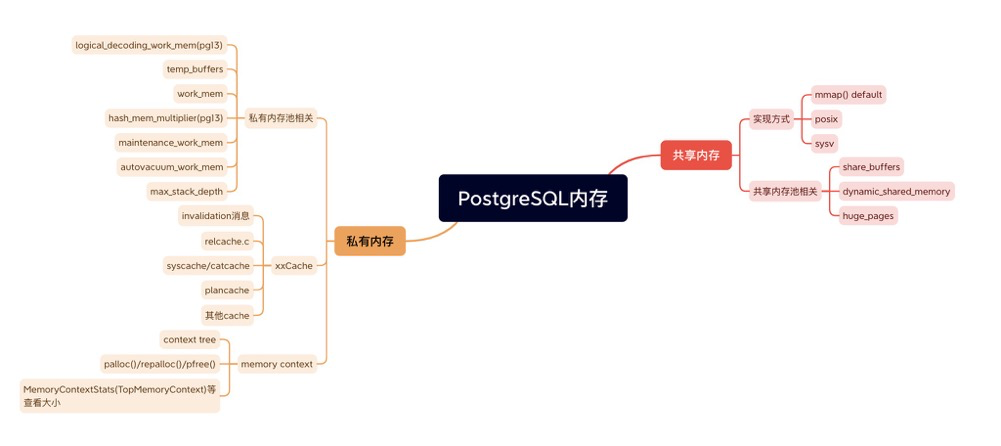
Architecture#
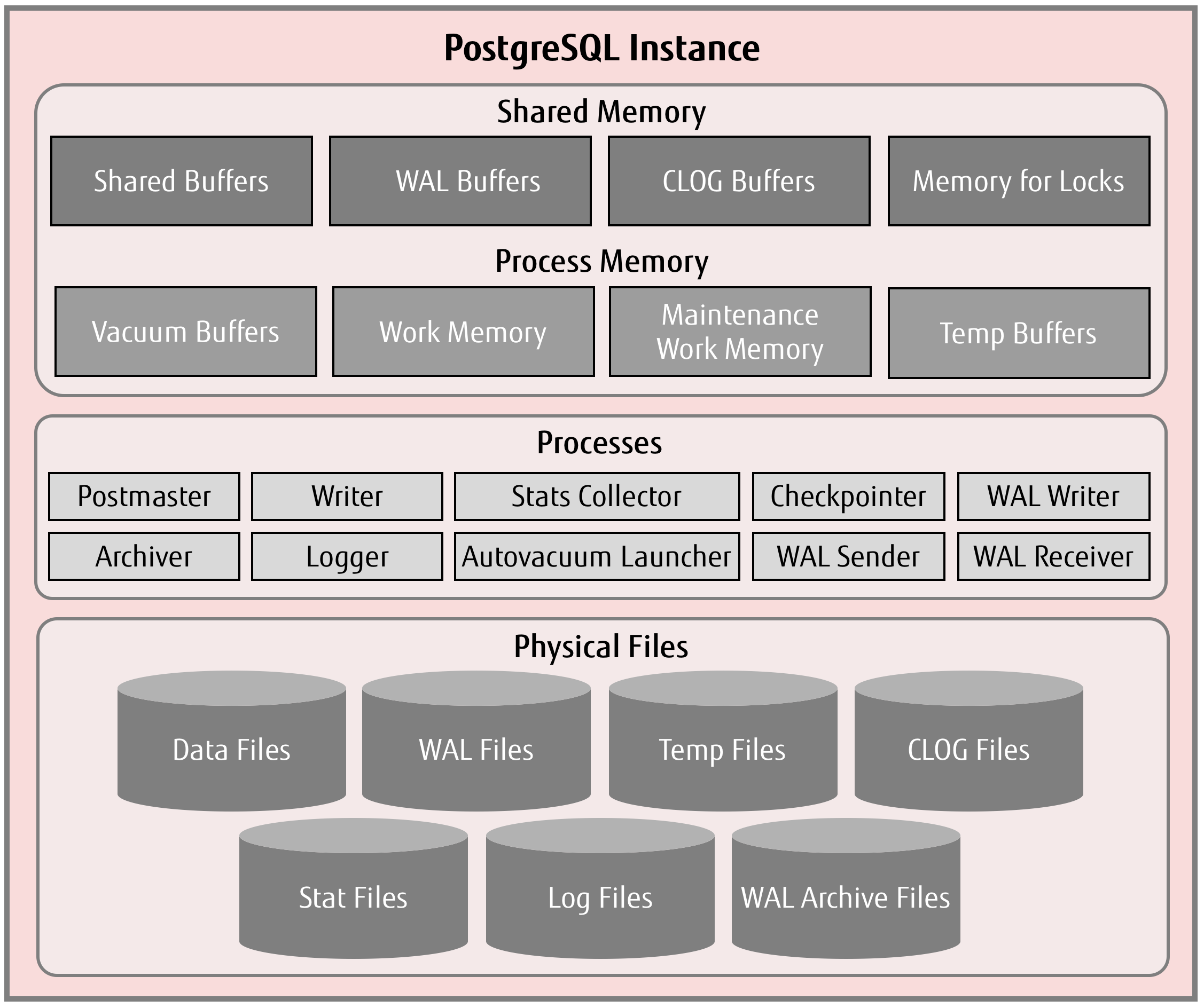 (https://www.postgresql.fastware.com/blog/lets-get-back-to-basics-postgresql-memory-components)
(https://www.postgresql.fastware.com/blog/lets-get-back-to-basics-postgresql-memory-components)
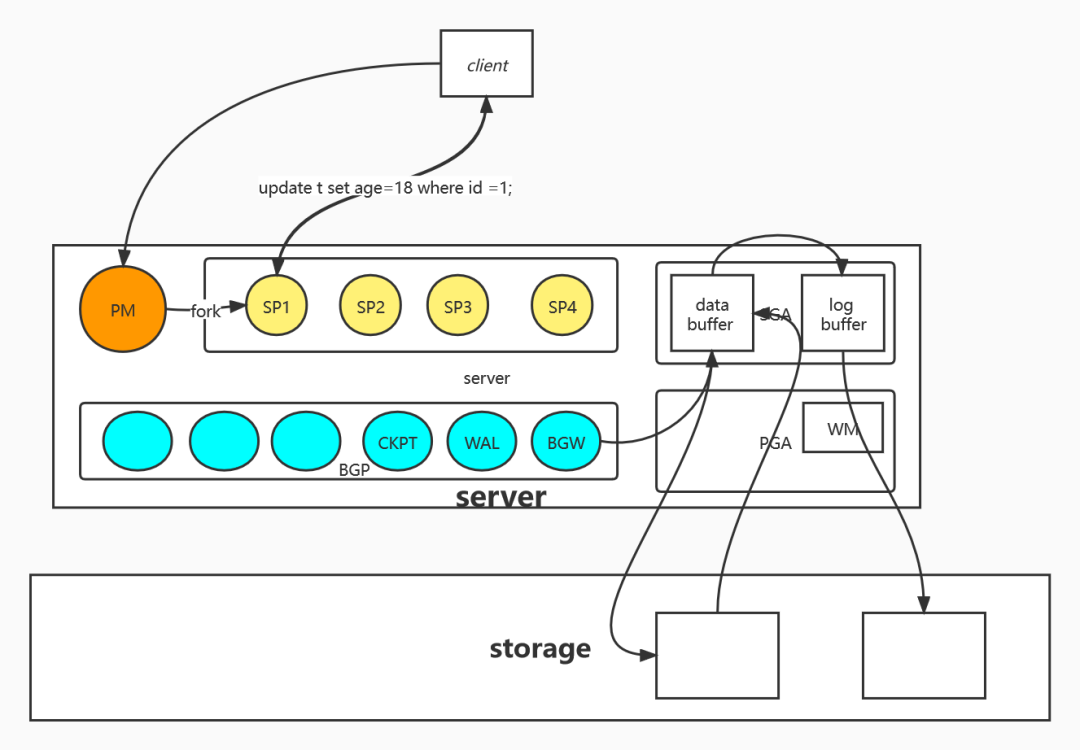 (http://geekdaxue.co/read/fcant@sql/qts5is)
(http://geekdaxue.co/read/fcant@sql/qts5is)
Shared Memory#
Linux Shared Memory Implementation#
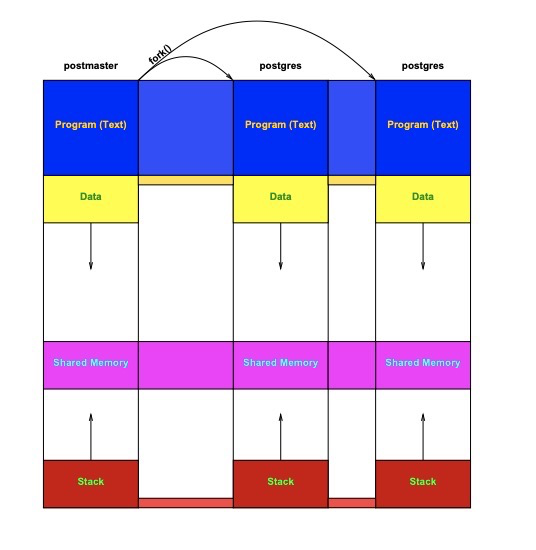
(https://momjian.us/main/writings/pgsql/inside_shmem.pdf)
Shared Memory on Linux Shared memory is an IPC (Inter-Process Communication) mechanism supported by Unix-based operating systems (including Linux). It is a type of memory that multiple processes can simultaneously use to communicate with each other. Shared memory is one of the fastest IPC mechanisms because it does not require processes to copy data between each other. Processes can access shared memory through their own address space.
