PG的事务
为了保证事务的ACID特性,rdbms必须要实现并发控制。pg和oracle、mysql(innodb)数据库都使用MVCC来实现并发控制。MVCC通过数据变化时不断生成新版本对象和可查询一定范围的老版本对象来实现并发,MVCC保存数据在某个时间点的快照,读数时选择一个版本进行读取。
oracle、mysql都通过undo来记录老版本对象,pg没有undo,而是在DML时在直接将历史数据写在原表上(update会创建新行,delete标记行),并在表中记录额外的列xmin,xmax来记录事务号,通过对比事务号和一些其他信息来实现mvcc机制。
在众多关系型数据库中,pg的事务机制非常有特色,了解pg的事务机制是了解pg数据库运行原理的关键。
事务隔离级别#
一般关系型数据库都可以设置多个不同的事务隔离级别。在不步的事务隔离级别下,事务并发行为有所不同
设置事务隔离级别#
pg支持设置4种事务隔离级别(实际上只会生效有3个)
{ SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }事务隔离级别参数
default_transaction_isolation:设置全局事务的默认隔离级别
transaction_isolation:设置当前会话的事务隔离级别
默认隔离级别read committed
修改全局事务的默认隔离级别
直接修改default_transaction_isolation参数,然后reload即可
修改完成后,每个新的事物都会使用default_transaction_isolation隔离级别
postgres=# alter system set default_transaction_isolation to 'serializable';
ALTER SYSTEM
postgres=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres=# show transaction_isolation;
transaction_isolation
-----------------------
serializable设置当前会话的隔离级别
注意参数transaction_isolation只是展示当前会话的隔离级别,这个参数是不可以直接修改的
lzldb=# alter system set transaction_isolation to 'REPEATABLE READ';
ERROR: parameter "transaction_isolation" cannot be changed通过SET SESSION修改会话的隔离级别,例如:
lzldb=# SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET
lzldb=# show transaction_isolation ;
-[ RECORD 1 ]---------+----------------
transaction_isolation | repeatable read设置事务的隔离级别
pg可以指定事务本身的隔离级别
可通过在开启事务时设置事务的隔离级别,例如:
lzldb=# BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN
lzldb=# start TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION或者开启事务后set transaction
lzldb=# begin;
BEGIN
lzldb=*# set transaction ISOLATION LEVEL REPEATABLE READ;
SETANSI92的事务隔离级别#
在ANSI SQL-92事务隔离级别标准中包含4种隔离级别:
Serializable(可串行化或称可序列号)
系统中所有的事务串行化执行,事务之间互不影响。
以串行地方式逐个执行,能避免所有数据不一致情况。
早期以排他锁来控制并发事务,串行化执行方式会导致事务排队,系统的并发量大幅下,不过ANSI 92后出现更多序列化实现方法,并发性和性能均有较大提升。
Repeatable read(可重复读)
一个事务一旦开始,事务过程中所读取的所有数据不允许被其他事务修改。可重复读是mysql的默认隔离级别。
注意, 在ANSI SQL中可重复读级别可发生幻读,但是pg的可重复读不会发生幻读
Read Committed(已提交读)
一个事务能读取到其他事务提交过的数据。
事务在处理过程中如果重复读取某一个数据,而且这个数据恰好被其他事务修改并提交了, 那么当前重复读取数据的事务就会出现同一个数据前后不同的情况。 已提交读是oracle、pg的默认隔离级别
在这个隔离级别会发生“不可重复读”和”幻读“的场景。
Read Uncommitted(未提交读)
一个事务能读取到其他事务修改过,但是还没有提交的(Uncommitted)的数据。
数据被其他事务修改过,但还没有提交,就存在着回滚的可能性,这时候读取这些“未提交” 数据的情况就是“脏读”。
在这个隔离级别会发生“脏读”场景。
pg没有未提交读这个隔离级别,设置未提交读会被当做已提交读
标准的一致性读和隔离级别矩阵
| 事务隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| 未提交读 | 可能 | 可能 | 可能 |
| 已提交读 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 可能 |
| 序列化 | 不可能 | 不可能 | 不可能 |
pg的一致性度和隔离级别矩阵
| 事务隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| 未提交读 | 不可能 | 可能 | 可能 |
| 已提交读 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 不可能 |
| 序列化 | 不可能 | 不可能 | 不可能 |
事务隔离级别的历史#
ANSI SQL-92定义的隔离级别和异常现象确实对数据库行业影响深远,甚至30年后的今天,绝大部分工程师对事务隔离级别的概念还停留在此,甚至很多真实的数据库隔离级别实现也停留在此。但后ANSI92时代对事物隔离有许多讨论甚至批评,针对隔离级别和异常现象的论文、博客、文章、讨论非常多,这里概况一下事务的比较重要发展历史:
1992年,由于数据库行业处于混沌的事务状态,美国国家标准学会定义ANSI SQL-92标准。也就是广泛流传的4种隔离级别和4种异常现象
1995年,snapshot isolation等隔离级别提出和更多的异常现象。微软工程师等提出snapshot isolation隔离级别,并对ANSI SQL-92做出批判,92标准定义模糊,而且有许多隔离级别和异常现象未定义。参考《对ANSI SQL隔离级别的批判》.
此时隔离级别已不止4个,异常现象也更多,其中也包括写偏序异常。
1999年 ,由于锁模式的不同发展出过多的隔离级别,Atul Adya的论文整理了这些现象,并根据异常现象和功能将众多隔离级别回溯到ANSI SQL92标准进行对应。
2005年 ,由于绝大部分数据库声称他们是可串行化的,但他们实际上是快照隔离, Alan Fekete et al 提出“使快照隔离可序列化”。在snapshot isolation级别基础上实现可序列化,消除快照隔离的异象。
2008年 ,Fekete 扩展了可序列化,并提出数据库层面实现“使快照隔离可序列化”,称之为快照隔离可序列化SSI (Serializable Snapshot Isolation)
2012年 ,postgresql第一个在数据库中实现SSI ,参考postgresql数据库实现SSI的论文
其中,95年《对ANSI SQL隔离级别的批判》中的隔离级别和异常现象
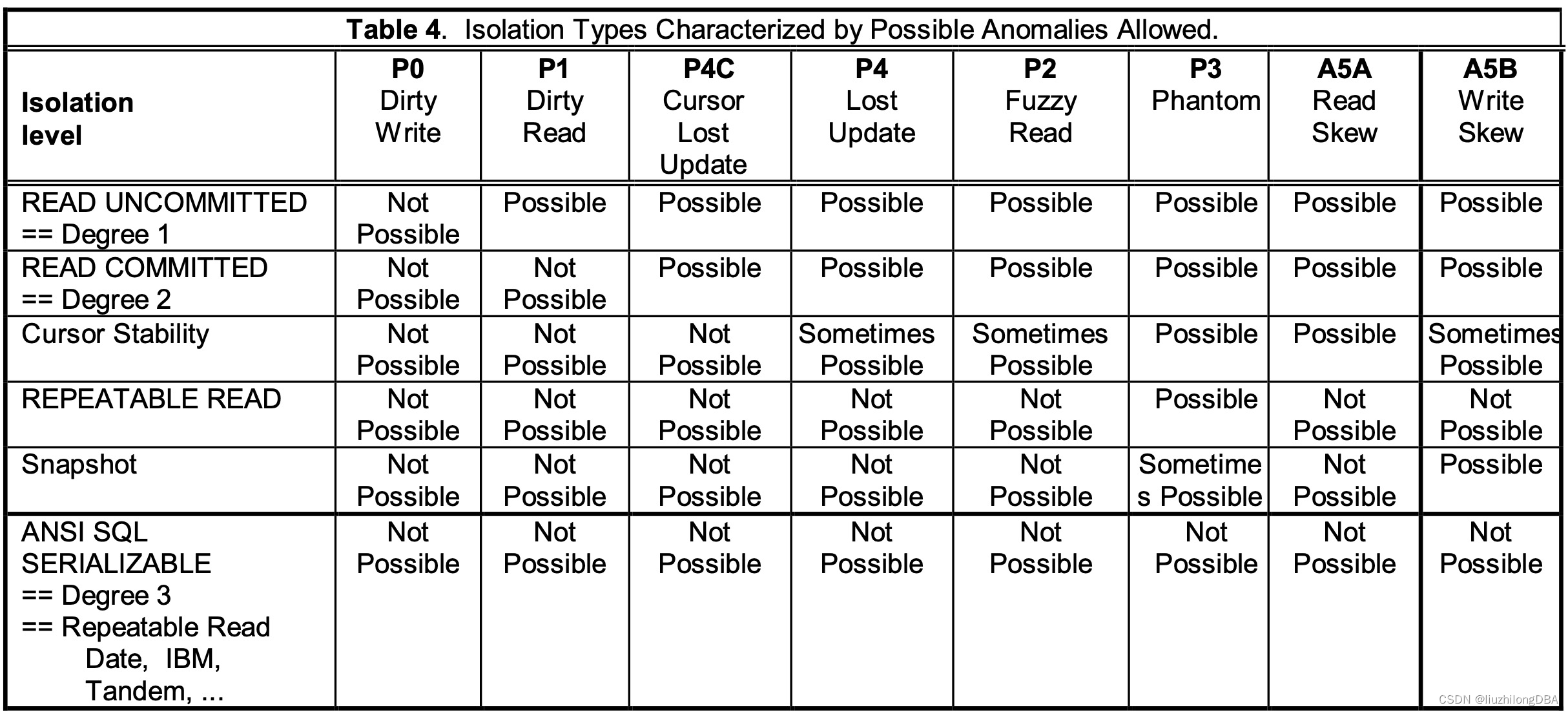
各种数据库支持的隔离级别#
很多数据库的声称他们”完全支持ACID“特性,但是没有可串行化是不能完全实现ACID的(特别是一致性)。然而许多数据库在不支持可串行化级别下声称他们支持ACID。其实他们绝大部分都没有完全实现,包括数据库老大哥oracle。
可串行化#
人们对可串行化存在许多误解。
可串行化的含义:如果每个事务本身是正确的,即满足某些完整性条件,那么包括这些事务的任何串行执行的时间表是正确的(其事务仍然满足其条件):“串行”意味着事务在时间上不重叠,并且不能相互干扰,即彼此之间存在完全隔离。
1970年代可串行化(serializable)通过严格两阶段锁(SS2PL)实现,读写相互阻塞,直到事务结束。SS2PL丢失高可用性但消除了异常现象。
除了SS2PL实现可串行化,还有其他方式,比如可串行化快照隔离(SSI)。
为了保证没有异常,可串行化会丢失一些并发性(不同实现方式有所不同),但可以真正保证数据的一致性(ACID中的consistency)。也就是说没有实现串行化的数据库,其实没有完全支持ACID特性
可串行化在数学上已经证明可以实现,但是真实的数据库世界有点”不正常“。实际上,可串行化是事务隔离级别中最高级的,也是所有学者和大佬强力推荐的隔离级别,不过绝大部分数据库在RC或快照隔离级别上运行
为什么弱隔离级别在学术上有问题,实际上没出现严重问题?#
1.非可串行化隔离级别的异常现象,一般都需要再高并发情况下才会发生,一般低并发数据库不太会出现问题
2.异常现象真的发生的时候,有些应用可能没发现异常现象或没检查到异常对他们不重要。
3.有可能数据异常了,但应用只是返回报错,并进入数据异常处理程序。
4.成本过高。不仅是数据库序列化隔离级别开发成本高,应用对可序列化也需要适应成本。光是理解这部分复杂的理论就不是一件容易的事
5.高级别的隔离会丢失一些性能。大量的改造工作可能是吃力不讨好的,应用需要在“高并发”和“无异常现象”间做抉择
6.业务基于机制开发,而不是规则开发。业务多少有点适应弱隔离级别的异常现象,特别是RC或快照隔离级别
快照隔离#
ANSI SQL92并未定义快照隔离snapshot isolation(SI),这个隔离级别随着数据库行业发展才出现。
引自wiki定义:在快照隔离下执行的事务是在事务开始时拍摄的数据库的快照上操作的。当事务结束时,只有当事务更新的值自快照拍摄以来没有外部更改时,它才会成功提交。这样写冲突将导致事务中止。
快照隔离级别顾名思义就是就是使用了快照,存在于使用了MVCC的数据库中,多版本并发机制支持用户并发执行事务。
1992年 ANSI SQL92标准基于数据库的锁而定义,所以没有快照隔离级别这个定义。直到1995年《批判》的出现才被提出。
快照隔离串行化#
由于快照隔离的广泛应用,而可序列化是学术上的数据库需要达到的隔离级别目标,可序列化快照隔离Serializable Snapshot Isolation (SSI) 随即产生。顾名思义,在快照隔离的基础上实现可序列化。
由于ANSI92标准的模糊性,虽然没有定义快照隔离,但许多数据库实际上就是使用的快照隔离。而快照隔离同样存在一些异常现象(包括写偏序),SSI的出现就是为了解决这些异常现象。
主流数据库通过基于S2PL或MVCC实现并发控制。在S2PL下写操作会阻塞其他事务读写,因此不会有写偏序异常问题。而MVCC实现了读写互不阻塞,只有写写冲突。在并发RW模式模式下会导致写偏序问题。SSI在pg9.1开始已经嵌入快照隔离SI中(pg只有快照隔离,哪怕是在可序列化级别下),解决了写偏序等异常。
写偏序#
由于某些冲突构成环,会出现串行化异常**。**其中比较容易理解的一个就是写偏序(write skew)。
写偏序只发生在rw模型,ww、wr均不会发生写偏序,并且事务必须在并发条件下才会出现。前一个事务写入依赖后一个事务写入才会形成依赖环。
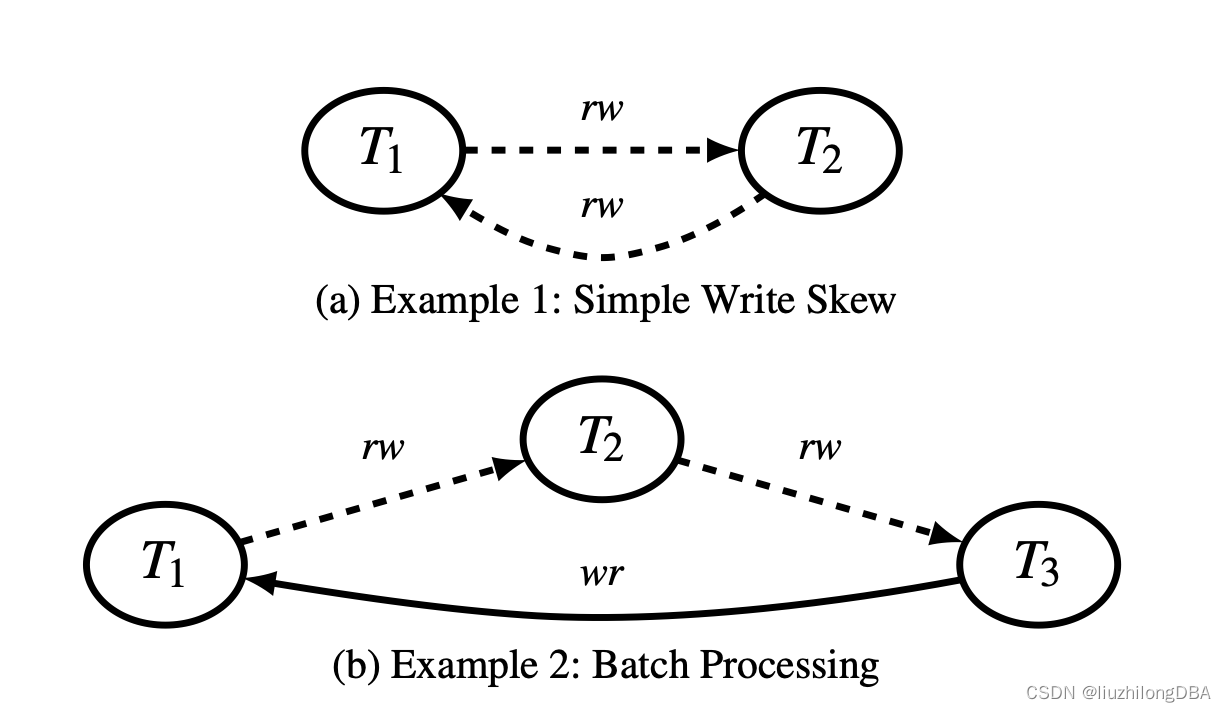
有许多现实案例可以出现写偏序异常,我们用一个经典的黑白球问题来理解写偏序
袋中有10个球,5个白球和5个黑球。此时有两个事务,P和Q。P将所有黑球改成白球,Q将所有白球改成黑球。此时可以有两个串行执行,P,Q或Q,P。在这两种情况下,最终结果是袋中有10个白球或者10个黑球。但是,快照隔离允许另一种结果:
- 事务 P 拿出5个黑球
- 事务 Q 拿出5个白球
- 事务 P 将手中所有黑球改成白球,放回袋中
- 事务 Q 将手中所有白球改成黑球,放回袋中
此时袋中还是5个黑球和5个白球,这在任何一个串行执行中都是不可能的。但这在快照隔离中是有效:每个事务都维护数据库的一致视图,并且其写集不与任何并发事务的写集重叠,如此白球黑球发生交换。
黑白球问题说明:快照隔离执行结果与串行化执行结果不一致,快照隔离下发生写偏序异常,数据结果与预期不一致。
pg中的SSI#
postgresql数据库是首个在数据库中实现SSI的数据库。
引用wiki的黑白球代码示例
create table dots
(
id int not null primary key,
color text not null
);
insert into dots
with x(id) as (select generate_series(1,10))
select id, case when id % 2 = 1 then 'black'
else 'white' end from x;| set default_transaction_isolation = ‘serializable’; | set default_transaction_isolation = ‘serializable’; |
|---|---|
| begin; update dots set color = ‘black’ where color = ‘white’; | |
| begin; update dots set color = ‘white’ where color = ‘black’; | |
| commit | |
| commit | |
| (pg SSI先提交者成功提交,后提交者抛出报错 ) | ERROR: could not serialize access due to read/write dependencies among transactions DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt. HINT: The transaction might succeed if retried. |
(已提交读和可重复读级别,均不会出现报错,黑白球颜色交换,不再展示测试结果)
严格两阶段提交(S2PL)也可以实现可串行化,但S2PL需要很重的读写锁,直到事务提交为止。S2PL会极大的影响并发性能,而且用户一般不会接受读写互相阻塞的情况,所以pg没有采用S2PL。
