论文:PolarDB-MP: A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory
SIGMOD best paper:https://sigmod.org/sigmod-awards/sigmod-best-paper-award/
前言和摘要#
开篇提出问题:主从库的写入吞吐受主库限制。shared-nothing架构是可扩展的多主集群,可以解决单主受限问题,但是该架构因分布式事务的开销而出现性能瓶颈。最近基于共享存储的云原生多主数据库出现,但该架构在高冲突场景下,有冲突解决代价高和数据融合效率低的问题。
所以,提出的问题的是:单主主从架构、shared-nothing架构、共享存储云原生多主架构,都有各自的问题。
本篇论文提议PolarDB-MP,它是结合了分离式共享内存与共享存储的新型多主云原生数据库。(an innovative multi-primary cloud-native database ,多主云原生数据库已经有了,所以得是新型)。
PolarDB-MP的基本特点:
所有节点都能平等访问全部数据,从而使事务能够在单个节点上独立处理,无需使用传统的分布式事务机制。
共享存储:PolarStore and PolarFS,或者其他兼容性共享存储方案
构建在分离式共享内存之上
通过RDMA远程直接内存访问实现低延迟通信
LLSN(局部逻辑序列号,Local Logical Sequence Number)。用于为不同节点生成的预写日志建立部分有序关系(partial order)**,**并配合定制化恢复策略,确保系统在异常恢复时的一致性与高效性。
核心组件PMFS(Polar Multi-Primary Fusion Server多主融合服务器)负责:
- Transaction Fusion(事务融合)——负责事务排序与可见性管理
- Buffer Fusion(缓冲区融合) —— 提供分布式共享缓冲机制
- Lock Fusion(锁融合)—— 用于跨节点并发控制
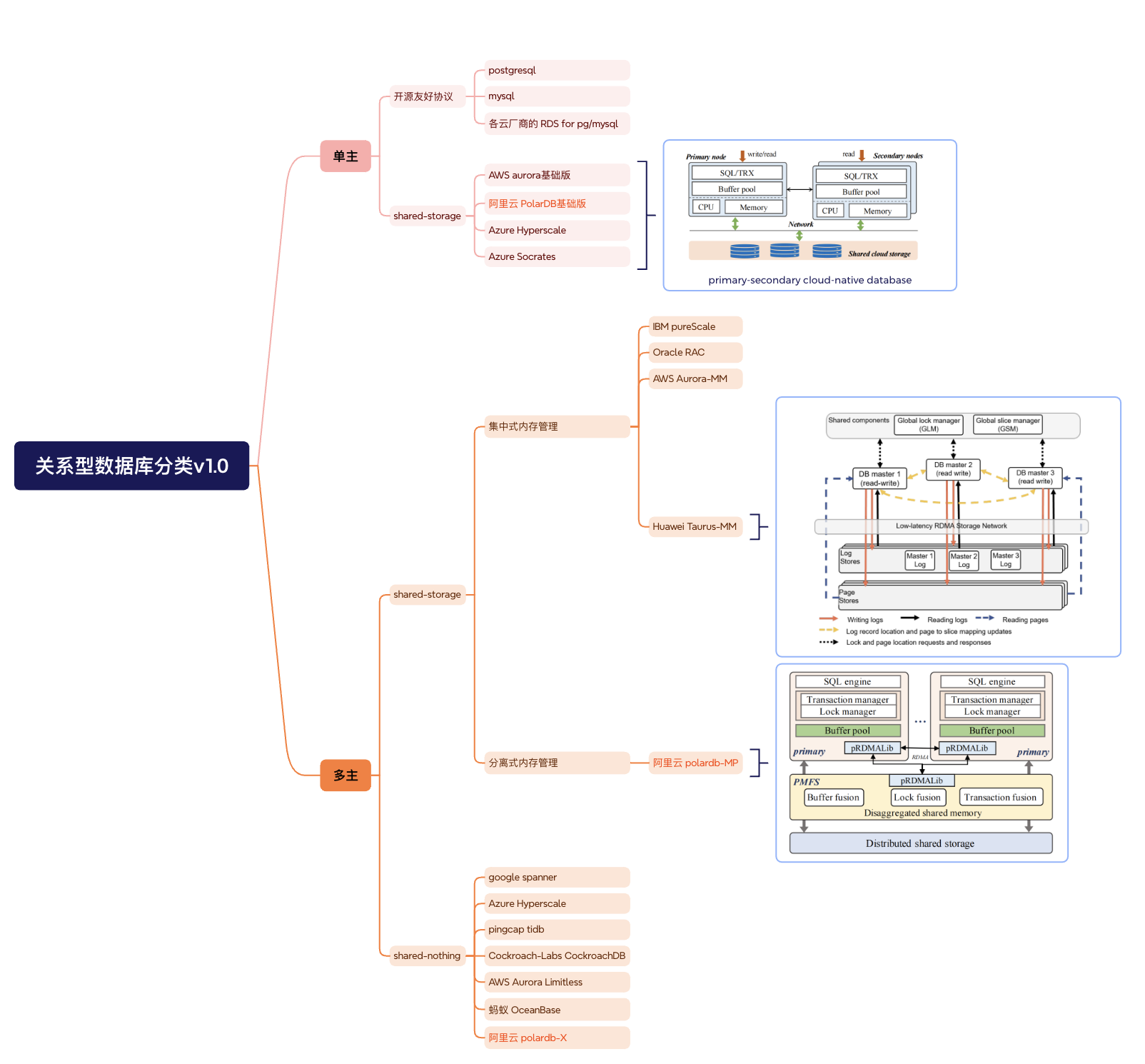
分类#
分类主要是为了看清polardb-mp的历史位置,也是为了理解”第一的定语“:
PolarDB-MP is the first multi-primary cloud-native database that utilizes disaggregated shared memory and shared storage for transaction coordination and buffer fusion
竞品黑点#
shared-nothing产品:对于这类产品没有一个个提黑点,只是一句话带过:事务在跨多分区访问时,分布式事物需要显著的额外开销。
oracle:
- 昂贵的分布式锁管理
- 昂贵的网络开销
- 比较依赖精致的机器(alien tech)
- 难以上云,或者上云后比云原生数据库的TCO成本(包含维护、人力成本)更高
AWS Aurora-MM:
- 采用乐观事物模型,事务冲突时有较高的事物中止率
- 某些场景下,4节点吞吐低于单节点
华为 Taurus-MM:
- 悲观事物模型。依赖页存储和日志重放来保证缓存一致性,在并发控制和数据同步方面存在较高的开销。
- 50% shared data 读写场景下,8节点只有1.5倍的单节点性能提升
oracle这里的黑点主要是看着有道理的口嗨,Aurora-MM和Taurus-MM是有原厂商引述的:
Aurora-MM “某些场景下,4节点吞吐低于单节点”
Taurus-MM “50% shared data 读写场景下,8节点只有1.5倍的单节点性能提升”
事务融合#
事务融合概述#
多主如何保证一致性数据视图?
快照隔离是常见的MVCC实现方式。快照隔离有一个特性是,查询或者事务必须在执行期间保持自己的一致性数据视图(consistent data view)。但是在多主架构中,因为远端的数据更新,本地无法保证一致性数据视图。
为了解决这个问题,一般的多主共享存储架构,会引入全局事务的机制(AuroraMM or Taurus-MM)。而在PolarDB-MP中提出了创新技术–PMFS中的事务融合技术。每个节点只维护本地事务信息,通过RDMA被其他节点访问。与全局事务相反,事务融合是去中心化的。
本地事物和TIT表#
polardb-mp的每个节点都会有一小部分内存来存储本地的事务信息(可以被其他节点通过RDMA访问)。这些本地事务信息存储在transaction Information Table (TIT)中。
TIT表的内容:
- 事务对象指针
- 由全局时间戳协调器(TSO)分配的事务提交时间戳CTS(commit timestamp)
- version,代表同一slot中的不同事务(事务对象指针不是指向一个事务???)
