论文:Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases
SIGMOD best paper:https://sigmod.org/sigmod-awards/sigmod-best-paper-award/
CXL和PolarDB-CXL#
CXL的概念#
CXL:开放的行业标准,由 CXL 联盟 (2019 年由英特尔、AMD、ARM 等科技巨头创立) 制定的高速互连规范。它代表了计算架构的演进方向。目前刚演进到CXL 4.0
| 特性 | CXL 1.0/1.1 | CXL 2.0 | CXL 3.0/3.1 | CXL 4.0 (最新) |
|---|---|---|---|---|
| 发布时间 | 2019 年 3 月 / 9 月 | 2020 年 10 月 | 2022 年 8 月 / 2023 年 11 月 | 2025 年 11 月 |
| 基础协议 | PCIe 5.0 (32 GT/s) | PCIe 5.0 (32 GT/s) | PCIe 6.0 (64 GT/s) | PCIe 7.0 (128 GT/s) |
| 最大带宽 | 1TB/s | 1TB/s | 2TB/s | 4TB/s+ |
| 拓扑规模 | 点对点 / 简单星型 | 单交换机 (≤32 节点) | 多级 Fabric (4096 节点) | 超大规模 Fabric |
据我搜索的资料中,摘取两个比较影响深刻的对CXL的描述:
- 内存即服务
- 近内存计算和扩展
CXL switch:是交换芯片,物理硬件。很多厂商在做工业化实现,论文中特指产商是XConn Tech的产品 CXL 2.0 switch。需要注意的是,截止2025年11月22日,XConn这家只有CXL 2.0 switch,没有3.0的产品,市面上是有支持3.0+标准的交换芯片的产品panmnesia CXL 3.2 Fabric Switch
