问题现象#
统计信息的n_distinct不准确
这个问题在多个库中出现,例如:
表有2亿行数据,真实DISTINCT有800w,统计信息中的DISTINCT只有4w。
问题分析#
采样模型#
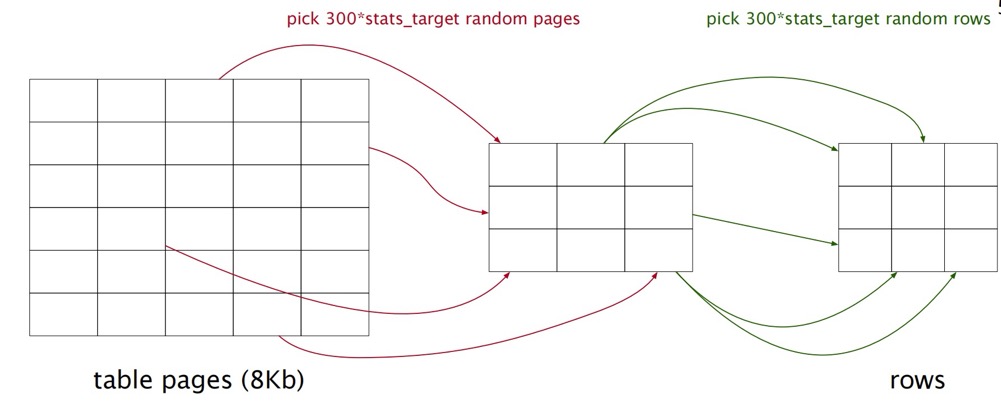
默认default_statistics_target=100,即采集30000 pages中的30000行数据。
analyze verbose tablzl1;
INFO: 00000: analyzing "public.tablzl1"
LOCATION: do_analyze_rel, analyze.c:332
INFO: 00000: "tablzl1": scanned 30000 of 22963751 pages, containing 1061942 live rows and 3953 dead rows; 30000 rows in sample, 812872389 estimated total rows
LOCATION: acquire_sample_rows, analyze.c:1340注意 “scanned 30000” 和 “30000 rows in sample”
distinct预估算法#
distinct的预估算法analyze.c:
/*----------
* Estimate the number of distinct values using the estimator
* proposed by Haas and Stokes in IBM Research Report RJ 10025:
* n*d / (n - f1 + f1*n/N)
* where f1 is the number of distinct values that occurred
* exactly once in our sample of n rows (from a total of N),
* and d is the total number of distinct values in the sample.
* This is their Duj1 estimator; the other estimators they
* recommend are considerably more complex, and are numerically
* very unstable when n is much smaller than N.
*
* In this calculation, we consider only non-nulls. We used to
* include rows with null values in the n and N counts, but that
* leads to inaccurate answers in columns with many nulls, and
* it's intuitively bogus anyway considering the desired result is
* the number of distinct non-null values.
*
* We assume (not very reliably!) that all the multiply-occurring
* values are reflected in the final track[] list, and the other
* nonnull values all appeared but once. (XXX this usually
* results in a drastic overestimate of ndistinct. Can we do
* any better?)
*----------
*/
int f1 = nonnull_cnt - summultiple;
int d = f1 + nmultiple;
double n = samplerows - null_cnt;
double N = totalrows * (1.0 - stats->stanullfrac);
double stadistinct;n*d / (n - f1 + f1*n/N)
n= 样本行数(扫描的行数)d= 样本中发现的distinct值的数量f1= 样本中只出现一次值的数量N= 表的总行数
算法论文:https://hugepdf.com/download/download-extended-version-of-this-paper_pdf
论文看起来比较费劲,下面做一些假设来理解这个disticnt算法:
1.假设全是出现一次值,且表很大n«N,即f1=d,n/N=0
d*d / (d - d + d*0)=d*2/0, 这应该是-1了.
2.假设全是出现一次值,且表很小n=N,即f1=d,n/N=1
n*d / (n - d + d*1)=d,即采集的distinct数,也等于采集的行数
3.假设采集样本中没有只出现一次值,即f1=0,
n*d / (n - f1 + f1*n/N)=n*d / (n)=n*d / (n)=d ,也就是采样中的distinct数.
如果一个列均是插入几条同样的值,然后再插入几条同样的值,比如:
11,2,2,2,2,3,3,3,..
3.1且表小,3w行采集全部采完,真实distinct=10000(假设),预估distinct=d=10000
3.2且表大,采样中有重复出现的值,也有出现一次值(因为某个重复数据只采到一条),即n=30000,n/N=0,
n*d / (n - f1 + f1*n/N)=n*d / (n - f1)=30000*d/(30000-f1),也就是采样中的distinct数越大,预估的distinct越大;采样只出现一次值数越大,预估的distinct越大
总结:
- distinct预估跟采样中的distinct数、只出现一次值数直接相关
- 如果只出现一次值数=0,那么采样越多,预估的distinct越大
验证#
由于默认采样数最大是3w行,也就是说这种采样算法只要超过3w,即表比较大的时候,预估distinct很可能偏小。注意这里的数据不能有太多唯一值。
测试一张表不同采样数的差异:
表有reltuples=8亿,relpages=2kw,size=175GB,真实的某字段distinct 1亿
| target statistics | pages采样比例(1) | tuples采样比例(1) | n_distinct | 执行时间 |
|---|---|---|---|---|
| 50 | 0.00075 | 0.00001875 | 6w | 2秒 |
| 100 | 0.0015 | 0.0000375 | 11w | 5秒 |
| 1000 | 0.015 | 0.000375 | 103w | 58秒 |
| 3000 | 0.045 | 0.001125 | 268w | 3分01秒 |
| 10000 | 0.15 | 0.00375 | 675w | 7分21秒 |
(target statistics 最大值10000)
可以粗糙的总结:n_distinct和analyze的执行时间随采样数量成倍增长。
n_distinct随采样数量增长,pages和tuples却一直都很准确。
解决#
由于表特别大,可以考虑改造分区表或根据实际SQL进行优化
还可以调整收集阈值,默认阈值default_statistics_target=100,即3w个pages中的3w条数据。
临时方案:
set default_statistics_target=3000;
analyze tab1;长期方案:
alter table tab1 alter column col1 set STATISTICS 3000;注意:
- 列的收集阈值优先级最高,大于
default_statistics_target参数 - 收集阈值最大为10000
- 表的收集阈值为最大的列阈值:
/*
* Determine how many rows we need to sample, using the worst case from
* all analyzable columns. We use a lower bound of 100 rows to avoid
* possible overflow in Vitter's algorithm. (Note: that will also be the
* target in the corner case where there are no analyzable columns.)
*/
targrows = 100;
for (i = 0; i < attr_cnt; i++)
{
if (targrows < vacattrstats[i]->minrows)
targrows = vacattrstats[i]->minrows;
}
for (ind = 0; ind < nindexes; ind++)
{
AnlIndexData *thisdata = &indexdata[ind];
for (i = 0; i < thisdata->attr_cnt; i++)
{
if (targrows < thisdata->vacattrstats[i]->minrows)
targrows = thisdata->vacattrstats[i]->minrows;
}
}如果执行analyze发现收集多了或者少了,可以看下pg_statistic是不是有设置字段stattarget
select attrelid::regclass,attname,attstattarget from pg_attribute where attrelid = 'tab1'::regclass and attstattarget not in (-1,0);总结#
对于大表,字段非唯一但distinct值比较高(符合真实场景),采样算法会低估distinct值,且跟采样比例正相关。默认的采样比例对于大表来说偏小,可以调大,但是最大也大不到哪去。