SSI是可序列化的另一种方案。它仍然会使用快照隔离,只是会额外检查是否有异常现象发生。
两个方案的处理方式也不同:在异常现象发生时,S2PL会阻塞事务,而SSI会中断事务以打破循环。
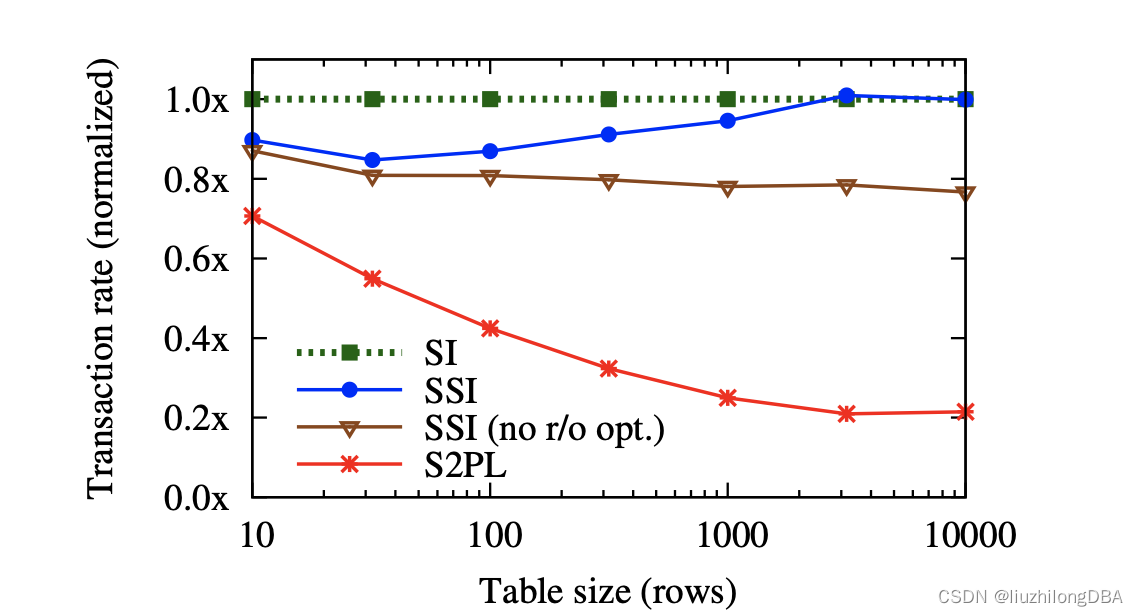
人们没有使用可串行化,原因之一有可串行化会降低数据库性能。这其实可以理解,因为有”检查异常现象“的SSI必定比什么检查都没有的弱隔离级别性能低。不过经过SSI实现理论的发展和pg本身对只读事务的优化,SSI的性能已于SI相差无几。
可序列化能极大的简化应用对一致性的担心,而pg9.1已实现ssi并加以优化。期待应用有一天真的能使用可串行化隔离级别。
事务隔离级别参考#
https://wiki.postgresql.org/wiki/SSI
https://en.wikipedia.org/wiki/Serializability
https://en.wikipedia.org/wiki/Snapshot_isolation
https://justinjaffray.com/what-does-write-skew-look-like/
http://www.bailis.org/blog/when-is-acid-acid-rarely/
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf 95年SI隔离级别以及对SQL92标准的批评
https://www.cse.iitb.ac.in/infolab/Data/Courses/CS632/2009/Papers/p492-fekete.pdf SSI论文
https://drkp.net/papers/ssi-vldb12.pdf postgresql实现SSI
https://ristret.com/s/f643zk/history_transaction_histories 事务隔离级别的历史
事务的处理#
事务块#
从事务形态划分可分为隐式事务和显示事务。隐式事务是一个独立的SQL语句,执行完成后默认提交。显示事务需要显示声明一个事务,多个sql语句组合到一起称为一个事务块。
事务块通过begin,begin transaction,start transaction开始
通过COMMIT,END或ABORT,ROLLBACK结束,其中COMMIT=END,ABORT=ROLLBACK
BEGIN;
select * from lzl1 limit 1;
update lzl1 set a=2;
END;如果事务块执行过程中一旦有报错,由于事务必须满足原子性,事务只能回退
lzldb=# begin;
BEGIN
lzldb=*# select * from lzl2;
ERROR: relation "lzl2" does not exist
LINE 1: select * from lzl2;
^
lzldb=!# commit;
ROLLBACK事务处理函数#
事务处理函数分为3个层次:顶层事务函数、中层事务函数、底层事务函数
顶层事务函数,处理事务块命令,比如BEGIN, COMMIT, ROLLBACK, SAVEPOINT等,有如下函数
| BeginTransactionBlock | 启动事务块 |
|---|---|
| EndTransactionBlock | 结束事务块 |
| UserAbortTransactionBlock | 用户显示结束事务块 |
| DefineSavepoint | 生成保存点 |
| RollbackToSavepoint | 回滚到某保存点 |
| ReleaseSavepoint | 释放保存点 |
中层事务函数,每个sql在执行前后都会调用中层事务函数,包括检测到异常后,有如下函数
| StartTransactionCommand | 启动事务命令 |
|---|---|
| CommitTransactionCommand | 完成事务命令,注意不是提交命令 |
| AbortCurrentTransaction | 退出当前事务 |
底层事务函数,真正的事务处理函数,负责维护事务状态、事务资源分配和回收等,有如下函数
| StartTransaction | 启动事务 |
|---|---|
| CommitTransaction | 提交事务 |
| AbortTransaction | 回滚/中断事务 |
| CleanupTransaction | 清理事务 |
| StartSubTransaction | 启动子事务 |
| CommitSubTransaction | 提交子事务 |
| AbortSubTransaction | 回滚/中断子事务 |
| CleanupSubTransaction | 清理子事务 |
其实这上面几个函数还是比较好分辨的。抛开几个特殊的函数(上层相关savepoint,中层abort函数),其实上、中、下三层事务层分成了:*Block(事务块函数),*Command(command函数),*Transaction(真正的事务处理函数)。然后把savepoint子事务当做事务块函数(后面会介绍,子事务可以在事务块中回退,所以这里把子事务放在事务块一级理所当然),把abort命令当做command级函数就可以了。
事务块状态#
上层函数和中层函数同时控制事务块状态,底层函数控制事务状态
事务块状态和事务状态均在src/backend/access/transam/xact.c
typedef enum TBlockState
{
/* 不在事务块中的状态 */
TBLOCK_DEFAULT, /* 空闲状态,事务开始或结束后都处于此状态 */
TBLOCK_STARTED, /* 刚开始进入事务块时的状态,由TBLOCK_DEFAULT转换到此状态,此状态存在时间较短 */
/* 事务块状态 */
TBLOCK_BEGIN, /* 启动事务块,此时才启动数据块,进入数据块级状态 */
TBLOCK_INPROGRESS, /* 活跃的事务,BEGIN以后事务块一直处于此状态,直到事务结束 */
TBLOCK_IMPLICIT_INPROGRESS, /* 隐式BEGIN的活跃事务 */
TBLOCK_PARALLEL_INPROGRESS, /* 并行执行的活跃事务 */
TBLOCK_END, /* 收到COMMIT命令 */
TBLOCK_ABORT, /* 事务失败,等待ROLLBACK */
TBLOCK_ABORT_END, /* 事务失败,收到ROLLBACK */
TBLOCK_ABORT_PENDING, /* 活跃事务,收到ROLLBACK */
TBLOCK_PREPARE, /* 活跃事务,收到PREPARE(显式2PC) */
/* 子事务状态(仍然是事务块级状态) */
TBLOCK_SUBBEGIN, /* 启动子事务 */
TBLOCK_SUBINPROGRESS, /* 活跃的子事务 */
TBLOCK_SUBRELEASE, /* 收到RELEASE(释放保存点) */
TBLOCK_SUBCOMMIT, /* 当子事务还在运行的时候(SUBINPROGRESS),收到父事务COMMIT */
TBLOCK_SUBABORT, /* 失败子事务,等待rollback命令 */
TBLOCK_SUBABORT_END, /* 失败子事务,收到rollback命令 */
TBLOCK_SUBABORT_PENDING, /* 活跃子事务,收到rollback命令 */
TBLOCK_SUBRESTART, /* 活跃子事务,收到rollback to命令 */
TBLOCK_SUBABORT_RESTART /* 失败子事务,收到ROLLBACK TO命令 */
} TBlockState;大部分状态是显而易见的。需要补充说明的是事务回滚(rollback)和事务失败(ABORT)两者后续行为是相似的,他们都要把清理事务资源和退出当前事务。但是pg把他们分为了两种行为,设置了两种状态TBLOCK_ABORT,TBLOCK_ABORT_END(子事务亦然),为什么会这样呢?
在src/backend/access/transam/README中对此现象作了详细的说明:
场景 1 场景 2 1) 用户输入 BEGIN1) 用户输入 BEGIN2) 用户执行某些命令 2) 用户执行某些命令 3) 用户不喜欢她所看到的东西,输入 ABORT3) 事务系统因为某些原因中断(语法错误等) 场景1中,我们想中断事务并把事务回退到default状态 。
场景2中,可能后续还会有更多的命令,这些命令也是当前事务块的一部分,我们不得不忽略这些命令,直到我们看见
COMMITorROLLBACK。
AbortCurrentTransaction处理事务内部中断,UserAbortTransactionBlock处理事务用户中断。两个函数都依赖AbortTransaction来处理所有真正的工作。唯一区别在于AbortTransaction工作结束后我们进入了什么状态:* AbortCurrentTransaction leaves us in TBLOCK_ABORT
* UserAbortTransactionBlock leaves us in TBLOCK_ABORT_END(原文如此,不过用户输入结束应该进入TBLOCK_ABORT_PENDING状态)
底层事务中断处理分为两个阶段:
* 一旦我们意识到事务失败,就会执行
AbortTransaction。这应该释放所有共享资源(锁等),以防不必要的增加其他backends的延迟。* 当我最终看到用户
COMMIT或者ROLLBACK时,执行CleanupTransaction;该函数将清理资源并让我们完全跳出事务。特别是,在此之前我们不能破坏TopTransactionContext。
事务状态#
事务状态一目了然(注意跟事务块状态是不同的)
typedef enum TransState
{
TRANS_DEFAULT, /* 空闲 */
TRANS_START, /* 事务启动 */
TRANS_INPROGRESS, /* 活跃的事务 */
TRANS_COMMIT, /* 事务提交 */
TRANS_ABORT, /* 退出事务 */
TRANS_PREPARE /* prepare事务(2pc) */
} TransState;事务状态流转#
事务块中的一个个命令,调用事务函数,事务函数转变事务、事务块的状态 以一个最简单的事务块举例(参考readme)
1)BEGIN
2)SELECT * FROM foo
3)INSERT INTO foo VALUES (...)
4)COMMIT命令调用关系:
/ StartTransactionCommand; --中层事务命令启动函数
/ StartTransaction; --底层真正处理启动事务函数
1)< ProcessUtility; --ProcessUtility处理BEGIN命
\ BeginTransactionBlock; --顶层事务块启动函数
\ CommitTransactionCommand; --中层完成命令函数
/ StartTransactionCommand; --中层事务命令启动函数
2) / PortalRunSelect; --SELECT语句执行
\ CommitTransactionCommand; --中层完成命令函数
\ CommandCounterIncrement; --中层完成命令函数
/ StartTransactionCommand; --中层事务命令启动函数
3) / ProcessQuery; --INSERT语句执行
\ CommitTransactionCommand; --中层完成命令函数
\ CommandCounterIncrement; --命令计数器计数+1
/ StartTransactionCommand; --中层事务命令启动函数
/ ProcessUtility; --ProcessUtility处理commit命令
4) < EndTransactionBlock; --调用顶层事务块结束函数
\ CommitTransactionCommand; --中层完成命令函数
\ CommitTransaction; --底层真正处理提交事务函数
- 事务块的每一个命令,都会以中层函数
StartTransactionCommand和CommitTransactionCommand开始和结束 - 在以上两个中层函数中间,可以看成真正执行的命令处理
2)SELECT和3)INSERT事务块状态都是TBLOCK_INPROGRESS,BEGIN和COMMIT状态块转换流程如下:
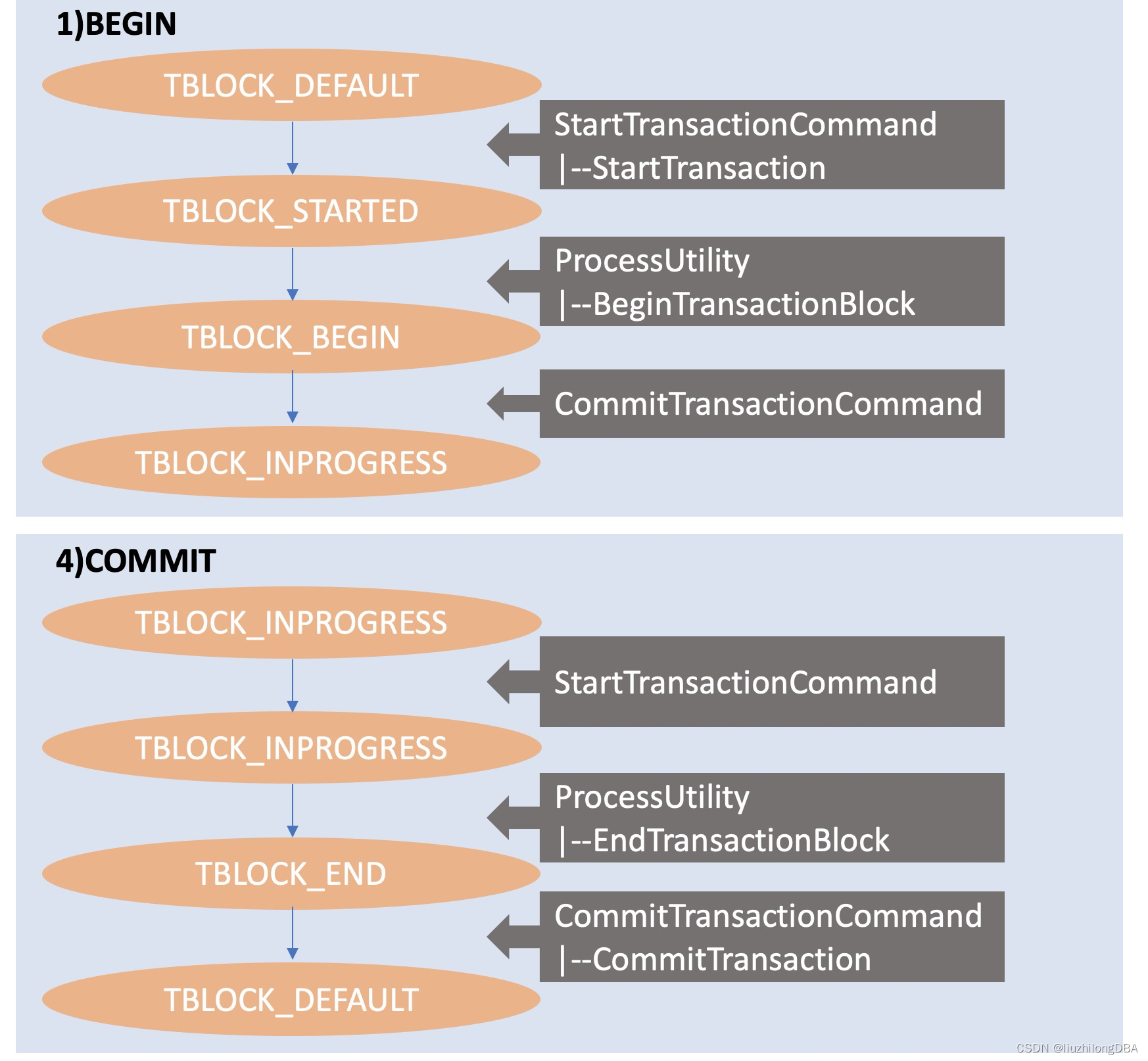
事务函数参考#
《postgresql技术内幕》 src/backend/access/transam/README
事务ID#
pg中每个事务都会分配事务ID,事务ID分为虚拟事务ID和持久化事务ID。pg的事务ID非常重要,是理解事务、数据可见性、事务ID回卷等等的重要知识点。
虚拟事务ID#
只读事务不会分配事务ID,事务ID是很宝贵的资源,比如简单的select语句不会申请事务ID。本身不需要把事务ID持久化到磁盘,但是为了在共享锁等情况下对事务进行标识,需要一种非持久化的事务ID,这个就是虚拟事务ID(vxid)
VXID由两部分组成:backendID 和backend本地计数器。
源码:src/include/storage/lock.h
typedef struct
{
BackendId backendId; /* backendId from PGPROC */
LocalTransactionId localTransactionId; /* lxid from PGPROC */
} VirtualTransactionId;(PGPROC是一种存储进程信息的结构体,后面会介绍)
pg_locks可以看到vxid,查询pg_locks本身就是一个sql,会产生vxid
lzldb=# begin;
BEGIN
lzldb=*# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/16 | AccessShareLock
virtualxid | 4/16 | 4/16 | ExclusiveLock
(2 rows)
lzldb=*# savepoint p1;
SAVEPOINT
lzldb=*# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/16 | AccessShareLock
virtualxid | 4/16 | 4/16 | ExclusiveLock
lzldb=*# rollback;
ROLLBACK
lzldb=# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/17 | AccessShareLock