polarCXLMem:据论文所说是“首个基于CXL-switch的分离式内存系统”。但是论文中提到“we leverage the world’s first CXL switch[50]”也就是特指Xconn tech CXL 2.0 switch,然后再提到“PolarCXLMem is the first CXL-switch-based disaggregated memory”。这句话可以理解为两种含义:
- 首个基于CXL switch的分离式内存系统
- 首个基于Xconn tech CXL 2.0 switch的分离式内存系统
polardb-cxl:其实论文中没有这个概念,但是行业在用这个词。这个词代表“integrate PolarCXLMem into the multi-primary version of PolarDB,known as PolarDB-MP”,相当于“PolarDB-MP的CXL升级版”。论文中反复使用这么长一段话,但是始终没有用polardb-cxl这个词。为了方便起见,本文中使用polardb-cxl这个词代表其本质含义。
RDMA vs CXL#
PolarDB-MP用的是RDMA架构,PolarDB-CXL是CXL架构:
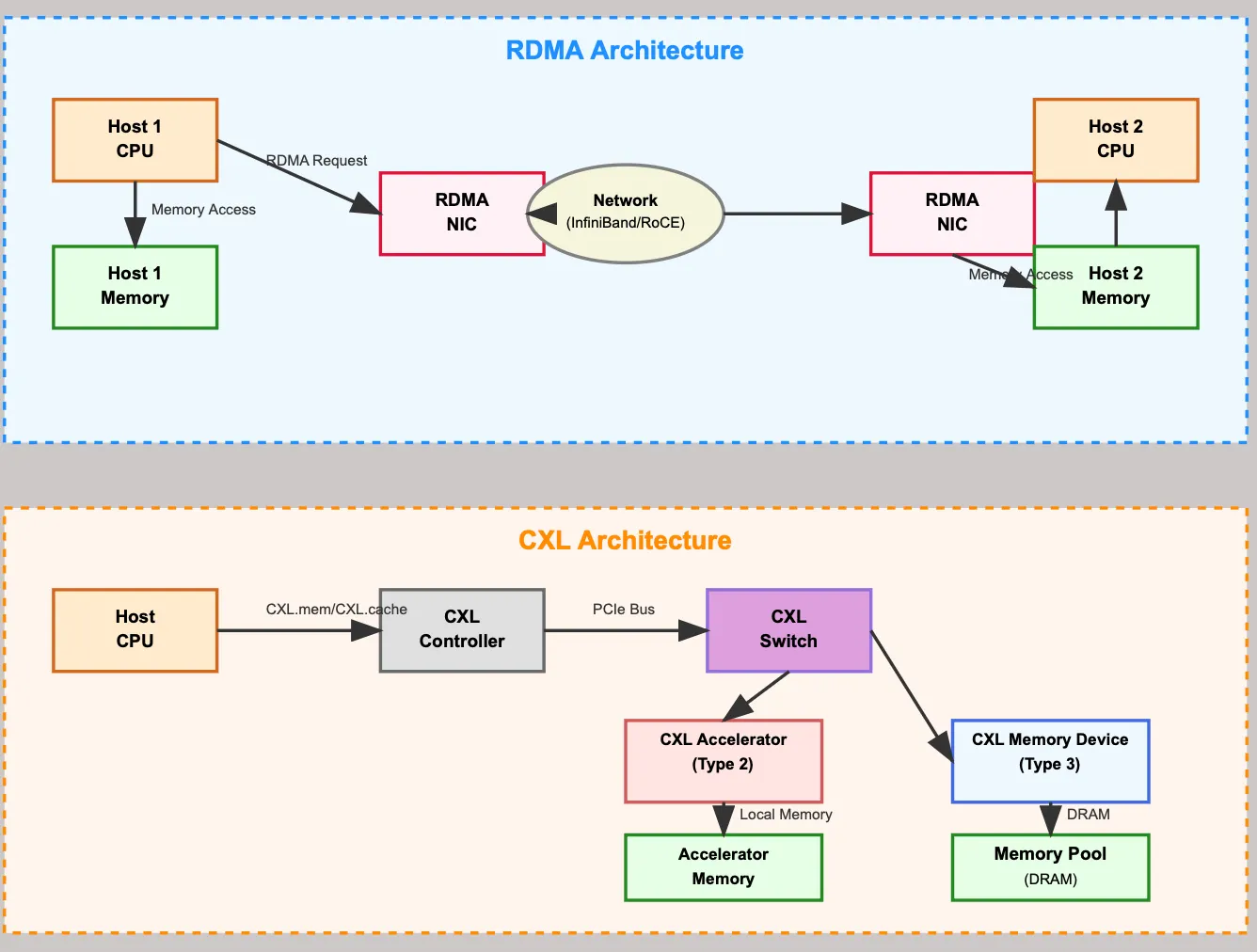
(https://medium.com/@anan.mirji/cxl-switch-vs-rdma-a-technical-comparison-for-high-performance-interconnects-6aaa031cde31)
RDMA架构是跨主机的分布式互联架构,CXL架构这是单主机的扩展互联架构。
核心差异
| 维度 | RDMA 架构 | CXL 架构 |
|---|---|---|
| 拓扑结构 | 多主机 + 网络交换机的分布式架构 | 单主机 + CXL 交换机的扩展架构 |
| 通信介质 | 网络(InfiniBand/RoCE) | PCIe 总线(CXL 基于 PCIe 物理层) |
| 核心组件 | RDMA NIC(专用网卡) | CXL Controller、CXL Switch |