- ref,标识这个事物是否被其他事物等待释放锁(应该是Plock或者Rlock)
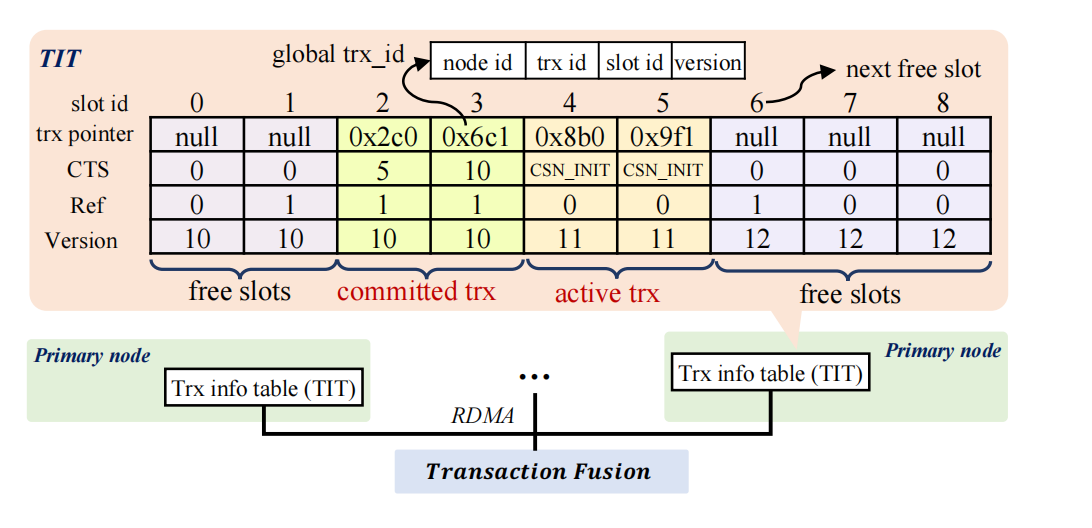
事务是如何进行的#
当事务开始时,本地事务id(应该就是txid了)会被分配,TIT slot会存放这个事务对象指针、ref初始化为0、CTS初始化为CSN_INIT。
Polardb-mp用全局事务ID标识一个事务,全局事务ID=(node_id, trx_id, slot_id, version)。全局事务ID是不包含CTS的,如果要知道事务的提交顺序,比如构建事务可见性视图时,就需要通过全局事物ID,经过RDMA,去目标节点找到CTS(类似pg中的pg_xact_commit_timestamp()函数通过事务id从本地文件找到对应的事务提交时间)。
如果trx_id是pg中事务ID的话,那么node_id,trx_id就可以标识事务的全局唯一性了,或者node_id,slot_id,version在某种程度上也可以(未复用slot id的情况下,比如某个时刻可以标识唯一事物id),当然多出来的信息组合起来也唯一。毕竟这些信息是polardb-mp实现事务融合的关键。
每个事务都会通过全局事务ID和CTS来构造可见性视图。可见性视图的概念跟pg是一致的,当前read view可读read view前已提交事务的数据行,且为最新版本行。
访问远端的CTS#
因为CTS在本地(TIT or本地文件系统上)的缘故,所以获得读取事务的CTS是一个有意思活:

1.1 如果一个行的CTS是CSN_INIT/CTS_INIT,即事务仍然活跃,那么返回最大CTS表示其对所有事务不可见,除了自己。
1.如果一个行的CTS不是CSN_INIT/CTS_INIT,即事务已提交,且在本地的TIT中,那么直接返回CTS
2.如果一个行没有CTS,通过行的g_trx_id获取CTS
2.1 如果事务属于本地节点( g_trx_id有node id),那么从本地文件系统读到本地TIT
2.2 如果事务不属于本地节点,那么从远端文件系统读到远端TIT,通过RDMA去访问
3.1 如果slot.version != g_trx_id.version,那么事务一定提交了,那么该行一定被所有事务可见(准确来说应该是一定被当前及以后的read view可见,但是理论上TIT slot不会把活动事务访问的row给刷下去,所以是所有事务可见),返回最小CTS表示其对所有事务可见
3.2 如果slot.version = g_trx_id.version,参考1.1、1.2
polardb-mp的事务可见性理念跟pg很相似,只是pg用的是txid而不是CTS表示事务新旧,也不需要考虑远程访问。
行更新事务#
除此之外,行更新也很像:
polardb-mp更新行的时候,除了更新数据本身,还需要:
更新行的全局事务ID(g_trx_id)(如果是行上更新,那么就改造了pg的行头)
更新行的CTS。(这里没有说是行头还是文件系统,如果类似pg,那么应该是文件系统上的
commit_ts目录上。polar未证实)
提问事务融合(没看懂的)#
g_trx_id是行的元数据,写入磁盘的。如果节点减加,需要更新数据行g_trx_id中的node_id吗?如果不需要,下次读取出来应该加载到哪个节点?