virtualxid | 4/17 | 4/17 | ExclusiveLock此时\q退出会话再立即登录,计数仍然继续4/19
另开一个窗口,backendID+1
lzldb=# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 5/3 | AccessShareLock
virtualxid | 5/3 | 5/3 | ExclusiveLock从以上测试能看出:
- VXID的backendID不是真正的进程号PID,也只是一个简单的递增的编号
- VXID的bakendID和命令编号都是递增的
- 子事务没有自己的VXID,他们用父事务的VXID
- VXID也有回卷,不过问题不严重,因为没有持久化,实例重启后VXID从头开始计数
永久事务ID#
32位的TransactionId#
当发生数据变化的事务开始时,事务管理器会为事务分配一个唯一标识TransactionId。TransactionId是32位无符号整型,总共可以存储 2^32=4294967296,42亿多个事务。32位无符号整型能存储的数据范围为:0~2^32-1
3个特殊的事务ID
src/include/access/transam.h中宏定义几个事务ID
#define InvalidTransactionId ((TransactionId) 0)
#define BootstrapTransactionId ((TransactionId) 1)
#define FrozenTransactionId ((TransactionId) 2)
#define FirstNormalTransactionId ((TransactionId) 3)
#define MaxTransactionId ((TransactionId) 0xFFFFFFFF)0 代表无效TransactionID
1 代表启动事务ID,只在初始化数据库时才会使用。比所有正常事务都旧
2 代表冻结事务ID。比所有正常事务都旧
#define TransactionIdIsNormal(xid) ((xid) >= FirstNormalTransactionId)事务ID>=3时是正常事务id。
最大事务ID MaxTransactionId是0xFFFFFFFF=4294967295=2^32-1 所以正常事务id能分配到的范围为:3~2^32-1
64位的FullTransactionId#
事务ID是顺序递增的,PostgreSQL一直使用32位事务ID。在PostgreSQL 7.2之前,当32位事务ID用完时,必须dump然后恢复数据库。而64位的事务ID几乎是用不完的。源码中定义64位FullTransactionId为结构体
/*
*一个64位的值,包含一个epoch和一个TransactionId。它被封装在一个结构中,以防止隐式转换为TransactionId。
*并非所有值都表示有效的正常XID。
*/
typedef struct FullTransactionId
{
uint64 value;
} FullTransactionId;由上面的源码可知,64位的由epoch和32位的TransactionId组成,通过以下函数转化
#define EpochFromFullTransactionId(x) ((uint32) ((x).value >> 32))
#define XidFromFullTransactionId(x) ((uint32) (x).value)epoch是FullTransactionId右移32位,xid(TransactionId)是FullTransactionId取模。这相当于把32位的TransactionId看成“环”,循环重复使用;64位的FullTransactionId是一直递增的“线”,几乎取不完。
full的事务id可以超过2^32:
事务ID分配#
做几个小实验来看下事务id是怎么分配的。其中用到两个返回事务id的function
pg_current_xact_id ():返回当前事务id,如果当前事务还没有分配事务id,那么分配一个事务id。pg12及以前用txid_current ()
pg_current_xact_id_if_assigned () :返回当前事务id,如果当前事务还没有分配事务id,那么返回NULL。pg12及以前用txid_current_if_assigned ()
事务id顺序分配
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
612
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
613
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
614begin不会立即分配事务id
lzldb=# begin; --显示开启事务
BEGIN
lzldb=*# select pg_current_xact_id_if_assigned () ; --begin不会立即分配事务id
pg_current_xact_id_if_assigned
--------------------------------
(1 row)
lzldb=*# select * from lzl1; --begin后立即查询
a
---
(0 rows)
lzldb=*# select pg_current_xact_id_if_assigned () ; --查询不会分配事务id
pg_current_xact_id_if_assigned
--------------------------------
(1 row)
lzldb=*# insert into lzl1 values(1); --插入数据,做一个数据变更
INSERT 0 1
lzldb=*# select pg_current_xact_id_if_assigned () ; --begin后的第一个非查询语句分配事务id
pg_current_xact_id_if_assigned
--------------------------------
611
lzldb=*# commit;
COMMIT
lzldb=# select xmin, pg_current_xact_id_if_assigned () from lzl1; --insert事务写入到xmin
xmin | pg_current_xact_id_if_assigned
------+--------------------------------
611 系统表中的有些记录,在数据库初始化时分配了BootstrapTransactionId=1
postgres=# select xmin,count(*) from pg_class where xmin=1 group by xmin;
xmin | count
------+-------
1 | 184以上实验得出以下结论
- 数据库初始化时分配特殊事务id 1,可以在系统表中看到
- 事务id是递增分配的
- begin不会立即分配事务id,begin后的第一个非查询语句分配事务id
- 当一个事务插入了一tuple后,会将事务的txid写入这个tuple的xmin。
事务ID对比#
pg事务新旧通过事务ID来对比。在src/backend/access/transam/transam.c定义了4种事务ID对比函数,分别是<,<=,>,>=
bool TransactionIdPrecedes()
bool TransactionIdPrecedesOrEquals()
bool TransactionIdFollows()
bool TransactionIdFollowsOrEquals()内容都差不多,拿TransactionIdPrecedes()代表来看
bool
TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}该段源码的知识点
TransactionIdIsNormal()是已经在header中宏定义了的判断正常事务的函数,FirstNormalTransactionId是常量3。也就是说正常事务ID是>=3的
#define TransactionIdIsNormal(xid) ((xid) >= FirstNormalTransactionId)- int32是有符号的整型,第一位0表示正数,第一位-1表示负数,取值范围-2*31~2^31-1
- 数值溢出,意思数值超过数据存储范围,比如2^31对于int32是刚好数值溢出的。为了保证数据在范围内,对数值加减模长
对比事务ID源码分为2段理解
非正常事务ID对比:
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);当id1=2,id2=100时,return(2<100),precede为真,正常事务较新
当id1=100,id2=2时,return (100<2),precede为假,正常事务较新
所以,txid为1、2时比正常事务要旧
正常事务ID对比:
diff = (int32) (id1 - id2);
return (diff < 0);id1-id2可以是负数,所以diff不能是unsign int,转换有符号型的int。然后最关键的来了
由于int32是-2*31~2^31-1,
当id1=2^31+99,id2=100,id1-id2=2^31-1。这没问题,int32刚好可以存放 =>大txid较新
当id1=2^31+100,id2=100,id1-id2=2^31。这有问题,刚好超出int32存储范围,此时的值为2^31-2^32=-2^31<0 =>小txid较新
当id1=100,id2=2^31+100,id1-id2=-2^31。这没问题,int32刚好可以存放 =>大txid较新
当id1=100,id2=2^31+101,id1-id2=-2^31-1。这有问题,刚好超出int32存储范围,此时的值为-2^31-1+2^32=2^31-1>0 =>小txid较新
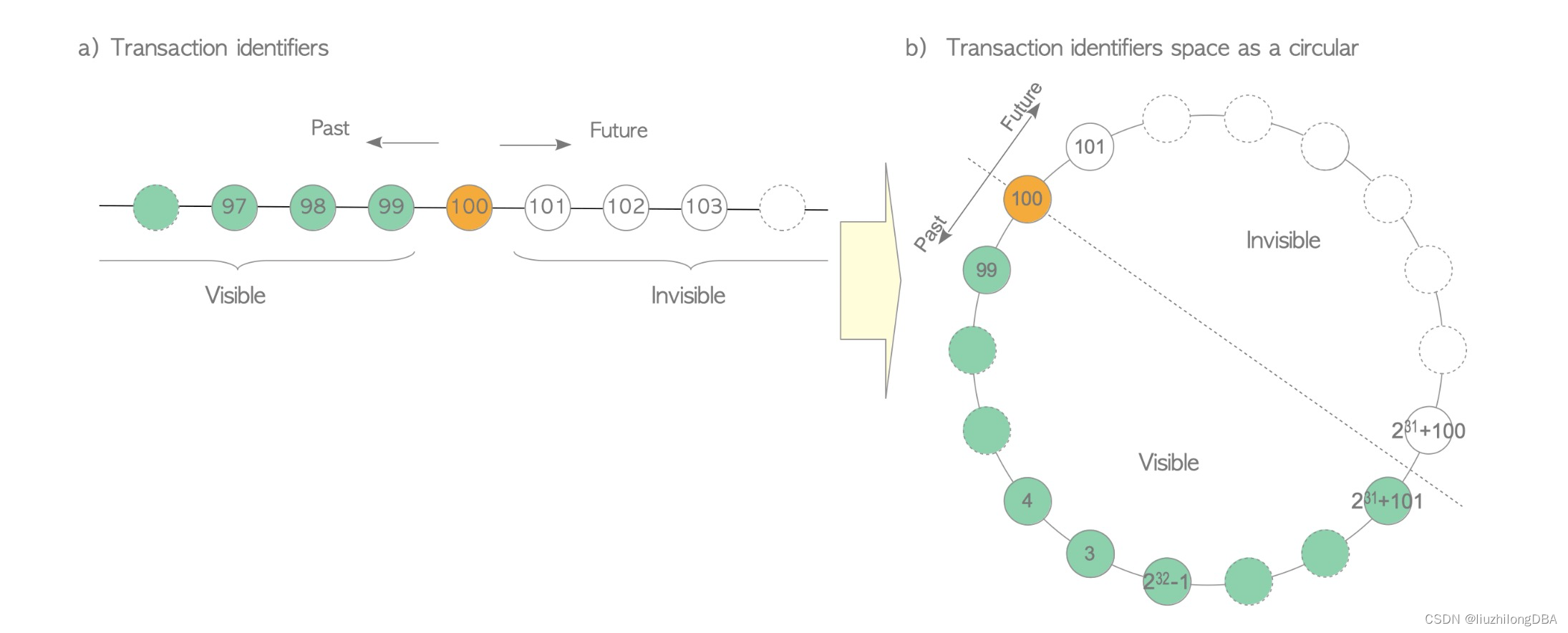
以上分析可以看出,当发生数值溢出时,txid大的事务看不见更小的txid事务,本身数值溢出是一个异常事件,这无可厚非。为了解决这个问题,pg将40亿事务id分成两半,一半事务是可见的,另一半事务是不可见的。
比如,txid 100的事务,它过去的20亿事务是它可见的,它未来的20亿事务是它不可见的。所以,在pg数据库中最大事务和最小事务(数据库年龄)之差最大为|-2^31|=2^31,20亿左右
事务ID回卷#
什么是事务ID回卷?
理解事务ID回卷本身不难,但是刚开始了解回卷时,发现了事务ID回卷有两种定义:
pg官方定义:
由于事务ID的大小有限(32位),一个长时间运行的集群(超过40亿个事务)将遭遇事务ID的回卷:XID计数器回卷到零,突然之间,过去的事务似乎在未来,这意味着它们变得不可见。简而言之,就是灾难性的数据丢失。(事实上,数据仍然存在,但如果你无法获得数据。)
interdb解释:
元组中t_xmin记录了当前元组的最小事务,如果这个元组一直没有变化,这个t_xmin不会变。假如一个元组tuple_1由txid=100事务创建,它的t_xmin=100。如果数据库事务向前推进了2^31个,到了2^31+100,此时tuple_1是可见的。此时再启动一个事务,txid推进至2^31+101,txid=100的事务属于未来,tuple_1是不可见的,此时便发生了严重的数据丢失问题,这就是事务回卷。
是的,对事物回卷的定义,官方文档与有些经典文章不太一样,他俩确实是在说两个事情。我把这个当成是翻译问题:他俩的行为在英语语义里面都是wraparound。如果重新思考“回卷”(wraparound)的含义,其实它俩都是回卷。
不过回卷形式还是有些区别:前者是事务ID(2^32)全部用完,回卷到0重新计数;后者是把事务ID分成两半,“最老的事务ID“与”最新的事务ID“只差大于2^31。
- pg官方定义的事务id回卷是为了引出“事务ID是一个环”这个概念
- 一般认为的事务id回卷问题 ,是“把环分成两半,一半为可见,一半为不可见”这个概念,出现“超过一半”的事务id就是事务id回卷
实际上真正需要关心的回卷问题是后者:最新和最旧的事务id相差不能超过21亿(2^31)。
21亿事务到底要跑多久?
21亿个事务看上去是挺多,但是仍然可能用完。
比如一个tps为100的pg库(不算select语句,因为单纯的select不会分配事务id),1天会使用8640000个事务,只需要历时2147483648/8640000≈248天就可以把21亿个事务id耗尽发生事务回卷;如果每秒1000个事务,不到1个月时间就可以把21亿事务id用完。所以事务回卷问题是pg数据库中必须要关注的。
事务id冻结#
为了解决事务回卷引起严重的数据丢失问题,pg引入事务冻结的概念。
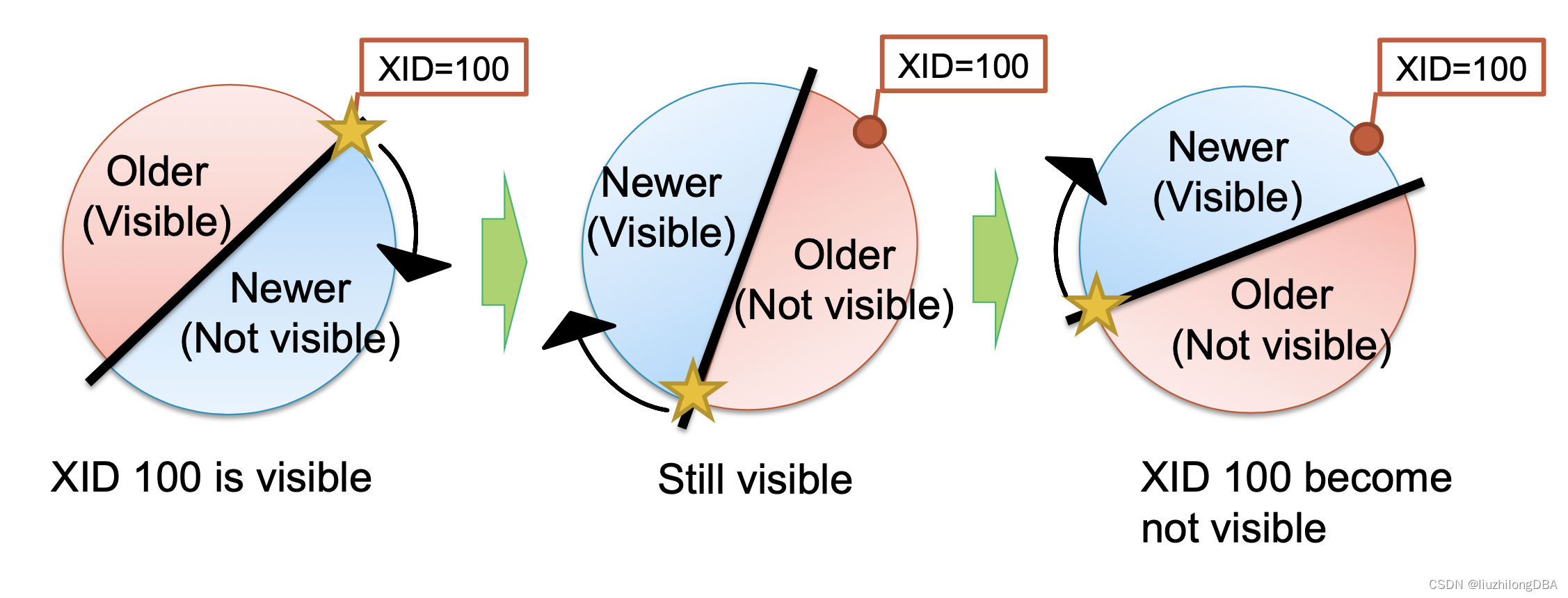
xid会循环使用,并分成2半,一半可见一半不可见。如xid=100的元组,如果不经过任何操作,事务id一直往前推进,那么这个可见的元组最终将不可见。
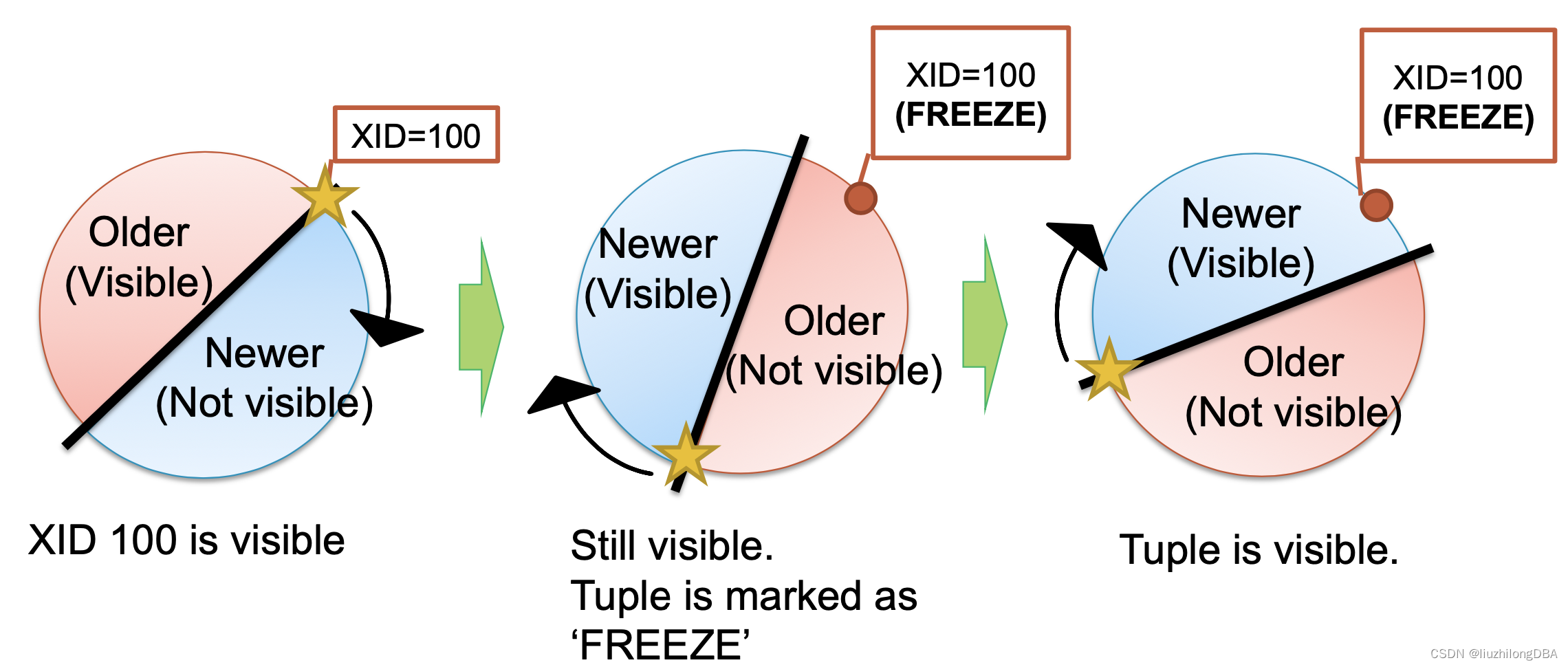
之前介绍有个冻结事务id,此时给xid=100的元组标记为冻结事务id,那么他将仍然可见。
这个就是事务冻结的作用。
事务id FrozenTransactionIdn=2,并且比所有正常事务都旧。也就是说txid=2对于所有正常事务(txid>=3)都是可见的。当t_xmin比当前txid-vacuum_freeze_min_age(默认5000w)更旧时,该元组将重写为冻结事务id 2。在9.4及以后的版本,用t_infomask中的xmin_frozen来表示冻结元组,而不是重写t_xmin为2。
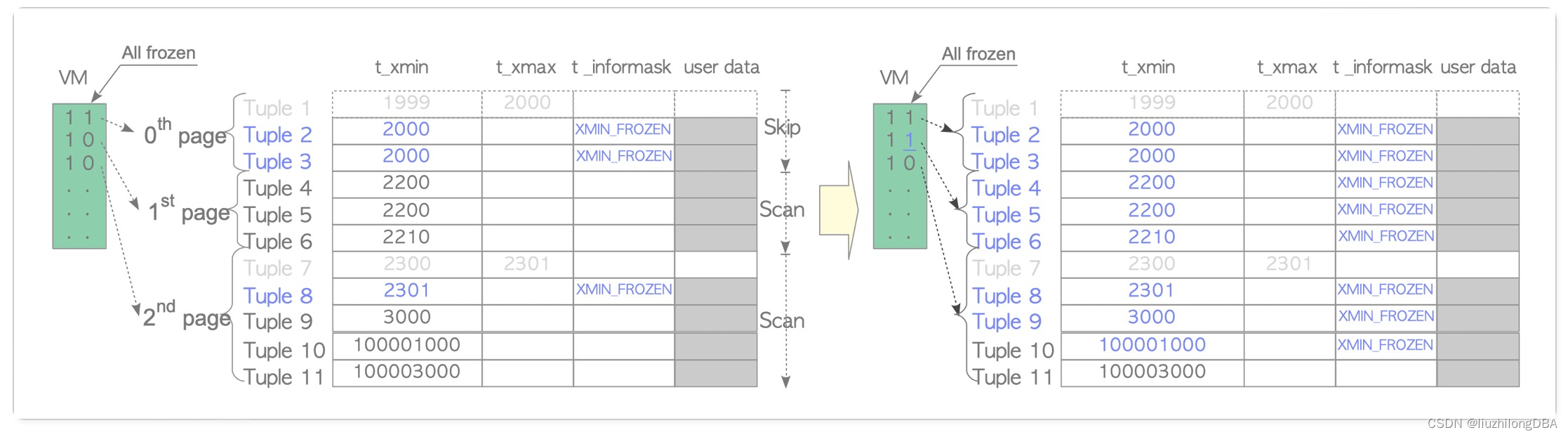
事务ID回卷问题有许多优化方案,不过都绕不过事务冻结处理回卷问题,而事务冻结这个操作,会有非常大的IO消耗以及cpu消耗(所有表的所有行读一遍,重置标记)无从避免回卷,甚至数据库会拒绝所有操作,直至冻结操作结束,这也是俗称的“冻结炸弹”。业务系统越繁忙,事务越多的库,越容易触发。(后面再开章节展开事务冻结优化)
64位的事务id#
事务id耗尽回卷问题终极解决方案就是使用64位的事务ID。32位事务id有2^32个,64位事务id有2^64个。即使每秒10000个事务,每天864000000个事务,也要5849万年才能把事务id消耗光。如果拥有64位事务id,事务id几乎是取之不尽用之不竭,就不需要考虑事务id回卷问题,也不需要事务冻结操作,也就没有“冻结炸弹”的概念…
为什么还没有实现64位事务id?