| 资源归属 | 跨独立主机的 “远程资源” | 主机架构内的 “扩展资源” |
CXL的优势#
CXL相较于RDMA的优势:
低延迟:CXL通过PCIe连接主机或者设备上的内存;而RDMA 需要在InfiniBand与PCIe 之间进行协议接口转换
指令支持:CXL提供了原生的 load/store指令,使CPU能像访问本地内存一样直接操作远程CXL设备内存;而RDMA需要从远端内存读到本地内存,在本地处理后再回写到远端内存。
简化应用:RDMA需要特殊的接口和驱动,需要专业人员设计复杂的程序;而CXL提供透明的内存空间极大简化应用设计
内存融合:CXL 3.0支持物理硬件级内存融合
polardb-mp存在的问题和CXL能提供的价值:
CXL说MP的问题:
内存页是4-16K的,就算只需要很少的数据传输,也必须在本地内存和共享内存间传输数据,这导致了读写放大。
维护本地内存需要额外的内存开销,这降低了吞吐
恢复非常花时间
RDMA远好于TCP/IP,但在高并发下有 “门铃寄存器隐式竞争” 和 “缓存颠簸”问题
数据库本身要维护共享内存
CXL带来的好处:
- 消除“共享内存-本地内存”的层级内存结构,也消除了层级结构的维护消耗和读写放大问题。因为CXL load/store本地内存足够快,所以允许直接store所有的buffer pages
- 以缓存行(64B)为最小CPU缓存和主存的传输单位,而不是polardb-MP的4K
- 节约主存。主存(DRAM)的成本非常高,大约占服务器/机架成本的40-50%
- 简化系统设计。在现有系统上最小化改造,对于商业数据库的稳定性来说很重要。
- PolarRecv:基于CXL做的立即恢复的系统。在数据库crash后,data和metadata都还在CXL上,可以直接在CXL memory上读到一致性状态,所以恢复非常快。(这看起来跟pg的page cache缓存可以帮助crash后快速启动有类似处)
DRAM vs RDMA vs CXL:
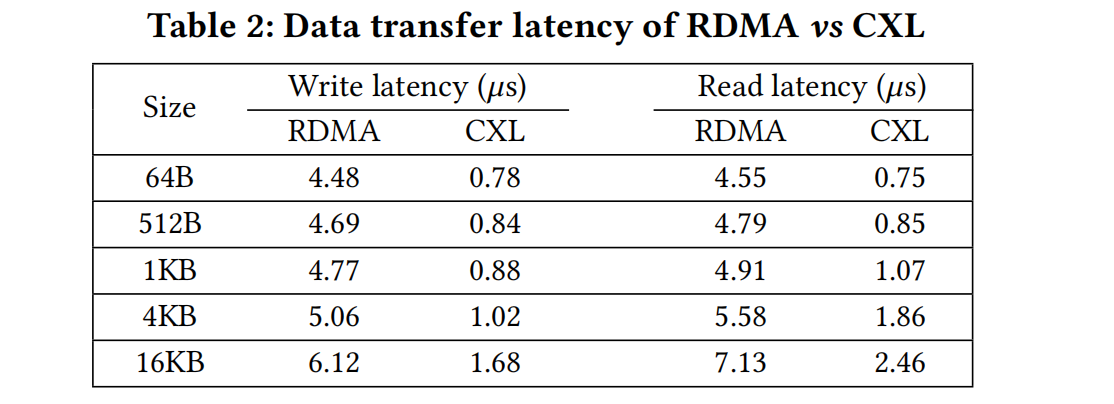
在数据量较少时,RDMA比CXL延迟高不少,数据大一点RDMA的延迟就稍微好点。本地访问内存DRAM要略好于通过CXL访问。
总体来说,CXL内存访问的延迟略高于DRAM但好于RDMA。
对于CXL延迟高于DRAM,论文这样解释“database buffer pool operations are more sensitive to bandwidth than latency”,对于数据库内存来说,带宽比延迟重要。
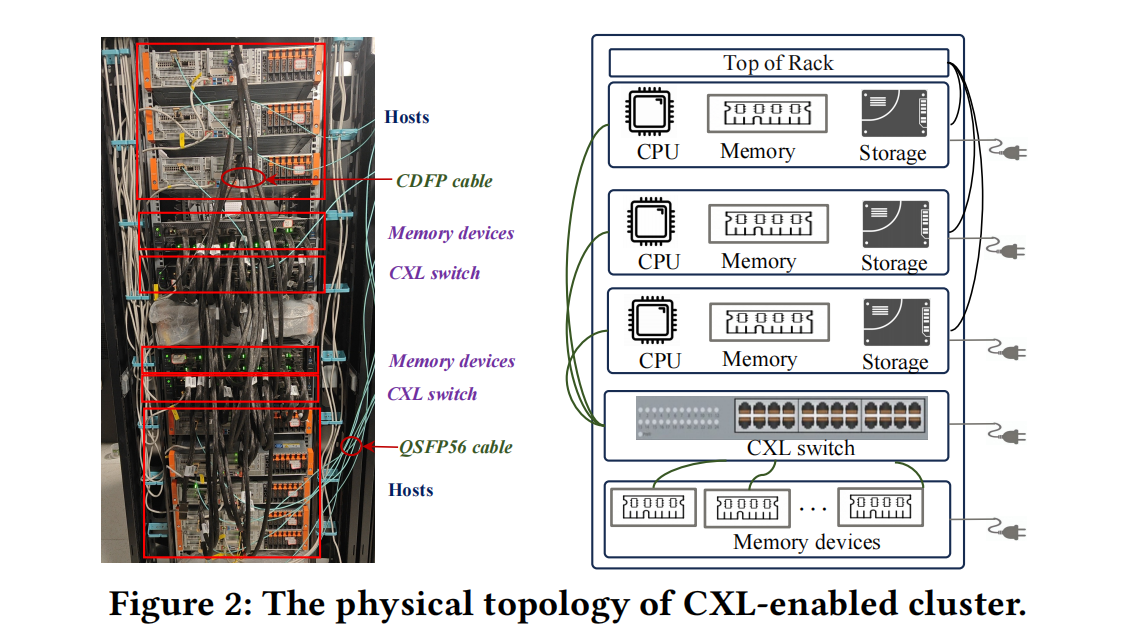
自研机架#
自研的物理原型机架。左边的机架集成了两个支持 CXL 交换机的集群,每个集群均连接至内存设备与主机;右边的机架集成了1个CXL 交换机,连接至内存设备和主机。
PolarCXLMem#
CXL 2.0 switch支持内存池但驱动没有完全支持,所以PolarCXLMem还是设计了CXL的内存分配和使用,不是完全透明的。PolarCXLMem经过一些处理,将CXL memory分成了多租户的模式,不同的主机节点分配不同的CXL内存区域。
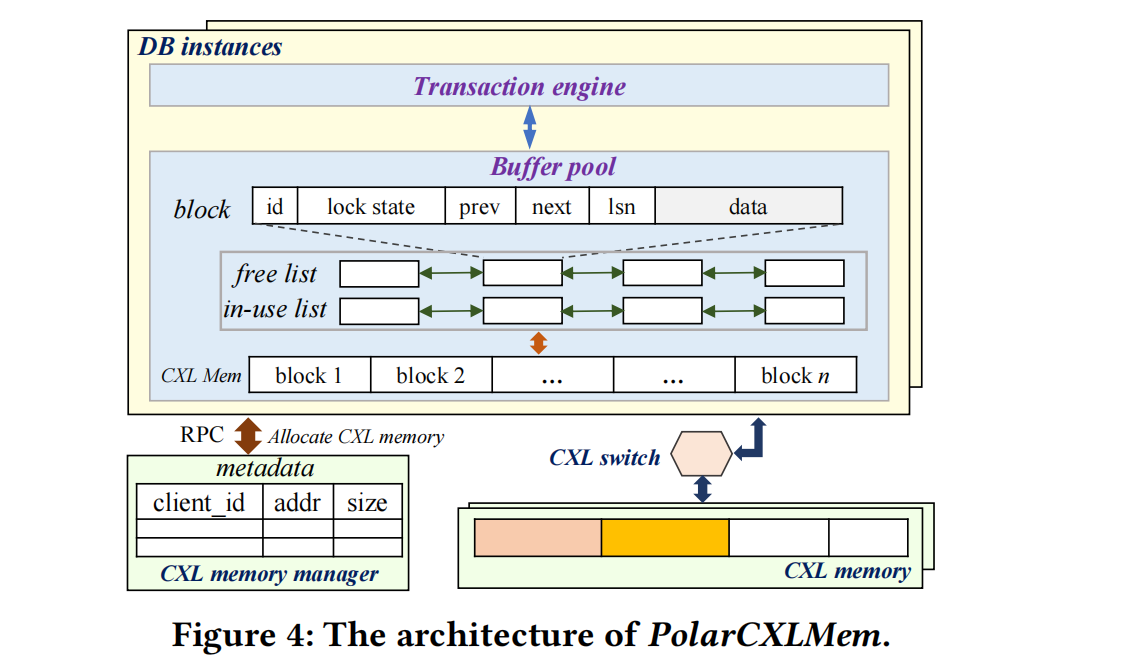
PolarCXLMem的特点:
- 节点有各自的CXL内存区域,不同的节点不会交叠CXL内存
- buffer pool仍在数据库启动后就分配(由上图中的CXL mem manager分配),运行状态不会改变内存分配区
- cxl mem中的内存单位结构是block,block会存储page的数据和page的元数据,这些元数据包括:id代表页id,lock state代表页是否有被update锁定,prev/next是LRU双链,lsn为page的最新日志序列号。
- free list/in-use list用来做LRU的
疑问:pg的pageheader有lsn、起始空闲空间指针、prune xid等等,polardb-cxl的页头又是什么结构呢?
PolarRecv#
