这篇文章主要是讲pg运维常见问题,两三年见一次的疑难杂症就不说了。
主要是技术性运维总结,主打通俗易懂和快速上手,尽量避免源码层面等深入分析。
SQL性能与执行计划#
执行计划突变#
pg官方不支持hint功能,并且计划永远不支持! PG社区大概是这个意思"我们的优化器是完美的,如果当前执行计划不够优秀,那是开发不懂优化”。
不管pg社区怎么看,生产环境的执行计划突变问题是时常发生的,而且我们没有ORACLE那样原生且丰富的绑定执行计划手段来处理问题。这对生产运维来说是一个挑战,例如:某天早上,一个敏感的sql突然执行计划改变了,运行时间从0.1s上涨到1s,由于SQL有一定的并发导致数据库的cpu打满,业务感知明显。由于我们没有绑定执行计划的手段,此时我们唯二能做的快速恢复手段就是1.收集统计信息 2.scale up扩容cpu。
这里的快速恢复手段有个问题是:收集统计信息一定有用吗?好的DBA可以找到优化器中的关键问题步骤在哪,但是也不能快速脑补一个完整的执行计划出来,特别是SQL比较复杂的时候。收集统计信息这个恢复手段,实际上把SQL优化问题返还给了优化器,同时相信优化器是可以胜任这个工作的。虽然这看上去有些扯,但是在PG数据库中,绝大部分情况是有用的(对于已知收集统计信息无用的场景,见"order by limit问题"小节)。
为什么执行计划会突变且性能变差?
- 执行计划是基于成本的,而成本又基于统计信息,统计信息又是永远滞后的
- SQL足够复杂的话执行路径就会有非常多种,优化器会根据成本选择最优的一条
- PG提供了很多优化器参数可以调整,目的是以适配本地硬件设置(如
seq_page_cost,effective_cache_size等等),我们可以通过调整这些参数来微调优化器的倾向。但是这些参数太底层,虽然理论上是有优化空间,但都是牵一发而动全身的。特别是数据库上线后,调整这些参数就是一个极高风险的操作。从这些参数设置的理由来看,也可以推测执行计划不可能是100%完美的,因为优化器的推理也依赖环境
即使强如oracle,提供了各种方案稳固执行计划,它也保证不了SQL 100%不会出问题,因为SQL、数据、统计信息、绑定变量等等都是动态的。 对于PGer来说还想不了那么远,不过我们可以尽可能地考虑稳定执行计划的方案,如下:
- 不要用太多的表连接。表越多可能的执行计划也就越多,甚至PG GEQO会放弃生成所有的执行计划,这就降低了最优执行计划的概率
- 不要写太过复杂的SQL。还要考虑SQL可能是框架(ORM)生成而不是业务人员手工编写的,这样的SQL一般是为了实现某个目标而几乎不考虑SQL的简洁性和阅读性,优化起来十分棘手。
- 不要乱建索引以迷惑优化器,必须有明确的目标
- 调整表的统计信息搜集阈值
autovacuum_vacuum_scale_factor(参考“统计信息收集不及时”小节) - 可以使用pg_hint_plan来提示优化器。
pg_hint_plan#
pg_hint_plan是第三方插件,通过hint来提示优化器选择正确的执行计划。 pg_hint_plan支持:
- 指定扫描方式(如索引扫描)、连接方式(NL/HASH/MERGE)、连接顺序、memoize、指定预估行数、并行、GUC参数
- 通过hint_plan.hints绑定sql的执行计划,不需要改变业务SQL文本
pg_hint_plan缺陷:
- 子查询、外部表、CTE、视图、PL/SQL等有使用限制
- compute_query_id会把hint当做注释忽略
- 未知的bug
这个插件虽然在持续更新,但是(我)还没有找到大规模生产应用的案例。另外我们在少量的生产应用场景中发现了一些问题,执行计划可能不会生效,这跟jdbc执行计划缓存有关系,至于有没有其他问题暂时不好下定论。 总之pg_hint_plan是个好东西,但是生产大规模部署有待商榷。推荐静待其变,可以试用但不要对它产生依赖性。
统计信息收集不及时#
统计信息是sql优化的基础,pg统计信息并不难但还是有很多人没弄明白。
pg的统计信息主要看这3个表:pg_class、pg_stat_all_tables、pg_stat
-- pg_class看pages和tuples
select relname,relpages,reltuples::bigint from pg_class where relname='lzlpg'\gx
-[ RECORD 1 ]------
relname | lzlpg
relpages | 187501
reltuples | 6000032
--pg_stat_all_tables看活元组、死元组,上次统计信息收集时间
select relname,n_live_tup,n_dead_tup,last_analyze,last_autoanalyze from pg_stat_all_tables where relname='lzlpg'\gx
-[ RECORD 1 ]----+------------------------------
relname | lzlpg
n_live_tup | 6000032
n_dead_tup | 0
last_analyze | 2025-01-04 15:54:44.553057+08
last_autoanalyze | [null]
--pg_stats看列的统计信息,每个字段都需要了解含义
select * from pg_stats where tablename='lzlpg' and attname='a'\gx
-[ RECORD 1 ]----------+-------
schemaname | public
tablename | lzlpg
attname | a
inherited | f
null_frac | 0
avg_width | 70
n_distinct | -1
most_common_vals | [null]
most_common_freqs | [null]
histogram_bounds | [null]
correlation | [null]
most_common_elems | [null]
most_common_elem_freqs | [null]
elem_count_histogram | [null]统计信息过久很有可能会造成SQL执行计划改变,引起SQL性能问题。
此时就需要查看pg_stat_all_tables表的last_autovacuum,last_autoanalyze时间来判断表的收集是不是滞后了。
为什么要调整?因为表的统计信息收集阈值autovacuum_analyze_scale_factor 默认值是0.1,也就是数据变化达到10%时,才会收集统计信息。例如一个10亿数据的表,数据变化达到1亿时才会收集,频率可能太低了。
应该结合是否核心业务表、SQL表连接个数、SQL复杂度、表访问频率、月初越界问题、数据倾斜问题等判断是否需要针对性的调整表的autovacuum_vacuum_scale_factor,autovacuum_analyze_scale_factor以提高统计信息收集频率,降低SQL执行计划突变的概率,同时也要避免收集过于频繁老是跑vacuum浪费资源。