请注意,64为事务id已经在pg库中了(就像前面介绍的FullTransactionId)。但因为元组存储结构有限,元组中的xmin、xmax等等仍然用的是32位的XID,事务id对比大小仍然依赖32位的XID。xmin,xmax可以简单理解为插入事务和删除事务的事务id,保存在每个元组的header中(元组结构章节将介绍该部分内容),而header空间是有限的。32位事务id有8个字节,64位事务有16个字节,存储xmin、xmax两个事务id将需要额外的16字节空间,目前header无法保存这么大的数据。社区讨论过两种实现方案
1.扩展header。直接将64位事务id存储进去
2.header大小不变。内存中保留64位事务id,增加epoch概念来位移转换两者的关系。
第一种方案已基本放弃,对比其他系统,pg的tuple header已经够大了。
第二种方案epoch已经有了,fulltransactionid转换transactionid已经有了,怎么把元组中的transactionid转换为fulltransactionid是关键(不过怎么也得多一些存储来保存epoch吧,不然怎么实现?)
参考社区邮件
https://www.postgresql.org/message-id/flat/DA1E65A4-7C5A-461D-B211-2AD5F9A6F2FD%40gmail.com
2014年社区就提出了64位事务永久解决freeze问题,并于2017年开始讨论如何实践64位事务id,不过经过了多个pg版本也只是只闻其声不见其人。由于数据库对于数据的敏感性和重要性,而事务id的改造对于数据库来说牵扯的东西太多,稍微不注意可能导致数据丢失或者触发未知bug,64位事务id改造的问题pg走的很谨慎。不过社区还是在考虑这个问题,期待有一天在某个pg版本中事务id回卷问题彻底解决。
事务id参考#
《Postgresql指南 内幕探索》 https://www.interdb.jp/pg/pgsql05.html https://www.interdb.jp/pg/pgsql06.html https://www.slideshare.net/masahikosawada98/introduction-vauum-freezing-xid-wraparound?from_action=save https://www.modb.pro/db/427012 https://www.modb.pro/db/377530 https://www.postgresql.org/docs/13/routine-vacuuming.html https://blog.csdn.net/weixin_30916255/article/details/112365965 https://wiki.postgresql.org/wiki/FullTransactionId https://www.bookstack.cn/read/aliyun-rds-core/bd7e1c1955b35f7d.md https://github.com/digoal/blog/blob/master/201605/20160520_01.md
事务相关的元组结构#
元组结构中包含很多pg的mvcc所必要的信息,下面的内容将梳理xmin,xmax,t_ctid,cmin,cmax,combo cid,tuple id的含义和关系
物理结构#

HeapTupleHeaderData相当于tuple的header,其结构在src/include/access/htup_details.h中定义
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* 插入事务的ID */
TransactionId t_xmax; /* 擅长或锁定事务的ID */
union
{
CommandId t_cid; /* 插入或删除的命令ID */
TransactionId t_xvac; /* VACUUM FULL的事务ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
...
} DatumTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* 当前元组或更新元组的TID */
...
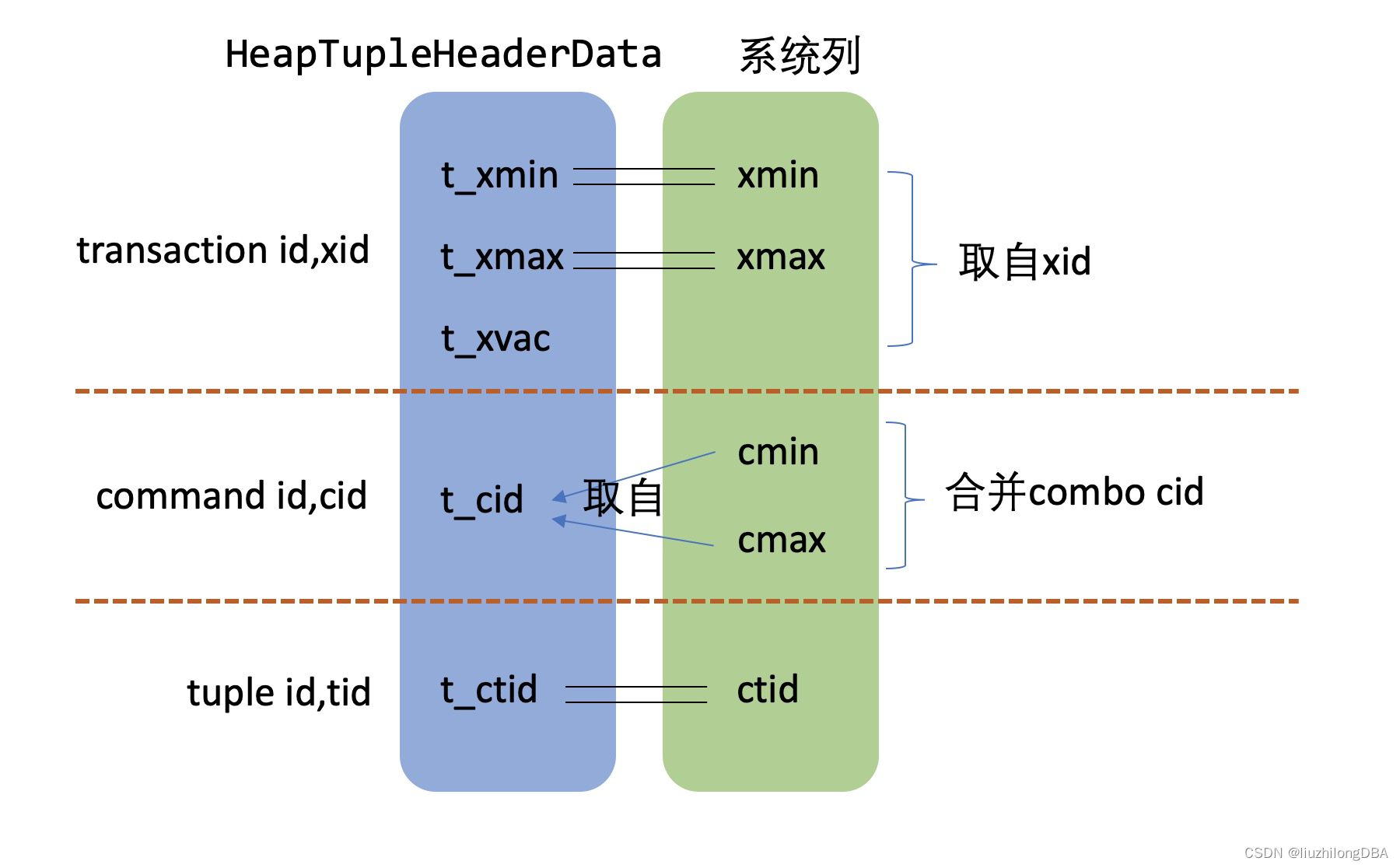
};HeapTupleHeaderData中有5个定义对MVCC及其重要。其中x代表transaction,c代表command,t代表tuple,便于分类理解
t_xmin:表示插入该元组的事务IDt_xmax:表示删除该元组的事务ID或者回滚事务ID。如果没有被删除或更新元组,xmax是0;如果删除或更新元组后回滚,xmax是回滚事务ID。t_xvac:元组被vacuum时设置的xid,此时元组已脱离了原来的事务t_cid:表示命令标识(command id,cid),一个事务可以包含多个SQL,事务中的命令从0开始编号,cid依次递增。CommandId是uint32类型,最大支持2^32 - 1个命令,为了节省资源,而且查询不会影响行的事务顺序,查询不会增加cid(这点类似事务id分配)t_ctid:保存指向自身或新元组标识符(tid),tid是标识表中元组的,是元组的物理地址。如果一条记录被修改多次,那么该记录会存在多个版本。各个版本通过t_cid串联,形成一个版本链。通过这个版本链,可以找到最新的版本
系统列#
每个元组都有6个系统列(每个tuple都有,可以直接查到),它们是tableoid,xmin,xmax,cmin,cmax,ctid 。tableoid是表的oid,在查询和dml时是不会变化的,这里重点讲其余5个系统列
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
616 | 619 | 0 | 0 | (0,3)cmin:插入元组的cid,command idcmax:删除元组的cid,command id
其中xmin,xman,xvac是物理存储的,定义在struct HeapTupleFields中,但是cmin和cmax没有定义在HeapTupleFields结构体中的,结构体有关于command的t_cid,cmin、cmax就是从t_cid取数
cmin,cmax的源码还是在src/include/access/htup_details.h中
/* SetCmin is reasonably simple since we never need a combo CID */
#define HeapTupleHeaderSetCmin(tup, cid) \
do { \
Assert(!((tup)->t_infomask & HEAP_MOVED)); \
(tup)->t_choice.t_heap.t_field3.t_cid = (cid); \
(tup)->t_infomask &= ~HEAP_COMBOCID; \
} while (0)
/* SetCmax must be used after HeapTupleHeaderAdjustCmax; see combocid.c */
#define HeapTupleHeaderSetCmax(tup, cid, iscombo) \
do { \
Assert(!((tup)->t_infomask & HEAP_MOVED)); \
(tup)->t_choice.t_heap.t_field3.t_cid = (cid); \
if (iscombo) \
(tup)->t_infomask |= HEAP_COMBOCID; \
else \
(tup)->t_infomask &= ~HEAP_COMBOCID; \
} while (0)
/*
* HeapTupleHeaderGetRawCommandId will give you what's in the header whether
* it is useful or not. Most code should use HeapTupleHeaderGetCmin or
* HeapTupleHeaderGetCmax instead, but note that those Assert that you can
* get a legitimate result, ie you are in the originating transaction!
*/
#define HeapTupleHeaderGetRawCommandId(tup) \
( \
(tup)->t_choice.t_heap.t_field3.t_cid \
)combocid#
在8.3以前cmin和cmax是分开的。后来考虑到同事务对一条数据既插入又删除的情况比较少,而且事务结束后cmin、cmax都不需要,同时为了节省header空间,cmin、cmax合并到一起称为combo command id即combocid
combocid源码位置src/backend/utils/time/combocid.c
/* Key and entry structures for the hash table */
typedef struct
{
CommandId cmin;
CommandId cmax;
} ComboCidKeyData;
/* comboid的结构为cmin和cmax*/
static CommandId
GetComboCommandId(CommandId cmin, CommandId cmax)
{
...
/*
* 当第一次使用到combo cid时才会生成hash表
*/
if (comboHash == NULL)
{
HASHCTL hash_ctl;
/* 生成数组、hash表 */
comboCids = (ComboCidKeyData *)
MemoryContextAlloc(TopTransactionContext,
sizeof(ComboCidKeyData) * CCID_ARRAY_SIZE);
sizeComboCids = CCID_ARRAY_SIZE;
usedComboCids = 0;
memset(&hash_ctl, 0, sizeof(hash_ctl));
...
comboHash = hash_create("Combo CIDs",
CCID_HASH_SIZE,
&hash_ctl,
HASH_ELEM | HASH_BLOBS | HASH_CONTEXT);
}
...
}combocid存放在hash表中。当事务第一次使用combocid时,会在内存中开辟一小块地方存放combocid。
所以这几个command id的关系和调用过程:combocid->(cmin,cmax)->(t_ctid,t_ctid)
简单的事务相关id和系统列关系#
看了这么多id和源码,似乎有点乱。为了便于理解和记忆,梳理一下这些事务id、command id、tuple id的关系
事务的初步体验#
在没有工具和插件的条件下,初步体验一下这几个系统列在事务中的变化
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
622 | 0 | 0 | 0 | (0,1)
lzldb=# begin ;
BEGIN
lzldb=*# update lzl1 set a=2;
UPDATE 1
--更新后,xmin+1,ctid+1,这里其实出现了新的tuple
lzldb=*
select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
623 | 0 | 0 | 0 | (0,2)
lzldb=*# rollback;
ROLLBACK
--xmax会记录回滚事务id
--xmin,ctid又回到了旧值,其实旧tuple不怎么变化
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
622 | 623 | 0 | 0 | (0,1)
lzldb=# update lzl1 set a=2;
UPDATE 1
--再次更新,tuple号跳过了2,直接到3
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
624 | 0 | 0 | 0 | (0,3)元组header与事务#
pageinspect插件#
直接看行的变化是看不到旧的tuple的,所以需要pageinsect插件。pageinsect插件是pg自带的第三方插件,可以展示数据页面的具体内容。为了观察tuple是如何支持事务的,需要用到get_raw_page()和heap_page_items()两个函数。
get_raw_page():返回指定块的二进制值。其中fork有main、fsm、vm、init几个值。main是数据文件主文件,fsm是free space map块文件,vm是可见性映射快文件,init是初始化的块,如果不指定fork默认为main
heap_page_items():显示一个堆页面上的所有行指针,即使因为mvcc看不到的行也会被展示。
一般把get_raw_page()当做参数传入heap_page_items()以展示元组的header、pointer信息和数据本身
heap_tuple_infomask_flags:将十进制的infomask,infomask2值转换成其含义(标识),输出2列:所有单标识和联合标识。(infomask后面会介绍)
lzldb=# create extension pageinspect;
CREATE EXTENSION
lzldb=# select t_xmin,t_xmax,t_field3 as t_cid,t_ctid from heap_page_items(get_raw_page('lzl1',0));
t_xmin | t_xmax | t_cid | t_ctid
--------+--------+-------+--------
633 | 0 | 0 | (0,1)lp(line pointer)#
line pointer直译是行指针的意思,实际上是页面中的行指针编号,相当于在页面中标记了一个元组。t_ctid看上去更像是tuple id,但是ctid只是(表的page号,行指针编号)的组合,ctid可以指向下个lp 。 例如对一个元组做一次update,会增加一个元组,新元组的lp编号+1,旧tuple的ctid指向新tuple的lp,新tuple的ctid指向自己
lzldb=# select lp,t_ctid from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid
----+--------
1 | (0,1)
(1 row)
lzldb=# update lzl1 set a=2;
UPDATE 1
lzldb=# select lp,t_ctid from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid
----+--------
1 | (0,2)
2 | (0,2)lp源码在src/include/storage/itemid.h中,ItemIdData结构保存了元组的offset位置,状态,长度
typedef struct ItemIdData
{
unsigned lp_off:15, /* 元组在页面的偏移量 */
lp_flags:2, /* lp的状态 */
lp_len:15; /* 元组的长度 */
} ItemIdData;
typedef ItemIdData *ItemId;*
*
/* lp_off:15代表位域,lp_off占用unsigned中的15位,3个定义加起来总共32位。所以ItemIdData是int类型,4个字节,共32位 */lp_flags定义了4种状态
/*
*lp_flags has these possible states. An UNUSED line pointer is available
*for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* lp没有被使用,元组长度pl_len总是为0 */
#define LP_NORMAL 1 /* lp正在使用,元组长度pl_len总是>0 */
#define LP_REDIRECT 2 /* HOT redirect重定向到其他lp (should have lp_len=0) */
#define LP_DEAD 3 /* dead的lp,可被vacuum */lzldb=# select lp,lp_flags,lp_off,lp_len from heap_page_items(get_raw_page('lzl1',0));
lp | lp_flags | lp_off | lp_len
----+----------+--------+--------
1 | 1 | 8160 | 28infomask#
infomask提供了事务、锁、元组状态等信息,比如提交、终止、锁、HOT信息等等。header中有两个infomask:infomask和infomask2。他们存储的信息有所不同
infomask,infomask2#
infomask源码还是在src/include/access/htup_details.h
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */infomask的标识含义#
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* 元组中是否有null值 */
#define HEAP_HASVARWIDTH 0x0002 /* 元组是否是变长的,如varchar类型 */
#define HEAP_HASEXTERNAL 0x0004 /* 是否有toast存储 */
#define HEAP_HASOID_OLD 0x0008 /* 元组是否有OID */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* 元组是否有for key-share锁 */
#define HEAP_COMBOCID 0x0020 /* t_cid是否是comboCID */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* 元组是否有for update锁 */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax只起锁作用 */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin对应的插入元组的事务已提交 */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin对于的插入元组的事务无效或终止 */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax对于的删除元组的事务是否提交 */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax对于的删除元组的事务无效或终止 */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax是否使用MultiXactId */
#define HEAP_UPDATED 0x2000 /* 该元组是数据行被更新后的版本 */
#define HEAP_MOVED_OFF 0x4000 /* 被 9.0 之前的 VACUUM FULL 移动到另外的地方,为了兼容二进制程序升级而保留 */
#define HEAP_MOVED_IN 0x8000 /* 与 HEAP_MOVED_OFF 相对,表明是从别处移动过来的,也是为了兼容性而保留 */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* 可见性相关位 */infomask2的标识含义#
#define HEAP_NATTS_MASK 0x07FF /* 有11位用来保存元组的列的数量,(MaxHeapAttributeNumber用户的列长度是1600个)*/
/* bits 0x1800 are available */
#define HEAP_KEYS_UPDATED 0x2000 /* 元组更新或者删除 */
#define HEAP_HOT_UPDATED 0x4000 /* 元组更新后,新元组是HOT */
#define HEAP_ONLY_TUPLE 0x8000 /* HOT tuple */
#define HEAP2_XACT_MASK 0xE000 /* 可见性相关位 */
#define HEAP_TUPLE_HAS_MATCH HEAP_ONLY_TUPLE
/*在 Hash Join 中临时使用的标志,只用于 Hash 表中的 tuple,且不需要可见性信息,所以我们可以用一个可见性标志覆盖他,而不是使用一个单独的位 */infomask的位与位计算#
把16进制转换为2进制,就比较容易理解位所代表的含义
--将16进制的1600转换为2进制
lzldb=# select x'1600'::bit(16);
bit
------------------
0001011000000000infomask:
0000000000000001 0x0001 HEAP_HASNULL
0000000000000010 0x0002 HEAP_HASVARWIDTH
0000000000000100 0x0004 HEAP_HASEXTERNAL
0000000000001000 0x0008 HEAP_HASOID_OLD
0000000000010000 0x0010 HEAP_XMAX_KEYSHR_LOCK
0000000000100000 0x0020 HEAP_COMBOCID
0000000001000000 0x0040 HEAP_XMAX_EXCL_LOCK
0000000010000000 0x0080 HEAP_XMAX_LOCK_ONLY
0000000001010000 0x0050 HEAP_XMAX_SHR_LOCK 位或计算一下(HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)=10|40=50
0000000001010000 0x0050 HEAP_LOCK_MASK 位或计算一下(HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)=50|40|10=50
0000000100000000 0x0100 HEAP_XMIN_COMMITTED
0000001000000000 0x0200 HEAP_XMIN_INVALID
0000001100000000 0x0300 HEAP_XMIN_FROZEN 位或计算一下(HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)=100|200=300
0000010000000000 0x0400 HEAP_XMAX_COMMITTED
0000100000000000 0x0800 HEAP_XMAX_INVALID
0001000000000000 0x1000 HEAP_XMAX_IS_MULTI
0010000000000000 0x2000 HEAP_UPDATED
0100000000000000 0x4000 HEAP_MOVED_OFF
1000000000000000 0x8000 HEAP_MOVED_IN
1100000000000000 0xC000 HEAP_MOVED 位或计算一下(HEAP_MOVED_OFF | HEAP_MOVED_IN)=4000|8000=C000
1111111111110000 0xFFF0 HEAP_XACT_MASKinfomask2:
0000011111111111 0x07FF HEAP_NATTS_MASK pg库的列最多有1600个=0000011001000000,所以前11位保存元组列足够
0001100000000000 0x1800 available位,看上去是空闲不用的
0010000000000000 0x2000 HEAP_KEYS_UPDATED
0100000000000000 0x4000 HEAP_HOT_UPDATED
1000000000000000 0x8000 HEAP_ONLY_TUPLE
1110000000000000 0xE000 HEAP2_XACT_MASK怎么计算infomask?#
infomask的标识是16进制,pageinspect插件查infomask出来的是10进制。需要to_hex(),10进制转换为16进制的函数 ,做一个转换