一个新行的CTS存储在本地节点A,如果一个其他节点B又更新了这个行,新的CTS在A还是B节点?
assigned a read view, which consists of its own g_trx_id and the current CTS。只读事务在构建读视图时,也会分配g_trx_id吗?
毫无疑问,类似track_commit_timestamp参数一定是强制打开的
如果有大量的写在A节点,读在B节点,B节点的读会通过RDMA访问A节点的TIT对应的数据,是不是会产生大量的网络IO?那么是不是需要在考虑读写分离时,或者多节点写入和读取时,应该考虑这个问题?不知道原文能不能回答这个问题–“多主架构天生就需要在节点间同步大量的数据和消息,以支撑关联多节点的并发访问。随着网络技术的发展(InfiniBand,RDMA)和商业化落地,网络瓶颈变得不那么重要。”
全局时间戳可能成为分布式系统的瓶颈,PolarDB-SCC是基于共享存储的时间戳,看上去性能不错。时间有限,先按下再说。
内存融合#
内存融合引述#
polardb-mp的每个节点都可以更新任何数据页,这会导致大量的数据转移。Buffer Fusion’s distributed buffer pool (DBP)就是为了解决这个问题。每个节点都有本地内存池LBP,属于DBP的子集。
内存融合是如何进行的#
LBP有两个新的东西用以存放页的元数据:
- valid:是否被其他节点更新
- r_addr:指针,指向DBP上的page
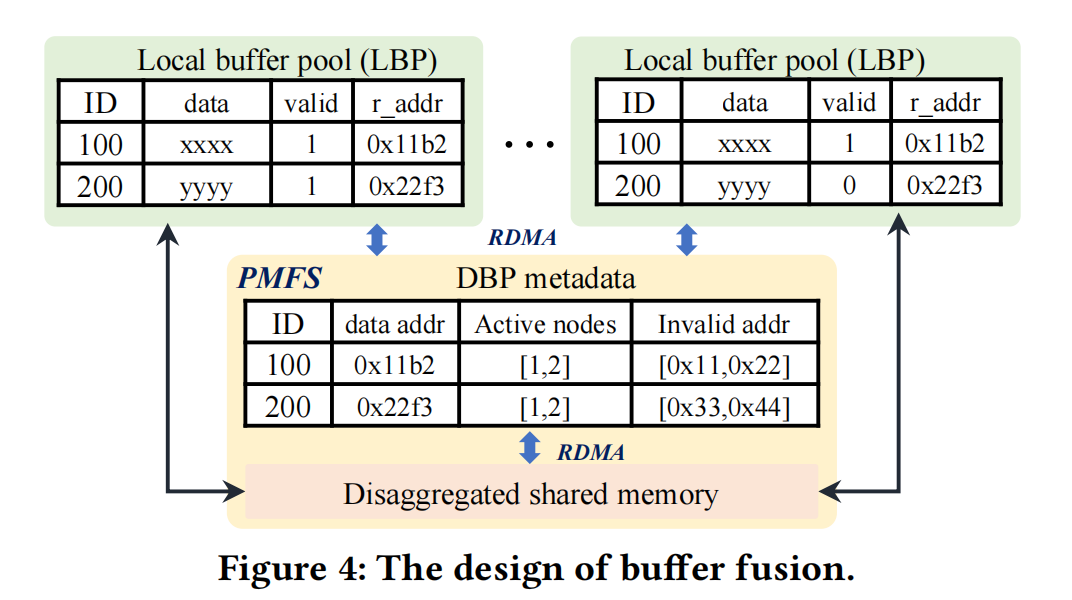
从LBP访问page时,当前节点需要先检查page是否是有效的,如果无效,需要通过r_addr去访问dbp。当dbp中存放page的新的版本后,内存融合会让所有远端的page失效。在LBP中,脏page会在后台周期性地或释放Plock锁后刷到DBP中。
page访问的步骤:
1.1 如果page在LBP且valid,直接访问。
1.2 如果page在LBP且invalid,经过RDMA访问DBP
2 如果page既不在LBP也不在DBP,从共享存储读取
3 page从一个node加载到LBP,并注册到DBP中
PolarDB内存融合的关键组件是分离式共享内存。看上去是一个/组物理硬件或者其上集成后的完整组件,游离于计算节点之外。这部分跟传统分布式系统的内存有很大的不同。
跟事务融合也有不同,事务融合需要访问相同架构的远端节点,内存融合不需要访问相同架构的远端节点,而是单独访问分离式共享存储这个组件。
提问内存融合(没看懂的)#
分离式共享内存像游离于标准主机之外的组件,所以它到底是个什么玩意儿?