Two Forms of Shared Memory One form of shared memory is memory-mapped files. Once multiple processes map the same file into their address space, they can access the file’s contents and simultaneously update the file directly using the mapped memory. Another form of shared memory is anonymous memory. This refers to shared memory regions allocated by programs without associating them with a file or persistent storage mechanism.
mmap()
Mapping a file into a process’s address space uses mmap(). Anonymous memory can also be created with mmap(). mmap is part of the standard C library. For anonymous memory, the flags should be MAP_ANONYMOUS or MAP_ANON, in which case fd should be NULL or -1, and offset should be 0.
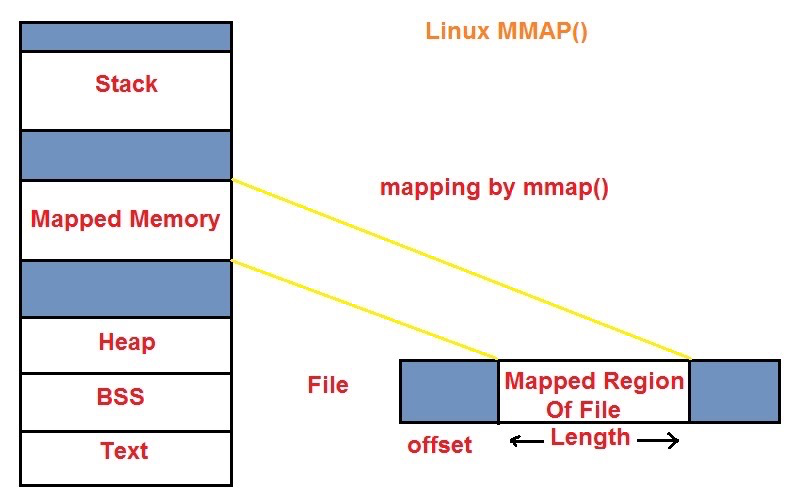
http://www.tutorialsdaddy.com/courses/linux-device-driver/lessons/mmap/
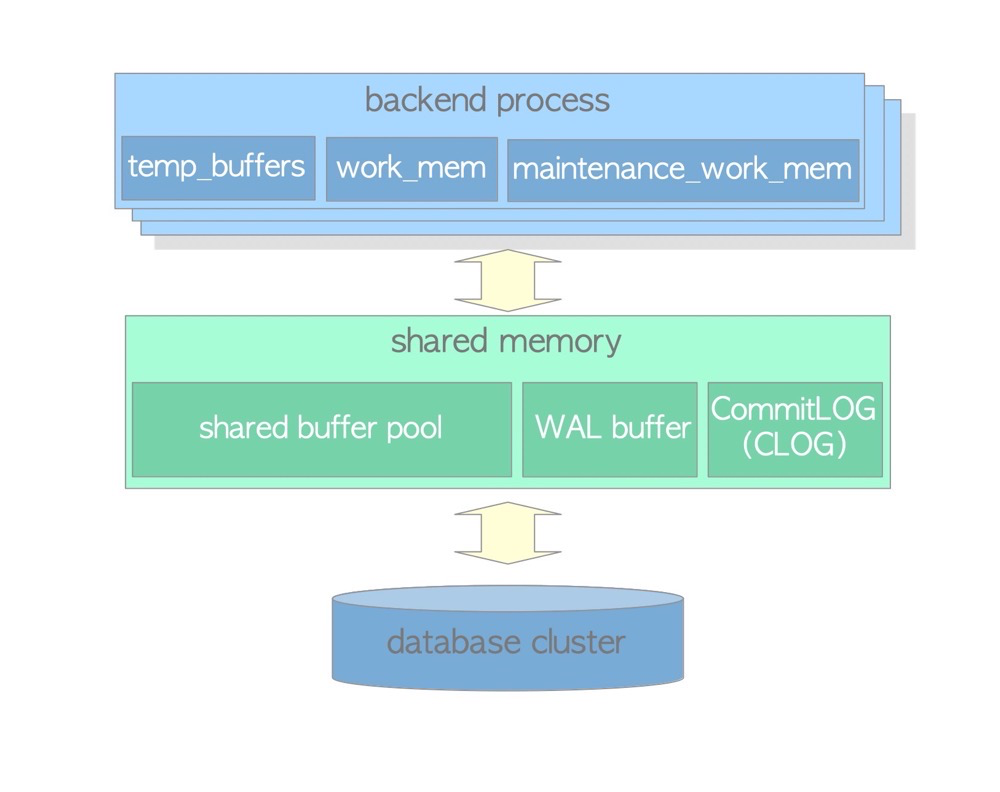
Shared Memory in PostgreSQL#
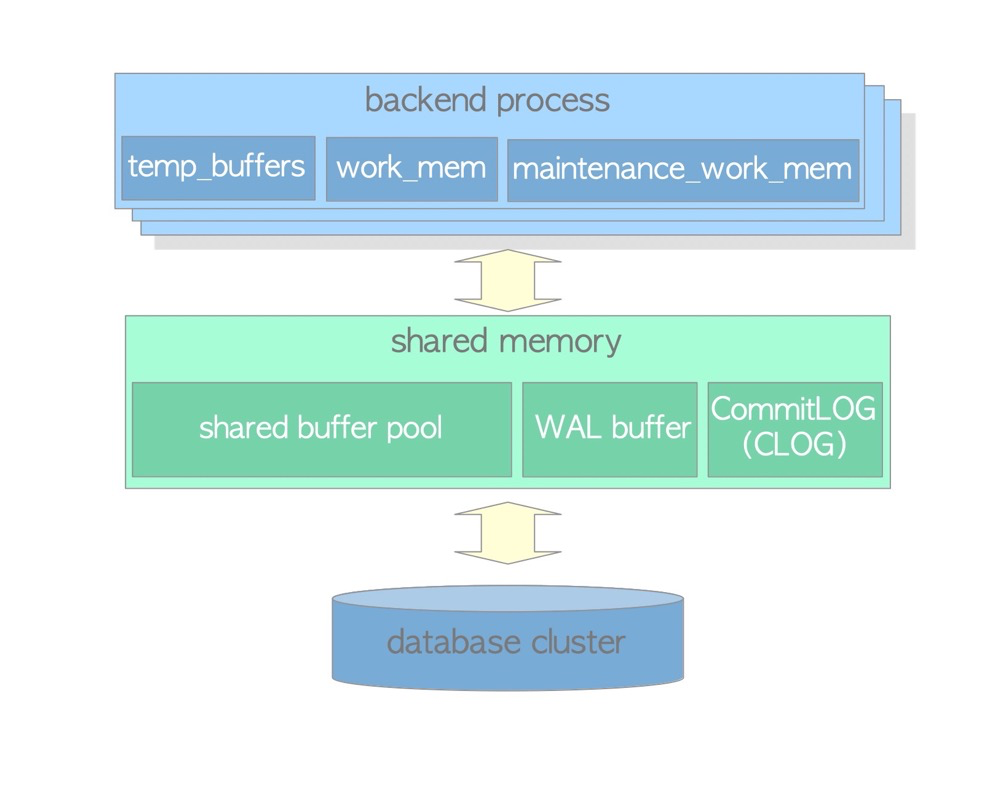 https://www.interdb.jp/pg/pgsql02.html
https://www.interdb.jp/pg/pgsql02.html
PostgreSQL has many types of shared memory: shared buffers, WAL buffer, CLOG buffer, lock space, etc.
Shared Buffer The shared memory area where PostgreSQL caches data, similar to Oracle’s SGA. When data hits the shared buffer, it is read directly from memory without requiring disk I/O. PostgreSQL loads table pages and indexes from persistent storage into this area and operates on them directly.