到底该调整到多少?举个例子:
以月表(或月分区表)及SQL统计当天数据为例,由于autovacuum_analyze_scale_factor =0.1,月表在前10天基本每天都会收集,在第12天左右的时候可能不会收集,这时候统计信息可能越界,执行计划就有可能有问题。为了保证月表在每月的10-31天都收集统计信息,应该把autovacuum_analyze_scale_factor设置得小于0.03,所以推荐autovacuum_analyze_scale_factor=0.02
参数调整参考(请考虑表上的业务数据模型!):
| 参数名 | 默认值 | 建议值 |
|---|---|---|
autovacuum_vacuum_scale_factor | 0.2 | 0.04 |
autovacuum_analyze_scale_factor | 0.1 | 0.02 |
优化器可能选择其他索引而不是主键#
一般来说主键的过滤性已经是最高了,但是优化器可能也不会选择走主键
--复现命令
create table t1(a char(1000) primary key,b char(1000));
insert into t1 select md5(g::text),md5(g::text) from generate_series(1,10000) g;
create index idxa on t1(a);
create index idxb on t1(b);
analyze t1;
explain (analyze,buffers) select * from t1 where a='qwer' and b='qwer';
explain (analyze,buffers) select * from t1 where a='qwer' and b||''='qwer';--a、b字段有同样的过滤性,但是优化器没有走主键而是走普通索引
explain (analyze,buffers) select * from t1 where a='qwer' and b='qwer';
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Index Scan using idxb on t1 (cost=0.41..5.43 rows=1 width=2008) (actual time=0.045..0.046 rows=0 loops=1)
Index Cond: (b = 'qwer'::bpchar)
Filter: (a = 'qwer'::bpchar)
Buffers: shared hit=3
--强行走主键,cost只多一丢丢丢
explain (analyze,buffers) select * from t1 where a='qwer' and b||''='qwer';
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Index Scan using idxa on t1 (cost=0.41..5.44 rows=1 width=2008) (actual time=0.079..0.079 rows=0 loops=1)
Index Cond: (a = 'qwer'::bpchar)`
Filter: (((b)::text || ''::text) = 'qwer'::text)
Buffers: shared read=3虽然a、b两个字段类型和选择率是一样的,但是优化器没有选择走主键而是走了普通索引,从cost来看走主键的cost多了0.01。
这有什么问题?
从当前这个表数据分布来看选择普通索引问题不大,但是数据一旦变化,两个索引的执行计划效率就会有差别:
alter table t1 set (autovacuum_enabled ='off');
insert into t1 select md5(g::text),'repeat' from generate_series(20001,30000) g;--b='repeat'过滤性很差,但是还是走b字段索引
explain (analyze,buffers) select * from t1 where a='qwer' and b='repeat';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Index Scan using idxb on t1 (cost=0.41..5.43 rows=1 width=2008) (actual time=15.823..15.824 rows=0 loops=1)
Index Cond: (b = 'repeat'::bpchar)
Filter: (a = 'qwer'::bpchar)
Rows Removed by Filter: 10000
Buffers: shared hit=2511
--对比走主键的执行计划
explain (analyze,buffers) select * from t1 where a='qwer' and b||''='repeat';
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Index Scan using idxa on t1 (cost=0.41..5.44 rows=1 width=2008) (actual time=0.041..0.041 rows=0 loops=1)
Index Cond: (a = 'qwer'::bpchar)
Filter: (((b)::text || ''::text) = 'repeat'::text)
Buffers: shared hit=3即使真实的过滤性不好,优化器仍然选择走普通索引,但是走普通索引的效率要低很多,因为shared hit=2511远大于shared hit=3。如果是敏感业务sql或者数据量比较大的时候,就会有问题,这个问题在生产中也常见。 解决办法:
- 手动收集统计信息;调高统计信息收集频率
- pg_hint_plan
- 改写sql让其不能走普通索引
order by limit问题#
order by limit的sql已是一个常见的问题了,网上案例和分析也比较多,这里就不详细分析了(可以参考我写这篇ORDER BY limit 10比ORDER BY limit 100更慢)。 根本原因在于优化器目前无法评估数据以索引顺序存放在表的哪个位置,可能数据靠后而导致扫描过多的数据才返回limit。注意这个场景不是仅出现在order by limit,任何可以用到排序操作的+limit都可能有这个问题,如:group by +limit、distinct +limit、merge..