PolarDB-MP是基于RDMA设计的,数据页在本地写入即可,分离式共享内存中没有最新版本的数据页。这导致主机crash后需要扫描和应用所有redo log文件(论文中说是redo不是wal)或一点点共享内存中的页。
而CXL switch有独立的电源,即便主机宕机,最新的数据还在CXL内存中。所以PolarRecv利用这一点来极大的提高主机宕机后数据库的恢复速度。
但是,虽然CXL switch内存透明又持久,crash后直接使用还是需要处理以下问题:
- LRU list可能在crash时是不一致的
- B-tree SMO(B-tree结构变化),例如索引分裂时,可能在crash时是不一致的
- 页在更新时crash,可能是不一致的
- redo log buffer用的本地DRAM,当redolog还没有刷盘时crash,CXL中的buffer pool中的page lsn可能大于redolog文件中的lsn,这直接违反了ARIES原则
PolarRecv设计的对应策略:
用mutex来保护LRU结构,mutex锁的状态代表LRU是否在crash时被修改,如果是的话,LRU需要重建,如果不是则直接使用CXL内存中的LRU。
B-tree SMO时会有一个mini-tranaction保护索引页,这个mini-tranaction是对应于page锁的两阶段锁。当mini-transaction提交时才会flush到redolog。所以在恢复过程中发现索引页有写锁,从redologs中恢复。
polarcxl的读写锁是放在cxl内存中的。如果写锁还在,说明crash时update在中间状态没有完成。此时老实从redolog文件中读取page而不是在cxl内存中读取不一致的page。
recovering过程中,首先会拿到redolog中最大LSN,然后检查CXL内存中page的锁和LSN,如果cxl内存中page的LSN大于最大LSN,那就用redolog中的信息去重建page而不是用CXL内存中版本。
内存融合#