lzldb=# select lp,t_ctid,to_hex(t_infomask) infomask,to_hex(t_infomask2) infomask2 from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid | infomask | infomask2
----+--------+----------+-----------
1 | (0,1) | 2b00 | 1infomask=2b00,还是有点转不过来,转成16进制有点难凑,转成二进制对着上面的位含义再凑一下0010101100000000=HEAP_UPDATED+HEAP_XMAX_INVALID+HEAP_XMIN_FROZEN
其含义为:标识元组更新过,xmax为invalid也就是0,xmin frozen对所有事务可见
infomask2=1,二进制的前11位,十进制的前2047(最多1600列),都是代表用户列的个数,所以1代表只有1个列
手动算infomask有点麻烦,从pg13开始pageinspect提供了函数heap_tuple_infomask_flags转换infomask,infomask2的含义。有单独位标识的是raw flag,联合多个位标识的是combined_flags
lzldb=# SELECT t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('lzl1', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+------------------------------------------------------------------------+--------------------
(0,1) | {HEAP_XMIN_COMMITTED,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID,HEAP_UPDATED} | {HEAP_XMIN_FROZEN}提交日志clog#
pg用提交日志(commit log,clog)来保存事务状态。pg会在事务完成前就将事务写进wal日志,这也是wal的含义。如果终止事务,将事务状态写进wal和clog,在实例恢复时,也能知道事务是没有完成提交的。
在需要获取事务状态时,比如判断事务可见性时,pg会读取clog的事务状态。
事务状态
源码src/include/access/clog.h
#define TRANSACTION_STATUS_IN_PROGRESS 0x00
#define TRANSACTION_STATUS_COMMITTED 0x01
#define TRANSACTION_STATUS_ABORTED 0x02
#define TRANSACTION_STATUS_SUB_COMMITTED 0x03clog中事务定义了4种状态:IN_PROGRESS,COMMITTED,ABORTD,SUB_COMMITTED
事务状态大小
源码src/backend/access/transam/clog.c
/* We need two bits per xact, so four xacts fit in a byte */
#define CLOG_BITS_PER_XACT 2
#define CLOG_XACTS_PER_BYTE 4
#define CLOG_XACTS_PER_PAGE (BLCKSZ * CLOG_XACTS_PER_BYTE)
#define CLOG_XACT_BITMASK ((1 << CLOG_BITS_PER_XACT) - 1)事务状态非常小,一个事务只需要2位,1字节可以保存4个事务状态 一个标准的page可以保留 8K*4=32768个事务状态 clog持久化 pg关库或落盘时,clog数据会写入pg_clog目录下,在10.0及以后的版本,pg_clog重命名为pg_xact。
[pg@lzl pg_xact]$ ll
total 8
-rw------- 1 pg pg 8192 Mar 28 23:33 0000磁盘上的clog文件命名为0000,0001等。 clog文件大小为256KB,而内存中通过page存储事务为8K,所以0000文件的大小只会是8192的倍数,当写了32个clog page后,下个page便写入0001文件。PostgreSQL 启动时会从 pg_xact 中读取事务的状态加载至内存。 系统运行过程中,并不是所有事务的状态都需要长期保留在 CLOG 文件中,因此 vacuum 操作会定期将不再使用的 CLOG 文件删除
Hint Bits#
什么是hintbits?#
hint bits是为了标记那些创建或删除的行的事务是否提交或终止。如果没有hint bits,事务可见性需要访问磁盘pg_clog或pg_subtrans,这种访问代价比较昂贵。如果元组被设置了hint bits,那么访问page中的元组,就能知道元组状态,不需要额外的访问。
源码中使用SetHintBits()函数设置hintbits
如
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
InvalidTransactionId);SetHintBits设置的只是infomask中的2位,共4种hint bits(其实这2位infomask还有一个联合标识HEAP_XMIN_FROZEN,能看出来hintbits就是单纯为了标记事务状态的)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin对应的插入或更新事务已提交 */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin对于的插入或更新事务无效或终止 */
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax对于的删除或更新事务是否提交 */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax对于的删除或更新事务无效或终止 */查询会产生写入#
事务开始后,pg的dml事务会在元组header中记录t_min等事务id和事务状态。但事务结束时,不会在header中作任何事情,而是在后面的DML或者DQL,VACUUM等SQL扫描到对应的TUPLE时,触发SetHintBits的操作(产生新快照访问数据时SetHintBits,代码在HeapTupleSatisfiesMVCC()中,后面可见性规则小节会介绍)。
在没有触发SetHintBits之前,pg在clog中寻找事务状态;触发SetHintBits后,在数据页的元组header中找hintbits所代表的事务状态。
例如一个insert语句
lzldb=# insert into lzl1 values(1);
INSERT 0 1
lzldb=# SELECT t_ctid, raw_flags, combined_flags
lzldb-# FROM heap_page_items(get_raw_page('lzl1', 0)),
lzldb-# LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
lzldb-# WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+---------------------+----------------
(0,1) | {HEAP_XMAX_INVALID} | {}
(1 row)
lzldb=# select * from lzl1; --仅做一次查询
a
---
1
(1 row)
lzldb=# SELECT t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('lzl1', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+-----------------------------------------+----------------
(0,1) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {} 一次查询后,t_infomask发生了变化,说明tuple header发生了变化。 在insert后,SetHintBits只有HEAP_XMAX_INVALID,因为insert本身只会更新xmin,无论事物是否提交或终止(退出或rollback)xmax都是没用的,可以随事务一起SetHintBits为HEAP_XMAX_INVALID 但是事务可能提交,也可能终止(退出或rollback),又由于事务完成不会更新元组,所以HEAP_XMIN_COMMITTED不能随事务完成而SetHintBits 在检测事务可见性(heapam_visibility.c)时,可见性检测更新了元组的事务状态SetHintBits到t_infomask中,所以查询更新了HEAP_XMIN_COMMITTED
hintbits优点:事务中数据更新的完成(包括失败),不会对元组产生任何写入。提交和回退会非常快。
hintbits缺点:如果一个事务更新了多行,下一次查询检测可见性时可能会从pg_clog中读取事务状态,并更新非常多的page。
hintbits是否会产生WAL日志?#
在开启 checksum 或者参数 wal_log_hints 为 true 的情况下,如果 checkpoint 后第一次使页面 dirty 的操作是更新 Hint Bits,则会产生一条 WAL 日志,将当前页面写入 WAL 日志中(即 Full Page Image),避免产生部分写,导致数据 checksum 异常。 因此,在开启 checksum 或者 参数 wal_log_hints 为 true 时,即便执行 SELECT,也可能更改页面的 Hint Bits,从而导致产生 WAL 日志,这会在一定程度上增加 WAL 日志占用的存储空间。如果在使用pg中发现执行SELECT会触发磁盘的写入操作,可以检查一下是否开启了CHECKSUM或者wal_log_hints。
hintbits为什么延迟更新?#
源码src/backend/access/heap/heapam_visibility.c里,在可见性规则HeapTupleSatisfiesMVCC()注释中有一段hintbits为什么延迟更新的解释
/*
*插入、删除操作还在跑时,哪怕事务已提交或者回退,都不会更新元组上的hint bits,也就是更新事务状态
*因为在高并发场景下共享数据结构可能会造成争用,而且这也不会影响可见性判断
*hintbits只会发生在首次全新快照访问已完成事务的数据之后
*所以HeapTupleSatisfiesMVCC每次都会运行TransactionIdIsCurrentTransactionId,XidInMVCCSnapshot,以判断是否当前事务的元组
*在老版本中,pg尝试立即更新hintbits(即使事务在运行中),但是造成对PGXACT array的更多争用
*/简单点说,hintbits立即更新性能非常差,所以将事务状态先放在clog,减少PGXACT的争用,以提升性能。hintbits延迟更新就造成了后续查询可能会更新元组的情况
元组的增删改#
在积累了元组header、系统列、clog、hintbits等知识点后,我们来看下pg是如何完成增删改操作。
观察DML事务#
通过对lp,lp_flags,ctid,xmin,xmax,cid(cmin,cmax),infomask,infomask2这些元组头部信息,观察pg的DML事务行为 观察这些内容会使用以下sql
select t_ctid,lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('lzl1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;(稍微说下,有些资料里喜欢这样SELECT '(0,'||lp||')' AS ctid,这样写不太合适,lp跟ctid是两码事,lp相当于行号,ctid是指向行号的,lp是可以不等于ctid的)
为了更好的阅读,创建一个view简化一下sql
create view vlzl1 as select t_ctid,lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('lzl1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;查询就像这样
lzldb=# \x
Expanded display is on.
lzldb=# select * from vlzl1;
-[ RECORD 6 ]--+-------
t_ctid | (0,6)
lp | 6
lp_flags | LP_NORMAL
t_xmin | 653
t_xmax | 0
t_cid | 0
raw_flags | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE}
combined_flags | {}插入#
清空数据,insert插入一行
lzldb=# begin ;
BEGIN
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# insert into lzl1 values(2);
INSERT 0 1
lzldb=*# commit;
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 664 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 664 | 0 | 1 | {HEAP_XMAX_INVALID} | {}ctid指向(page 0,lp 1),也就指向自身 lp,line pointer行指针编号,递增 2个元组xmin是同一个事务,表示2个元组是一个事务插入 xmax为0表示无效事务ID,infomask也仅说明xmax无效,该元组还没有"经历"删除事务 cid从0开始递增,0代表事务第一个command,1代表事务第二个command
删除#
lzldb=# begin;
BEGIN
lzldb=*# delete from lzl1 where a=1;
DELETE 1
lzldb=*# commit;
COMMIT
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 664 | 665 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
(0,2) | 2 | LP_NORMAL | 664 | 0 | 1 | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}删除了第一个元组,元组没有物理上删除,只是几个属性打了标记 ctid未变还是指向自身 xmax更新为删除事务id infomask标识有HEAP_KEYS_UPDATED表示元组删除了(实际上HEAP_KEYS_UPDATED的有删除或更新的意思) 虽然只更新了第一个元组,但是第二个元组更新了infomask HEAP_XMIN_COMMITTED
更新#
lzldb=# begin;
BEGIN
lzldb=# update lzl1 set a=3;
UPDATE 1
lzldb=*# commit;
COMMIT
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-------------------------------------------------------------+----
(0,1) | 1 | LP_NORMAL | 664 | 665 | 0 | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_KEYS_UPDATED} | {}
(0,3) | 2 | LP_NORMAL | 664 | 666 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 666 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}更新事务不会再元组上操作,而是将老元组标识为不可用,新增一个新元组 lp=2 为更新事务的老元组,t_xmax更新为更新事务id,infomask增加标识HEAP_HOT_UPDATED,表示该元组是hot,ctid指向了新元组 lp=3 为更新事务的新元组,相当于插入了一个新元组,不过xmin事务id跟老元组xmax一致,并且infomask有额外标识HEAP_UPDATED表示该元组是update后的row 另外,一个看不见的被删除的元组 lp=1,在不相关的更新事务发生后,infomask增加了标识HEAP_XMAX_COMMITTED
回退#
lzldb=# truncate table lzl1;
TRUNCATE TABLE
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(1); --插入
INSERT 0 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 679 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
(1 row)
lzldb=*# rollback; --插入回退
ROLLBACK
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 679 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
lzldb=# select * from lzl1;
a
---
(0 rows)
--插入后回退,元组header信息没有任何变化
lzldb=# insert into lzl1 values(2);
INSERT 0 1
lzldb=# begin ;
BEGIN
lzldb=*# delete from lzl1 ; --删除
DELETE 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 685 | 686 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
(2 rows)
lzldb=*# rollback; --删除回退
ROLLBACK
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 685 | 686 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
--删除后回退,元组header信息没有任何变化
lzldb=*# update lzl1 set a=100 ; --更新
UPDATE 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------+---------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,3) | 2 | LP_NORMAL | 685 | 688 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 688 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
(3 rows)
lzldb=*# rollback; --更新回退
ROLLBACK
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------+---------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,3) | 2 | LP_NORMAL | 685 | 688 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 688 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
--更新后回退,元组header信息没有任何变化• 事务回退,元组信息不会有任何变化。这也是为什么pg的mvcc不用担心回滚段不够用,因为回滚只是可见性操作,不会更新数据本身 • xmax在回退后也没有变,说明xmax有值不一定代表元组被删除,也可能是删除或更新事务回退了 • 但是,只要产生了可见性检测,哪怕不产生数据变化,所有元组的infomask都会更新HEAP_XMIN_INVALID。其中非HOT元组都加上HEAP_XMIN_INVALID,HOT指向的元组当然也是HEAP_XMIN_INVALID
参考 books: 《postgresql指南 内幕探索》 《postgresql实战》 《postgresql技术内幕 事务处理深度探索》 《postgresql数据库内核分析》 https://edu.postgrespro.com/postgresql_internals-14_parts1-2_en.pdf 官方资料: https://en.wikipedia.org/wiki/Concurrency_control https://wiki.postgresql.org/wiki/Hint_Bits https://www.postgresql.org/docs/current/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND https://www.postgresql.org/docs/10/storage-page-layout.html https://www.postgresql.org/docs/13/pageinspect.html3 pg事务必读文章 interdb https://www.interdb.jp/pg/pgsql05.html https://www.interdb.jp/pg/pgsql06.html 源码大佬 https://blog.csdn.net/Hehuyi_In/article/details/102920988 https://blog.csdn.net/Hehuyi_In/article/details/127955762 https://blog.csdn.net/Hehuyi_In/article/details/125023923 pg的快照优化性能对比 https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/improving-postgres-connection-scalability-snapshots/ba-p/1806462 其他资料 https://brandur.org/postgres-atomicity https://mp.weixin.qq.com/s/j-8uRuZDRf4mHIQR_ZKIEg
pg中的快照#
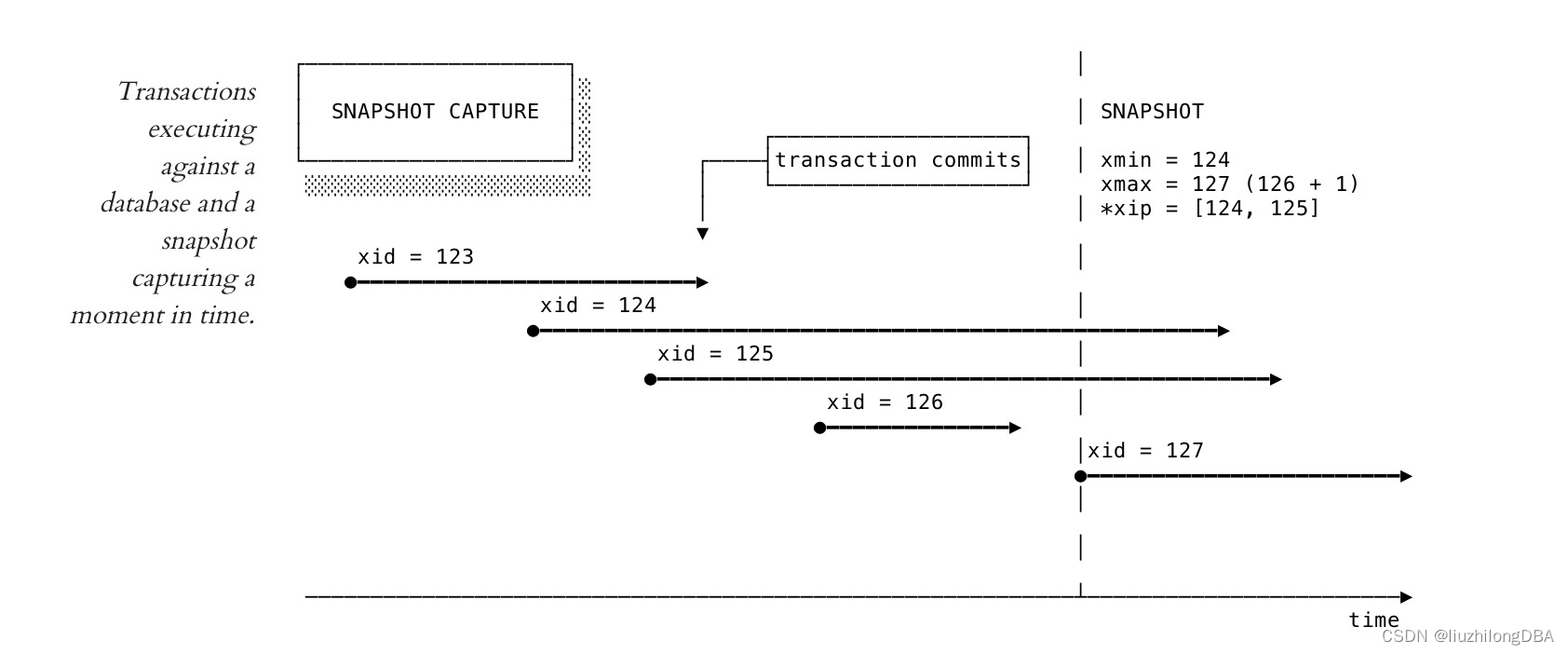
快照(snapshot)是记录数据库当前瞬时状态的一个数据结构。pg数据库的快照保存当前所有活动事务的最小事务ID、最大事务ID、当前活跃事务列表、当前事务的command id等
快照数据保存在SnapshotData结构体类型中,源码src/include/utils/snapshot.h
typedef struct SnapshotData
{
SnapshotType snapshot_type; /* 快照类型 */
TransactionId xmin; /* 事务ID小于xmin,对于快照可见 */
TransactionId xmax; /* 事务ID大于xmax,对于快照不可见 */
/* 获取快照时活跃事务列表。该列表仅包括xmin与xmax之间的txid */
TransactionId *xip;
uint32 xcnt; /* xip_list保存在xip[] */
/* 获取快照时活跃子事务列表 */
TransactionId *subxip;
int32 subxcnt; /* 子事务保存在subxip[] */
bool suboverflowed; /* 子事务是否溢出,子事务较多时会产生溢出 */
bool takenDuringRecovery; /* 是否是恢复快照recovery-shaped snapshot? */
bool copied; /* 这里应该是快照是否是copy的(可重复读和串行化隔离级别,会copy快照)false if it's a static snapshot */
CommandId curcid; /* 事务中的command id,CID< curcid的可见 */
...