解决办法:
- SQL改造:添加表达式防止走到排序列的索引上(含主键),如
order by ''||col1 limit xxx - 创建复合索引:创建排序字段的索引字段的复合索引,优化器可能会选择这个索引,效率一般都比排序字段的索引高。这个方案也不用动sql。
表膨胀#
某个东西阻止了死元组回收#
抛开autovacuum配置问题和一些边缘场景,常见的阻塞是:
- 长事务。注意:不是同一个表的长事务也会阻止死元组回收;查询语句也会造成这个问题
- 复制槽。复制槽延迟和死的复制槽会造成这个问题
这两种常见都是比较好解决的,1.terminate长事务会话 2.删除复制槽或者让消费端分析消费为什么这么慢。
update并发高导致表膨胀#
不同于某个东西阻止vacuum回收死元组,频繁的update导致表膨胀是因为死元组生成的速度快于vacuum回收的速度。一般来说这个场景的表的pg_stat_all_tables.n_tup_upd比较高,如果是因为表膨胀问题发现需要做repack的话,最好同时评估下是不是表的写入量大,应避免反复的手工repack。此时就需要调整表/索引的fillfactor参数。
原理参考这篇文章从很慢的唯一索引扫描到索引膨胀,结论我直接copy下来:
fillfactor原理:
fillfactor相当于表或索引的水位线,在INSERT数据时,插入到page的fillfactor线就到下一页去插入。fillfactor本身是为了给update留一定的空间,防止update频繁的去寻找新的page。
虽然表和索引都有fillfactor,他们的目的是一样的(为了update),但是具体细节有很大区别:
- 表:如果表的某个page上还有留有空间,那么update可以在这个page中进行,不需要申请新的page或者到其他有空闲空间的page上去。不仅如此,因为PG 独有的HOT特性,页内更新不会更新索引,当然也就会减缓索引膨胀
- 索引:不同的数据行或者相同数据行的页外更新,会新生成索引条目。fillfactor给索引页留下余量,会极大的减缓索引分离问题。
当然,fillfactor的设置跟业务模型是息息相关的,如果数据类似日志那样是递增且完全没有更新的,那么表和索引的fillfactor设置成100无可厚非。但是大部分业务表总是有更新的,表和索引fillfactor就不应该设置成100,如果是频繁的update,那么fillfactor应该设置得更低。 然而,pg默认的fillfactor如下:
- 表默认 fillfactor=100
- 索引默认 fillfactor=90
推荐设置:
alter table lzlpg set (fillfactor=60);
alter index lzlpg_pkey set (fillfactor=70);
--以上命令只会对新page生效,对存量page需要做repack
--repack:
1.检查是否有长事务,有则先处理长事务
2.nohup pg_repack -d lzldb --table lzlpg -p 6666 -no-kill-backend > pgrepack_lzlpg_log.log 2>&1 &长事务问题#
长事务的知识点没有多少,及时告警及时处理就行了,但长事务问题绝对值得拿出来单独批斗。
长事务会导致许多问题,例如:
- 锁不释放导致应用阻塞
- wal不回收导致磁盘告警
- 死元组不回收导致sql性能下降
- 还有些奇葩性能问题跟长事务相关
- …
pg的长事务危害要比oracle、mysql来得大的多,pg中的长事务一定要严格管理。
子事务问题#
“Subtransactions are basically cursed. Rip em out.”
子事务会造成很多问题,也是我们常踩的坑,在行业中也经常遇到子事务导致的问题。
行业踩坑记录:
Waiting for Postgres 17: Configurable SLRU cache sizes for increased performance
Subtransactions-overflow-and-the-performance-cliff
Why we spent the last month eliminating PostgreSQL subtransactions
子事务的出现:
PL/pgSQLfunctions containing a block with an exception clausesavepoints- JDBC+autosave=always (默认
autosave=never) - ODBC
注意OGG使用ODBC驱动,ODBC不能关闭子事务。
GaussDB提供的ODBC可以关闭子事务,参数ForExtensionConnector
所以我们可以建议应用使用子事务不超过64个,但很难建议他们不去使用OGG,因为脱O意味着使用依赖OGG 的数据同步工具。
子事务问题出现的场景和现象:
- 1(+)个长事务+子事务溢出+高并发业务,性能急剧下降
- 子事务溢出(64+),性能稍微下降
- 子事务溢出(64+)+multixact,性能急剧下降
- 1(+)个长事务+1(+)个子事务,查询库性能急剧下降
pg17的提升:
SLRU是clog、multixact、subtrans等用来在共享内存中管理事务关系的。相关的源码定义如下:
/* Number of SLRU buffers to use for subtrans */
#define NUM_SUBTRANS_BUFFERS 32 //SLRU页面个数32个,这是共享内存中的
/*
* Each backend advertises up to PGPROC_MAX_CACHED_SUBXIDS TransactionIds
* for non-aborted subtransactions of its current top transaction. These
* have to be treated as running XIDs by other backends.
*
* We also keep track of whether the cache overflowed (ie, the transaction has
* generated at least one subtransaction that didn't fit in the cache).
* If none of the caches have overflowed, we can assume that an XID that's not
* listed anywhere in the PGPROC array is not a running transaction. Else we
* have to look at pg_subtrans.
