate snapshot for SQL in a transaction
Snapshot
GetTransactionSnapshot(void)
{
// Return historic snapshot if doing logical decoding. We'll never need a
// non-historic snapshot after this, so return directly.
if (HistoricSnapshotActive())
{
Assert(!FirstSnapshotSet);
return HistoricSnapshot;
}
/* If it's not the first call in this transaction, enter this if */
if (!FirstSnapshotSet)
{
/*
* Ensure the catalog snapshot is fresh.
*/
InvalidateCatalogSnapshot();
Assert(pairingheap_is_empty(&RegisteredSnapshots));
Assert(FirstXactSnapshot == NULL);
// Return error if in parallel mode
if (IsInParallelMode())
elog(ERROR,
"cannot take query snapshot during a parallel operation");
// For Repeatable Read or Serializable, use the same snapshot for the entire transaction; only copy once
// IsolationUsesXactSnapshot() means the isolation level is RR or Serializable — they use one snapshot per transaction
if (IsolationUsesXactSnapshot())
{
// First, create the snapshot in CurrentSnapshotData
// If SI isolation level, initialize SSI-required data structures
if (IsolationIsSerializable())
CurrentSnapshot = GetSerializableTransactionSnapshot(&CurrentSnapshotData);
else
CurrentSnapshot = GetSnapshotData(&CurrentSnapshotData);
/* Make a saved copy */
/* For Repeatable Read or Serializable, this snapshot lasts the entire transaction; copy once */
CurrentSnapshot = CopySnapshot(CurrentSnapshot);
FirstXactSnapshot = CurrentSnapshot;
/* Mark it as "registered" in FirstXactSnapshot */
FirstXactSnapshot->regd_count++;
pairingheap_add(&RegisteredSnapshots, &FirstXactSnapshot->ph_node);
}
else
// For Read Committed, acquire a snapshot
CurrentSnapshot = GetSnapshotData(&CurrentSnapshotData);
// Modify flag to indicate this is the first snapshot; subsequent calls in this transaction won't enter this if
FirstSnapshotSet = true;
return CurrentSnapshot;
}
// If not the first call in this transaction (already have a first snapshot)
// For Repeatable Read or Serializable, return a copy of the first snapshot
if (IsolationUsesXactSnapshot())
return CurrentSnapshot;
/* Don't allow catalog snapshot to be older than xact snapshot. */
InvalidateCatalogSnapshot();
// Read Committed: re-acquire snapshot
CurrentSnapshot = GetSnapshotData(&CurrentSnapshotData);
return CurrentSnapshot;
}About IsolationUsesXactSnapshot() and IsolationIsSerializable():
Defined as macros in src/include/access/xact.h:
#define XACT_READ_UNCOMMITTED 0
#define XACT_READ_COMMITTED 1
#define XACT_REPEATABLE_READ 2
#define XACT_SERIALIZABLE 3
// Internally only 3 isolation levels: 1, 2, 3
// 2 isolation levels use one snapshot per transaction; others use one snapshot per SQL statement
#define IsolationUsesXactSnapshot() (XactIsoLevel >= XACT_REPEATABLE_READ)
#define IsolationIsSerializable() (XactIsoLevel == XACT_SERIALIZABLE)IsolationUsesXactSnapshot() is true for Repeatable Read or Serializable.
IsolationIsSerializable() is true for Serializable only.
GetTransactionSnapshot() flow chart:
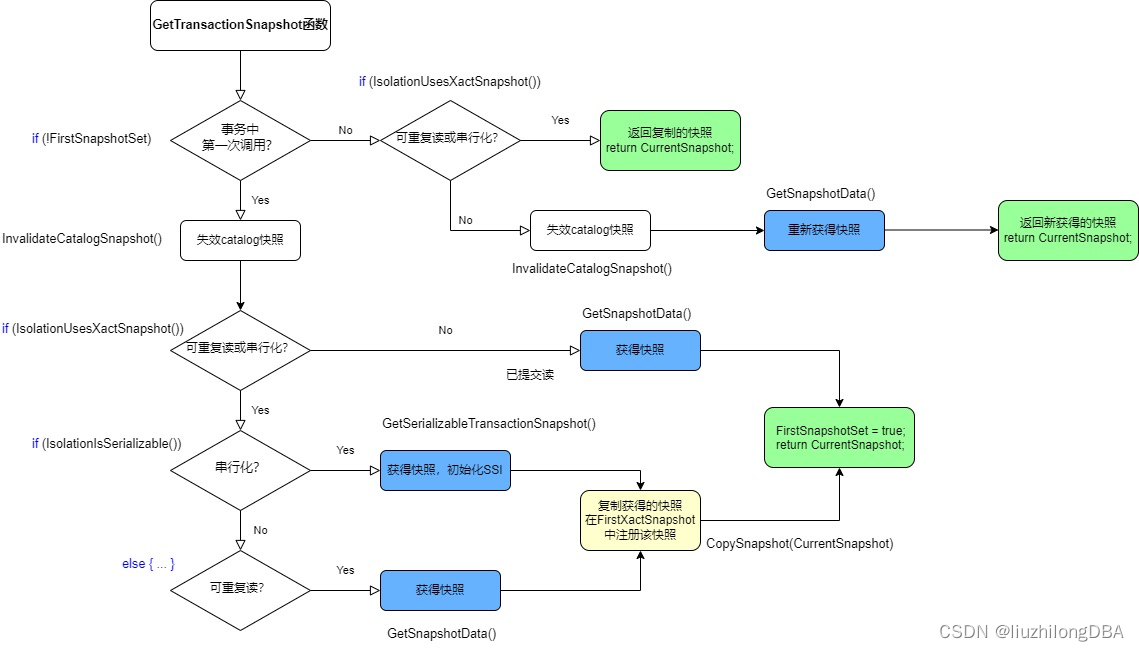 (image from CSDN: https://blog.csdn.net/Hehuyi_In)
(image from CSDN: https://blog.csdn.net/Hehuyi_In)
The main logic of GetTransactionSnapshot():
- For historic snapshots during logical decoding, return the snapshot result directly.
- For Repeatable Read or Serializable: on the first call, return the snapshot and copy it so subsequent calls (non-first) can directly reference it.
- For Read Committed: generate a new snapshot on every call.
- For the first call in Serializable, additionally acquire SSI data information.
GetTransactionSnapshot()acquires the snapshot; the actual data comes fromGetSnapshotData().
GetSnapshotData()#
Source: src/backend/storage/ipc/procarray.c
Snapshot
GetSnapshotData(Snapshot snapshot)
{
// Initialize some variables: arrayP pointer, procarray, xmin, xmax, replication slot txid, etc.
ProcArrayStruct *arrayP = procArray;
TransactionId xmin;
TransactionId xmax;
TransactionId globalxmin;
int index;
int count = 0;
int subcount = 0;
bool suboverflowed = false;
TransactionId replication_slot_xmin = InvalidTransactionId;
TransactionId replication_slot_catalog_xmin = InvalidTransactionId;
Assert(snapshot != NULL);
if (snapshot->xip == NULL)
{
/*
* First call for this snapshot. Snapshot is same size whether or not
* we are in recovery, see later comments.
*/
snapshot->xip = (TransactionId *) // get current transaction's xip
malloc(GetMaxSnapshotXidCount() * sizeof(TransactionId));
...
Assert(snapshot->subxip == NULL);
snapshot->subxip = (TransactionId *) // get current subtransaction's subxip
malloc(GetMaxSnapshotSubxidCount() * sizeof(TransactionId));
...