TimestampTz whenTaken; /* 生成快照的时间戳 */
XLogRecPtr lsn; /* 生成快照的LSN */
} SnapshotData;
typedef struct SnapshotData *Snapshot;快照中最重要的信息是xmin、xmax、xip_list。通过pg_current_snapshot()(pg12及以前用 txid_current_snapshot () )显示当前事务的快照。
注意区分快照xmin、xmax跟元组上的xmin、xmax,含义是不一样的。
lzldb=*# select pg_current_snapshot();
pg_current_snapshot
---------------------
100:104:100,102| xmin | 最早活跃的txid,所有比他更早的事务txid<xmin,要么提交和可见,要么回滚并成为死元组 |
|---|---|
| xmax | 第一个尚未分配的txid,xmax=latestCompletedXid+1,所有txid>=xmax的事务都未启动并对当前快照不可见 |
| xip_list | xip_list存储在数组xip[]中。因为所有事务开始顺序性和完成顺序不一定是一致的,晚开始的事务可能早完成,所以只有xmin和xmax不能完全表达获取快照时的所有活动事务。xip_list保存获得快照时的活动事务 |
快照类型#
除了mvcc快照以外,pg在src/include/utils/snapshot.h中还定义了一些其他的快照类型
typedef enum SnapshotType
{
/* 当且仅当元组符合mvcc快照可见规则时,元组可见
* 最重要的一种快照事务,是pg用来实现mvcc的快照类型
* 元组可见性基于事务快照的xmin,xmax,xip_list,curcid等信息进行判断
* 如果命令发生了数据变更,当前mvcc快照是看不到的,需要再生成mvcc快照
*/
SNAPSHOT_MVCC = 0,
/* 元组上的事务已提交,则可见
* 进行中的事务不可见
* 命令发生了数据变更,当前self快照可以看见
*/
SNAPSHOT_SELF,
/*
* 任何元组都可见
*/
SNAPSHOT_ANY,
/*
* toast重要是有效的就可见。toast可见性依赖主表的元组可见性
*/
SNAPSHOT_TOAST,
/*
* 命令发生了数据变更,当前dirty快照可以看见
* dirty快照会保存当前进行中元组的版本信息
* 快照xmin会设置成其他进行中事务的元组xmin,xmax类似
*/
SNAPSHOT_DIRTY,
/* HISTORIC_MVCC快照规则与MVCC快照一致,用于逻辑解码
*/
SNAPSHOT_HISTORIC_MVCC,
/*
判断死元组是否对一些事务可见
*/
SNAPSHOT_NON_VACUUMABLE
} SnapshotType;快照与隔离级别#
不同的隔离级别,快照获取方式是不一样的
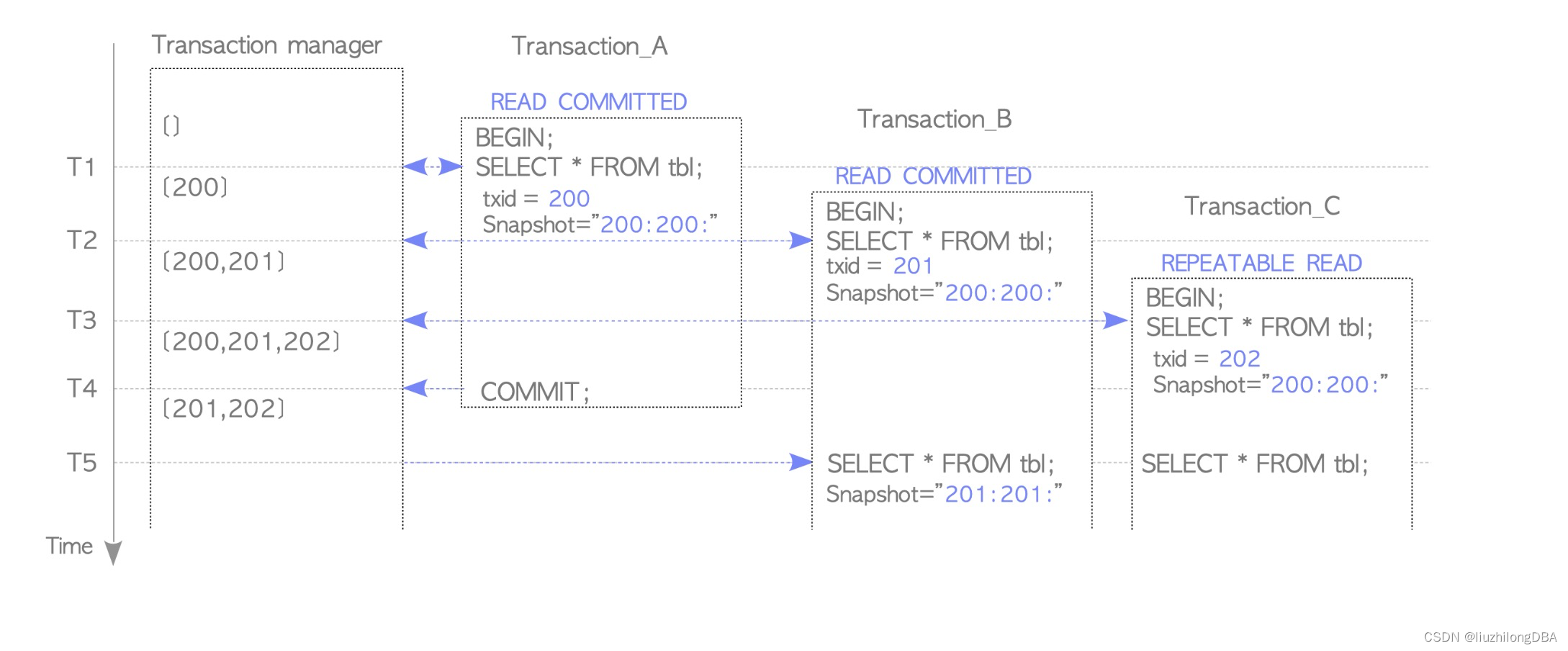
rc模式需要事务中的每个sql都获得快照,而rr模式在事务中只使用一个快照。获得快照的方法在GetTransactionSnapshot()函数中。
进程上的事务结构体#
pg在获得快照数据的时候,需要检索所有backend进程的事务状态。
所以在理解获得快照数据函数GetSnapshotData()之前,需要先理解几个在关于backend process的结构体。这些结构体包括PGPROC、PGXACT、PROC_HDR(PROCGLOBAL)、ProcArray
这些process相关结构体包含一些进程、锁等信息,这里只研究process里事务相关的信息。源码以pg13源码为示例
PGPROC结构体#
源码src/include/storage/proc.h
//每个backend进程在内存中都存储PGPROC结构体
//可以理解为backend进程的主结构体
struct PGPROC
{
...
LocalTransactionId lxid; /* local id of top-level transaction currently
* being executed by this proc, if running;
* else InvalidLocalTransactionId */
...
struct XidCache subxids; /* 缓存子事务XIDs */
...
/* clog组事务状态更新 */
bool clogGroupMember; /* 当前proc是否使用clog组提交 */
pg_atomic_uint32 clogGroupNext; /* 原子int,指向下一个组成员proc */
TransactionId clogGroupMemberXid; /* 当前要提交的xid */
XidStatus clogGroupMemberXidStatus; /* 当前要提交xid的状态 */
int clogGroupMemberPage; /* 当前要提交xid属于哪个page*/
XLogRecPtr clogGroupMemberLsn; /* 当前要提交的xid的commit日志的lsn号 */
};
/* NOTE: "typedef struct PGPROC PGPROC" appears in storage/lock.h. 居然不跟结构体写在一起*/PGXACT结构体#
//在9.2以前,PGXACT的信息在PGPROC中,由于压测显示在多cpu系统中,因为减少了获取的缓存行数,把两者分开GetSnapshotData会更快,
typedef struct PGXACT
{
TransactionId xid; /* id of top-level transaction currently being
* executed by this proc, if running and XID
* is assigned; else InvalidTransactionId */
// 看上是当前进程的xmax
TransactionId xmin; /* 不包括lazy vaccum,事务开始时最小xid,vacuum无法删除xid >= xmin的元组*/
uint8 vacuumFlags; /* vacuum-related flags, see above */
bool overflowed; //PGXACT是否溢出
uint8 nxids;
} PGXACT;能看出pgxact保存的信息比较简单,是backend的xmin、xmax等事务相关信息。而pgproc更倾向于保存backend的基本信息,pgproc中还是有一部分不太频繁调用的事务信息,不过最核心的进程事务信息在pgxact中
PROC_HDR(PROCGLOBAL)结构体#
每个backend process都有proc结构体,很明显在高并发场景下扫描所有proc寻找事务信息比较耗时,这时需要一个实例级别的结构体存储所有proc信息,这个结构体就是PROCGLOBAL**。**
源码一般用结构体类型PROC_HDR定义结构体指针指向PROCGLOBAL。PROC_HDR存储的是全局的proc信息,所有proc数组列表、空闲proc等等
源码位置src/include/storage/proc.h
typedef struct PROC_HDR
{
/* pgproc数组 (not including dummies for prepared txns) */
PGPROC *allProcs;
/* pgxact数组 (not including dummies for prepared txns) */
PGXACT *allPgXact;
...
/* Current shared estimate of appropriate spins_per_delay value */
int spins_per_delay;
/* The proc of the Startup process, since not in ProcArray */
PGPROC *startupProc;
int startupProcPid;
/* Buffer id of the buffer that Startup process waits for pin on, or -1 */
int startupBufferPinWaitBufId;
} PROC_HDR;PROCARRAY结构体#
procarray在procarray.c中,procarray.c是维护所有backend的PGPROC和PGXACT结构的。
源码位置src/backend/storage/ipc/procarray.c
typedef struct ProcArrayStruct
{
int numProcs; /* proc的个数*/
int maxProcs; /* proc array的大小 */
//处理已分配的xid
int maxKnownAssignedXids; /* allocated size of array */
int numKnownAssignedXids; /* current # of valid entries */
int tailKnownAssignedXids; /* index of oldest valid element */
int headKnownAssignedXids; /* index of newest element, + 1 */
slock_t known_assigned_xids_lck; /* protects head/tail pointers */
/*
* Highest subxid that has been removed from KnownAssignedXids array to
* prevent overflow; or InvalidTransactionId if none. We track this for
* similar reasons to tracking overflowing cached subxids in PGXACT
* entries. Must hold exclusive ProcArrayLock to change this, and shared
* lock to read it.
*/
TransactionId lastOverflowedXid;
/* oldest xmin of any replication slot */
TransactionId replication_slot_xmin;
/* oldest catalog xmin of any replication slot */
TransactionId replication_slot_catalog_xmin;
/* pgprocnos,相当于allPgXact[]数组下标,可用于检索allPgXact[],该数组有PROCARRAY_MAXPROCS条目 */
int pgprocnos[FLEXIBLE_ARRAY_MEMBER];
} ProcArrayStruct;
static ProcArrayStruct *procArray;获得快照#
GetTransactionSnapshot()#
通过函数GetTransactionSnapshot()获得快照
源码src/backend/utils/time/snapmgr.c
// GetTransactionSnapshot()为一个事务中的sql分配合适的快照
Snapshot
GetTransactionSnapshot(void)
{
// 如果是逻辑解码,则获得historic类型快照Return historic snapshot if doing logical decoding. We'll never need a
// 因为是逻辑解码事务,后续就不需要再call非historic类型快照了,直接return
if (HistoricSnapshotActive())
{
Assert(!FirstSnapshotSet);
return HistoricSnapshot;
}
/* 如果不是事务的第一次调用,则进入if */
if (!FirstSnapshotSet)
{
/*
* 保证catalog快照是新的
*/
InvalidateCatalogSnapshot();
Assert(pairingheap_is_empty(&RegisteredSnapshots));
Assert(FirstXactSnapshot == NULL);
//如果是并行模式下则返回报错
if (IsInParallelMode())
elog(ERROR,
"cannot take query snapshot during a parallel operation");
//如果是可重复读或串行化隔离级别,则在事务中都使用同一个快照,所以只copy一次
//IsolationUsesXactSnapshot()标识隔离级别为可重复读或串行化,他们的在同事务中只使用一个快照
if (IsolationUsesXactSnapshot())
{
//首先,在CurrentSnapshotData中创建快照
//如果是SI隔离级别,初始化SSI所需的数据结构
if (IsolationIsSerializable())
CurrentSnapshot = GetSerializableTransactionSnapshot(&CurrentSnapshotData);
else
CurrentSnapshot = GetSnapshotData(&CurrentSnapshotData);
/* Make a saved copy */
/* 可重复读或串行化隔离级别,这个快照会贯穿整个事务,所以只复制一次 */
CurrentSnapshot = CopySnapshot(CurrentSnapshot);
FirstXactSnapshot = CurrentSnapshot;
/* Mark it as "registered" in FirstXactSnapshot */
FirstXactSnapshot->regd_count++;
pairingheap_add(&RegisteredSnapshots, &FirstXactSnapshot->ph_node);
}
else
//如果是读已提交隔离级别,获得快照
CurrentSnapshot = GetSnapshotData(&CurrentSnapshotData);
// 修改标记,表示是第一次获得的快照,下次事务再调用该函数,就不会进到这层if了
FirstSnapshotSet = true;
return CurrentSnapshot;
}
//如果不是事务中第一次调用(已经有第一个快照了)
//可重复读或串行化隔离级别,返回第一个快照的复制品
if (IsolationUsesXactSnapshot())
return CurrentSnapshot;
/* Don't allow catalog snapshot to be older than xact snapshot. */
InvalidateCatalogSnapshot();
//读已提交级别,重新获得快照
CurrentSnapshot = GetSnapshotData(&CurrentSnapshotData);
return CurrentSnapshot;
}关于IsolationUsesXactSnapshot()和IsolationIsSerializable()
在src/include/access/xact.h宏定义
#define XACT_READ_UNCOMMITTED 0
#define XACT_READ_COMMITTED 1
#define XACT_REPEATABLE_READ 2
#define XACT_SERIALIZABLE 3
//内部只有3个隔离级别,就是1、2、3
//2个隔离级别在每个事务中用同一快照,其他隔离级别在每个sql语句用一个快照
#define IsolationUsesXactSnapshot() (XactIsoLevel >= XACT_REPEATABLE_READ)
#define IsolationIsSerializable() (XactIsoLevel == XACT_SERIALIZABLE)IsolationUsesXactSnapshot()是可重复读或串行化隔离级别
IsolationIsSerializable()是串行化隔离级别。
GetTransactionSnapshot()函数流程图:
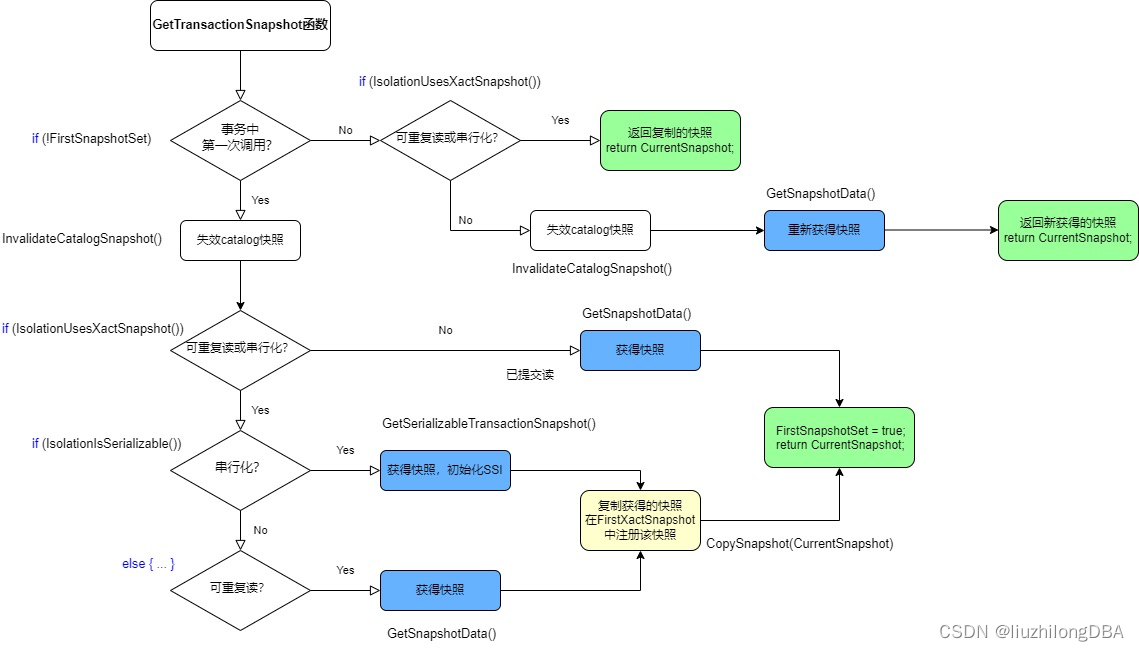 (图片来自csdn https://blog.csdn.net/Hehuyi_In)
(图片来自csdn https://blog.csdn.net/Hehuyi_In)
GetTransactionSnapshot()主要的判断逻辑:
- 逻辑解码时的historic快照直接返回快照结果
- 在可重复读或串行化隔离级别,如果是第一次调用,返回快照并复制,以便下次(既非第一次)直接引用该快照
- 在读已提交隔离级别,每次调用都生成新快照
- 串行化隔离级别的第一次调用,额外获得SSI数据信息
GetTransactionSnapshot()获得快照,其获得快照数据调用的是GetSnapshotData()
GetSnapshotData()#
源码src/backend/storage/ipc/procarray.c
Snapshot
GetSnapshotData(Snapshot snapshot)
{
//先初始化一些变量,包括arrayP指针,procarray,xmin,xmax,复制槽事务id等等
ProcArrayStruct *arrayP = procArray;
TransactionId xmin;
TransactionId xmax;
TransactionId globalxmin;
int index;
int count = 0;
int subcount = 0;
bool suboverflowed = false;
TransactionId replication_slot_xmin = InvalidTransactionId;
TransactionId replication_slot_catalog_xmin = InvalidTransactionId;
Assert(snapshot != NULL);
if (snapshot->xip == NULL)
{
/*
* First call for this snapshot. Snapshot is same size whether or not
* we are in recovery, see later comments.