锁融合#
锁融合中锁的类型#
内存融合是为了解决节点怎么访问远端数据,锁融合是为了解决并发访问控制。
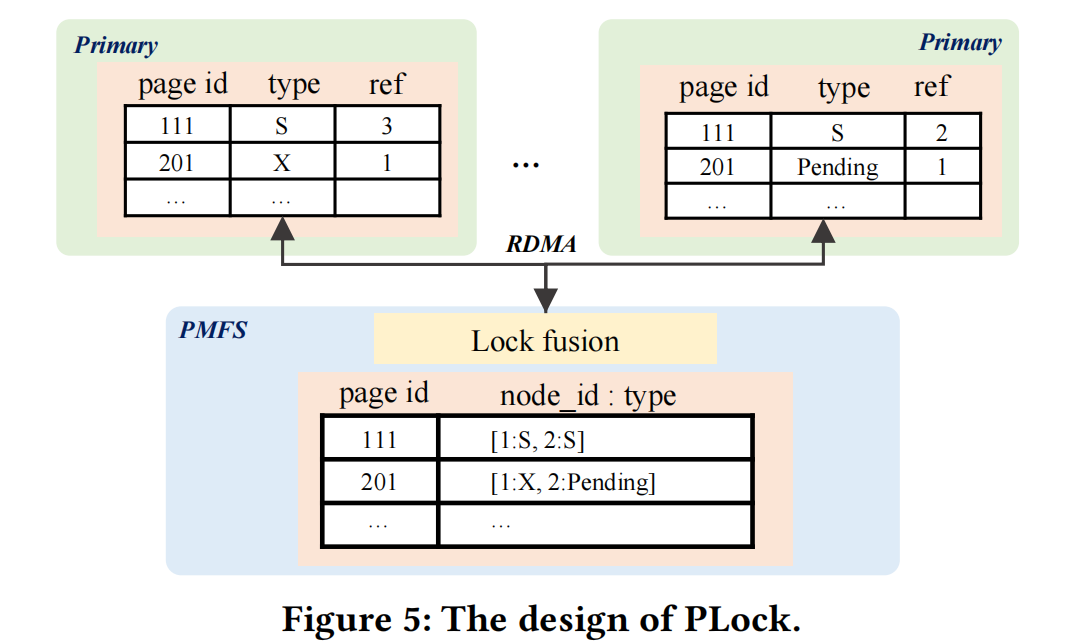
内存融合有两种锁:
- page-locking (PLock):类似latch,控制原子访问和内部结构一致性。单节点page访问没有Plock。
- row-locking (RLock):负责跨节点的事务控制,遵循两阶段锁协议
PLock访问流程#
(论文没有说锁融合发生在哪,因为Plock是页上的栓锁,页的融合发生在共享内存上,所以我先假设锁融合也发生在共享内存上,因为这样容易理解一点)
1 在更新/读取page前,通过本地锁管理器检查本地节点是已持有对应的X/S Plock(或更高级别的锁)
1.1如果有,原地执行操作
1.2 如果没有,通过Lock fusion拿到PLock
2 锁融合在响应前先检查冲突,如果冲突存在则请求等待
3 当PLock被一个节点释放,会通知锁融合,锁融合更新Plock的状态,并通知其他节点继续执行自己的操作
Plock lazy releasing#
根据上面PLock访问流程,一个Plock在本地执行完操作后会被立即释放。这可能不是最优解,根据时间局部性原理——“一个数据或指令在某一时刻被访问,那么在短期内,它很可能会被再次访问”。lazy releasing就是为了最小化Plock锁的RPC访问负载。
原理很简单,Plock在本地节点使用后不会被立即释放,而是等ref为0时才释放。
当其他节点需要PLock时,锁融合还会发送谈判信息干预本地节点一直持有锁,本地必须与锁融合通信而不是自主处理PLock。锁融合采用“先进先出”的策略解决跨节点锁归属权问题,同样直到本地节点的ref=0时,其他节点才可以拿到锁。
lazy releasing是有效的分布式锁解决方案,为了平衡本地锁优化和全局锁分配。
RLock概述#
RLock是通过全局事务ID来判断的(跟pg类似)。根据事务融合的内容,全局事务ID包含了节点id、事务id、slot id、version。所以,本地节点读取行时直接就可以拿到行上所需要的锁信息,知道锁在哪(node id),知道锁是否活跃。
判断事务活跃也有2个好玩的点:
- 从事务融合访问远端的CTS的流程来看,事物的CTS是有效值或事物在TIT中属于同一slot但不是同一version,说明事物肯定提交了,所以不需要再检查是否活跃。源事务不活跃当然就不等待锁,直接运行。