WAL Buffer To ensure no data is lost in the event of a server failure, PostgreSQL supports the WAL mechanism. WAL data (also called XLOG records) is PostgreSQL’s transaction log. The WAL BUFFER is the buffer for WAL data before it is written to persistent storage.
CLOG BUFFER The Commit Log (CLOG) maintains the status of all transactions (e.g., in_progress, committed, aborted) for the concurrency control mechanism. The corresponding CLOG BUFFER is the buffer for CLOG data before it is written to disk.
PostgreSQL Shared Memory Parameters#
shared_buffers
Default 128MB. Recommended to configure at 25% of total memory. Because PostgreSQL’s private memory generally takes up a significant portion and relies on cache, sufficient memory must be left for the OS. It is therefore not recommended to set this to as high a value (relative to total memory) as you would for Oracle’s SGA.
shared_memory_type
Specifies the shared memory implementation method, not only for shared_buffers but also for other shared data areas.
The shared memory implementation varies by platform. (It appears) on Linux the default is mmap. Other values are:
posix(for POSIX shared memory allocated usingshm_open)sysv(for System V shared memory allocated viashmget)windows(for Windows shared memory)mmap(to simulate shared memory using memory-mapped files stored in the data directory)
By default, PostgreSQL uses a very small amount of System V shared memory, with the vast majority being mmap shared memory. Due to differences between POSIX and System V IPC, signal implementations differ. The shared_memory_type parameter can be explicitly adjusted for the IPC implementation mechanism:
Setting System V IPC (default is
mmap): On Linux and FreeBSD systems, the default shared memory system settings are generally sufficient. Settingshared_memory_typetosysvdoes not take effect on these two platforms (System V semaphores are not used on this platform). On OpenBSD systems, ifshared_memory_typeis set tosysv, the default shared memory system parameters are insufficient and need to be adjusted via sysctl.Setting POSIX IPC: POSIX semaphores are effective on Linux and FreeBSD.
dynamic_shared_memory_type
The mechanism for dynamic shared memory, defaults to posix. This parameter is important for parallel queries. A community email about /dev/shm describes:
PostgreSQL creates segments in /dev/shm for parallel queries (via
shm_open()), not for shared buffers. The amount used is controlled by
work_mem. Queries can use up to work_mem for each node you see in the
EXPLAIN plan, and for each process, so it can be quite a lot if you
have lots of parallel worker processes and/or lots of
tables/partitions being sorted or hashed in your query.
Translation:
- Parallel queries use POSIX and create segments in
/dev/shm - Parallel queries do NOT use
shared_buffers - Each plan node in a query is limited by
work_mem!
min_dynamic_shared_memory
The initial size of memory used by parallel queries, allocated at server startup. Related to huge_pages and dynamic_shared_memory_type.
huge_pages
This parameter controls whether the main shared memory area uses huge pages. This means private memory and OS-level memory are not affected by this setting. PostgreSQL’s use of huge pages is currently only supported on Linux and Windows systems; on Linux systems, it is only supported when shared_memory_type is set to mmap!
| Setting | Description |
|---|---|
| try | default, attempts to allocate huge pages |
| on | uses huge pages; server will not start if allocation fails |
| off | does not use huge pages |
huge_page_size
Controls the size of huge pages. Default is 0, meaning PostgreSQL uses the huge page size provided by the operating system. Setting a non-default value is only supported on Linux.
The pg_shmem_allocations View#
pg_shmem_allocations is a view introduced in PG13 that allows viewing the allocation of major shared memory segments, including those from PostgreSQL itself and extensions.
> select sum(allocated_size)/1024/1024/1024 gb from pg_shmem_allocations;
gb
--------------------
2.7658920288085938
>select * from pg_shmem_allocations order by 4 desc;
name | off | size | allocated_size
-------------------------------------+------------+------------+----------------
Buffer Blocks | 38575360 | 2415919104 | 2415919104
[null] | 2729553280 | 240300672 | 240300672
<anonymous> | [null] | 240198528 | 240198528
Buffer Descriptors | 19700992 | 18874368 | 18874368
XLOG Ctl | 171008 | 16803472 | 16803584
Backend Activity Buffer | 2707733248 | 10680320 | 10680320
...NULL indicates unused memory, anonymous indicates anonymous page allocations.
Most of the memory modules in the pg_shmem_allocations view are difficult to understand. You can find them by searching the source code, but there is no intuitive explanation — it simply displays the data from the source code’s init memory module.
Example: Buffer Blocks: Searching the source code directly for “buffer blocks”:
// Initialize shared buffer pool
// Called only once, during shared memory initialization
void
InitBufferPool(void)
{
bool foundBufs,
foundDescs,
foundIOCV,
foundBufCkpt;
/* Align descriptors to a cacheline boundary. */
BufferDescriptors = (BufferDescPadded *)
ShmemInitStruct("Buffer Descriptors",
NBuffers * sizeof(BufferDescPadded),
&foundDescs);
BufferBlocks = (char *)
ShmemInitStruct("Buffer Blocks",
NBuffers * (Size) BLCKSZ, &foundBufs);
/* Align condition variables to cacheline boundary. */
BufferIOCVArray = (ConditionVariableMinimallyPadded *)
ShmemInitStruct("Buffer IO Condition Variables",
NBuffers * sizeof(ConditionVariableMinimallyPadded),
&foundIOCV);
// Checkpoint BufferIds are used to sort checkpoints in shared memory
CkptBufferIds = (CkptSortItem *)
ShmemInitStruct("Checkpoint BufferIds",
NBuffers * sizeof(CkptSortItem), &foundBufCkpt);
}- The
InitBufferPool()function initializes the shared buffer. - The shared buffer has 4 sub-pools: Buffer Descriptors, Buffer Blocks, Buffer IO Condition Variables, Checkpoint BufferIds.
Private Memory#
Private memory is memory areas allocated by PostgreSQL for each session or process. Unlike shared buffers, there is not just one. Private memory of each process cannot be accessed by other processes.
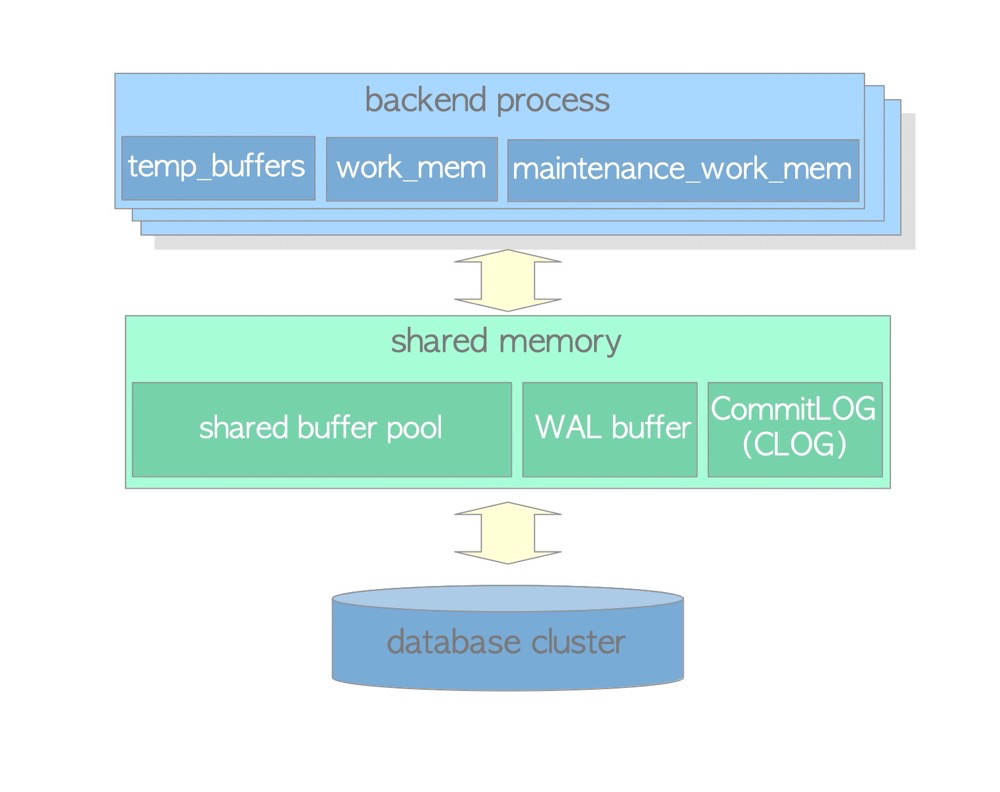
temp_buffers
Temp buffers are used to cache temporary table data, default 8MB. temp_buffers is private memory, so temporary tables are only visible to the current session.
work_mem
The maximum memory used by query operations, such as sorts and hash tables. Default 4MB.
Each query or each plan node?