*/
snapshot->xip = (TransactionId *) //获得当前事务的xip
malloc(GetMaxSnapshotXidCount() * sizeof(TransactionId));
...
Assert(snapshot->subxip == NULL);
snapshot->subxip = (TransactionId *) //获得当前子事务的subxip
malloc(GetMaxSnapshotSubxidCount() * sizeof(TransactionId));
...
}
//获取procarray,需要共享lwlock锁
LWLockAcquire(ProcArrayLock, LW_SHARED);
/* xmax=最大完成xid+1 */
xmax = ShmemVariableCache->latestCompletedXid;
Assert(TransactionIdIsNormal(xmax));
TransactionIdAdvance(xmax); //xmax+1
/* xmax的值已经取出,xmin需要检索pgproc、pgxact、procarray */
/* 先把globalxmin、xmin赋值xmax,如果判断backend没有事务信息,就比较好办了 */
globalxmin = xmin = xmax;
//恢复快照单独处理
snapshot->takenDuringRecovery = RecoveryInProgress();
//非恢复快照需要到backend中获取事务信息
if (!snapshot->takenDuringRecovery)
{
int *pgprocnos = arrayP->pgprocnos;
int numProcs;
/*
* Spin over procArray checking xid, xmin, and subxids. The goal is
* to gather all active xids, find the lowest xmin, and try to record
* subxids.看上去在检索procarray的时候会spin,以收集所有活跃的xid,最小的xmin,子事务subxid
*/
numProcs = arrayP->numProcs;
for (index = 0; index < numProcs; index++)
{
int pgprocno = pgprocnos[index]; //通过循环numProcs进程个数,取pgprocno全部下标
PGXACT *pgxact = &allPgXact[pgprocno]; //通过pgprocno遍历所有pgxact结构体
TransactionId xid;
...
/* Update globalxmin to be the smallest valid xmin */
xid = UINT32_ACCESS_ONCE(pgxact->xmin);
if (TransactionIdIsNormal(xid) &&
NormalTransactionIdPrecedes(xid, globalxmin))
globalxmin = xid;
/* Fetch xid just once - see GetNewTransactionId */
xid = UINT32_ACCESS_ONCE(pgxact->xid);
...
/* 把backend中的xmin保存到快照xip中 */
/* 也就是说通过便利所有pgxact以找到所有活跃的xid */
snapshot->xip[count++] = xid;
...
/* 子事务信息处理 */
if (!suboverflowed) //如果子事务没有溢出
{
if (pgxact->overflowed)
suboverflowed = true; //如果事务溢出,将子事务也标记为溢出
else
{
int nxids = pgxact->nxids;
if (nxids > 0)
{
PGPROC *proc = &allProcs[pgprocno];
pg_read_barrier(); /* pairs with GetNewTransactionId */
memcpy(snapshot->subxip + subcount,
(void *) proc->subxids.xids,
nxids * sizeof(TransactionId));
subcount += nxids;
}
}
}
}
}
else //这里的else对应if (!snapshot->takenDuringRecovery)
{
// 这里的判断都是standby的,当实例是hot standby模式,从库中有查询事务时
subcount = KnownAssignedXidsGetAndSetXmin(snapshot->subxip, &xmin,
xmax);
if (TransactionIdPrecedesOrEquals(xmin, procArray->lastOverflowedXid))
suboverflowed = true;
}
//事物槽的xmin和catalog全集群xmin,先保存到本地变量
//事物槽xmin是为了防止元组被回收
//注释中说明是为了不长时间持有ProcArrayLock,才保存到本地变量
replication_slot_xmin = procArray->replication_slot_xmin;
replication_slot_catalog_xmin = procArray->replication_slot_catalog_xmin;
//从backend中获取事务信息的工作已经完成,下面是一堆if判断,收尾工作并增加代码严谨性
if (!TransactionIdIsValid(MyPgXact->xmin))
MyPgXact->xmin = TransactionXmin = xmin;
LWLockRelease(ProcArrayLock); //释放ProcArrayLock
if (TransactionIdPrecedes(xmin, globalxmin))
globalxmin = xmin; //globalxmin和进程xmin,globalxmin赋值更小的那个
RecentGlobalXmin = globalxmin - vacuum_defer_cleanup_age;
if (!TransactionIdIsNormal(RecentGlobalXmin))
RecentGlobalXmin = FirstNormalTransactionId; //特殊情况下,如果RecentGlobalXmin<=2,赋值3
/* Check whether there's a replication slot requiring an older xmin. */
if (TransactionIdIsValid(replication_slot_xmin) &&
NormalTransactionIdPrecedes(replication_slot_xmin, RecentGlobalXmin))
RecentGlobalXmin = replication_slot_xmin;
/* Non-catalog tables can be vacuumed if older than this xid */
RecentGlobalDataXmin = RecentGlobalXmin;
//再次检查和对比catalog,globalxminn
if (TransactionIdIsNormal(replication_slot_catalog_xmin) &&
NormalTransactionIdPrecedes(replication_slot_catalog_xmin, RecentGlobalXmin))
RecentGlobalXmin = replication_slot_catalog_xmin;
RecentXmin = xmin;
//开始给snapshot结构体赋值,返回快照数据
snapshot->xmin = xmin;
snapshot->xmax = xmax;
snapshot->xcnt = count;
snapshot->subxcnt = subcount;
snapshot->suboverflowed = suboverflowed;
snapshot->curcid = GetCurrentCommandId(false);
//如果是一个新快照,初始化一些快照信息
snapshot->active_count = 0;
snapshot->regd_count = 0;
snapshot->copied = false;
//下面是快照过久时的判断,居然写在这
if (old_snapshot_threshold < 0)
{
/*
* If not using "snapshot too old" feature, fill related fields with
* dummy values that don't require any locking.
*/
//如果没有使用old_snapshot_threshold参数(参数<0,不会出现snapshot too old的问题)
//赋一些简单的值,都是常量,不会产生任何锁
snapshot->lsn = InvalidXLogRecPtr;
snapshot->whenTaken = 0;
}
else
{
//当old_snapshot_threshold参数>=0时,需要完成old snapshot的逻辑
snapshot->lsn = GetXLogInsertRecPtr(); //获得lsn
snapshot->whenTaken = GetSnapshotCurrentTimestamp(); //获得快照时间
MaintainOldSnapshotTimeMapping(snapshot->whenTaken, xmin); //
//GetXLogInsertRecPtr(),GetSnapshotCurrentTimestamp() ,MaintainOldSnapshotTimeMapping()三个函数中有 //SpinLockAcquire和SpinLockRelease
//MaintainOldSnapshotTimeMapping()函数还有LWLockAcquire和LWLockRelease
//因为每次快照都要调用,获取快照数据函数应该是很频繁的
//所以能看出来pg13源码中,如果将old_snapshot_threshold设置为负数,spinlock和lwlock会少很多
}
return snapshot;
}pg14对事务的优化#
pg14事务优化源码分析#
pg13的源码能看出来GetSnapshotData()中写死了old_snapshot_threshold>=0时,每次获得快照数据都会产生较多的SpinLock和LWLock,而获得快照对于数据库来说是非常频繁的操作,这必定导致一些性能问题。所以pg14中直接把old_snapshot_threshold部分删除了···
除了删除GetSnapshotData()中的old_snapshot_threshold逻辑,还做了很多其他优化:
移除
RecentGlobalXmin,RecentGlobalDataXmin,新增GlobalVisTest*系列函数新增边界boundaries概念,有两个边界分别为definitely_needed,maybe_needed
struct GlobalVisState { /* XIDs >= are considered running by some backend */ // >=definitely_needed的行一定可见 FullTransactionId definitely_needed; /* XIDs < are not considered to be running by any backend */ // <maybe_needed的行一定可以清理 FullTransactionId maybe_needed; };新增
ComputeXidHorizons()用于进一步精准计算horizons(保存xmin和removable xid信息),该函数仍需要遍历PGPROC。计算的范围当然是在XID >= maybe_needed && XID < definitely_needed新增
GlobalVisTestShouldUpdate()用于判断是否需要再次计算边界先了解一个变量
ComputeXidHorizonsResultLastXminstatic TransactionId ComputeXidHorizonsResultLastXmin; //最后一次精准计算的xmin GlobalVisTestShouldUpdate(GlobalVisState *state) { //如果xmin=0,需要重新计算边界。相当于给初始化数据库产生的元组设置一个例外判断 if (!TransactionIdIsValid(ComputeXidHorizonsResultLastXmin)) return true; /* * If the maybe_needed/definitely_needed boundaries are the same, it's * unlikely to be beneficial to refresh boundaries. */ //maybe_needed等于definitely_needed不需要再计算了 //不过不是用的等于,而是maybe_needed>=definitely_needed //“大于”的场景是没有行一定可见,“等于”的场景是只有一行一定可见 if (FullTransactionIdFollowsOrEquals(state->maybe_needed, state->definitely_needed)) return false; /* does the last snapshot built have a different xmin? */ //当最后一次快照snapshot->xmin=最后一次精准计算的xmin时,不再重新计算边界 return RecentXmin != ComputeXidHorizonsResultLastXmin; }
可以看出maybe_needed和definitely_needed跟快照xmin、xmax是相似的,多嵌套了1层计算。先计算boundaries,再进一步精确计算horizons。GlobalVisTestShouldUpdate减少了计算boundaries的场景,而ComputeXidHorizons()精准计算也更高效。
优化结果#
推荐一篇pg快照优化的文章:
对比优化前后的效果相当明显:
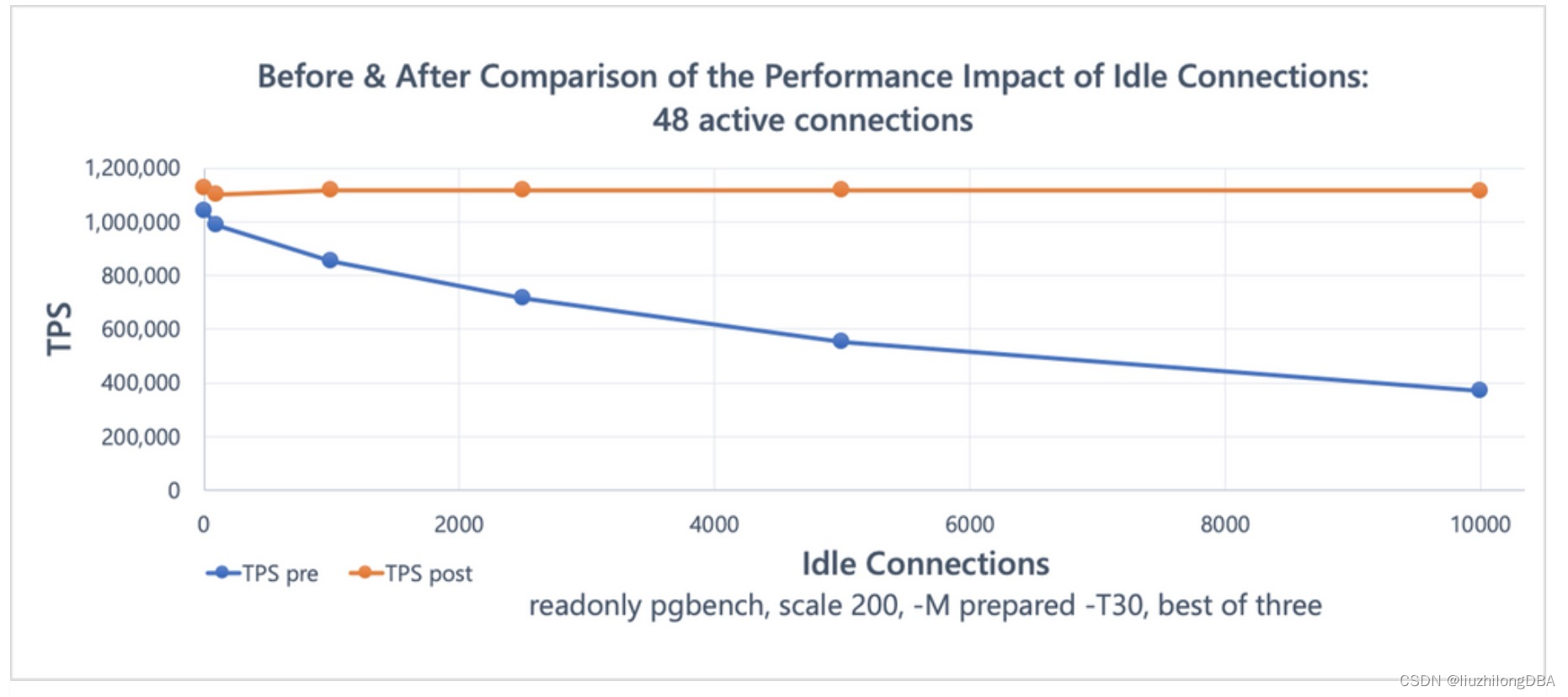
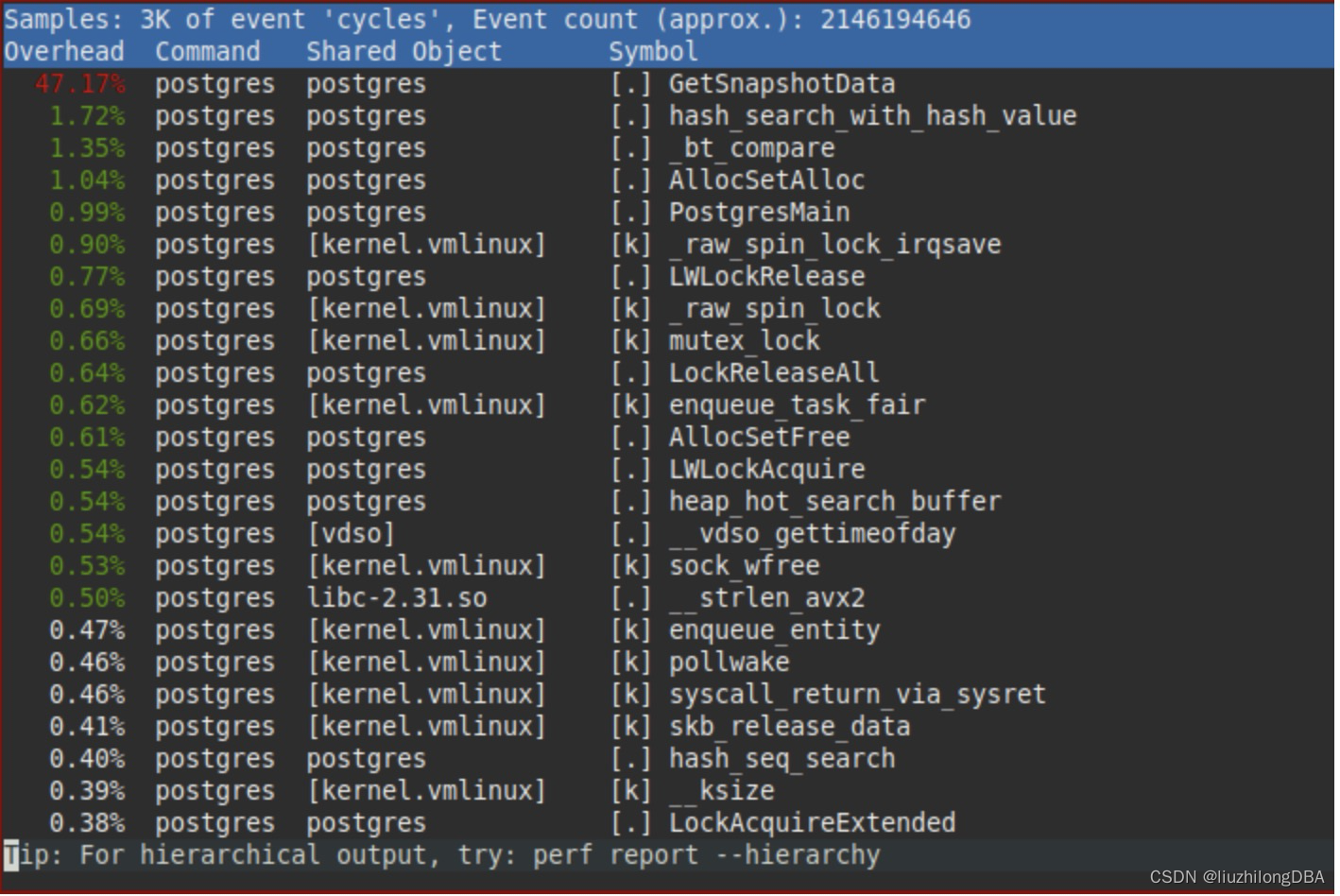
其实在pg13的生产上也能看到GetSnapshotData的性能消耗总是很高。不过没截图,再借用下大佬的图
reference#
books: 《postgresql指南 内幕探索》 《postgresql实战》 《postgresql技术内幕 事务处理深度探索》 《postgresql数据库内核分析》 https://edu.postgrespro.com/postgresql_internals-14_parts1-2_en.pdf 官方资料: https://en.wikipedia.org/wiki/Concurrency_control https://wiki.postgresql.org/wiki/Hint_Bits https://www.postgresql.org/docs/current/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND https://www.postgresql.org/docs/10/storage-page-layout.html https://www.postgresql.org/docs/13/pageinspect.html3 pg事务必读文章 interdb https://www.interdb.jp/pg/pgsql05.html https://www.interdb.jp/pg/pgsql06.html 源码大佬 https://blog.csdn.net/Hehuyi_In/article/details/102920988 https://blog.csdn.net/Hehuyi_In/article/details/127955762 https://blog.csdn.net/Hehuyi_In/article/details/125023923 pg的快照优化性能对比 https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/improving-postgres-connection-scalability-snapshots/ba-p/1806462 其他资料 https://brandur.org/postgres-atomicity https://mp.weixin.qq.com/s/j-8uRuZDRf4mHIQR_ZKIEg
可见性检查#
快照有了,就可以通过快照数据去判断元组的可见性。回顾一下(先不考虑子事务),事务的关键信息:元组头部事务信息、快照信息、clog事务状态(SetHintBits前需要)
- 元组上有元组xmin、xmax、cmin、cmax、infomask等
- 快照数据中有快照xmin、xmax、xip_list、curcid等
- clog中额外的事务状态信息,也可能写入了infomask中的hintbits
快照类型不同,可见性判断略有区别
bool
HeapTupleSatisfiesVisibility(HeapTuple tup, Snapshot snapshot, Buffer buffer)
{
switch (snapshot->snapshot_type)
{
case SNAPSHOT_MVCC:
return HeapTupleSatisfiesMVCC(tup, snapshot, buffer);
break;
...
case SNAPSHOT_NON_VACUUMABLE:
return HeapTupleSatisfiesNonVacuumable(tup, snapshot, buffer);
break;
}
...