- pg中会有最小活跃事物ID的概念,在polardb-mp中也存在。如果行上的事务ID小于全局的最小活跃事务ID,那么源事务肯定也提交(或回滚)了。
Rlock是如何进行的#
本地行本地处理即可,只有冲突的时候会在锁融合中处理,跨节点行锁才需要RLock。”The transaction ID in the row functions as a lock indicator. So this protocol only supports exclusive (X) lock. The shared (S) lock on a row is not supported in PolarDB-MP, but it’s acceptable“ ,真冲突的排他锁才需要RLock,共享锁不需要RLock。
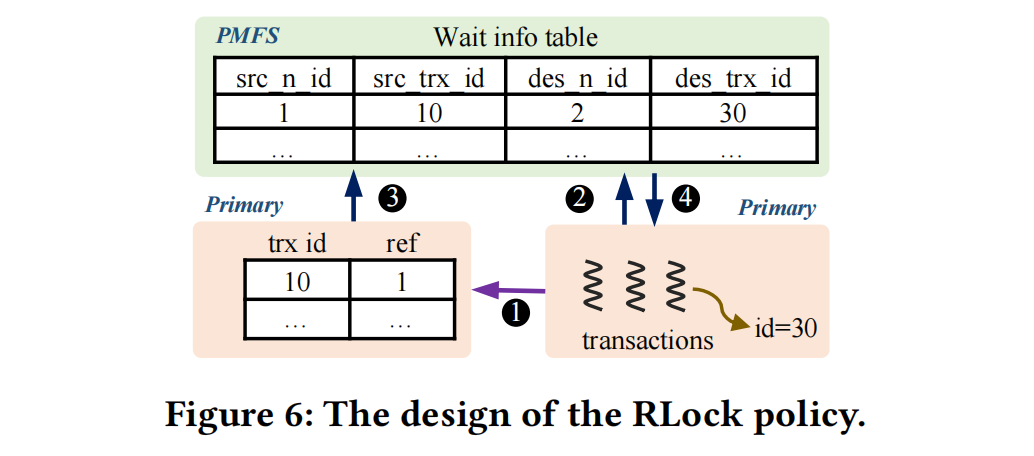
1 T30从共享存储中读取行,从行的元数据(g_trx_id)就可以知道事物活跃且事务在哪个节点
2 T30远程调整T10的事物ref
3 T30发送等待状态给锁融合服务
4 锁融合添加等待信息到wait info table中
5 T10执行结束,通知Lock Fusion
6 Lock Fusion检查wait info table,然后通知T30可以继续执行了
提问锁融合(没看懂的)#
“when attempting to update a row, it must already hold an X PLock lock on the page containing the row”
update还要持有page的PLock排他锁,也就是说同一page上的update是相互阻塞的,这会影响并发吧?本地应该不会有这种行为,pg是没有update场景的page排他的。
在Logs ordering and recovery章节有这么两句话:“Thanks to the PLock design, only one transaction can update a page at a time",“When a page is updated across two nodes, one node pushes its updated page to the DBP before releasing the PLock,allowing the next node to retrieve it from the DBP.”