因为PolarCXLMem是基于CXL 2.0 switch设计的,CXL 3.0才支持内存融合,所以还是要做内存融合的设计。因为每个节点的buffer pool都是隔离式地放在PolarCXLMem中,CXL 2.0的内存融合通过对DBP的元数据管理来实现,每个buffer pool都只存页的CXL内存地址而不是页本身。
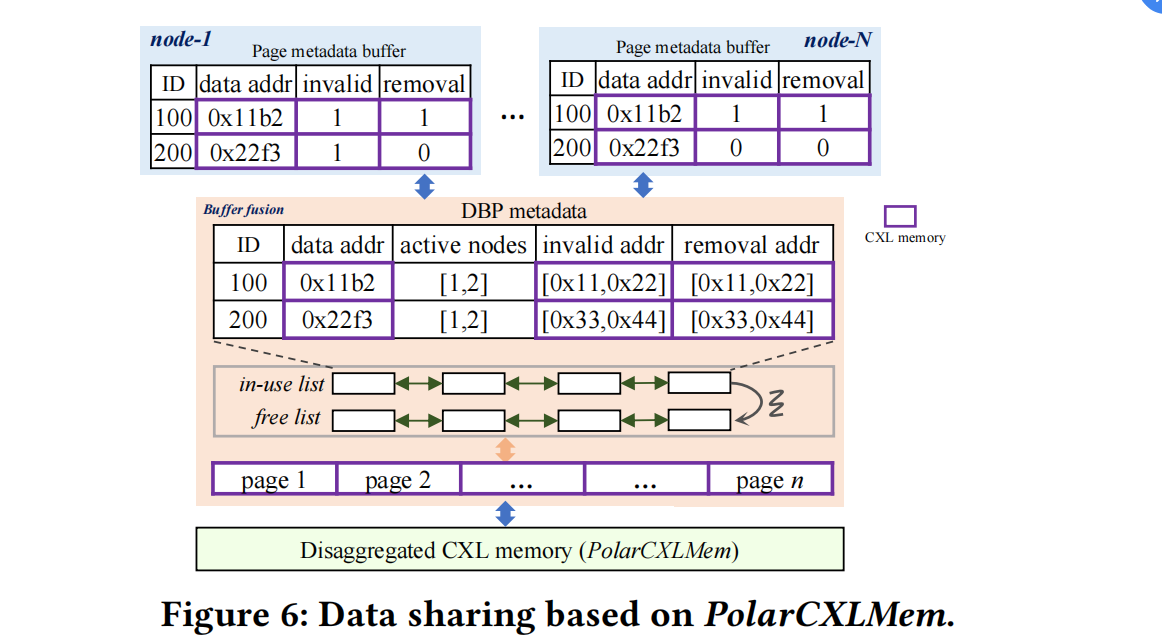
看懂上图需要注意区分CXL memory,dbp和本地buffer :
- CXL memory是物理硬件,CXL mem本身
- dbp是CXL中开辟出来的区域用于管理内存融合服务
- 本地 metadata buffer包含了本地buffer的元数据和CXL的部分
另外还需要了解,对于每个buffer pool中的page都有两个标志:
- invalid:其他节点写入页后,当前节点需要invalidate本地cpu cache
- removal:page从in-use list转移到free list,所有节点都要设置removal标志
内存融合page的访问流程:
1.请求的页不在本地page metadata buffer中,
1.1 从freelist中分配新的meta record,并通过rpc给内存融合服务提供invalid、removal地址
请求的页在本地page metadata buffer中,
2.1先检查removal flag,若removal被设置,代表内存融合服务已经回收了该page,需要通过RPC请求内存融合服务的新内存地址
2.2然后检查invalid flag,invalid flag被设置,代表页被其他节点修改,需要invalidate cpu cache以确保一致性
融合一致性:
因为CXL 2.0没有内存融合,cpu cache不会被自动更新。polarcxl通过页级锁来实现多节点并发写入控制。
节点读写page需要拿到读写锁。当一个节点正在写入page时,其他节点不能获得读写该page。当节点写完后,还需要
- 当前节点将cpu cache lflush到CXL mem中,以确保CXL mem是最新版本的page