Official documentation:
Note that a complex query might perform several sort and hash operations at the same time, with each operation generally being allowed to use as much memory as this value specifies before it starts to write data into temporary files.
Community email about /dev/shm:
Queries can use up to work_mem for each node you see in the
EXPLAIN plan,
This parameter applies to each operation (plan node) in a query, not to each query. A query can have many parallel operations, so a single query can also consume a lot of memory. Therefore, the work_mem setting must be made very carefully to avoid exhausting OS memory. The worst case: multiple sessions, each session having multiple plan nodes, and those plan nodes using operations that heavily consume work_mem.
Which operations use work_mem?
For sort operations: ORDER BY, DISTINCT, merge joins. For hash table usage: hash joins, hash-based aggregation, memoize nodes, hash-based IN subqueries.
hash_mem_multiplier
Used to limit the memory size of hash-based operations. The limit is hash_mem_multiplier * work_mem. hash_mem_multiplier defaults to 2.
Although work_mem can be limited, you cannot limit how many hash operations a query uses, so PG13 added this parameter. This means that before version 12 (inclusive), it was very difficult to limit hash table memory.
In our 9.6 production environment, we found a single session consuming 300GB of memory. The culprit was the lack of hash table limits in older versions combined with an execution plan that incorrectly used hash tables.
maintenance_work_mem
Memory area used by operations such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY. These are session-initiated operations with independent processes that use private memory. These maintenance operations cannot run in parallel within a single session, and concurrency is generally low, so this parameter can be set relatively high.
Autovacuum may also use this memory area and limit. See autovacuum_work_mem explanation.
autovacuum_work_mem
Maximum memory used by each autovacuum worker process. Default -1, meaning the maintenance_work_mem parameter is used to limit autovacuum workers. Vacuum uses at most 1GB of memory, and autovacuum has the same limit, so setting the vacuum/autovacuum memory limit above 1GB is meaningless.
vacuum_buffer_usage_limit
Limits the number of pages that VACUUM and ANALYZE can access from shared memory, to prevent too many pages from being evicted. Default is 256KB, 0 means no limit.
When using VACUUM or ANALYZE commands, BUFFER_USAGE_LIMIT can be specified, which takes precedence over the GUC parameter vacuum_buffer_usage_limit.
max_stack_depth
The maximum safe depth of the execution stack, generally meaning the stack depth of a recursive function executed on a single backend process. Default is 2MB. The OS kernel stack limit should be set slightly larger than max_stack_depth.
If a recursive function exceeds the stack depth, the following error is reported:
ERROR: stack depth limit exceeded HINT:
Increase the configuration parameter max_stack_depth (currently 2048kB),
after ensuring the platform's stack depth limit is adequate.logical_decoding_work_mem
Before PG13, logical decoding would retain at most 4096 changes in memory (max_changes_in_memory hardcoded in the source). PG13 introduced the parameter logical_decoding_work_mem. If the data held by logical decoding exceeds this memory value, it is written to disk. Default 64MB.
each replication connection only uses a single buffer of this size,
Generally, the number of logical replication connections is not large, so logical_decoding_work_mem can be set relatively high without issues.
xxCache#
xxCache is also private memory. For example, PostgreSQL caches relation metadata in relcache. The official documentation has relatively little description about this, but PostgreSQL memory problems are often related to it. For instance, the issue of catalog cache causing each backend process to consume a lot of memory without releasing it has appeared in many environments. Here is a community email from 2016 by Digoal about catalog cache consuming excessive memory
Every PostgreSQL session holds system data in own cache. Usually this cache is pretty small (for significant numbers of users). But can be pretty big if your catalog is untypically big and you touch almost all objects from
catalog in session. A implementation of this cache is simple - there is not
delete or limits. There is not garabage collector (and issue related to
GC), what is great, but the long sessions on big catalog can be problem.
The solution is simple - close session over some time or over some number of operations. Then all memory in caches will be released.
The community’s explanation of catalog cache:
- Each session has its own cache for storing system data (metadata, etc.)
- Generally, this cache is small. When the catalog is large and a session has accessed all catalog objects, the cache can become very large.
- Cache management is simple: there is no deletion mechanism or limit (though invalidation messages do exist).
- Closing the session releases the cache.
Tom Lane’s solution was also simple and blunt — add more hardware resources:
I do not think you should complain if that takes a great deal of memory. Either rethink why you need so many tables, or buy hardware commensurate with the size of your problem.
In fact, there are many knowledge points about caches worth paying attention to. After understanding their principles, the solutions to cache-caused memory issues may not be limited to just one approach.
There are many types of xxCache, such as relcache, syscache, plancache, etc. Since documentation is scarce, understanding xxCache requires reading the source code. The main xxCache source code is under src/backend/utils/cache.
Source structure:
inval.c -- Invalidation message dispatcher for private caches. The corresponding shared cache invalidation message handler is sinval.c
relfilenodemap.c -- relfilenode to oid mapping cache
ts_cache.c -- Cache for Tsearch (text search) related objects
relmapper.c -- catalog to relfilenode mapping cache
typcache.c -- type cache
spccache.c -- tablespace cache
evtcache.c -- event trigger cache
attoptcache.c -- attribute cache
plancache.c -- plan cache
relcache.c -- relation cache *Focus of this article*
catcache.c -- system catalog cache *Focus of this article*
syscache.c -- one layer above catcache, also system catalog cache *Focus of this article*
lsyscache.c -- routines for conveniently querying catalog cache, 'l' likely stands for lookup
partcache.c -- routines for operating on partition information in relcacheIn addition to handling various caches, there is also source code for operations and messages. Below we focus on relcache, catcache/syscache, and invalidation messages.
relcache#
What data does a relcache entry store?
Defined in src/include/utils/rel.h:
* POSTGRES relation descriptor (a/k/a relcache entry) definitions.RelationData is the primary data structure for relcache entries:
typedef struct RelationData
{
RelFileNode rd_node; /* physical identifier of relation */
SMgrRelation rd_smgr; /* cached file handle, or NULL */
int rd_refcnt; /* reference count */
BackendId rd_backend; /* if temp relation, the owning backend id */
bool rd_islocaltemp; /* is it a temp rel of the current session */
bool rd_isnailed; /* is it nailed in cache */
bool rd_isvalid; /* is the relcache entry valid */
bool rd_indexvalid; /* are the indexes on the relation valid */
bool rd_statvalid; /* are the statistics on the relation valid */
...
/* some subtransaction info */
SubTransactionId rd_createSubid; /* rel was created in current xact */
SubTransactionId rd_newRelfilenodeSubid; /* highest subxact changing rd_node to current value */
SubTransactionId rd_firstRelfilenodeSubid; /* highest subxact changing rd_node to any value */
SubTransactionId rd_droppedSubid; /* dropped with another Subid set */
Form_pg_class rd_rel; /* pointer to the relation's pg_class tuple */
TupleDesc rd_att; /* tuple descriptor */
Oid rd_id; /* relation's oid */
LockInfoData rd_lockInfo; /* lock info on the relation */
RuleLock *rd_rules; /* rewrite rules */
MemoryContext rd_rulescxt; /* private memory cxt for rd_rules */
TriggerDesc *trigdesc; /* trigger info, NULL if none */
...
/* foreign key info */
List *rd_fkeylist; /* list of ForeignKeyCacheInfo (see below) */
bool rd_fkeyvalid; /* true if list has been computed */
/* partition info */
PartitionKey rd_partkey; /* partition key, or NULL */
MemoryContext rd_partkeycxt; /* private context for rd_partkey, if any */
...
List *rd_indexlist; /* list of all index OIDs */
Oid rd_pkindex; /* primary key oid */
Oid rd_replidindex; /* replica identity index oid */
List *rd_statlist; /* list of extended stats OIDs */
...
PublicationDesc *rd_pubdesc; /* publication descriptor, or NULL */
...
bytea *rd_options; /* parsed pg_class.reloptions */
...
Form_pg_index rd_index; /* index descriptor in pg_index tuple */
struct HeapTupleData *rd_indextuple; /* all pg_index tuples */
MemoryContext rd_indexcxt; /* index cxt */
...
void *rd_amcache; /* available for use by index/table AM */
...
struct FdwRoutine *rd_fdwroutine; /* cached function pointers, or NULL */
...
} RelationData;RelationData contains a large amount of relation-related metadata: oid, pg_class, partition tables, subtransactions, row security policies, statistics, index metadata, AM, etc.
relcache ROUTINES
The ROUTINES source code is located at src/backend/utils/cache/relcache.c.