*/
#define PGPROC_MAX_CACHED_SUBXIDS 64 //超过64个则溢出,each backend
pg17对SLRU的提升: 新增GUC参数可以配置SLRU槽的个数,拆分现有的SLRU锁由单个集中控制锁变为多个bank锁
提升效果:
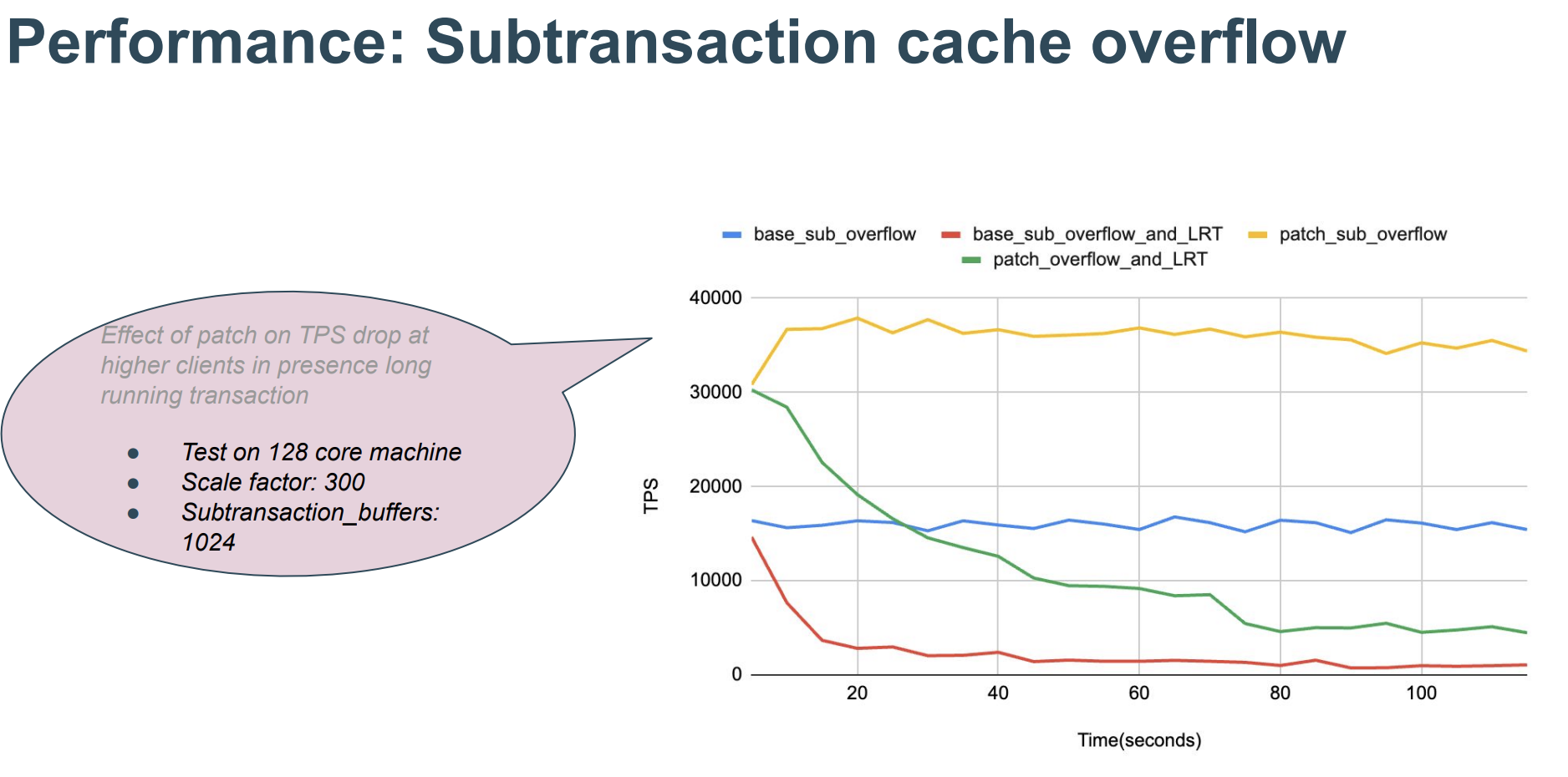 (https://www.pgevents.ca/events/pgconfdev2024/sessions/session/53/slides/27/SLRU%20Performance%20Issues.pdf)
(https://www.pgevents.ca/events/pgconfdev2024/sessions/session/53/slides/27/SLRU%20Performance%20Issues.pdf)
子事务处理方案:
- 开发规范:不要用
savepoints,考虑on conflict语法处理写入冲突 - 开发规范:不要用
exception - 开发规范:确保jdbc没有显示打开
autosave=always - 添加监控:针对性的监控
pg_stat_slru - 添加监控:针对性的监控
SAVEPOINTandEXCEPTION - CDC规范:谨慎使用ODBC,OGG或其他用到ODBC的工具,需要切割事务,一个大事务最高子事务个数上限为5W
- 升级版本:升级到PG17
并发与性能#
快照和并发参数调整#
| 参数名 | 参数类型 | 默认值 | 建议值 | 是否需要重启 |
|---|---|---|---|---|
old_snapshot_threshold | cpu | -1(社区版) | -1 | 是 |
max_parallel_workers_per_gather | cpu | 2 | 0 | 否 |
old_snapshot_threshold参数打开很容易引起性能问题,网上资料已经很多了自行搜索,哪怕是需要重启数据库,也强烈推荐关闭参数。
max_parallel_workers_per_gather 参数会自动开墙大sql的并行,但是并行为2效率不会成比例提高2倍,参数建议在特殊场景下使用,如跑批时显示指定并行度。由于不需要重启,也就顺手一改的事。
关闭old_snapshot_threshold会不会有问题?