}
// Acquire procarray; need shared LWLock
LWLockAcquire(ProcArrayLock, LW_SHARED);
/* xmax = max completed xid + 1 */
xmax = ShmemVariableCache->latestCompletedXid;
Assert(TransactionIdIsNormal(xmax));
TransactionIdAdvance(xmax); // xmax + 1
/* xmax value retrieved; xmin needs scanning pgproc, pgxact, procarray */
/* Set globalxmin and xmin to xmax first; if backends have no transaction info, this is simpler */
globalxmin = xmin = xmax;
// Recovery snapshots handled separately
snapshot->takenDuringRecovery = RecoveryInProgress();
// Non-recovery snapshots need transaction info from backends
if (!snapshot->takenDuringRecovery)
{
int *pgprocnos = arrayP->pgprocnos;
int numProcs;
/*
* Spin over procArray checking xid, xmin, and subxids. The goal is
* to gather all active xids, find the lowest xmin, and try to record
* subxids. It appears that while scanning procarray, it will spin
* to collect all active xids, the smallest xmin, and subtransaction subxids.
*/
numProcs = arrayP->numProcs;
for (index = 0; index < numProcs; index++)
{
int pgprocno = pgprocnos[index]; // iterate numProcs, get all pgprocno indices
PGXACT *pgxact = &allPgXact[pgprocno]; // iterate all pgxact structs via pgprocno
TransactionId xid;
...
/* Update globalxmin to be the smallest valid xmin */
xid = UINT32_ACCESS_ONCE(pgxact->xmin);
if (TransactionIdIsNormal(xid) &&
NormalTransactionIdPrecedes(xid, globalxmin))
globalxmin = xid;
/* Fetch xid just once - see GetNewTransactionId */
xid = UINT32_ACCESS_ONCE(pgxact->xid);
...
/* Save backend's xmin into snapshot xip */
/* i.e., iterate all pgxact to find all active xids */
snapshot->xip[count++] = xid;
...
/* Subtransaction info handling */
if (!suboverflowed) // if subtransaction hasn't overflowed
{
if (pgxact->overflowed)
suboverflowed = true; // if transaction overflowed, mark subtransaction as overflowed too
else
{
int nxids = pgxact->nxids;
if (nxids > 0)
{
PGPROC *proc = &allProcs[pgprocno];
pg_read_barrier(); /* pairs with GetNewTransactionId */
memcpy(snapshot->subxip + subcount,
(void *) proc->subxids.xids,
nxids * sizeof(TransactionId));
subcount += nxids;
}
}
}
}
}
else // the else corresponds to if (!snapshot->takenDuringRecovery)
{
// These checks are for standby; when the instance is in hot standby mode and queries run on the replica
subcount = KnownAssignedXidsGetAndSetXmin(snapshot->subxip, &xmin,
xmax);
if (TransactionIdPrecedesOrEquals(xmin, procArray->lastOverflowedXid))
suboverflowed = true;
}
// Replication slot xmin and catalog cluster-wide xmin, first save to local variables
// Replication slot xmin prevents tuple reclamation
// The comment says this is to avoid holding ProcArrayLock for too long, so save to local variables
replication_slot_xmin = procArray->replication_slot_xmin;
replication_slot_catalog_xmin = procArray->replication_slot_catalog_xmin;
// Backend transaction info gathering is done; below is a series of ifs for cleanup and code robustness
if (!TransactionIdIsValid(MyPgXact->xmin))
MyPgXact->xmin = TransactionXmin = xmin;
LWLockRelease(ProcArrayLock); // release ProcArrayLock
if (TransactionIdPrecedes(xmin, globalxmin))
globalxmin = xmin; // globalxmin and process xmin: assign globalxmin to the smaller one
RecentGlobalXmin = globalxmin - vacuum_defer_cleanup_age;
if (!TransactionIdIsNormal(RecentGlobalXmin))
RecentGlobalXmin = FirstNormalTransactionId; // edge case: if RecentGlobalXmin <= 2, assign 3
/* Check whether there's a replication slot requiring an older xmin. */
if (TransactionIdIsValid(replication_slot_xmin) &&
NormalTransactionIdPrecedes(replication_slot_xmin, RecentGlobalXmin))
RecentGlobalXmin = replication_slot_xmin;
/* Non-catalog tables can be vacuumed if older than this xid */
RecentGlobalDataXmin = RecentGlobalXmin;
// Re-check and compare catalog, globalxmin
if (TransactionIdIsNormal(replication_slot_catalog_xmin) &&
NormalTransactionIdPrecedes(replication_slot_catalog_xmin, RecentGlobalXmin))
RecentGlobalXmin = replication_slot_catalog_xmin;
RecentXmin = xmin;
// Start assigning values to the snapshot struct, returning snapshot data
snapshot->xmin = xmin;
snapshot->xmax = xmax;
snapshot->xcnt = count;
snapshot->subxcnt = subcount;
snapshot->suboverflowed = suboverflowed;
snapshot->curcid = GetCurrentCommandId(false);
// If it's a new snapshot, initialize some snapshot info
snapshot->active_count = 0;
snapshot->regd_count = 0;
snapshot->copied = false;
// Snapshot-too-old logic below; oddly written here
if (old_snapshot_threshold < 0)
{
/*
* If not using "snapshot too old" feature, fill related fields with
* dummy values that don't require any locking.
*/
// When old_snapshot_threshold < 0 (no "snapshot too old" issue)
// assign simple constant values that won't require any locks
snapshot->lsn = InvalidXLogRecPtr;
snapshot->whenTaken = 0;
}
else
{
// When old_snapshot_threshold >= 0, need to handle old snapshot logic
snapshot->lsn = GetXLogInsertRecPtr(); // get LSN
snapshot->whenTaken = GetSnapshotCurrentTimestamp(); // get snapshot timestamp
MaintainOldSnapshotTimeMapping(snapshot->whenTaken, xmin); //
// GetXLogInsertRecPtr(), GetSnapshotCurrentTimestamp(), MaintainOldSnapshotTimeMapping()
// all contain SpinLockAcquire and SpinLockRelease
// MaintainOldSnapshotTimeMapping() also has LWLockAcquire and LWLockRelease
// Since this is called for every snapshot, GetSnapshotData should be very frequent
// So in pg13 source, setting old_snapshot_threshold to negative avoids many spinlocks and lwlocks
}
return snapshot;
}pg14 Snapshot Optimizations#
pg14 Optimization Source Analysis#
From the pg13 source, we can see that GetSnapshotData() hardcodes old_snapshot_threshold >= 0, causing each snapshot acquisition to incur many SpinLock and LWLock operations. Since snapshot acquisition is extremely frequent, this inevitably causes performance issues. So pg14 simply removed the old_snapshot_threshold logic from GetSnapshotData().
Beyond that removal, pg14 made many other optimizations:
Removed
RecentGlobalXminandRecentGlobalDataXmin, added theGlobalVisTest*family of functions.Introduced the boundaries concept with two boundaries:
definitely_neededandmaybe_needed:struct GlobalVisState { /* XIDs >= are considered running by some backend */ // rows with XID >= definitely_needed are definitely visible FullTransactionId definitely_needed; /* XIDs < are not considered to be running by any backend */ // rows with XID < maybe_needed can definitely be cleaned up FullTransactionId maybe_needed; };Added
ComputeXidHorizons()for more precise horizon calculation (storing xmin and removable xid information). This function still needs to iterate PGPROC. The calculation range isXID >= maybe_needed && XID < definitely_needed.Added
GlobalVisTestShouldUpdate()to determine whether boundaries need recalculation.First, understand the variable
ComputeXidHorizonsResultLastXmin:static TransactionId ComputeXidHorizonsResultLastXmin; // last precisely computed xmin GlobalVisTestShouldUpdate(GlobalVisState *state) { // If xmin=0, need to recalculate boundaries. This is an edge case for tuples created during database initialization. if (!TransactionIdIsValid(ComputeXidHorizonsResultLastXmin)) return true; /* * If the maybe_needed/definitely_needed boundaries are the same, it's * unlikely to be beneficial to refresh boundaries. */ // When maybe_needed equals definitely_needed, no need to recalculate // Uses FullTransactionIdFollowsOrEquals (not strict equality) // "Greater than" scenario: no rows definitely visible. "Equal" scenario: only one row definitely visible. if (FullTransactionIdFollowsOrEquals(state->maybe_needed, state->definitely_needed)) return false; /* does the last snapshot built have a different xmin? */ // When the last snapshot's xmin equals the last precisely computed xmin, no need to recalculate boundaries return RecentXmin != ComputeXidHorizonsResultLastXmin; }
We can see that maybe_needed and definitely_needed are similar to snapshot xmin/xmax, but with an additional layer of computation. First calculate boundaries, then further refine with ComputeXidHorizons(). GlobalVisTestShouldUpdate reduces the scenarios where boundaries need recalculation, and ComputeXidHorizons() is also more efficient for precise calculation.