There are mainly 5 stages:
RelationCacheInitialize- Initialize relcache, initially emptyRelationCacheInitializePhase2- Initialize shared catalogsRelationCacheInitializePhase3- Complete relcache initializationRelationIdGetRelation- Get relation descriptor by relation idRelationClose- Close a relation
These 5 stages are the 5 main logical steps for a rel entry, equivalent to the lifecycle of a rel entry, not the lifecycle of relcache. The first three stages are all relcache initialization — they initialize relcache and load some system tables and their indexes. The last two stages are the logic for obtaining a reldesc and closing a relation; the relcache itself still exists.
Stage 1: RelationCacheInitialize
RelationCacheInitialize initializes relcache:
// Define initial size 400
#define INITRELCACHESIZE 400
void
RelationCacheInitialize(void)
{
HASHCTL ctl;
int allocsize;
/*
* make sure cache memory context exists
*/
// Check if cache mctx exists, create one if not
if (!CacheMemoryContext)
CreateCacheMemoryContext();
// Create hash table indexed by OID for relcache
ctl.keysize = sizeof(Oid);
ctl.entrysize = sizeof(RelIdCacheEnt);
RelationIdCache = hash_create("Relcache by OID", INITRELCACHESIZE,
&ctl, HASH_ELEM | HASH_BLOBS);
...
// Initialize relation mapper
RelationMapInitialize();
}RelationCacheInitialize does not allocate any relation operations; it only initializes relcache memory, hash tables, mappers, etc.
Stage 2: RelationCacheInitializePhase2
void
RelationCacheInitializePhase2(void)
{
MemoryContext oldcxt;
// Initialize relation mapper
RelationMapInitializePhase2();
// If in bootstrap mode, shared catalogs don't exist yet, so do nothing
if (IsBootstrapProcessingMode())
return;
// Switch to current cache mctx
oldcxt = MemoryContextSwitchTo(CacheMemoryContext);
// Try to load shared relcache file
if (!load_relcache_init_file(true)) // If init file not loaded
{
formrdesc("pg_database", DatabaseRelation_Rowtype_Id, true,
Natts_pg_database, Desc_pg_database);
formrdesc("pg_authid", AuthIdRelation_Rowtype_Id, true,
Natts_pg_authid, Desc_pg_authid);
formrdesc("pg_auth_members", AuthMemRelation_Rowtype_Id, true,
Natts_pg_auth_members, Desc_pg_auth_members);
formrdesc("pg_shseclabel", SharedSecLabelRelation_Rowtype_Id, true,
Natts_pg_shseclabel, Desc_pg_shseclabel);
formrdesc("pg_subscription", SubscriptionRelation_Rowtype_Id, true,
Natts_pg_subscription, Desc_pg_subscription);
#define NUM_CRITICAL_SHARED_RELS 5 /* fix if you change list above */
}
MemoryContextSwitchTo(oldcxt);
}The init file is divided into shared and local cache init files. load_relcache_init_file() attempts to load data from these two types of files into relcache (here it should only load the shared ones). If loading fails, it creates descriptors for the 5 basic system tables: pg_database, pg_authid, etc.
Stage 3:
RelationCacheInitializePhase3 is the third stage of initialization and contains the most content:
void
RelationCacheInitializePhase3(void)
{
HASH_SEQ_STATUS status;
RelIdCacheEnt *idhentry;
MemoryContext oldcxt;
bool needNewCacheFile = !criticalSharedRelcachesBuilt;
RelationMapInitializePhase3();
// Switch to CacheMemoryContext
oldcxt = MemoryContextSwitchTo(CacheMemoryContext);
// Like stage 2, load more system table descriptors
if (IsBootstrapProcessingMode() ||
!load_relcache_init_file(false))
{
needNewCacheFile = true;
formrdesc("pg_class", RelationRelation_Rowtype_Id, false,
Natts_pg_class, Desc_pg_class);
formrdesc("pg_attribute", AttributeRelation_Rowtype_Id, false,
Natts_pg_attribute, Desc_pg_attribute);
formrdesc("pg_proc", ProcedureRelation_Rowtype_Id, false,
Natts_pg_proc, Desc_pg_proc);
formrdesc("pg_type", TypeRelation_Rowtype_Id, false,
Natts_pg_type, Desc_pg_type);
#define NUM_CRITICAL_LOCAL_RELS 4 /* fix if you change list above */
}
MemoryContextSwitchTo(oldcxt);
...
// If we haven't obtained critical system indexes yet, do it now
// Because catcache and/or opclass cache depend on critical system indexes in relcache
if (!criticalRelcachesBuilt) // If critical indexes not loaded
{
load_critical_index(ClassOidIndexId,
RelationRelationId);
...
load_critical_index(TriggerRelidNameIndexId,
TriggerRelationId);
#define NUM_CRITICAL_LOCAL_INDEXES 7 /* fix if you change list above */
criticalRelcachesBuilt = true; // Mark: critical system table indexes obtained
}
// Continue processing shared critical system table indexes.
// These shared critical system tables are needed in certain situations (autovacuum, client authentication, etc.)
if (!criticalSharedRelcachesBuilt)
{
load_critical_index(DatabaseNameIndexId,
DatabaseRelationId);
...
load_critical_index(SharedSecLabelObjectIndexId,
SharedSecLabelRelationId);
#define NUM_CRITICAL_SHARED_INDEXES 6 /* fix if you change list above */
criticalSharedRelcachesBuilt = true; // Mark: shared critical system table indexes obtained
}
// Scan all entries in relcache and update those that are erroneous
// from formrdesc or init file
// If erroneous, read pg_class data and replace the erroneous entry
// Because the cache file does not contain rules, triggers, security policies,
// also fetch from pg_class
...
while ((idhentry = (RelIdCacheEnt *) hash_seq_search(&status)) != NULL)
{
Relation relation = idhentry->reldesc;
bool restart = false;
// Ensure relations in use are not flushed
RelationIncrementReferenceCount(relation);
// If it's an erroneous entry, read the tuple from pg_class
if (relation->rd_rel->relowner == InvalidOid)
{
...
memcpy((char *) relation->rd_rel, (char *) relp, CLASS_TUPLE_SIZE);
// Update rd_option
if (relation->rd_options)
pfree(relation->rd_options);
RelationParseRelOptions(relation, htup);
...
ReleaseSysCache(htup);
...
restart = true;
}
// Fix data not in the init file
// For example, relhasrules, relhastriggers may be outdated or incorrect
if (relation->rd_rel->relhasrules && relation->rd_rules == NULL)
{
RelationBuildRuleLock(relation);
if (relation->rd_rules == NULL)
relation->rd_rel->relhasrules = false;
restart = true;
}
if (relation->rd_rel->relhastriggers && relation->trigdesc == NULL)
{
RelationBuildTriggers(relation);
if (relation->trigdesc == NULL)
relation->rd_rel->relhastriggers = false;
restart = true;
}
// Reload row security policies, since init file doesn't contain them
if (relation->rd_rel->relrowsecurity && relation->rd_rsdesc == NULL)
{
RelationBuildRowSecurity(relation);
Assert(relation->rd_rsdesc != NULL);
restart = true;
}
// If tableam needs reloading
if (relation->rd_tableam == NULL &&
(RELKIND_HAS_TABLE_AM(relation->rd_rel->relkind) || relation->rd_rel->relkind == RELKIND_SEQUENCE))
{
RelationInitTableAccessMethod(relation);
Assert(relation->rd_tableam != NULL);
restart = true;
}
// Decrement reference count
RelationDecrementReferenceCount(relation);
...
// Finally, if needed, update the init file (since there may have been reloads, don't waste them)
if (needNewCacheFile)
{
InitCatalogCachePhase2();
/* now write the files */
write_relcache_init_file(true); // Write global init file
write_relcache_init_file(false); // Write private init file
}
}Compared to Stage 2 which loads 5 system tables, RelationCacheInitializePhase3() loads more system tables, such as pg_class, pg_proc, and the indexes on these tables. Of course, the precondition for loading these rels is that they are not in cache or have expired. After reloading is complete, the “new” catalog is written to the init file.
Looking at the write_relcache_init_file function source code when writing the init file, we can understand the meaning of the true and false parameters:
static void
write_relcache_init_file(bool shared)
{
...
if (shared)
{
snprintf(tempfilename, sizeof(tempfilename), "global/%s.%d",
RELCACHE_INIT_FILENAME, MyProcPid);
snprintf(finalfilename, sizeof(finalfilename), "global/%s",
RELCACHE_INIT_FILENAME);
}
else
{
snprintf(tempfilename, sizeof(tempfilename), "%s/%s.%d",
DatabasePath, RELCACHE_INIT_FILENAME, MyProcPid);
snprintf(finalfilename, sizeof(finalfilename), "%s/%s",
DatabasePath, RELCACHE_INIT_FILENAME);
}
...
}true means write to the global init file.
false means write to the local init file.