不会。old_snapshot_threshold参数目的是为了限制长事务,因为pg长事务很容易引起性能问题,但是参数本身也会引发性能问题就得不偿失了。
处理长事务可以很多手段:
- 长事务监控。这是最重要的,而且监控已经比较成熟了。
- 设置
statement_timeout,默认0 - 设置
transaction_timeout,默认0,版本17=+支持 - 设置
lock_timeout,默认0,DDL语句建议会话级别开启 - 设置
idle_in_transaction_session_timeout,默认0,已开启2h - 设置
idle_session_timeout,默认0,这个场景没用
高并发提交导致LWLOCK:WALWrite#
记忆点:
- IO:WALWrite只有1个,而LWLOCK:WALWrite有几十个
- 不能直接看到LWLOCK的blocking chain,但是我可以从源码中得知,LWLOCK:WALWrite在等待IO:WALWrite
- 在这种并发高的小事务场景中,提高wal buffer内存大小理论上效果不会太理想
会引起什么问题?
- 并发写入阻塞,写入接口变慢,活动会话可能上涨
- 高并发小事务无法压榨磁盘IO
解决办法:
- 业务打散并发写入
- 业务合并提交
- 分析FPI,尝试减少FPI(参考FPI小节)
- 组提交(待研究)
WAL与延迟#
FPI与checkpoint参数#
pg的wal FPI发生在checkpoint后首次写入相关page时,所以checkpoint越频繁FPI出现的概率越高。
checkpoint频率与两个参数相关:
- checkpoint_timeout
- max_wal_size
原理如下:
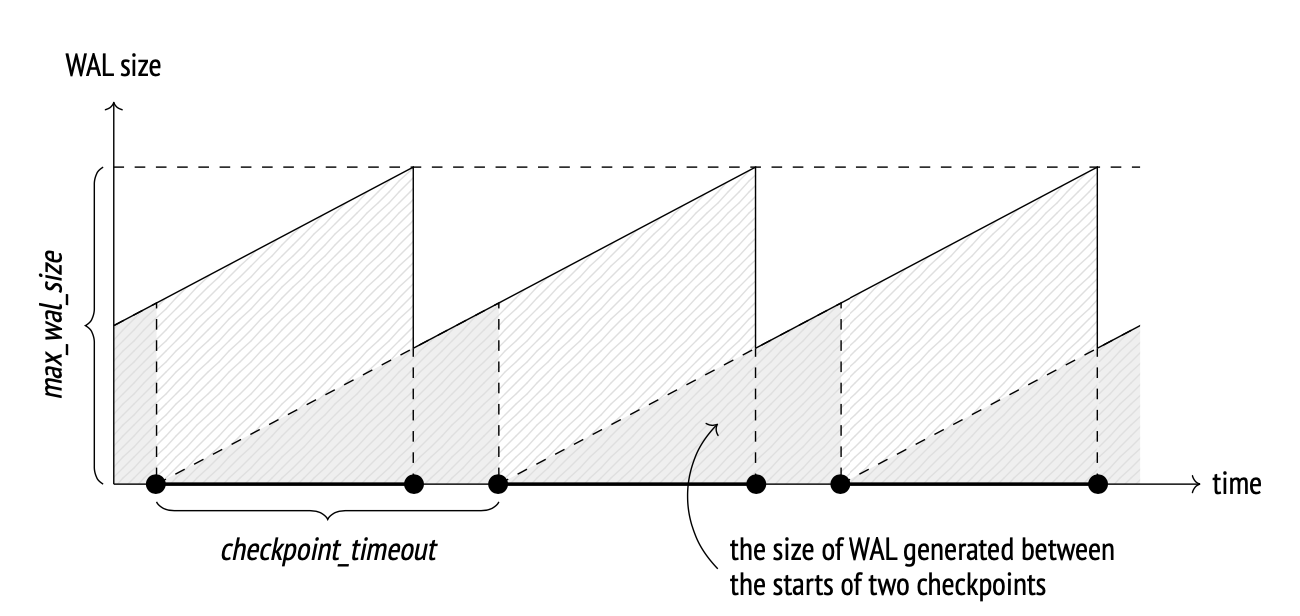 (Egor Rogov PoStgreSQL 14 Internals)
(Egor Rogov PoStgreSQL 14 Internals)
max_wal_size默认是1GB,这对于负载高的库来说太小了,一般来说可以调大这个参数以减少FPI。
checkpoint_timeout默认是5分钟,目前来看比较合理。
FPI与离散写#
即使调大了checkpoint的间隔,可能还是会有 FPI 问题,此时需要再排查业务是否有 UUID 离散写情况,可能需要业务改造为 sequence 或其他 UUID 方案。
找到具体索引示例:
1.查看FPI是否严重
--stats=record比较好用
pg_waldump -z --stats=record 00000001000001860000001B2.排序哪个rel的FPW比较多
pg_waldump 00000001000001860000001B|grep FPW|awk -F ':' '{print $7}'|awk '{print $2}'|sort -n|uniq -c |sort -r|head -10逻辑复制和复制槽#
逻辑复制问题非常多,也是社区重点优化项之一,几乎每个版本都有很大提升。
spill问题#
spill记忆点:
- spill是逻辑解码的时候内存放不下事务信息了所以放到磁盘,spill文件存放的就是事务信息
- 每个walsender都有独立的解码,所以每个逻辑复制都有自己的spill
- 大事物spill时,会有大spill文件,一般文件数比较少
- 子事务spill时,每个子事务对应一个spill文件
版本:
- PG12及以前是写死的4096条changes
- PG13新增
logical_decoding_work_mem参数,可调整内存大小以减少spill概率 - PG14及以后支持流式复制Streaming
- 触发流式复制也需要一定的条件,所以即使有流式复制也可能会发生spill
- PG17新增
debug_logical_replication_streaming参数以强制触发流式传输
walsender阻止停库#
其实任意进程不退出都会阻止停库,问题在于哪些比较容易搞出事。从停库代码流程来看archiver、walsender会常阻止停库,因为他们在停库阶段会做最后一次归档or日志传递。
- 如果停库卡在walsender,尝试用
kill杀掉walsender而不是直接kill -9,此时checkpoint还没有跑完,强制停库会造成不一致停库。注意强制停库也最好用pg_ctl stop -D $PGDATA -m i来停库,而不是直接kill -9 - 如果停库卡在archiver,可以直接kill -9,因为checkpoint已经跑完了,库是一致性状态
分区表#
由于PG分区表其实是很有特点的,有些特性知识不研究就不知道,开发一般弄不明白pg分区表,所以在使用分区表时会留下很多坑
分区表父表和子表索引不一致#
由于创建子分区不规范,很多索引是在子表上建的(实际上不应该单独在子表上建索引),也没有做 ”所有子表创建索引+attach索引“的操作,导致父表其实没有索引或没用有效索引。父表因为没有数据所以其上没索引对业务没有影响,影响的是新建子分区时,只会继承父表索引,导致新的子表可能会缺少索引。
父表失效索引比较好处理,参考创建分区索引的正确姿势