Optimization Results#
Recommended article on PostgreSQL snapshot optimization:
The before-and-after comparison is striking:
In pg13 production environments, GetSnapshotData consistently shows high performance overhead. (No screenshot, so I’ll borrow another expert’s chart:)
Snapshot References#
Books:
- The Internals of PostgreSQL
- PostgreSQL in Action
- PostgreSQL Internals: Deep Dive into Transaction Processing
- PostgreSQL Database Kernel Analysis
https://edu.postgrespro.com/postgresql_internals-14_parts1-2_en.pdf
Official resources:
https://en.wikipedia.org/wiki/Concurrency_control
https://wiki.postgresql.org/wiki/Hint_Bits
https://www.postgresql.org/docs/current/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND
https://www.postgresql.org/docs/10/storage-page-layout.html
https://www.postgresql.org/docs/13/pageinspect.html3
Essential PostgreSQL transaction reads (interdb):
https://www.interdb.jp/pg/pgsql05.html
https://www.interdb.jp/pg/pgsql06.html
Source code experts:
https://blog.csdn.net/Hehuyi_In/article/details/102920988
https://blog.csdn.net/Hehuyi_In/article/details/127955762
https://blog.csdn.net/Hehuyi_In/article/details/125023923
PostgreSQL snapshot optimization performance comparison:
Other resources:
https://brandur.org/postgres-atomicity
https://mp.weixin.qq.com/s/j-8uRuZDRf4mHIQR_ZKIEg
Visibility Checking#
With a snapshot, we can determine tuple visibility. Let’s review the key information (ignoring subtransactions for now): tuple header transaction info, snapshot info, and CLOG transaction status (before SetHintBits).
- Tuple header has: xmin, xmax, cmin, cmax, infomask, etc.
- Snapshot data has: snapshot xmin, xmax, xip_list, curcid, etc.
- CLOG has additional transaction status info, which may also be written to infomask as hint bits.
Different snapshot types have slightly different visibility rules:
bool
HeapTupleSatisfiesVisibility(HeapTuple tup, Snapshot snapshot, Buffer buffer)
{
switch (snapshot->snapshot_type)
{
case SNAPSHOT_MVCC:
return HeapTupleSatisfiesMVCC(tup, snapshot, buffer);
break;
...
case SNAPSHOT_NON_VACUUMABLE:
return HeapTupleSatisfiesNonVacuumable(tup, snapshot, buffer);
break;
}
...
}Each snapshot type has its own visibility rules. Here we’ll use the most common SNAPSHOT_MVCC visibility rules to understand tuple visibility.
static bool
HeapTupleSatisfiesMVCC(HeapTuple htup, Snapshot snapshot,
Buffer buffer)
{
HeapTupleHeader tuple = htup->t_data;
Assert(ItemPointerIsValid(&htup->t_self)); // lp valid, i.e., tuple valid
Assert(htup->t_tableOid != InvalidOid); // oid valid, i.e., table valid
// t_xmin not committed: the transaction that INSERTed or UPDATEd this new tuple has not committed
// In htup_details.h, macro: HeapTupleHeaderXminCommitted() is ((tup)->t_infomask & HEAP_XMIN_COMMITTED) != 0
// So if (!HeapTupleHeaderXminCommitted(tuple)) means the tuple infomask does not have HEAP_XMIN_COMMITTED
// Literally: t_xmin has not committed
if (!HeapTupleHeaderXminCommitted(tuple))
{
// If a transaction updated the tuple but then aborted or failed, this tuple's xmin is the failed transaction ID
// If the inserting transaction failed, directly return invisible
if (HeapTupleHeaderXminInvalid(tuple))
return false;
// When infomask has HEAP_MOVED_OFF, visibility is judged separately for VACUUM tuples, with hint bits set
/* Used by pre-9.0 binary upgrades */
if (tuple->t_infomask & HEAP_MOVED_OFF)
{
TransactionId xvac = HeapTupleHeaderGetXvac(tuple);
if (TransactionIdIsCurrentTransactionId(xvac))
return false;
if (!XidInMVCCSnapshot(xvac, snapshot))
{
if (TransactionIdDidCommit(xvac))
{
SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,
InvalidTransactionId);
return false;
}
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
InvalidTransactionId);
}
}
// When infomask has HEAP_MOVED_IN, visibility is judged separately for VACUUM tuples, with hint bits set
/* Used by pre-9.0 binary upgrades */
else if (tuple->t_infomask & HEAP_MOVED_IN)
{
TransactionId xvac = HeapTupleHeaderGetXvac(tuple);
if (!TransactionIdIsCurrentTransactionId(xvac))
{
if (XidInMVCCSnapshot(xvac, snapshot))
return false;
if (TransactionIdDidCommit(xvac))
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
InvalidTransactionId);
else
{
SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,
InvalidTransactionId);
return false;
}
}
}
// When the tuple was written by the current transaction
else if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmin(tuple)))
{
if (HeapTupleHeaderGetCmin(tuple) >= snapshot->curcid) // tuple cid >= snapshot current command id
return false; // tuple was inserted after visibility check started; invisible
if (tuple->t_infomask & HEAP_XMAX_INVALID) // infomask has HEAP_XMAX_INVALID
return true; // tuple not deleted; visible
// A pure insert, whether committed, not yet committed, or rolled back, has HEAP_XMAX_INVALID
// But this check is under the "written by current transaction" condition, so:
// Tuple inserted by current transaction, not committed (logically equivalent to not deleted within the same tx),
// and t_cid < curcid → visible
// xmax is set in two scenarios: 1) tuple locked, 2) tuple deleted
// Even without HEAP_XMAX_INVALID, the tuple may not be deleted — it may just be locked
// Locked tuples have xmax set but are visible
if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask)) /* not deleter */
return true;
// HEAP_XMAX_IS_MULTI is set when multiple transactions acquire locks on the same row, producing MultiXactId
// Still judging visibility under xmax lock scenarios
if (tuple->t_infomask & HEAP_XMAX_IS_MULTI)
{
TransactionId xmax;
xmax = HeapTupleGetUpdateXid(tuple);
/* not LOCKED_ONLY, so it has to have an xmax */
Assert(TransactionIdIsValid(xmax));
/* updating subtransaction must have aborted */
// If xmax is not the current transaction, visible
if (!TransactionIdIsCurrentTransactionId(xmax))
return true;
// If xmax is the current transaction, judge by command id:
// snapshot acquired before update/delete → tuple was visible at snapshot time
else if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* updated after scan started */
else
return false; /* updated before scan started */
}
// The following scenario: a subtransaction's delete command was rolled back, need SetHintBits HEAP_XMAX_INVALID
// Delete rolled back, so tuple is visible
if (!TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmax(tuple)))
{
/* deleting subtransaction must have aborted */
SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,
InvalidTransactionId);
return true;
}
// cmax is the command ID that deleted the tuple
// If tuple cmax >= snapshot curcid: delete happened after snapshot scan → visible
// If tuple cmax < snapshot curcid: delete happened before snapshot scan → invisible
if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* deleted after scan started */
else
return false; /* deleted before scan started */
}
// XidInMVCCSnapshot() checks if xid was in-progress at snapshot time
// "in-progress" means: 1. snapshot xmin <= xid < snapshot xmax AND xid in xip_list 2. xid >= snapshot xmax
// The xid below is t_xmin
// So this means: if t_xmin was in-progress at snapshot time → invisible
// Equivalent to: t_xmin not committed → invisible. This seems redundant.
// Because this whole block is under !HeapTupleHeaderXminCommitted(tuple) — also meaning t_xmin not committed.