是的,在跨节点数据更新时,有页级排他锁。
PMFS小结(锐评)#
PMFS(Polar Multi-Primary Fusion Server)是PolarDB-MP多主分布式系统实现的核心组件。其中,全局事务ID设计巧妙,它转化了pg的事务ID为包含节点信息、事务id和事务融合中的slot和version信息并放在行头。这样做有几个好处:
- 直接访问行就知道行的版本新旧情况
- 直接访问行就知道行是哪个节点更新的
- 直接访问行就知道是否可能存在跨节点锁
- 利用最小活动事务以减少冲突判断
- 利用全局事务ID信息,实现分布式获取事务提交时间CTS
另外
- PMFS中的内存融合和锁融合看上去高度依赖共享内存组件
- RDMA的应用时刻存在
日志的顺序#
partial order#
首先,wal在每个节点上都生成,且不需要任何并发控制机制,各自往共享存储中写。每个节点的LSN对于各自的节点而言是顺序的,但是多节点就不能体现wal记录在全局的顺序性。
但是,需要在写入时体现wal记录的全局顺序吗?
从论文来看,大部分情况是不需要的。
只有1种情况需要保证写入时的全局顺序性,那就是跨节点更新同一个page时。
但是,根据PMFS锁融合机制,跨节点更新同一page是排他的。锁融合就可以保证跨节点page更新的顺序了。
恢复的顺序#
由于跨节点写入的LLSN来自多个节点很可能不是顺序的,恢复时就需要按顺序进行恢复。全量读取wal记录再按LLSN排序是一个简单的方案,但是大量的排序非常消耗资源。
polardb-mp提出了分段排序LLSN,每段称为chunk,chunk的边界称为LLSN bound。polardb-mp可保证LLSN bound一定小于下一个bound,然后在chunk内排序LLSN即可。
提问日志的顺序(没看懂的)#
”utilizing redo (write-ahead) logs for data recovery and undo logs for rolling back uncommitted changes“