--ONLY方式在分区主表上创建失效索引。快,会阻塞后续dml,会影响业务,需要关注长事务
CREATE INDEX IDX_DATECREATED ON ONLY lzlpartition1(date_created);
--CONCURRENTLY在各个分区子表上创建索引。慢,不会阻塞后续dml,不会影响业务,但需要关注DML长事务防止本身失败
create index concurrently idx_datecreated_202302 on lzlpartition1_202302(date_created);
--所有索引attach。快,不会发生业务阻塞
ALTER INDEX idx_datecreated ATTACH PARTITION idx_datecreated_202302;父表没有主键比较难处理,参考分区表添加主键和唯一索引
添加主键在主表上申请AccessExclusiveLock,阻塞一切。 分区表上添加索引很慢,主键又会造成后续的阻塞,目前没有影响较小的在分区表上添加主键的办法。虽然没有达到目的,可以考虑用“attach唯一索引+非空约束”的办法;或者只能申请较长的停分区表业务,等待创建索引完成;或者通过第三方同步工具将数据插入一个带主键的分区表。
滥用default分区#
default分区过大导致parition of创建子分区长期阻塞
原因很简单:分区表新增子分区时,由于建分区的语句需要校验default分区中的数据,保证新分区数据范围与default分区的现有数据不冲突,导致create table partition of读取了大量的default分区数据,新建分区一直未完成。随后阻塞扩大,业务数据无法查询和写入。
default分区滥用是普遍的问题!社区pg本来也没有提供interval分区功能,开发哪天忘记创建分区了,数据就跑到default分区,也不会有任何报错和告警。但是日复一日···default分区就越来越大,最后发版建分区搞出问题。
default分区过大不能一直这么放着,虽然attach建分区可以避开阻塞问题,但出于各种角度考虑还是需要排这个雷。
default分区数据处理方案1:
- detach default子分区,然后合理创建子分区,再将default表数据回插到分区表中。
- 如有必要,可在detach且创建合理子分区后,创建一个空的default分区,以保持业务数据的连续性。
- 注意detach跟attach不同,detach需要主表的8级锁。PG14支持detach concurrently,但不能有default分区。
default分区数据处理方案2:
- detach default子分区,然后合理创建子分区,detached后的default表attach成普通子分区,需要注意range的范围。
- 如有必要,可在detach且创建合理子分区后,创建一个空的default分区,以保持业务数据的连续性。
- 注意detach跟attach不同,detach需要主表的8级锁。PG14支持detach concurrently,但不能有default分区。
default分区数据处理方案3:
- 新建表所有数据通过dts同步
- rename表
方案3看起来是最矬的,但是我个人最推荐。原因是如果你的手里有5套库需要处理,那么可以用精湛方案没问题,如果你的手里有200套库需要处理,那么要投入的人力成本,dts应该是最佳落地方案。
分区表select权限丢失导致执行计划异常#
用户对分区子表没用select权限,会导致用户执行的sql不能访问子表的统计信息,从而导致执行计划异常。正常partition of创建的分区表是不带select权限的,从主表访问数据可以访问到,所以这是范围比较大的问题。
解决方案
- 让云平台解决,自动化处理
- 落地select子分区权限的开发规范
高并发分区全扫描和LWLock:lockmanager#
这也是一个很常见的问题!
推荐看下aws的文档,写的很清楚了:https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/wait-event.lw-lock-manager.html
问题现象:
- 活动会话暴涨
- LWLock:lockmanager等待事件严重
- 数据库性能cliff
发生场景:
- sql查询多个分区
- 该sql并发较高
记忆点:
- fastpath锁机制本身是为了“弱锁”快速访问,提升数据库并发而设计的
- fastpath锁等级小于等于3。即是select、select for xxx、DML才能使用(弱锁便是锁模式必须小于
ShareUpdateExclusiveLock,也就是1、2、3级锁有机会使用到fastpath)。换句话说就是为了正常业务都受益 FP_LOCK_SLOTS_PER_BACKEND,本地进程持有fastpath的锁不超过16个,超过16就要到内存中去获得锁,LWLock:lockmanager在此时产生- 不仅是表,每个被访问的索引都要加锁
- 这个问题跟分区数量没有多大关系,即便分区比较少也可能触发
LWLock:lockmanager等待导致性能下降
可以计算一下,如果一个分区表上有1个主键和2个普通索引,多少个分区就会用不到fastpath?