// But with the preceding checks, this else if is reasonable. Meaning:
// t_xmin not committed, tuple not deleted, not current transaction → invisible
else if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmin(tuple), snapshot))
return false;
// If t_xmin transaction committed, SetHintBits HEAP_XMIN_COMMITTED
// This seems odd: the entire block is for t_xmin NOT committed, how could it be committed here?
// And if this case really happens, why no visibility judgment?
else if (TransactionIdDidCommit(HeapTupleHeaderGetRawXmin(tuple)))
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
HeapTupleHeaderGetRawXmin(tuple));
// If t_xmin transaction did not commit, SetHintBits HEAP_XMIN_INVALID
else
{
/* it must have aborted or crashed */
SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,
InvalidTransactionId);
// t_xmin transaction not committed, return invisible again. Similar to XidInMVCCSnapshot() above?
// Currently: not committed, and doesn't satisfy XidInMVCCSnapshot() (xid was not in-progress at snapshot time)
// The only case: transaction hadn't started at snapshot time, later started, still not committed → invisible
return false;
}
}
// xmin-not-committed visibility judgments finally done
// Everything after the else is for when xmin IS committed (hint bit HEAP_XMIN_COMMITTED is set)
else
{
// xmin is committed, but maybe not according to our snapshot
/* xmin is committed, but maybe not according to our snapshot */
// If infomask has no HEAP_XMIN_FROZEN AND xmin was in-progress at snapshot time → invisible
// Translating the if: at snapshot time, xmin was not committed; at visibility check time,
// tuple xmin is committed but not marked FROZEN → invisible
// Even though tuple xmin is now committed, from the current snapshot's perspective it was still in-progress
if (!HeapTupleHeaderXminFrozen(tuple) &&
XidInMVCCSnapshot(HeapTupleHeaderGetRawXmin(tuple), snapshot))
return false; /* treat as still in progress */
}
// HEAP_XMAX_INVALID means tuple not deleted
// This if means: tuple committed, and was committed at snapshot time, and not deleted (no delete marker at all) → visible
if (tuple->t_infomask & HEAP_XMAX_INVALID) /* xid invalid or aborted */
return true;
// Tuple has xmax, but it's not a delete — it's a lock marker
// This if means: tuple committed, was committed at snapshot time, has xmax but xmax is a lock → visible
if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask))
return true;
// HEAP_XMAX_IS_MULTI means the tuple is in shared-row-lock state, typically when multiple transactions process one row
if (tuple->t_infomask & HEAP_XMAX_IS_MULTI)
{
TransactionId xmax;
/* already checked above */
Assert(!HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask));
// Get the transaction ID that updated the tuple
xmax = HeapTupleGetUpdateXid(tuple);
/* not LOCKED_ONLY, so it has to have an xmax */
Assert(TransactionIdIsValid(xmax));
// If the shared-row-lock tuple's transaction ID is the current transaction
if (TransactionIdIsCurrentTransactionId(xmax))
{
// tuple cmax >= snapshot curcid: tuple not yet deleted at snapshot time → visible
if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* deleted after scan started */
// tuple cmax < snapshot curcid: tuple already deleted at snapshot time → invisible
else
return false; /* deleted before scan started */
}
// If the shared-row-lock tuple's transaction ID is not the current transaction, and xmax was in-progress at snapshot time
// This if means: xmin committed, tuple not deleted, MULTI XMAX marker present, xmax not yet committed at snapshot time → visible
if (XidInMVCCSnapshot(xmax, snapshot))
return true;
// If the shared-row-lock tuple transaction committed → invisible
if (TransactionIdDidCommit(xmax))
return false; /* updating transaction committed */
/* it must have aborted or crashed */
// Updating transaction aborted or crashed → still visible
return true;
}
// Tuple xmin committed, xmax not yet marked committed, not yet deleted
// Seems !HEAP_XMAX_COMMITTED differs from HEAP_XMAX_INVALID
// This looks like: tuple experienced a delete, but the delete transaction hasn't committed
// While HEAP_XMAX_INVALID above is: definitely no delete or delete aborted/rolled back, so can directly return true
if (!(tuple->t_infomask & HEAP_XMAX_COMMITTED))
{
// If xmax is the same as the checking transaction
if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmax(tuple)))
{
// Same old pattern: visibility via command id
// cmax >= snapshot curcid: delete happened after snapshot → visible
if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* deleted after scan started */
// cmax < snapshot curcid: delete happened before snapshot → invisible
else
return false; /* deleted before scan started */
}
// Delete transaction not committed, and xmax not the checking transaction
// If xmax was in-progress at snapshot time → visible
if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmax(tuple), snapshot))
return true;
// Confirm xmax delete transaction aborted or failed; SetHintBits HEAP_XMAX_INVALID
// Similar to HEAP_XMAX_INVALID above → visible
if (!TransactionIdDidCommit(HeapTupleHeaderGetRawXmax(tuple)))
{
/* it must have aborted or crashed */
SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,
InvalidTransactionId);
return true;
}
/* xmax transaction committed */
// Remaining case: xmax delete transaction committed. SetHintBits HEAP_XMAX_COMMITTED
// Visibility should be judged here, but it's deferred to the last few lines, because this is a sub-case of a larger condition
SetHintBits(tuple, buffer, HEAP_XMAX_COMMITTED,
HeapTupleHeaderGetRawXmax(tuple));
}
else
{
/* xmax is committed, but maybe not according to our snapshot */
// xmax delete transaction now committed, but was in-progress at snapshot time → visible
if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmax(tuple), snapshot))
return true; /* treat as still in progress */
}
/* xmax transaction committed */
// Only remaining case: xmax committed and was not in-progress at snapshot time → invisible
return false;
}The entire visibility judgment source code looks complex. Stripping out the SetHintBits parts and the convoluted if-else chains, focusing only on the core visibility rules, the key points are:
Core visibility rule logic:
- Delete committed → tuple invisible
- Insert committed, delete rolled back → tuple visible
- Insert committed, delete not committed → current transaction compares cid; other transactions see the tuple as visible
- Insert rolled back → tuple invisible
- Insert not committed → same transaction compares cmin; other transactions see the tuple as invisible
Visibility checking involves two time points: the check time and the snapshot time. The logic distinguishes between the same transaction (checking transaction = snapshot transaction) and different transactions.
Same transaction: compare tuple cmin/cmax against
snapshot->curcid.cmin >= snapshot->curcid: tuple inserted after snapshot → invisible. Otherwise visible.cmax >= snapshot->curcid: tuple deleted after snapshot → visible. Otherwise invisible.
Different transactions: use
XidInMVCCSnapshot()to check whether xid (t_xmin or t_xmax) was in-progress at snapshot time.- xmin was in-progress at snapshot time → invisible.
- xmax was in-progress at snapshot time → visible.
Beyond basic DML operations, there are 4 additional cases:
- VACUUM tuple insert/delete visibility
- Lock-only marker (
HEAP_XMAX_IS_LOCKED_ONLY): tuple visible - MultiXact state (
HEAP_XMAX_IS_MULTI): visibility for tuples under multi-transaction locks - Frozen tuples: visibility when frozen marker is set
MultiXact#
What Is MultiXact?#
When multiple transactions lock the same row, there may be multiple associated transaction IDs on the tuple. PostgreSQL groups multiple transaction IDs together and manages them with a single MultiXactId. The relationship between TransactionId and MultiXactId is many-to-one.

Like TransactionId, MultiXactId is also 32-bit and also subject to wraparound.
MultiXactId values 0 and 1 are reserved for system use. Allocatable MultiXactIds start from 2.
Source: src/include/access/multixact.h
#define InvalidMultiXactId ((MultiXactId) 0)
#define FirstMultiXactId ((MultiXactId) 1)
#define MaxMultiXactId ((MultiXactId) 0xFFFFFFFF)Row Lock Types#
MultiXact only exists when rows are locked. MultiXact defines 6 states:
typedef enum
{
MultiXactStatusForKeyShare = 0x00,
MultiXactStatusForShare = 0x01,
MultiXactStatusForNoKeyUpdate = 0x02,
MultiXactStatusForUpdate = 0x03,
/* an update that doesn't touch "key" columns */
MultiXactStatusNoKeyUpdate = 0x04,
/* other updates, and delete */
MultiXactStatusUpdate = 0x05
} MultiXactStatus;There are 4 explicitly declarable row lock states: ForKeyShare, ForShare, ForNoKeyUpdate, ForUpdate.