The RELCACHE_INIT_FILENAME parameter macro definition:
#define RELCACHE_INIT_FILENAME "pg_internal.init"So the written init files are:
- shared:
global/pg_internal.init - local:
DatabasePath/pg_internal.initandDatabasePath/pg_internal.init.myPID
Let’s look at real init file paths:
[postgres]$ find ./ -name *init*
./global/pg_internal.init #shared
./base/1/pg_internal.init #local
./base/13577/pg_internal.init #local
./base/13578/pg_internal.init #local
./base/16398/pg_internal.init #local
./base/16811/pg_internal.init #local
./base/17674/pg_internal.init #localDiagram of the three initialization stages call flow:
 (https://blog.japinli.top/2022/07/postgres-relcache-and-syscache/)
(https://blog.japinli.top/2022/07/postgres-relcache-and-syscache/)
Stage 4: RelationIdGetRelation
Find a reldesc by OID. The caller only needs an AccessShareLock on the OID and is responsible for incrementing/decrementing the rel’s reference count.
Relation
RelationIdGetRelation(Oid relationId)
{
Relation rd;
// Ensure we're in a transaction
Assert(IsTransactionState());
// First try to find in cache via reldesc
RelationIdCacheLookup(relationId, rd);
if (RelationIsValid(rd))
{
// Return NULL for dropped relations
if (rd->rd_droppedSubid != InvalidSubTransactionId)
{
Assert(!rd->rd_isvalid);
return NULL;
}
RelationIncrementReferenceCount(rd);
if (!rd->rd_isvalid) // If cached rel is invalid, revalidate it
{
if (rd->rd_rel->relkind == RELKIND_INDEX ||
rd->rd_rel->relkind == RELKIND_PARTITIONED_INDEX) // Load index info directly
RelationReloadIndexInfo(rd);
else // For non-index, clear the reldesc
RelationClearRelation(rd, true);
...
}
return rd;
}
// No reldesc found, create a new one
rd = RelationBuildDesc(relationId, true);
if (RelationIsValid(rd))
RelationIncrementReferenceCount(rd);
return rd;
}RelationIdGetRelation is relatively simple: it obtains a reldesc and index info via OID.
Stage 5: RelationClose
The code for RelationClose is also quite simple:
void
RelationClose(Relation relation)
{
// No lock operations needed, simply decrement refcount
RelationDecrementReferenceCount(relation);
// If no sessions have the relation open, partition descriptors can be deleted
if (RelationHasReferenceCountZero(relation))
{
if (relation->rd_pdcxt != NULL &&
relation->rd_pdcxt->firstchild != NULL)
MemoryContextDeleteChildren(relation->rd_pdcxt);
if (relation->rd_pddcxt != NULL &&
relation->rd_pddcxt->firstchild != NULL)
MemoryContextDeleteChildren(relation->rd_pddcxt);
}
#ifdef RELCACHE_FORCE_RELEASE
if (RelationHasReferenceCountZero(relation) &&
relation->rd_createSubid == InvalidSubTransactionId &&
relation->rd_firstRelfilenodeSubid == InvalidSubTransactionId)
RelationClearRelation(relation, false);
#endif
}RelationClose is the operation for closing access to a relation. Generally, this function only decrements the refcount of sessions accessing the relation. However, there are exceptions:
- When
refcountis 0,MemoryContextDeleteChildren()is executed. This function deletes the mctx related to child partition descriptors, which does release memory. - When
refcountis 0 and the macroRELCACHE_FORCE_RELEASEis defined, theRelationClearRelation()function deletes the hash table entry. This step does not release memory. TheRELCACHE_FORCE_RELEASEmacro was not found (only available with explicit compilation?).
relcache is not completely without memory release logic, but the trigger conditions are relatively strict, and the freed memory is not all of the relcache memory.
syscache/catcache#
CatCache caches tuples from system tables. Built on top of CatCache is another layer called SysCache (KV interface). Essentially, CatCache and SysCache together reorganize data from system tables in memory using a KV approach. syscache/catcache is more complex. Here I’ll briefly extract some easily interpretable content, mainly to understand the cached content and loading mechanism of syscache. For deeper source code analysis, refer to PostgreSQL Source Analysis — Storage Management — Memory Management (3) and PostgreSQL RelCache and SysCache Caches.
catcache struct
typedef struct catcache
{
int id; // cache id, defined in syscache.h
int cc_nbuckets; // number of hash buckets for this cache
TupleDesc cc_tupdesc; // tuple descriptor, copied from reldesc
...
const char *cc_relname; // system table name corresponding to the tuple
Oid cc_reloid; // system table OID
Oid cc_indexoid; // index OID for cache key
bool cc_relisshared; // is the table shared across databases?
...
// Statistics used by catcache
#ifdef CATCACHE_STATS
long cc_searches; // number of queries against this catcache
long cc_hits; // hit count
long cc_neg_hits; // negative entry hit count
...
#endif
} CatCache;catcache entry
typedef struct catctup
{
int ct_magic; // identifies this catctup entry
#define CT_MAGIC 0x57261502
uint32 hash_value; // hash key value for this tuple
...
// Dead tuples won't be returned, but will be removed from catcache when refcount reaches zero
int refcount; // tuple refcount, indicates whether it's being accessed
bool dead; // dead tuple, but not yet cleaned up
bool negative; // is this a negative cache entry?
HeapTupleData tuple; // tuple header structure
...
CatCache *my_cache; // link to the catcache this tuple belongs to
} CatCTup;SearchCatCacheMiss() Function
SearchCatCacheMiss() is the main function for catcache hit/miss, and after a miss it accesses tuples from the dictionary.
static pg_noinline HeapTuple
SearchCatCacheMiss(CatCache *cache,
int nkeys,
uint32 hashValue,
Index hashIndex,
Datum v1,
Datum v2,
Datum v3,
Datum v4)
{
ScanKeyData cur_skey[CATCACHE_MAXKEYS];
Relation relation;
SysScanDesc scandesc;
HeapTuple ntp;
CatCTup *ct;
Datum arguments[CATCACHE_MAXKEYS];
...
// Tuple not found in cache, so try to find it directly from the table
// If found, add it to cache
// If not found, add a negative cache entry
relation = table_open(cache->cc_reloid, AccessShareLock);
scandesc = systable_beginscan(relation,
cache->cc_indexoid,
IndexScanOK(cache, cur_skey),
NULL,
nkeys,
cur_skey);
ct = NULL;
// When tuple is valid, create an entry
while (HeapTupleIsValid(ntp = systable_getnext(scandesc)))
{
ct = CatalogCacheCreateEntry(cache, ntp, arguments,
hashValue, hashIndex,
false); // Create an entry
// Immediately increment refcount
ResourceOwnerEnlargeCatCacheRefs(CurrentResourceOwner);
ct->refcount++;
ResourceOwnerRememberCatCacheRef(CurrentResourceOwner, &ct->tuple);
break; /* assume only one match */
}
systable_endscan(scandesc);
table_close(relation, AccessShareLock);
/*
// If no tuple found, create a negative cache entry (a dummy tuple)
// The dummy tuple has key columns, all others are null
// During startup, the invalidation mechanism is not active and entries
// cannot be cleaned up if a tuple is actually created later
// So during this phase, negative entries are not created
*/
if (ct == NULL) // If no tuple found, enter the following logic
{
if (IsBootstrapProcessingMode()) // Return NULL directly if in startup phase
return NULL;
ct = CatalogCacheCreateEntry(cache, NULL, arguments,
hashValue, hashIndex,
true); // Create entry
CACHE_elog(DEBUG2, "SearchCatCache(%s): Contains %d/%d tuples",
cache->cc_relname, cache->cc_ntup, CacheHdr->ch_ntup);
CACHE_elog(DEBUG2, "SearchCatCache(%s): put neg entry in bucket %d",
cache->cc_relname, hashIndex);
// Negative entries are not returned to caller, refcount remains 0
return NULL;
}
...
return &ct->tuple;
}The dummy tuple (negative cache entry) here is brilliant — caching a non-existent tuple in catcache prevents needing to query the data dictionary again on the next access, avoiding repeated pointless data dictionary lookups.
Cache Validation Messages#
When a tuple is updated or deleted, due to transaction visibility rules, these tuples that become invisible after the transaction ends need to be communicated to caches, invalidating the cached tuples so they can be reloaded on the next read. Similarly, when new tuples are inserted, negative cache entries in caches may also need to be flushed to match the new tuples. One common scenario is DDL — DDL may cause certain tuples in the metadata to become invalid, at which point cache validation messages need to be sent to various private caches to clean up cache entries. This cache validation mechanism applies to managing private cache pools like syscache and relcache. Since idle backends won’t read sinval events, messages must be actively sent to allow lagging backends to “catch up.” When completing a transaction, invalidation events must be broadcast to other backends via the SI message queue.