- 设置invalid flag,以确保其他节点不去读其cpu cache的老版本page
内存融合小节:
CXL 2.0本身支持不太完整的内存融合,导致数据库层还是需要设计内存融合方案。内存页通过CXL地址访问,而不是像RDMA方案一样本地/远程访问整个page。本地CPU cache需要数据库层来刷新以确保节点访问数据的一致性,这是硬性限制。这也导致了跨节点更新仍然是排他页级锁(RDMA方案也是排他页级锁)。
性能评估#
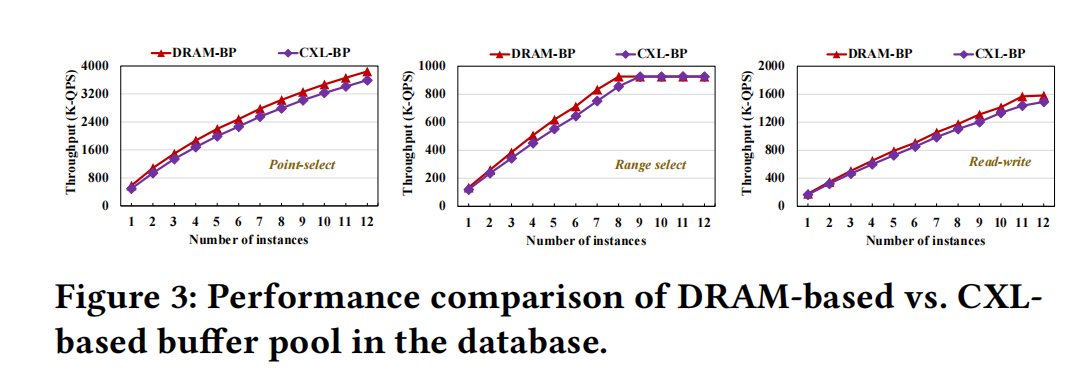
多节点读写#
一个192 vC的主机上放12个实例进行的压测,对比RDMA(PolarDB-MP)和CXL(PolarDB-MP with PolarCXLMem)的性能:
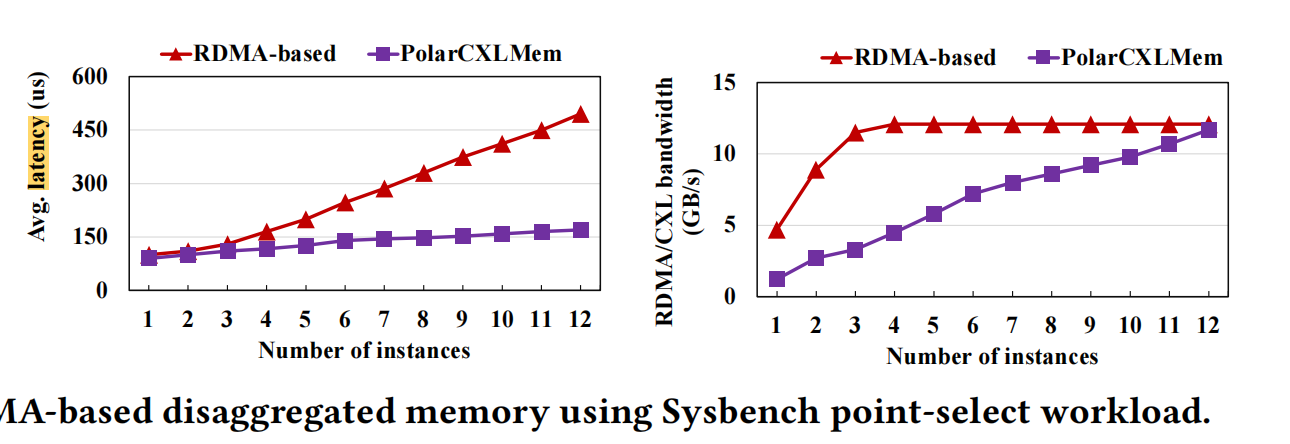
点查:
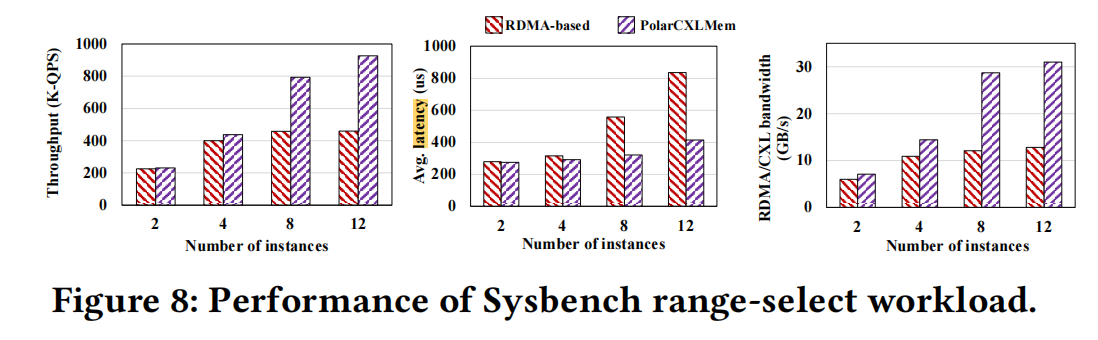
范围查询:
读写:
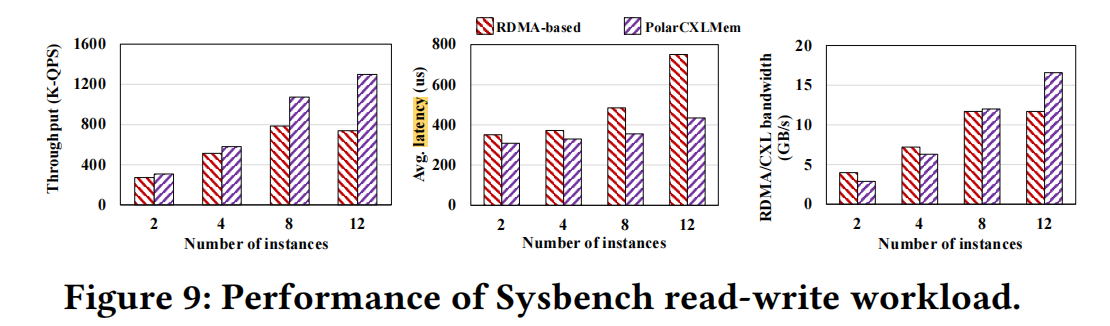
- 点查:点查的读放大问题最严重,CXL的带宽消耗比RDMA小3-4倍。当节点达到3个时,RDMA的带宽已经被占满,再增加节点不会有任何带宽上的提升。
- 范围查询:范围查询的读放大问题没有那么严重,只是在节点大于4时达到带宽上限11GB/s,而CXL还可以随节点线性增长。
- 读写:表现与范围查询类似,只是差异再小一点
PolarRecv恢复时效#
- vanilla指一般方案,应该是指类似pg从本地cache或disk中读取(也有可能是polar redo)
- RDMA-based指polardb-mp有些数据可以从分离式共享存储中读取
- PolarRecv指从大部分数据从CXL中继续读,少部分patial page需要从redo文件中恢复
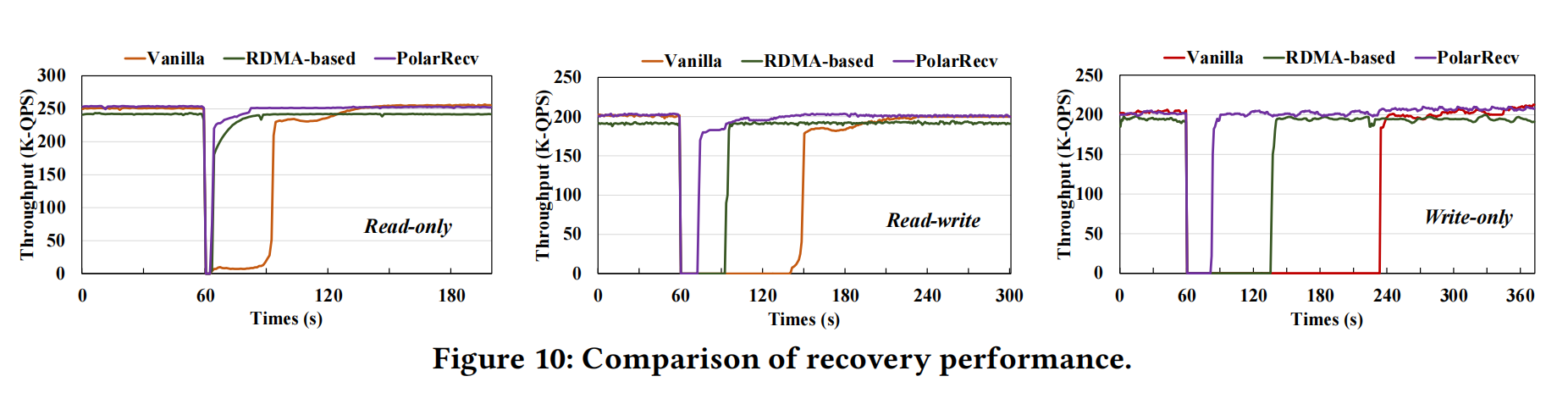