MultiXact Infomask Flags#
PostgreSQL marks row locks on xmax and records them in infomask.
Source: src/include/access/htup_details.h
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */Here we focus on the HEAP_XMAX_IS_MULTI flag. Only when multiple transactions hold shared locks on the same row is a true MultiXact ID generated and this flag set.
lzldb=# insert into lzl1 values(1); -- initially one row
INSERT 0 1
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+----------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 742 | 0 | 0 | {HEAP_HASNULL,HEAP_XMAX_INVALID} | {}
(1 row)| Session 1 | Session 2 |
|---|---|
| lzldb=# begin; BEGIN lzldb=*# select * from lzl1 for share; a — 1 | |
| lzldb=# begin; BEGIN lzldb=*# select * from lzl1 for share; a — 1 | |
| lzldb=*# update lzl1 set a=2; –hang | |
| commit; | |
| UPDATE 1 –update completed |
-- Check tuple xmax and infomask
lzldb=*# select t_ctid,lp,t_xmin,t_xmax,(t_infomask&4096)!=0 is_multixact from heap_page_items(get_raw_page('lzl1',0));
t_ctid | lp | t_xmin | t_xmax | is_multixact
--------+----+--------+--------+--------------
(0,2) | 1 | 742 | 4 | t
(0,2) | 2 | 744 | 3 | tHEAP_XMAX_IS_MULTI is 0x1000 in hex, which is 4096 in decimal. Using (t_infomask&4096)!=0 is_multixact shows whether the tuple uses a MultiXact ID. From the example:
- MultiXact IDs have their own value space, separate from transaction IDs.
- MultiXact IDs are generally smaller than transaction IDs — here t_xmax < t_xmin.
- For an UPDATE, old and new tuples typically share the same xmax. In MultiXact scenarios, they may differ.
MultiXact SLRU#
Although src/backend/access/transam/multixact.c defines many variables and functions at the top — page, member, membergroup, offset — they are all about defining variable values and conversion functions between them.
Before reading multixact.c, understand a few macros:
src/include/c.h defines MultiXactOffset as a 32-bit type:
typedef uint32 MultiXactOffset;src/include/access/slru.h defines how many SLRU pages per segment:
#define SLRU_PAGES_PER_SEGMENT 32Back to the top of src/backend/access/transam/multixact.c:
define MULTIXACT_OFFSETS_PER_PAGE (BLCKSZ / sizeof(MultiXactOffset))
// MULTIXACT_OFFSETS_PER_PAGE = 8k / 32B = 2048. One page stores 2048 offset markers, i.e., 2048 MultiXactIds.
#define MultiXactIdToOffsetPage(xid) \
((xid) / (MultiXactOffset) MULTIXACT_OFFSETS_PER_PAGE)
// Convert xid to the page where the corresponding record resides: xid / 2048
#define MultiXactIdToOffsetEntry(xid) \
((xid) % (MultiXactOffset) MULTIXACT_OFFSETS_PER_PAGE)
// Convert xid to the offset within the page: xid % 2048
#define MultiXactIdToOffsetSegment(xid) (MultiXactIdToOffsetPage(xid) / SLRU_PAGES_PER_SEGMENT)
// Convert xid to the segment: xid / 2048 / 32
Now read the comments at the top of the source:
/*
* Defines for MultiXactOffset page sizes. A page is the same BLCKSZ as is
* used everywhere else in Postgres.
*
* Note: because MultiXactOffsets are 32 bits and wrap around at 0xFFFFFFFF,
* MultiXact page numbering also wraps around at
* 0xFFFFFFFF/MULTIXACT_OFFSETS_PER_PAGE, and segment numbering at
* 0xFFFFFFFF/MULTIXACT_OFFSETS_PER_PAGE/SLRU_PAGES_PER_SEGMENT. We need
* take no explicit notice of that fact in this module, except when comparing
* segment and page numbers in TruncateMultiXact (see
* MultiXactOffsetPagePrecedes).
*/Since MultiXactOffsets are 32-bit and subject to wraparound:
- MultiXact page numbering wraps at
0xFFFFFFFF / MULTIXACT_OFFSETS_PER_PAGE = 2^32 / 2048 = 2^21 - Segment numbering wraps at
0xFFFFFFFF / MULTIXACT_OFFSETS_PER_PAGE / SLRU_PAGES_PER_SEGMENT = 2^32 / 2^11 / 2^5 = 2^16
TruncateMultiXact() cleans up these segments and page numbers. It is called by VACUUM.
The pg_multixact Directory#
Like CLOG and SUBTRANS, MultiXact logs use an SLRU buffer pool implementation. The pg_multixact directory has only two subdirectories: members and offsets.
[pg@lzl pg_multixact]$ ll
total 8
drwx------ 2 pg pg 4096 Feb 14 21:29 members
drwx------ 2 pg pg 4096 Feb 14 21:29 offsetsOne MultiXactId corresponds to multiple TransactionIds — the members. The offset is the starting position of each MultiXact.
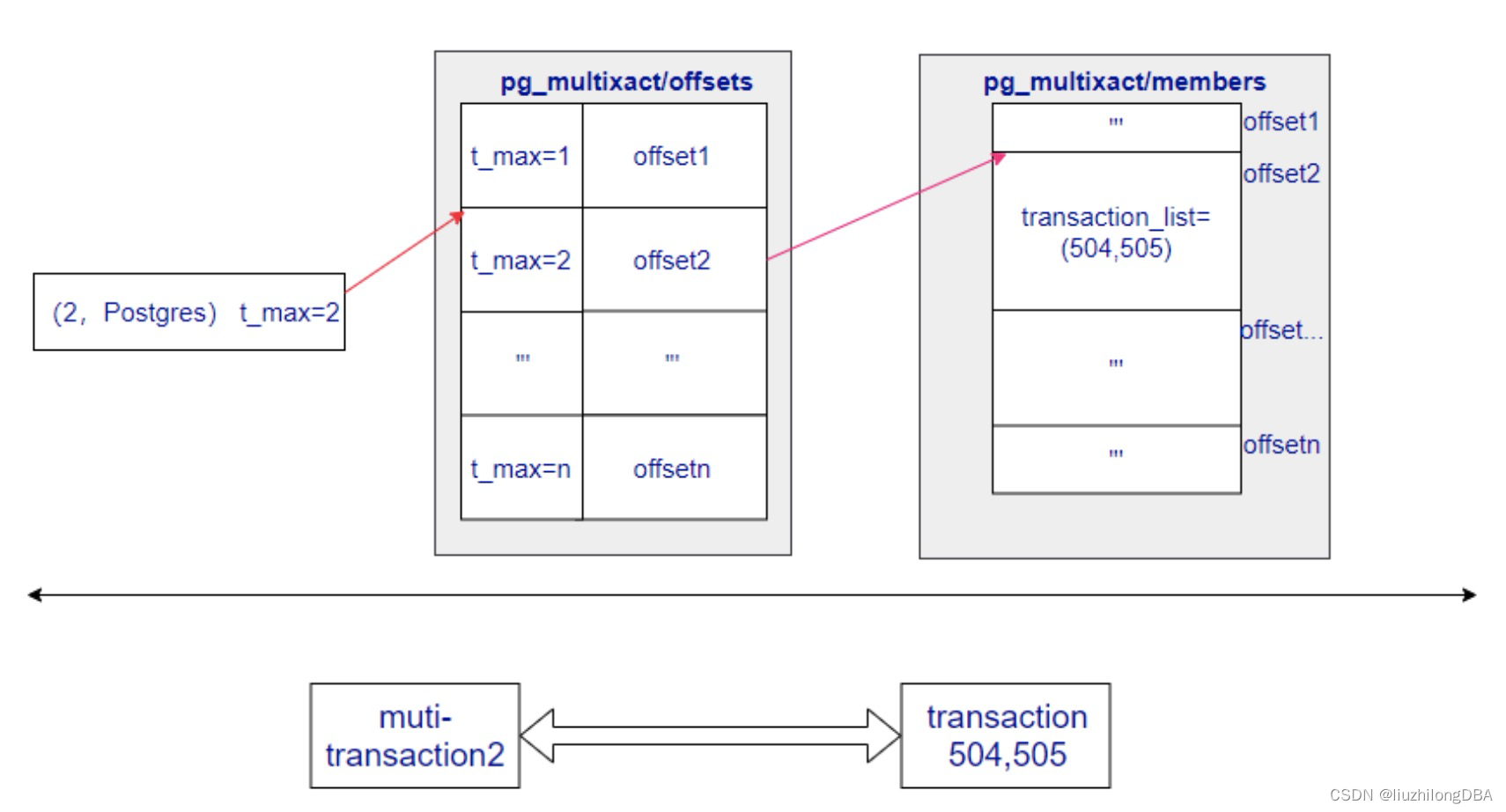
typedef struct mXactCacheEnt
{
MultiXactId multi; // one MultiXactId
int nmembers;
dlist_node node;
MultiXactMember members[FLEXIBLE_ARRAY_MEMBER]; // multiple TransactionIds; expanded via MultiXactIdExpand() if needed
} mXactCacheEnt;multixact.h defines MultiXactMember as just a single transaction ID and its status:
typedef struct MultiXactMember
{
TransactionId xid;
MultiXactStatus status;
} MultiXactMember;MultiXact References#
https://www.postgresql.org/docs/current/routine-vacuuming.html
https://pgpedia.info/m/multixact-id.html
https://www.postgresql.org/docs/15/explicit-locking.html
https://www.highgo.ca/2020/06/12/transactions-in-postgresql-and-their-mechanism/
Two-Phase Commit (2PC) Transactions#
What Is a 2PC Transaction?#
Transaction atomicity requires that a transaction either completes entirely or rolls back entirely. In distributed transactions spanning multiple connected databases, a consistent state must be provided to satisfy distributed transaction atomicity. Like other databases, PostgreSQL provides the Two-Phase Commit Protocol (2PC).