The source code is split into two parts: sinval and inval.
- Invalidation interface: src/include/utils/inval.h
- Invalidation dispatch: src/backend/utils/cache/inval.c
- Invalidation message sharing interface: src/include/storage/sinval.h
- Invalidation message sharing dispatch: src/backend/storage/ipc/sinval.c
- Invalidation message sharing data structures interface: src/include/storage/sinvaladt.h
- Invalidation message sharing data structures: src/backend/storage/ipc/sinvaladt.c
In src/backend/utils/cache/inval.c, the shared-invalidation message structure is defined:
typedef union
{
int8 id; /* type field --- must be first */
SharedInvalCatcacheMsg cc;
SharedInvalCatalogMsg cat;
SharedInvalRelcacheMsg rc;
SharedInvalSmgrMsg sm;
SharedInvalRelmapMsg rm;
SharedInvalSnapshotMsg sn;
} SharedInvalidationMessage;Shared-invalidation messages include the following types:
- Invalidate a specific catcache entry
- Invalidate the entire catcache entry for a particular system catalog
- Invalidate a specific relcache entry
- Invalidate ALL relcache entries
- Invalidate the smgr cache entry for a particular physical relation
- Invalidate a mapped-relation
- Invalidate saved snapshots that scanned a relation
Messages are located in the shared memory queue until all other processes read them. Normally, receiving processes only read messages at specific times, so if a receiving process is idle (not processing any user requests) or busy doing other things such that they don’t have time to read these messages, the messages may remain in shared memory indefinitely. In unfortunate situations, if this shared memory space is no longer available for processes to store new messages, that process will have to take on the cleanup task. (In practice, this cleanup is done proactively, so space rarely runs out.) To discard old messages, it must be ensured that all other processes have read them. If some processes cannot do so for the above reasons, it must explicitly signal the lagging processes to catch up. Once the lagging processes have caught up, these messages can be freely discarded. When processing a message, it first checks whether the catalog tuple specified in the message is currently in the cache (the message also specifies the syscache identifier). If so, it is removed from the cache’s hash table. The next time that tuple is requested, it will be re-read from the underlying catalog table and added to the hash table, so subsequent accesses will read the new value. If a process has already locked a particular database object preventing concurrent processes from modifying it, it can continue using the cached tuple until the lock is released.
xxCache Issues Summary#
There are many types of xxCache, among which the more notable ones are plancache, relcache, and syscache. These caches belong to private memory and exist in each backend process. These caches have no LRU mechanism to evict stale data; they use invalidation messages to clean up globally-unneeded snapshots and metadata information, such as when an object is deleted.
- relcache is the place most likely to occupy significant memory. relcache loads metadata information, and during initialization it reads *.init files to speed up loading metadata into relcache. Later, when other metadata needs to be read, loading also occurs.
- catcache caches tuple information from the data dictionary. syscache is one layer above catcache — they can be understood as jointly implementing this data dictionary cache. If a tuple does not exist, a negative entry is created to avoid accessing the data dictionary again on the next visit. Similarly, a catcache miss will also read tuples from the data dictionary.
- Cache validation messages exist to inform caches that cached tuples and snapshot information have become stale. They can invalidate corresponding relcache and catcache entries. Entries are removed from the cache’s hash table, which releases memory.
Since the cache memory release mechanisms are very limited, when there is a lot of metadata (many tables, partition tables), relcache and catcache can consume a lot of memory — and this can happen for every backend. Possible solutions:
- Global cache. Like Oracle’s dictionary cache, cache in one place with shared access. For example, PolarDB’s Global RelCache has already implemented this functionality.
- LRU. An LRU mechanism suitable for caches is needed to separate hot and cold ends, cleaning excessively old cache entries from the hash table. This might require cache limit parameters to restrict cache size — ideally one per cache…
- Threading mode. Memory is shared and accessed by all threads — a natural advantage.
- Periodically disconnect long connections. All of the above are just wishful thinking.
- Don’t create too many tables or partitions (note that in PostgreSQL, partitions are also tables).
Memory Contexts#
PostgreSQL manages memory through the memory context mechanism. I previously did a translation about memory contexts, roughly summarized as follows:
- C language requires explicit memory deallocation. To reduce the risk of memory leaks, PostgreSQL implemented memory contexts to manage private memory.
- Memory contexts do not require freeing memory after each use; instead, memory is released by deleting a particular context.
- Memory contexts form a hierarchical structure — releasing a parent context recursively deletes all child contexts.
- Aside from debugging, observing memory context usage is quite difficult. Starting from PG14, the
pg_backend_memory_contextsview can observe the current memory context usage of the current session.
Timing of memory context creation during SQL operations:

(https://www.pgcon.org/2019/schedule/attachments/514_introduction-memory-contexts.pdf)
Source Code Analysis#
In PostgreSQL, all memory allocation, deallocation, and resetting is done within memory contexts, so the malloc(), realloc(), and free() system call functions are not used directly. Instead, palloc(), repalloc(), and pfree() are used for memory allocation, reallocation, and deallocation.
C Library Memory Functions C library dynamic memory allocation functions include:
- malloc(): The C library’s malloc() function (memory allocation) is used to allocate large blocks of memory.
- calloc(): The C library’s calloc() function (contiguous allocation) is used to allocate contiguous memory.
- free(): Used to release memory. malloc() and calloc() do not release memory; after dynamic memory allocation, free() must be used to release it.
- realloc(): Used for memory re-allocation.
There is also a C library function memset(), used to fill a memory block with a specific value.
PostgreSQL-Defined Memory Functions
The functions actually heavily used in PostgreSQL source code for memory allocation, deallocation, etc., are palloc(), palloc0(), repalloc(), and pfree(). They mostly do not directly interact with OS memory (C library functions); only in certain cases do they call C library memory functions. This essentially adds a layer of protection over OS memory operations, with PostgreSQL handling small memory operations on its own.
palloc():
palloc() primarily calls the alloc method of MemoryContext. alloc corresponds to calling the MemoryContextAlloc function, which in turn calls the AllocSetAlloc function specified in the methods field of the current memory context.
void *
palloc(Size size)
{
/* duplicates MemoryContextAlloc to avoid increased overhead */
void *ret;
MemoryContext context = CurrentMemoryContext;
...
ret = context->methods->alloc(context, size);
....
return ret;
}palloc0():
void *
palloc0(Size size)
{
...
ret = context->methods->alloc(context, size);
...
MemSetAligned(ret, 0, size);
return ret;
}MemSetAligned is macro-defined and actually calls C library memset for memory filling, but MemSetAligned passes 0 as the value.
#define MemSetAligned(start, val, len)\
...\
memset(_start, _val, _len); \
... Compared to palloc, palloc0 not only calls alloc(context, size) but also zeroes out the memory content.
repalloc():
repalloc() primarily calls the realloc method of MemoryContext. The realloc function pointer corresponds to the AllocSetRealloc function.
/*
* repalloc
* Adjust the size of a previously allocated chunk.
*/
void *
repalloc(void *pointer, Size size)
{
MemoryContext context = GetMemoryChunkContext(pointer);
...
ret = context->methods->realloc(context, pointer, size);
...
return ret;
}pfree():
pfree calls the free_p function pointer in the methods field of the memory context to which the memory chunk belongs, to release the memory chunk’s space. Currently, in PostgreSQL, the free_p pointer actually points to the AllocSetFree function.
/*
* pfree
* Release an allocated chunk.