16/(3个索引+1表本身)-1父表本身=3个子分区是的,3个子分区的全分区扫描就会可能会出现这个LWLock:lockmanager等待了。
如果是普通表的话,表上建16个索引也会用不到fastpath。
解决办法:
- 对于表不是特别大的,合并分区成普通表
- sql加入分区过滤条件
- 减少索引(比较没用,因为一般子分区数就超过16个了)
难点:
在oracle脱O到PG库的场景中,由于oracle支持全局索引,主键和唯一索引可以不带分区键,到pg后主键和唯一索引必须要带分区键。
主键示例如下:
idxlzl(primarykey) --oracle
idxlzl(primarykey,partitionkey) --pg常见的表上的sql是这样:
select col from tlzl where primarykey=12345;这个场景要推动业务在这个sql上添加分区条件吗?很难。阻力在于“我已经传入主键了,你还要我怎样?如果我什么数据都知道,我还要查数据库吗?”
如果是这样,只能推荐改造分区表为普通表,目前没有想出其他好办法。
内存#
对象过多导致relcache过大#
记忆点:
- relcache保留relation相关的元数据:oid、pg_class、分区表、子事务、行安全策略、统计信息、索引元数据、am等等。
- 每个会话都有自己的(rel)cache缓存系统数据(元数据等)
- 一般这个cache很小。当catalog很大且会话访问过所有catalog时,cache会变的很大
- cache的管理很简单,没有删除机制和limit限制(其实有invalidation消息)
- 关闭会话会释放cache
解决办法:
- 减少对象,特别是要检查分区表子分区数是否太多了
- 设置激进的连接池断连参数,让业务连接中断更频繁
内存碎片问题#
命令推荐:
cat /proc/meminfo|grep whatyouneed
cat /proc/buddyinfo
## cg内存
/opt/cgtools/cginfo -t perf -s mem
#重点关注 pgscand/s直接内存回收指标,一般几万就代表有问题
sar -B -s "08:00:00" -e "09:00:00"
#min_free_kbytes设置:
cat /proc/sys/vm/min_free_kbytes
#所有进程的物理总内存使用量:
grep Pss /proc/[1-9]*/smaps | awk '{total+=$2}; END {printf "%d kB\n", total }'
#某进程PSS内存:
cat /proc/90875/smaps |grep Pss |awk '{sum+=$2 };END {print sum/1024}'
#某进程的RSS内存 :
cat /proc/68729/smaps |grep Rss |awk '{sum+=$2 };END {print sum/1024}'
#某进程私有内存:
cat /proc/90875/smaps|sed '/zero/,/VmFlags/d' |grep Private |awk '{sum+=$2 };END {print sum/1024}'min_free_kbytes:
(https://vivani.net/2022/06/14/linux-kernel-tuning-page-allocation-failure/)
当可用内存较低时kswapd守护进程会被唤醒以释放页
- pages_low:当可用的空闲页面数量低于pages_low 时,buddy allocator会唤醒 kswapd 进程,内核开始将页换出到硬盘。
- pages_min:当可用页面数量达到 pages_min时,说明页回收工作的压力就比较大,因为内存域中急需空闲页。分配器将以同步的方式执行 kswapd 工作,有时也称为直接回收。
- pages_high:一旦 kswapd 被唤醒开始释放页面,只有在可用页面数量达到pages_high时,内核才认为该区域是“平衡的”。如果水位线达到pages_high,kswapd 将重新进入休眠状态。空闲页多于pages_high,则内核认为zone的状态是理想的。
vm.min_free_kbytes也就是min_pages线,十分重要的操作系统参数。非常低的值会阻止系统有效地回收内存,这可能会导致系统崩溃并中断服务。太高的值会增加系统回收活动,造成分配延迟,这可能导致系统立即进入内存不足状态。
优化效果:
min_free_kbytes调大+部署非业务时段drop cache,问题已经少很多了。
为什么是调高min_free_kbytes?
This is used to force the Linux VM to keep a minimum number of kilobytes free. The VM uses this number to compute a watermark[WMARK_MIN] value for each lowmem zone in the system. Each lowmem zone gets a number of reserved free pages based proportionally on its size.
min_free_kbytes调高的本质不是为了把对应的min page线提高已更高概率地触发直接内存回收,而是因为low page线在linux7以前是无法调整的,只能通过调高min page线以等比例的提高low page线以更容易触发异步回收,并给直接内存回收的触发创造缓冲时间。
Redhat 8 版本增加了2个内存参数来优化内存回收 :watermark_scale_factor 可以在不调整min_free_kbytes情况下,抬高水位线。
建议开启大页:
- 大页在业务(pg库)申请连续内存的时候性能较好
- 大页也有助于减少page cache大小
- shared_buffer可使用大页,需开启Huge_pages和操作系统已开启大页
- 生产开启了大页的库,性能有提升,问题更少
- aws大页标准:除了几个测试套餐外,其他均默认开启大页且不可关闭
Huge_pagesparameter is turned on by default for all DB instance classes other than t3.medium,db.t3.large,db.t4g.medium,db.t4g.large instance classes. You can’t change thehuge_pagesparameter value or turn off this feature in the supported instance classes of Aurora PostgreSQL.