There are many distributed transaction implementations; 2PC is the most fundamental and common. Distributed transactions encompass atomic commit, atomic visibility, and global consistency. 2PC is only an implementation for atomic commit.
PREPARE TRANSACTION#
Foreign Data Wrappers (FDWs) can handle 2PC internally. PostgreSQL also provides an explicit way to use 2PC: PREPARE TRANSACTION. Once issued, the prepared transaction is detached from the session; its state is persisted. PREPARE TRANSACTION is not designed for use in applications or interactive sessions — unless you’re writing a transaction manager — so it is recommended (and default) to keep it disabled.
Syntax:
PREPARE TRANSACTION transaction_id
COMMIT PREPARED transaction_id
ROLLBACK PREPARED transaction_idNotes:
- The
transaction_idhere is not the internal transaction ID — it’s just a user-declared string. PREPARE TRANSACTIONmust be inside a transaction block, started withBEGINorSTART TRANSACTION.max_prepared_transactionscontrols the number of prepared transactions. Default is 0 (disabled). Must be increased to use prepared transactions.
Starting a Prepared Transaction#
lzldb=# begin;
BEGIN
lzldb=*# PREPARE TRANSACTION 'lzl';
PREPARE TRANSACTION
lzldb=# select * from pg_prepared_xacts ;
transaction | gid | prepared | owner | database
-------------+-----+-------------------------------+-------+----------
719 | lzl | 2023-04-29 16:08:45.866022+08 | pg | lzldb
(1 row)
lzldb=# rollback prepared 'lzl';
ROLLBACK PREPARED
lzldb=# select * from pg_prepared_xacts ;
transaction | gid | prepared | owner | database
-------------+-----+----------+-------+----------
(0 rows)The pg_twophase Directory#
As mentioned, prepared transactions are session-independent. When a prepared transaction is started, its state information is stored in a cache. To ensure the transaction is not lost, prepared transactions are also persisted to the pg_twophase directory. This doesn’t only happen on shutdown — it’s tied to checkpoint.
Source: src/backend/access/transam/twophase.c
void
CheckPointTwoPhase(XLogRecPtr redo_horizon)
{
...
TRACE_POSTGRESQL_TWOPHASE_CHECKPOINT_START(); // checkpoint start
...
fsync_fname(TWOPHASE_DIR, true); // call fsync to flush to disk
TRACE_POSTGRESQL_TWOPHASE_CHECKPOINT_DONE(); // checkpoint done
...
}Let’s test: start a prepared transaction and run a checkpoint:
[pg@lzl pg_twophase]$ ll
total 0
lzldb=*# PREPARE TRANSACTION 'lzl';
PREPARE TRANSACTION
lzldb=# checkpoint;
CHECKPOINT
[pg@lzl pg_twophase]$ ll
total 4
-rw------- 1 pg pg 116 Apr 29 16:33 000002D0Orphaned Prepared Transactions#
If a prepared transaction is never completed (neither committed nor rolled back), and since it is session-independent, it will persist unless explicitly terminated. (Normally, a regular transaction rolls back when the session disconnects.) This is an orphaned prepared transaction.
Orphaned prepared transactions hold locks and tuple resources indefinitely, preventing VACUUM from reclaiming dead tuples and even blocking transaction ID wraparound. For example, if a prepared transaction is forgotten and not committed or rolled back, and there is no external transaction management monitoring it, it may go unnoticed and exist forever — ultimately causing severe problems. Therefore, it’s recommended to keep max_prepared_transactions=0 (default) or monitor prepared transactions via the pg_prepared_xacts view.
Here’s a simulation of an orphaned prepared transaction causing indefinite blocking:
-- Start a prepared transaction and disconnect
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# PREPARE TRANSACTION 'lzl';
PREPARE TRANSACTION
lzldb=# \q
-- After disconnecting, the prepared transaction still exists
postgres=# select * from pg_prepared_xacts ;
transaction | gid | prepared | owner | database
-------------+-----+-------------------------------+-------+----------
721 | lzl | 2023-04-29 17:08:59.597678+08 | pg | lzldb
-- DDL blocked
lzldb=# alter table lzl1 add column b int;
-- Check locks
lzldb=# select locktype,relation,pid,mode from pg_locks where relation=32808;
locktype | relation | pid | mode
----------+----------+-------+---------------------
relation | 32808 | 26136 | AccessExclusiveLock
relation | 32808 | | RowExclusiveLock
-- End the prepared transaction; DDL completes
lzldb=# rollback prepared 'lzl';
ROLLBACK PREPARED
lzldb=# alter table lzl1 add column b int;
ALTER TABLE2PC Transaction References#
http://postgres.cn/docs/13/sql-prepare-transaction.html
https://www.highgo.ca/2020/01/28/understanding-prepared-transactions-and-handling-the-orphans/
https://wiki.postgresql.org/wiki/Atomic_Commit_of_Distributed_Transactions
Subtransactions#
What Is a Subtransaction?#
A regular transaction can only commit or roll back as a whole. Subtransactions allow partial rollback.
SAVEPOINT p1 places a savepoint marker inside a transaction. You cannot directly commit a subtransaction — subtransactions are committed when the parent transaction commits. However, you can use ROLLBACK TO SAVEPOINT p1 to roll back to that savepoint.
Subtransactions are useful for bulk data loading. If a transaction contains multiple subtransactions and one small segment fails, only that segment needs to be retried — not the entire transaction.
Using Subtransactions in SQL#
SAVEPOINT savepoint_name
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
RELEASE [ SAVEPOINT ] savepoint_nameNotes:
- Savepoint statements must be inside a transaction block.
SAVEPOINTcreates a savepoint;ROLLBACK TOrolls back to the named savepoint;RELEASEerases the savepoint without rolling back subtransaction data.- Cursors are not affected by savepoint operations.