*/
void
pfree(void *pointer)
{
MemoryContext context = GetMemoryChunkContext(pointer);
context->methods->free_p(context, pointer);
VALGRIND_MEMPOOL_FREE(context, pointer);
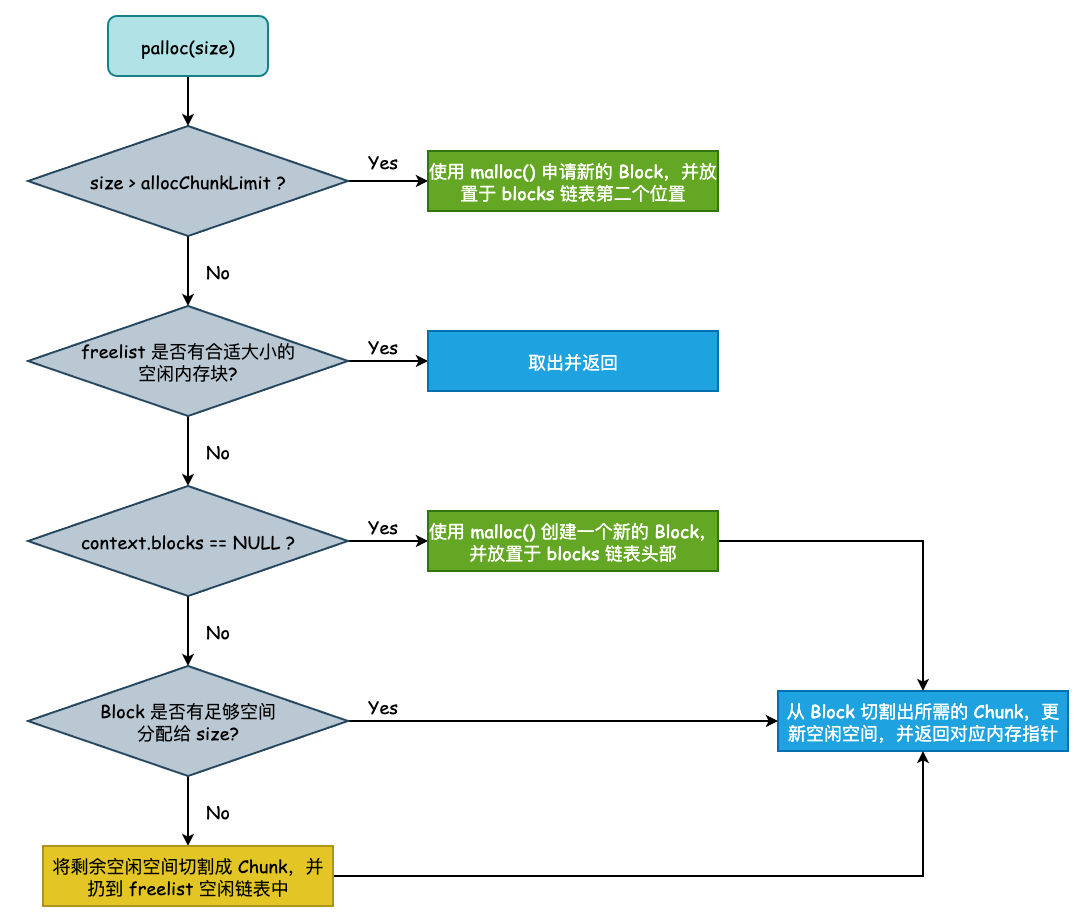
}AllocSetAlloc Memory Allocation
Looking at the alloc method within, alloc ultimately points to the AllocSetAlloc function. AllocSetAlloc looks rather complex, but it becomes easier to understand when read in segments:
static void *
AllocSetAlloc(MemoryContext context, Size size)
{
AllocSet set = (AllocSet) context;
AllocBlock block;
AllocChunk chunk;
int fidx;
Size chunk_size;
Size blksize;
...
// If requested memory exceeds the max chunk size, allocate an entire memory block
if (size > set->allocChunkLimit)
{
...
block = (AllocBlock) malloc(blksize);
...
}
// If requested memory is less than chunk size, check free list for available free chunks
fidx = AllocSetFreeIndex(size);
chunk = set->freelist[fidx];
if (chunk != NULL) // There are chunks available in the free list
{
Assert(chunk->size >= size);
set->freelist[fidx] = (AllocChunk) chunk->aset;
chunk->aset = (void *) set;
...
return AllocChunkGetPointer(chunk);
}
...
// If there's space, try to place the chunk in the allocation block; if not, create a new block
if ((block = set->blocks) != NULL)
{
Size availspace = block->endptr - block->freeptr;
if (availspace < (chunk_size + ALLOC_CHUNKHDRSZ))
{
...
block = NULL;
}
}
// No space, create a new block
if (block == NULL)
{
Size required_size;
...
// Requested block size is a power of 2, not exceeding maxBlockSize
required_size = chunk_size + ALLOC_BLOCKHDRSZ + ALLOC_CHUNKHDRSZ;
while (blksize < required_size)
blksize <<= 1;
// Use malloc to allocate the block, size is a power of 2
block = (AllocBlock) malloc(blksize);
...
}
(https://smartkeyerror.com/PostgreSQL-MemoryContext)
palloc() => AllocSetAlloc() only calls malloc() to request memory from the OS when the requested memory exceeds the chunk size limit or when there are no free blocks in the freelist. In all other cases, it takes existing free chunks from the freelist.
pfree() is similar (not demonstrated here):
pfree() => AllocSetFree() releases a specified memory chunk in a memory context. If the chunk to be freed is the only chunk in the memory block, free() is called directly to release that memory block. Otherwise, the specified chunk is added to the freelist for the next allocation.
Viewing Memory Context Size#
- PG14+:
pg_backend_memory_contextsview to directly inspect memory context memory within the database.
lzldb=> SELECT * FROM pg_backend_memory_contexts ORDER BY used_bytes DESC LIMIT 5;
name | ident | parent | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes
-------------------------+-------+------------------+-------+-------------+---------------+------------+-------------+------------
CacheMemoryContext | | TopMemoryContext | 1 | 1048576 | 8 | 508216 | 1 | 540360
Timezones | | TopMemoryContext | 1 | 104120 | 2 | 2616 | 0 | 101504
TopMemoryContext | | | 0 | 97680 | 5 | 12904 | 7 | 84776
ExecutorState | | PortalContext | 3 | 49208 | 4 | 4424 | 3 | 44784
WAL record construction | | TopMemoryContext | 1 | 49768 | 2 | 6360 | 0 | 43408- PG14+:
pg_log_backend_memory_contextsfunction outputs memory information to the log file, producing output similar toMemoryContextStats(TopMemoryContext)log output.
SELECT pg_log_backend_memory_contexts(9293);- Universal — gdb
MemoryContextStats(TopMemoryContext)
Use gdb to call MemoryContextStats(TopMemoryContext):
gdb
(gdb) attach 9293
(gdb) p MemoryContextStats(TopMemoryContext)
$2 = voidLog output:
TopMemoryContext: 97680 total in 5 blocks; 16856 free (16 chunks); 80824 used
TableSpace cache: 8192 total in 1 blocks; 2088 free (0 chunks); 6104 used
RowDescriptionContext: 8192 total in 1 blocks; 6888 free (0 chunks); 1304 used
MessageContext: 8192 total in 1 blocks; 6888 free (1 chunks); 1304 used
Operator class cache: 8192 total in 1 blocks; 552 free (0 chunks); 7640 used
...
Relcache by OID: 16384 total in 2 blocks; 3504 free (2 chunks); 12880 used
CacheMemoryContext: 524288 total in 7 blocks; 90840 free (0 chunks); 433448 used
index info: 2048 total in 2 blocks; 904 free (0 chunks); 1144 used: pg_statistic_ext_relid_index
...
index info: 2048 total in 2 blocks; 824 free (0 chunks); 1224 used: pg_database_oid_index
index info: 2048 total in 2 blocks; 824 free (0 chunks); 1224 used: pg_authid_rolname_index
WAL record construction: 49768 total in 2 blocks; 6360 free (0 chunks); 43408 used
PrivateRefCount: 8192 total in 1 blocks; 2616 free (0 chunks); 5576 used
MdSmgr: 8192 total in 1 blocks; 7592 free (0 chunks); 600 used
LOCALLOCK hash: 8192 total in 1 blocks; 552 free (0 chunks); 7640 used
Timezones: 104120 total in 2 blocks; 2616 free (0 chunks); 101504 used
ErrorContext: 8192 total in 1 blocks; 7928 free (3 chunks); 264 usedSummary#
references#
src/backend/utils/mmgr/mcxt.c
src/backend/utils/mmgr/README
https://momjian.us/main/writings/pgsql/inside_shmem.pdf
https://www.interdb.jp/pg/pgsql02.html
https://www.postgresql.org/docs/current/runtime-config-resource.htm
https://www.postgresql.org/docs/16/kernel-resources.html
https://blog.csdn.net/weixin_45644897/article/details/121340327
https://help.aliyun.com/zh/polardb/polardb-for-postgresql/global-cache
https://www.cnblogs.com/feishujun/p/PostgreSQLSourceAnalysis_cache02.html
https://blog.japinli.top/2022/07/postgres-relcache-and-syscache/
https://amitlan.com/2019/06/14/caches-inval.html
https://www.cybertec-postgresql.com/en/memory-context-for-postgresql-memory-management/
https://www.geeksforgeeks.org/dynamic-memory-allocation-in-c-using-malloc-calloc-free-and-realloc/
https://www.cnblogs.com/feishujun/p/PostgreSQLSourceAnalysis_mmgr01.html
https://www.cnblogs.com/feishujun/p/PostgreSQLSourceAnalysis_mmgr02.html
https://smartkeyerror.com/PostgreSQL-MemoryContext
https://jnidzwetzki.github.io/2022/05/28/postgres-memory-context.html
https://www.pgcon.org/2019/schedule/attachments/514_introduction-memory-contexts.pdf