cgroup和主机内存错位#
cgroup中的内存达到cg内存限制后,kswapd 进程会优先回收cg中的内存,云主机售卖资源和cgroup配置,可能存在主机空闲内存在水位之上,而cg内存紧张,主机层面的pages_low ,导致kswapd 不会异步回收主机内存也不会回收cg内存,最终是通过触发直接回收内存CG中的DB内存需求。
根因在于cgroup中没有单独的free page内存管理机制。
这种情况只能把cg内存调高,云主机内存更多的超卖,以达更容易达到主机的pages_low。
shared_buffer和pagecache#
pg是double buffer机制,目前还没有direct IO。
double buffer是指DB shared buffer一层共享内存,OS pagecache一层共享内存。在真实场景中,pagecache一般远大于shared buffer,而pagecache又是算在cgroup mem中的,没有算到监控cg内存中···
总之,要留足内存给pagecache使用,shared buffer不要超过太大(目前来看20GB足够),除非可以明显观察到等待事件中有buffer mapping相关内存等待,不然不要去调太大。
work_mem无法限制hash join/hash aggregate使用的内存#
hash_mem_multiplier 用于限制基于hash-based operations的内存大小(应该包括hash join,hash agg等),限制是hash_mem_multiplier*work mem。hash_mem_multiplier默认为2。
在pg13以前虽然可以限制work mem,但是无法限制1个query使用了多少个hash操作,所以pg13增加了这个参数。也就是说13以前,是很难限制hash table的内存的。
在pg12-的生产环境中找到消耗300G内存的一个会话,罪魁祸首就是低版本没有hash table限制和执行计划错误的使用hash table
其他问题#
排他备份和起库问题#
正常来说,数据库停库再起库,起库的位置从pg_controldata中的LSN位置获取,但是如果PGDATA目录下有一个backup_label文件,启动位置LSN会从backup_label文件获取。
会引起什么问题:
磁盘快照直接打的是data目录快照,label文件有可能在里面,如果库大备份时间长的话,起库时间就很长
大问题:某些原因生产停库后,库启动会很久。根因在于起库的LSN应该从controldata中获取,而不是备份中
版本变化:
pg13:
pg_start_backup()
pg_stop_backup()
支持排他和非排他模式,默认就是排他模式。排他模式会在start的时候在data目录下创建backup_label文件,stop的时候会清理。非排他模式start的时候不会创建label文件,stop的时候返回label信息。
pg15:
pg_backup_start()
pg_backup_stop()
函数名称变化,移除了排他备份模式。不会在启动备份的时候写backup_label文件,而是在结束备份的时候写入到备份区域。
pg_stat_activty无法查询#
现象:
pg_stat_activty无法查询
当时的pstack如下:
#0 pgstat_read_current_status () at pgstat.c:3642
#1 0x0000000000727181 in pgstat_read_current_status () at pgstat.c:2788
#2 pgstat_fetch_stat_numbackends () at pgstat.c:2789
#3 0x000000000083f2ee in pg_stat_get_activity (fcinfo=0x25c2d98) at pgstatfuncs.c:575
#4 0x000000000065058f in ExecMakeTableFunctionResult (setexpr=0x25b1d28, econtext=0x25b1c48, argContext=<optimized out>, expectedDesc=0x2545218, randomAccess=false) at execSRF.c:234
#5 0x00000000006609dc in FunctionNext (node=node@entry=0x25b1b38) at nodeFunctionscan.c:94
#6 0x000000000065110c in ExecScanFetch (recheckMtd=0x660700 <FunctionRecheck>, accessMtd=0x660720 <FunctionNext>, node=0x25b1b38) at execScan.c:133分析:
代码定位比较明确,卡在st_changecount成为奇数进入死循环。
什么场景会触发?OOM(可复现),backend异常退出(可能),terminate(maybe);这三个场景不代表一定会造成这个问题。
社区邮件没有讨论出结果,目前来看触发概率不高。
解决方案:重启数据库
连接问题和连接池问题#
IO error报错#
IO error报错一般是业务层与数据库连接断开,业务层仍在使用已断连的连接导致的报错。 该问题出现比较频繁,而且由于整个链路上涉及的组件多、知识域宽,所以诊断起来比较困难,以下做一个简单总结。
已知的主动断连场景:
1.hikari maxLifetime
现象:会话保持时间与参数一致。 可能报错原因:业务显示事务执行 select 未提交,连接池断开会话,业务报 io error;could not rollback 相关错误。
pg.datasouce.maxLifetime2.druid timeout 现象:业务 sql 执行超 20s 后连接断开
spring.datasource.dynamic.druid.socketTimeout=20000
spring.datasource.dynamic.druid.connectTimeout=20000
改为
spring.datasource.socketTimeout=3600000
spring.datasource.connectTimeout=3600000 业务容器扩容和数据库连接上限#
业务横向扩容和pg库的连接瓶颈:
HikariCP目前已是SpringBoot默认的连接池,伴随着SpringBoot和微服务的普及,HikariCP 的使用也越来越多。业务每扩容一个pod,数据库连接数都会上涨。原因在于maximumPoolSize虽然每个pod中配置没有动,但业务节点横向扩展了。从已有节点数、增加节点数、现有数据库连接总数可以成比例的计算出来数据库的空闲连接会加多少。
应用可以无状态的横向扩容,但是数据库不是,pg的连接上限参数max_connections,应用成倍的扩容是有可能造成idle连接数就打满了。max_connections的调整是个很麻烦的工作因为要重启数据库生效。
pg库连接上限:
还有一个点在于,业务无限横向扩容,max_connections应该随云实例套餐调整而调整,但是可以无限往上调整吗?很明显不是的。pg库,无论什么库,idle连接越多性能都会下降。
可参考AWS的做法:
max_connections与套餐相关,最大值5000 ,LEAST({DBInstanceClassMemory/9531392},5000).这可以减少人力运维连接数,也给出了比较合理的最大值