Example:
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(0);
INSERT 0 1
lzldb=*# savepoint p1;
SAVEPOINT
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# savepoint p2;
SAVEPOINT
lzldb=*# insert into lzl1 values(2);
INSERT 0 1
lzldb=*# savepoint p3;
SAVEPOINT
lzldb=*# insert into lzl1 values(3);
INSERT 0 1
lzldb=*# rollback to savepoint p2;
ROLLBACK
lzldb=*# commit;
COMMIT
lzldb=# select xmin,xmax,cmin,a from lzl1;
xmin | xmax | cmin | a
------+------+------+---
731 | 0 | 0 | 0
732 | 0 | 1 | 1
(2 rows)
-- Rolling back to p2 also rolled back p3
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+------------------------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 731 | 0 | 0 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 732 | 0 | 1 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
(0,3) | 3 | LP_NORMAL | 733 | 0 | 2 | {HEAP_HASNULL,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,4) | 4 | LP_NORMAL | 734 | 0 | 3 | {HEAP_HASNULL,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(4 rows)
-- Subtransaction infomask is not very different from regular transactions.
-- Multiple commands within the same transaction are differentiated by cid and HEAP_XMIN_INVALID, etc.
-- Subtransaction writes also consume transaction IDs, and cid increments within the parent transaction framework.Other Sources of Subtransactions#
Even without explicit SAVEPOINT, subtransactions can be created by other means:
EXCEPTIONblocks trigger subtransactions. This is common in tools and frameworks and easily overlooked. EveryEXCEPTIONcreates a subtransaction.Syntax:
BEGIN / EXCEPTION WHEN .. / ENDReference: https://fluca1978.github.io/2020/02/05/PLPGSQLExceptions.html
PL/Python code using
plpy.subtransaction().
Subtransaction SLRU Cache#
Subtransaction commit logs are in pg_xact. Parent-child relationships are stored in pg_subtrans, which caches the mapping of subXID to parent XID. When PostgreSQL needs to look up a subXID, it calculates which memory page the ID resides on and searches within that page. If the page is not in cache, it evicts a page and loads the required page from pg_subtrans into memory. Large numbers of subtransaction cache misses consume system I/O and CPU.
The subtransaction buffer is only 32 pages, hardcoded in the source.
Source: src/include/access/subtrans.h
/* Number of SLRU buffers to use for subtrans */
\#define NUM_SUBTRANS_BUFFERS 32Buffer default is 8KB; xid is 32 bits (4 bytes). Therefore:
- SUBTRANS_BUFFER size:
32 * 8K = 256KB - SUBTRANS_BUFFER can store at most:
32 * 8K / 4 = 65,536xids

Finding a subtransaction’s position in a page by transaction ID:
Source: src/backend/access/transam/subtrans.c
/* We need four bytes per xact */
#define SUBTRANS_XACTS_PER_PAGE (BLCKSZ / sizeof(TransactionId))
// Each page can store up to 8K / 4 bytes = 2048 subtransaction IDs
#define TransactionIdToPage(xid) ((xid) / (TransactionId) SUBTRANS_XACTS_PER_PAGE)
// Calculate page number from subtransaction xid: xid / 2048
#define TransactionIdToEntry(xid) ((xid) % (TransactionId) SUBTRANS_XACTS_PER_PAGE)
// Calculate offset within page from subtransaction xid: xid % 2048
Subtransaction xids may not be densely packed within a page — a page may hold fewer than 2048 subtransaction IDs.
The Dangers of Subtransactions#
1. PGPROC_MAX_CACHED_SUBXIDS Overflow
PGPROC_MAX_CACHED_SUBXIDS is not a GUC parameter — it’s hardcoded. You can only change it by modifying the source.
Source: src/include/storage/proc.h
/*
*Each backend has a subtransaction cache limit of PGPROC_MAX_CACHED_SUBXIDS.
*We must track whether the cache has overflowed (i.e., the transaction has at least one subtransaction that couldn't be cached).
*If no cache has overflowed, we can be sure that an xid not in the PGPROC array is definitely not a running transaction.
*If there is an overflow, we must consult pg_subtrans.
*/
#define PGPROC_MAX_CACHED_SUBXIDS 64 /* XXX guessed-at value */
struct XidCache
{
TransactionId xids[PGPROC_MAX_CACHED_SUBXIDS];
};Two key takeaways from this source:
- Every backend’s subtransaction cache is capped at
PGPROC_MAX_CACHED_SUBXIDS: 64 subtransactions. - Beyond 64 subtransactions, they overflow to the
pg_subtransdirectory.
An expert’s benchmark: performance drops when subtransactions just exceed 64. So it’s best to keep per-session subtransactions below 64.
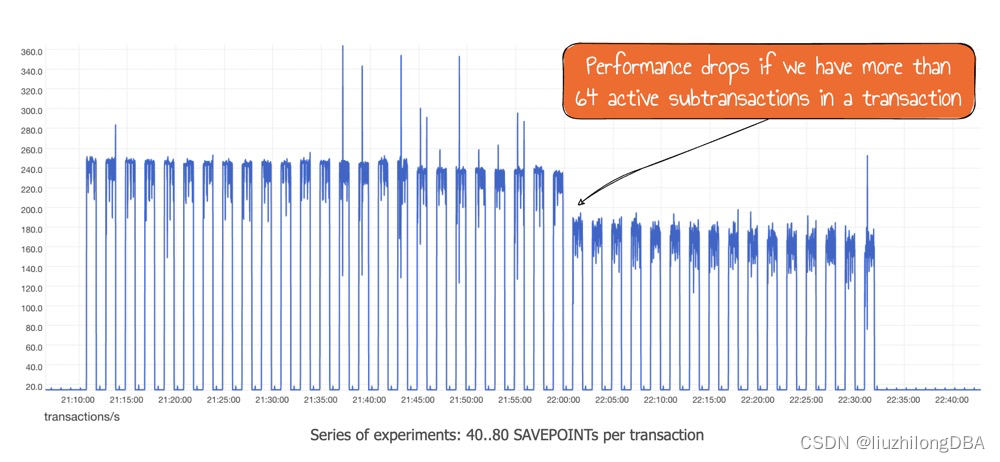 Reference: https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
Reference: https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
2. Subtransactions Causing MultiXact Contention
Reference: https://buttondown.email/nelhage/archive/notes-on-some-postgresql-implementation-details/
FOR UPDATE itself is a row-level exclusive lock and should not generate a MultiXact ID. But in this scenario, multiple MultiXact waits occurred, causing a cliff-like performance drop:
- LWLock:MultiXactMemberControlLock
- LWLock:MultiXactOffsetControlLock
- LWLock:multixact_member
- LwLock:multixact_offset
It was later discovered that the Django framework was issuing subtransaction statements:
SELECT [some row] FOR UPDATE;
SAVEPOINT save;
UPDATE [the same row];3. Replica Performance Cliff
A single long transaction with a savepoint subtransaction can also cause a performance cliff on replicas.
If a read occurs on a snapshot taken on the primary, the snapshot includes xmin, xmax, the txip transaction list, and subxip (the list of in-progress subtransactions). However, neither the original arrays nor the snapshot are directly shared with replicas — replicas read all needed data from WAL.