论文中论述恢复时效其实分为2个阶段:起库/recovery和负载达到crash前的水平。只读不需要recovery,只要有数据就能起库承接负载。当有写入时,就需要做恢复,此时继续从CXL内存读数的优势就体现出来了。1分钟、2分钟、4分钟的恢复时效,还是有差距的,差距可能就是业务几乎无感和有感的区别。
共享数据更新#
分布式数据库性能PK的焦点就是对共享数据的更新。在Polardb-mp性能暴打taurus-mm后,Polardb-cxl也暴打了Polardb-mp:
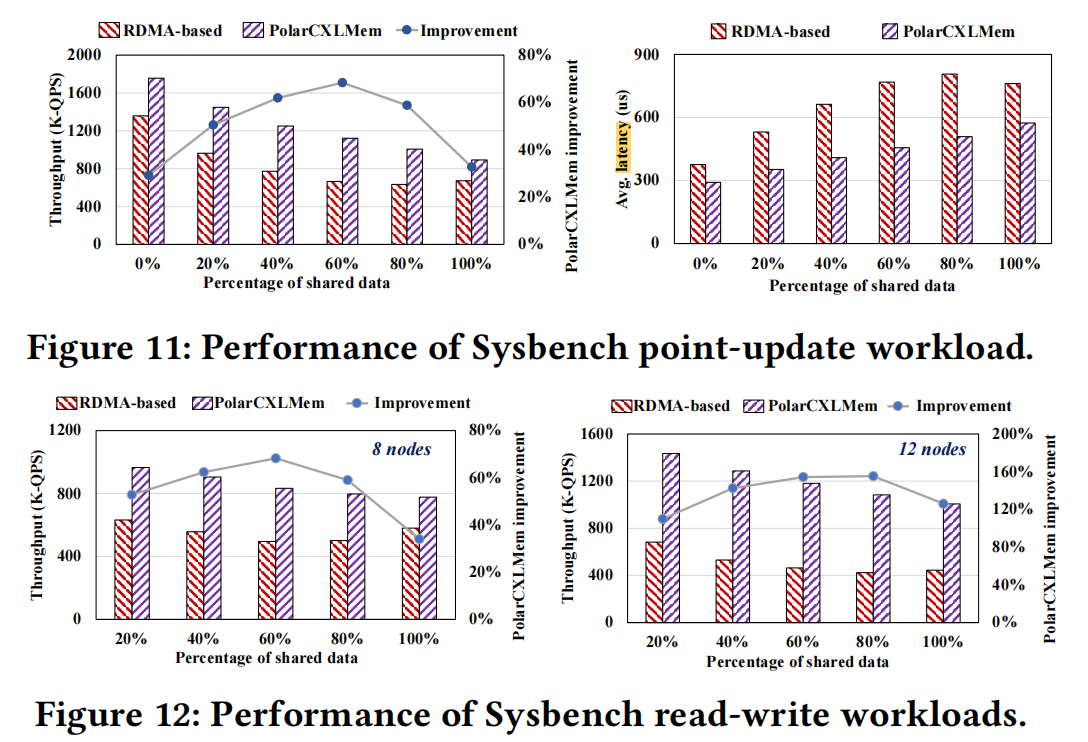
0%的 shared data的情况下,RDMA-based就访问local buffer就行了,Polardb-CXL只是把CXL当成内存池使用。即便如此,CXL-based还是性能更好,主要是之前说的,RDMA-based方案有读写放大和带宽上限问题。
从上的性对比图可以看出来Polardb-CXL明显好于Polardb-MP,数据是非常清晰的。但是要注意,当shared data>60%时,Polardb-CXL性能提升不明显了,主要原因如下:
- 页级锁成为瓶颈
- 随着锁竞争加剧,进程会进入sleep状态,频繁的上下文切换也加剧了资源争用
总结#
PolarDB-CXL优点:
消灭了RDMA的“本地-远程”层级内结构设计
解决了RDMA的读写放大问题
提供基于CXL的内存池
PolarRecv基于CXL持久内存,数据库崩溃恢复速度更快
压测显示polardb-mp cxl性能优于polardb-MP RDMA
PolarDB-CXL缺点:
- 跨节点更新仍然是页级锁,在共享数据更新的场景下,仍是性能瓶颈的主因
- CXL 2.0 switch看起来有点老了,在论文发表的时候已经有支持3.2的交换设备了,在2025年11月也发布CXL 4.0标准。可以预测未来应该有基于更新CXL标准的交换设备的数据库出现。
- 论文质量其实没有MP这篇高,主要是围绕CXL 2.0 switch物理硬件做的解决方案,跟PoalrDB-MP论文中有大量的数据库层面的设计还是有区别的