polardb-mp有undo日志文件?这个undo是干嘛的?
LLSN没有看出来有什么特别的,论文也没有详细说明它的结构,LSN看上去都够了,maybe全局事务id那有些区别。
评估#
只读都是本地的,所以加节点吞吐提升是线性的。如果读写/只写的数据都分区得好,不跨节点,也几乎是线性的。
问题就在于读写/只写节点间共享数据的情况,非常考验分布式数据库的性能。
论文直接拿华为的taurus-mm来对比。结论就是:polardb跨多节点写数据性能确实要好不少。
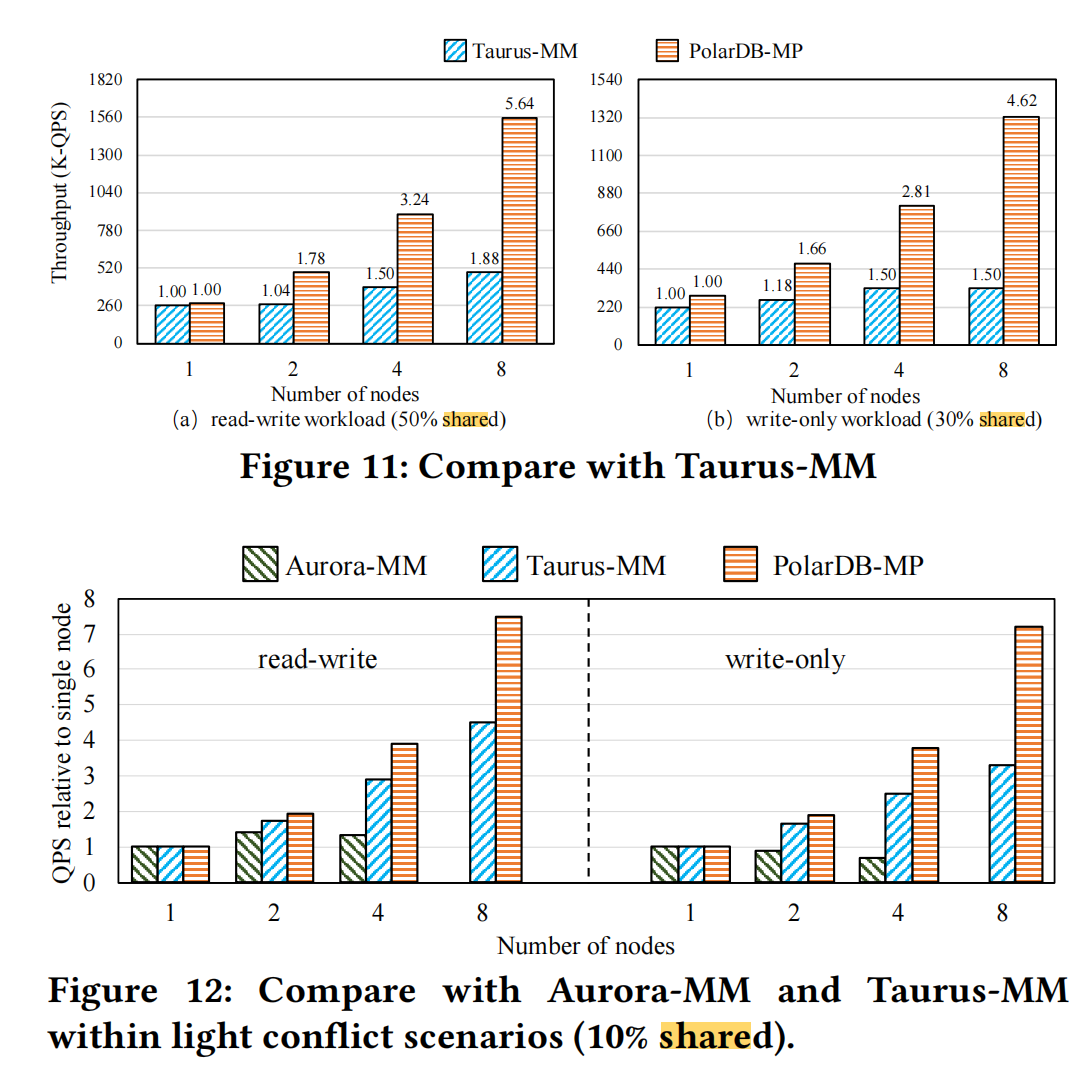
吹毛索疵#
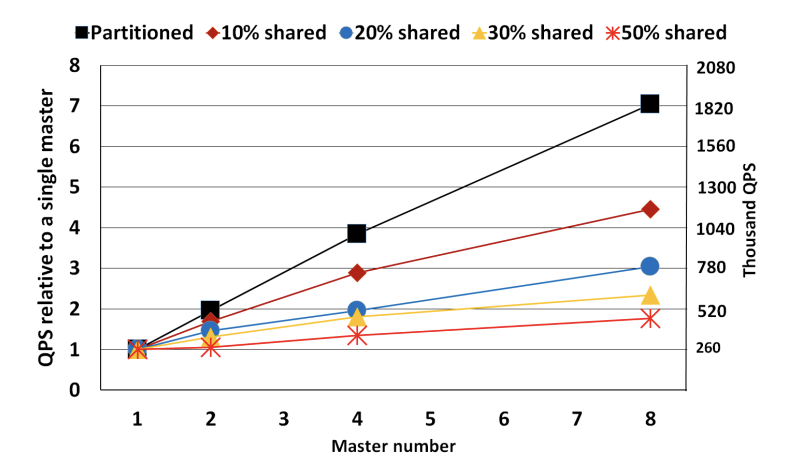
文章有2个地方提到Taurus-MM在8节点共享数据下的性能提升,但是数据有歧义:
The eight-node cluster only improves the throughput by 1.8× compared to the single-node version in the read-write workload with 50% shared data.
the throughput of Taurus-MM ’s eight-node cluster is approximately 1.8× that of a single node under the SysBench write-only workload with 30% shared data, illustrating the trade-offs and challenges in optimizing multi-primary cloud databases
一会30% shared data,一会50% shared data,不是很严谨。原文Taurus MM是50%:
总结#
好像没什么好总结的,看章节前言和摘要和PMFS小结 就行。