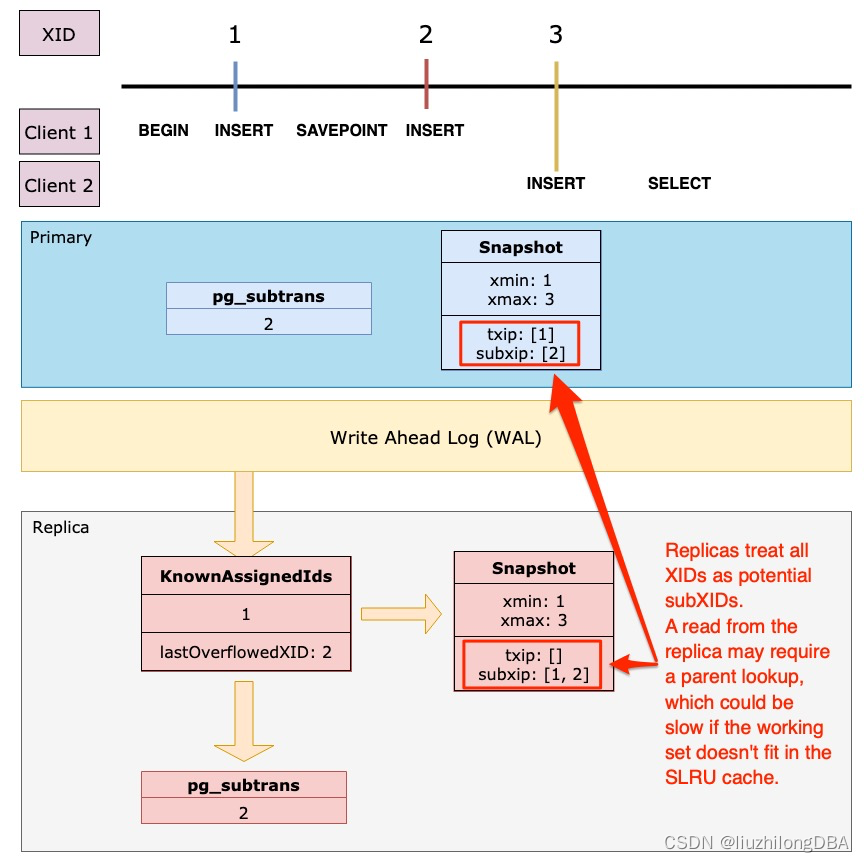
When subtransactions exist, a single long-running transaction can cause replica performance to drop off a cliff:
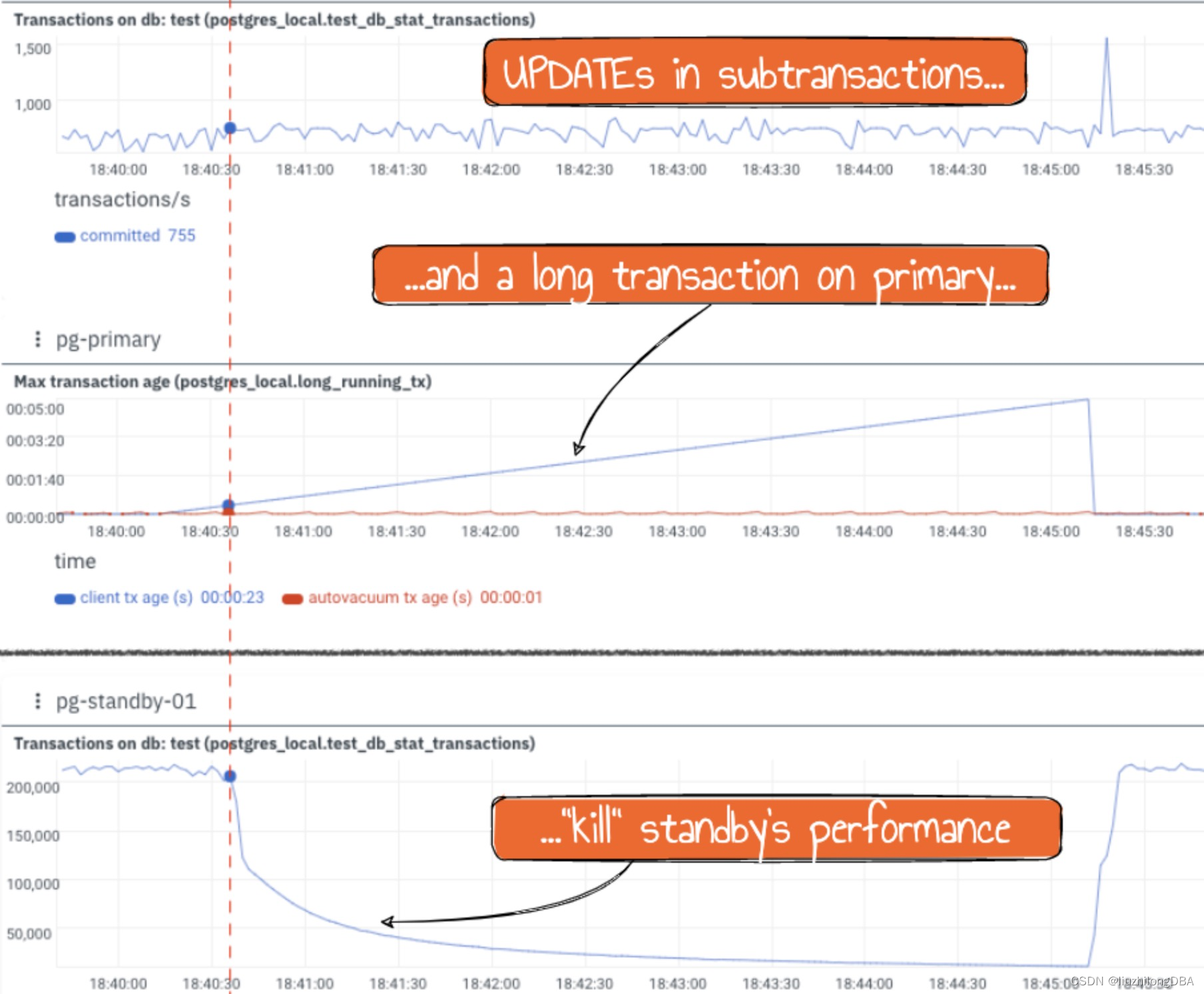
4. Production Performance Cliff
When the database is busy and many subtransactions exist, performance can drop sharply, accompanied by subtransaction wait events. This scenario can occur even when per-session subtransactions don’t exceed 64, and even on the primary (not just replicas).
We found that a tool (OGG) defaulted to 50 subtransactions. Reducing the subtransaction count in that tool to 10–20 alleviated the database performance issue.
Subtransaction usage recommendations:
- Besides explicit
SAVEPOINT, EXCEPTION blocks, frameworks, and tools can also generate subtransactions. - If you have replica query workloads, disable subtransactions.
- Use row locks cautiously.
FOR UPDATE+ subtransactions can also trigger MultiXactId issues. - If you must use subtransactions, keep them well below 64 per session — preferably much lower.
Subtransactions have caused countless production issues worldwide, with many case studies and analyses. To quote: “Subtransactions are basically cursed. Rip ’em out.”
Subtransaction References#
https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
https://www.cybertec-postgresql.com/en/subtransactions-and-performance-in-postgresql/
https://fluca1978.github.io/2020/02/05/PLPGSQLExceptions.html
https://buttondown.email/nelhage/archive/notes-on-some-postgresql-implementation-details/
References#
Books:
- The Internals of PostgreSQL
- PostgreSQL in Action
- PostgreSQL Internals: Deep Dive into Transaction Processing
- PostgreSQL Database Kernel Analysis
https://edu.postgrespro.com/postgresql_internals-14_parts1-2_en.pdf
Official resources:
https://en.wikipedia.org/wiki/Concurrency_control
https://wiki.postgresql.org/wiki/Hint_Bits
https://www.postgresql.org/docs/current/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND
https://www.postgresql.org/docs/10/storage-page-layout.html
https://www.postgresql.org/docs/13/pageinspect.html3
Essential PostgreSQL transaction reads (interdb):
https://www.interdb.jp/pg/pgsql05.html
https://www.interdb.jp/pg/pgsql06.html
Source code experts:
https://blog.csdn.net/Hehuyi_In/article/details/102920988
https://blog.csdn.net/Hehuyi_In/article/details/127955762
https://blog.csdn.net/Hehuyi_In/article/details/125023923
PostgreSQL snapshot optimization performance comparison:
Other resources:
https://brandur.org/postgres-atomicity
https://mp.weixin.qq.com/s/j-8uRuZDRf4mHIQR_ZKIEg
http://mysql.taobao.org/monthly/2018/12/02/
Originally published in Chinese on lastdba.com.