}每种快照都有各自的可见性规则,这里用最常见的SNAPSHOT_MVCC快照可见性规则来理解元组可见性
static bool
HeapTupleSatisfiesMVCC(HeapTuple htup, Snapshot snapshot,
Buffer buffer)
{
HeapTupleHeader tuple = htup->t_data;
Assert(ItemPointerIsValid(&htup->t_self)); //lp有效,也就是元组有效
Assert(htup->t_tableOid != InvalidOid); //oid有效,也就是表还有效
//t_xmin未提交,insert或update新元组的事务,未提交
//在htup_details.h中已经宏定过,HeapTupleHeaderXminCommitted()是((tup)->t_infomask & HEAP_XMIN_COMMITTED) != 0
//也就是说if (!HeapTupleHeaderXminCommitted(tuple)) 表示元组infomask中没有HEAP_XMIN_COMMITTED
//其实就是字面含义,t_xmin没有提交
if (!HeapTupleHeaderXminCommitted(tuple))
{
//假如有个事务更新了元组,但是回退或者失败了,那么这个元组的xmin就是失败的事务ID
//如果是失败事务的t_xmin,则直接返回不可见
if (HeapTupleHeaderXminInvalid(tuple))
return false;
//当元组infomask有HEAP_MOVED_OFF标记时,vacuum元组单独判断可见性,并对于vacuum事务做一些hintbits标记
/* Used by pre-9.0 binary upgrades */
if (tuple->t_infomask & HEAP_MOVED_OFF)
{
TransactionId xvac = HeapTupleHeaderGetXvac(tuple);
if (TransactionIdIsCurrentTransactionId(xvac))
return false;
if (!XidInMVCCSnapshot(xvac, snapshot))
{
if (TransactionIdDidCommit(xvac))
{
SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,
InvalidTransactionId);
return false;
}
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
InvalidTransactionId);
}
}
//当元组infomask有HEAP_MOVED_IN标记时,vacuum元组单独判断可见性,并对于vacuum事务做一些hintbits标记
/* Used by pre-9.0 binary upgrades */
else if (tuple->t_infomask & HEAP_MOVED_IN)
{
TransactionId xvac = HeapTupleHeaderGetXvac(tuple);
if (!TransactionIdIsCurrentTransactionId(xvac))
{
if (XidInMVCCSnapshot(xvac, snapshot))
return false;
if (TransactionIdDidCommit(xvac))
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
InvalidTransactionId);
else
{
SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,
InvalidTransactionId);
return false;
}
}
}
//当元组是本事务写入的
else if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmin(tuple)))
{
if (HeapTupleHeaderGetCmin(tuple) >= snapshot->curcid) //当元组cid>=快照事务当前commandid时
return false; // 说明插入元组的时间晚于可见性检测开始时间,元组不可见
if (tuple->t_infomask & HEAP_XMAX_INVALID) //当元组infomask位有HEAP_XMAX_INVALID时
return true; //说明元组没有被删除(delete),元组可见
//因为仅插入元组,不提交、提交或者回退,都是HEAP_XMAX_INVALID
//但是这个判断在“本事物写入”条件下,所以这里的逻辑是
//本事务新增元组,未提交(逻辑上等价于同一事务中元组未被删除),且t_cid<curcid,元组可见
//xmax在两种情况被设置:1对元组加锁,元组被删除
//即使元组没有HEAP_XMAX_INVALID,可能也不是被删除,也可能是元组加锁了
//元组加锁情况下设置了xmax,元组可见
if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask)) /* not deleter */
return true;
// HEAP_XMAX_IS_MULTI是对多个事务获取同一行锁时,才会产生MultiXactId
// 这里仍然是在判断xmax加锁情况下的可见性
if (tuple->t_infomask & HEAP_XMAX_IS_MULTI)
{
TransactionId xmax;
xmax = HeapTupleGetUpdateXid(tuple);
/* not LOCKED_ONLY, so it has to have an xmax */
Assert(TransactionIdIsValid(xmax));
/* updating subtransaction must have aborted */
//如果xmax不是当前事务,则可见
if (!TransactionIdIsCurrentTransactionId(xmax))
return true;
//如果xmax是当前事务,通过commandid判断,在更新和删除操作之前获得快照,在获得快照时间元组是可见的
else if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* updated after scan started */
else
return false; /* updated before scan started */
}
//以下判断场景是:子事务中的删除命令回退了,需要SetHintBits为HEAP_XMAX_INVALID
//删除命令回退了,所以元组是可见的
if (!TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmax(tuple)))
{
/* deleting subtransaction must have aborted */
SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,
InvalidTransactionId);
return true;
}
//cmax删除元组的cid
//如果元组cmax>=快照curcid,则删除发生在快照扫描之后,元组可见
//如果元组cmax<快照curcid,则删除发生在快照扫描之前,元组不可见
if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* deleted after scan started */
else
return false; /* deleted before scan started */
}
//XidInMVCCSnapshot()判断xid在快照生成时是in-progress状态
//in-progress是 1.快照xmin<=xid<快照xmax且xid in xip_list 2.xid>=快照xmax
//以下XidInMVCCSnapshot()中的xid是t_xmin
//所以,这个判断的含义是:如果t_xmin在快照生成时是in-progress状态,则元组不可见
//相当于t_xmin没有提交,所以元组不可见。这看上去有点奇怪
//因为整个判断是在!HeapTupleHeaderXminCommitted(tuple)下的,含义也是t_xmin没有提交,判断有些重复
//但是加上前面的几个小判断,这的else if就变得合理,其含义为:
//t_xmin没有提交,且元组没有被删除,且不是当前事务,则元组不可见
else if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmin(tuple), snapshot))
return false;
//如果t_xmin事务提交了,做个SetHintBits为HEAP_XMIN_COMMITTED
//这里看上去有点奇怪,整个判断是t_xmin未提交的情况下,不应该出现t_xmin提交了
//而且,真的有这种情况的话,为什么这里不做事务可见性判断?
else if (TransactionIdDidCommit(HeapTupleHeaderGetRawXmin(tuple)))
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
HeapTupleHeaderGetRawXmin(tuple));
//如果t_xmin事务没有提交,做个SetHintBits为HEAP_XMIN_INVALID
else
{
/* it must have aborted or crashed */
SetHintBits(tuple, buffer, HEAP_XMIN_INVALID,
InvalidTransactionId);
//t_xmin事务没有提交,再次返回不可见。看上去跟上面的关于XidInMVCCSnapshot()的条件很像
//当前即没有提交,又不满足XidInMVCCSnapshot()(xid在快照生成时不是in-progress)
//只有生成快照时事务未开始,后来事务开始了,目前没有提交,元组不可见
return false;
}
}
//xmin未提交的情况下的事务可见性总算判断完了
//这里的else以后都是xmin提交的情况下,对元组可见性的判断
//xmin已提交的判断是hintbits位有HEAP_XMIN_COMMITTED
else
{
//xmin已提交,但是不是当前快照做的
/* xmin is committed, but maybe not according to our snapshot */
//当infomask没有HEAP_XMIN_FROZEN且在快照生成时xmin in-progress状态,则元组不可见
//整合翻译一下,这里的if含义为快照生成时xmin未提交,在可见性判断时,元组xmin提交但没有标记FROZEN的情况,元组不可见
//即使元组xmin已提交了,对当前快照而言仍然是in-progress
if (!HeapTupleHeaderXminFrozen(tuple) &&
XidInMVCCSnapshot(HeapTupleHeaderGetRawXmin(tuple), snapshot))
return false; /* treat as still in progress */
}
//HEAP_XMAX_INVALID表示元组没有被删除
//这里的if含义是:当前元组提交了且在快照生成时也提交了且没有被删除(完全没有删除标记),元组可见
if (tuple->t_infomask & HEAP_XMAX_INVALID) /* xid invalid or aborted */
return true;
//虽然元组上有xmax,但不是删除事务,而是锁标记
//这里的if含义是:当前元组提交了且在快照生成时也提交了且有xmax,但xmax是锁标记,元组可见
if (HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask))
return true;
//HEAP_XMAX_IS_MULTI表示元组处于shared-row-lock,一般表示多个事务处理一行时行所拥有的infomask标记
if (tuple->t_infomask & HEAP_XMAX_IS_MULTI)
{
TransactionId xmax;
/* already checked above */
Assert(!HEAP_XMAX_IS_LOCKED_ONLY(tuple->t_infomask));
//获取更新元组的事务id
xmax = HeapTupleGetUpdateXid(tuple);
/* not LOCKED_ONLY, so it has to have an xmax */
Assert(TransactionIdIsValid(xmax));
//如果shared-row-lock元组的事务ID是当前事务
if (TransactionIdIsCurrentTransactionId(xmax))
{
//元组cmax>=快照curcid时,元组在快照生成时还没有被删除,元组可见
if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* deleted after scan started */
//元组cmax<快照curcid时,元组在快照生成时还已被删除,元组可见
else
return false; /* deleted before scan started */
}
//如果shared-row-lock元组的事务ID不是当前事务,且在快照生成时xmax处于in-progress状态
//这里的if含义是:xmin提交,且元组未被删除,有MULTI XMAX标记的情况下,xmax在快照生成时还未提交,元组可见
if (XidInMVCCSnapshot(xmax, snapshot))
return true;
//如果shared-row-lock元组事务已提交,则元组不可见
if (TransactionIdDidCommit(xmax))
return false; /* updating transaction committed */
/* it must have aborted or crashed */
//更新元组异常终止或回滚,元组仍可见
return true;
}
//元组xmin已提交,xmax还没有提交标记,还没有被删除
//看来!HEAP_XMAX_COMMITTED和HEAP_XMAX_INVALID还是有点区别
//这里的判断看上去像元组经历过删除,但删除事务没有提交
//而上面的HEAP_XMAX_INVALID是完全确认没有删除元组或删除abort or rollback,所以可以直接判断为true
if (!(tuple->t_infomask & HEAP_XMAX_COMMITTED))
{
//如果xmax与校验事务是同一事物
if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmax(tuple)))
{
//还是老一套通过commandid检测可见性
//cmax>=快照curcid,说明删除在快照生成之后,元组可见
if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* deleted after scan started */
//cmax<快照curcid,说明删除在快照生成之前,元组不可见
else
return false; /* deleted before scan started */
}
//删除事务没有提交,且xmax与校验事务不是同一事物
//xmax在生成快照时是in-progress的,则元组可见
if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmax(tuple), snapshot))
return true;
//确认xmax删除事务回退或失败,SetHintBits为HEAP_XMAX_INVALID
//类似上面的HEAP_XMAX_INVALID,元组可见
if (!TransactionIdDidCommit(HeapTupleHeaderGetRawXmax(tuple)))
{
/* it must have aborted or crashed */
SetHintBits(tuple, buffer, HEAP_XMAX_INVALID,
InvalidTransactionId);
return true;
}
/* xmax transaction committed */
//还剩下xmax删除事务已提交的场景,SetHintBits为HEAP_XMAX_COMMITTED
//按道理这里应该判断可见性,但是没有写在这,而是在代码的最后几行。因为这里的小条件属于大条件之一
SetHintBits(tuple, buffer, HEAP_XMAX_COMMITTED,
HeapTupleHeaderGetRawXmax(tuple));
}
else
{
/* xmax is committed, but maybe not according to our snapshot */
//xmax删除事务当前已提交,但是在快照生成时in-progress,则元组可见
if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmax(tuple), snapshot))
return true; /* treat as still in progress */
}
/* xmax transaction committed */
//只剩下xmax已提交的,且不在快照生成时in-progress的情况,元组不可见
return false;
}整个可见性判断的源码看上去有点复杂。把SetHintBits部分刨去,省略繁杂的if,只看关键性的可见性规则,其中的关键点如下:
可见性规则的主干逻辑
- 删除已提交,元组不可见
- 插入已提交,删除回滚,元组可见
- 插入已提交,删除未提交,本事务需要对比cid,其他事务对元组可见
- 插入回滚,元组不可见
- 插入未提交,同事务需要对比cmin,其他事务对元组不可见
可见性检查中有两个时间点,一个是检查发生时间,一个是快照生成时间。判断逻辑就有同一个事务(检查事务和快照生成事务为同一事务)和不同事务(检查事务和快照生成事务为2个不同的事务)的情况
如果是同一事务,通过对比元组cmin/cmax和snapshot->curcid的大小
cmin>=snapshot->curcid,说明插入元组的事务晚于快照获取时间,此时元组不可见。反之元组可见
cmax>=snapshot->curcid,说明删除元组的事务晚于快照获取时间,此时元组可见。反之元组不可见
如果不是同一事务,通过XidInMVCCSnapshot()函数判断xid(t_xmin或t_xmax)是否在快照生成时in-progress
xmin在快照生成时in-progress,则元组不可见
xmax在快照生成时in-progress,则元组可见
除了基本的dml操作,还需要完善其他条件下的判断,有如下4种情况:
vacuum事务删除和新增的元组可见性判断
HEAP_XMAX_IS_LOCKED_ONLY锁标记时元组可见
HEAP_XMAX_IS_MULTI元组处于multixact状态时的可见性判断
元组有frozen标记时的可见性判断
multixact#
什么是multixact?#
在对同一行加锁时,元组上关联的事务ID可能有多个,pg将多个事务ID组合起来用一个MultiXactID来管理。TransactionId和MultiXactID是多对一的关系

multixactID跟TransactionId一样,也是32位,同样有wraparound
MultiXactId的0、1都是系统使用,可分配的MultiXactId从2开始
源码src/include/access/multixact.h
#define InvalidMultiXactId ((MultiXactId) 0)
#define FirstMultiXactId ((MultiXactId) 1)
#define MaxMultiXactId ((MultiXactId) 0xFFFFFFFF)行锁的类型#
只有行上有锁时,才会有multixact。MultiXact总共定义了6种状态
typedef enum
{
MultiXactStatusForKeyShare = 0x00,
MultiXactStatusForShare = 0x01,
MultiXactStatusForNoKeyUpdate = 0x02,
MultiXactStatusForUpdate = 0x03,
/* an update that doesn't touch "key" columns */
MultiXactStatusNoKeyUpdate = 0x04,
/* other updates, and delete */
MultiXactStatusUpdate = 0x05
} MultiXactStatus;其中能显示声明的行锁的状态有4种:ForKeyShare,ForShare,ForNoKeyUpdate,ForUpdate
multixact的infomask标记#
pg会将行锁标记到xmax上并记录到infomask中
源码src/include/access/htup_details.h
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */这里重点模拟HEAP_XMAX_IS_MULTI标记,只有多个事务对同一行持有共享锁时才真正产生multixact id,才会有此标记
lzldb=# insert into lzl1 values(1); --初始只有1行数据
INSERT 0 1
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+----------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 742 | 0 | 0 | {HEAP_HASNULL,HEAP_XMAX_INVALID} | {}
(1 row)| 窗口1 | 窗口2 |
|---|---|
| lzldb=# begin; BEGIN lzldb=*# select * from lzl1 for share; a — 1 | |
| lzldb=# begin; BEGIN lzldb=*# select * from lzl1 for share; a — 1 | |
| lzldb=*# update lzl1 set a=2; –hang | |
| commit; | |
| UPDATE 1 –update更新完成 |
--查看元组xmax、infomask情况
lzldb=*# select t_ctid,lp,t_xmin,t_xmax,(t_infomask&4096)!=0 is_multixact from heap_page_items(get_raw_page('lzl1',0));
t_ctid | lp | t_xmin | t_xmax | is_multixact
--------+----+--------+--------+--------------
(0,2) | 1 | 742 | 4 | t
(0,2) | 2 | 744 | 3 | tHEAP_XMAX_IS_MULTI的16进制值是1000,转换为10进制为4096,通过(t_infomask&4096)!=0 is_multixact可以看出元组是否使用了multixact id。从上面的例子可以看出:
- multxact id不同于transaction id,它有自己的取值空间
- multixact id一般来说比transaction id小,所以这里t_xmax比t_xmin更小
- 如果是一个update语句更新的元组,那么新旧元组的xmax肯定是相等的。但是在multixact的场景下,可能就不一样了。
multixact slru#
虽然src/backend/access/transam/multixact.c的开头定义很多变量和函数,有page,member,membergoup,offset,但是总体都是定义变量值,然后定义这些变量进行相互转化的函数
读懂multixact.c前需要先了解几个宏定义
src/include/c.h中定义MultiXactOffset是32位的类型
typedef uint32 MultiXactOffset;src/include/access/slru.h中定义每个段有多少SLRU PAGES
#define SLRU_PAGES_PER_SEGMENT 32回到src/backend/access/transam/multixact.c的开头
define MULTIXACT_OFFSETS_PER_PAGE (BLCKSZ / sizeof(MultiXactOffset))
//MULTIXACT_OFFSETS_PER_PAGE=8k/32B=2048 一个page可以存储2048个offsets标识位,其实也是2048个MULTIXACTID
#define MultiXactIdToOffsetPage(xid) \
((xid) / (MultiXactOffset) MULTIXACT_OFFSETS_PER_PAGE)
//通过xid转换为对应记录的位于的页面:xid/2048
#define MultiXactIdToOffsetEntry(xid) \
((xid) % (MultiXactOffset) MULTIXACT_OFFSETS_PER_PAGE)
//通过xid转换为对应记录位于页面的偏移量:xid%2048
#define MultiXactIdToOffsetSegment(xid) (MultiXactIdToOffsetPage(xid) / SLRU_PAGES_PER_SEGMENT)
//通过xid转换为对应记录位于的segment:xid/2048/32
再看下源码开头的注释
/*
* Defines for MultiXactOffset page sizes. A page is the same BLCKSZ as is
* used everywhere else in Postgres.
*
* Note: because MultiXactOffsets are 32 bits and wrap around at 0xFFFFFFFF,
* MultiXact page numbering also wraps around at
* 0xFFFFFFFF/MULTIXACT_OFFSETS_PER_PAGE, and segment numbering at
* 0xFFFFFFFF/MULTIXACT_OFFSETS_PER_PAGE/SLRU_PAGES_PER_SEGMENT. We need
* take no explicit notice of that fact in this module, except when comparing
* segment and page numbers in TruncateMultiXact (see
* MultiXactOffsetPagePrecedes).
*/因为MultiXactOffsets是32位且有wraparound,所以
MultiXact页编号回卷于0xFFFFFFFF/MULTIXACT_OFFSETS_PER_PAGE=2^32^/2048=2^21
段编号回卷于0xFFFFFFFF/MULTIXACT_OFFSETS_PER_PAGE/SLRU_PAGES_PER_SEGMENT=2^32^/2^11/^2^5^=2^16
TruncateMultiXact()会清理这些段包括页编号,TruncateMultiXact()被vacuum调用
pg_multixact目录#
同CLOG,SUBTRANS日志一样,multixact日志SLRU缓冲池实现。pg_multixact目录下只有两个目录member,offset
[pg@lzl pg_multixact]$ ll
total 8
drwx------ 2 pg pg 4096 Feb 14 21:29 members
drwx------ 2 pg pg 4096 Feb 14 21:29 offsets一个mutixactid有对应多个transaction id,也就是member。offset是每个multiact的起始位置
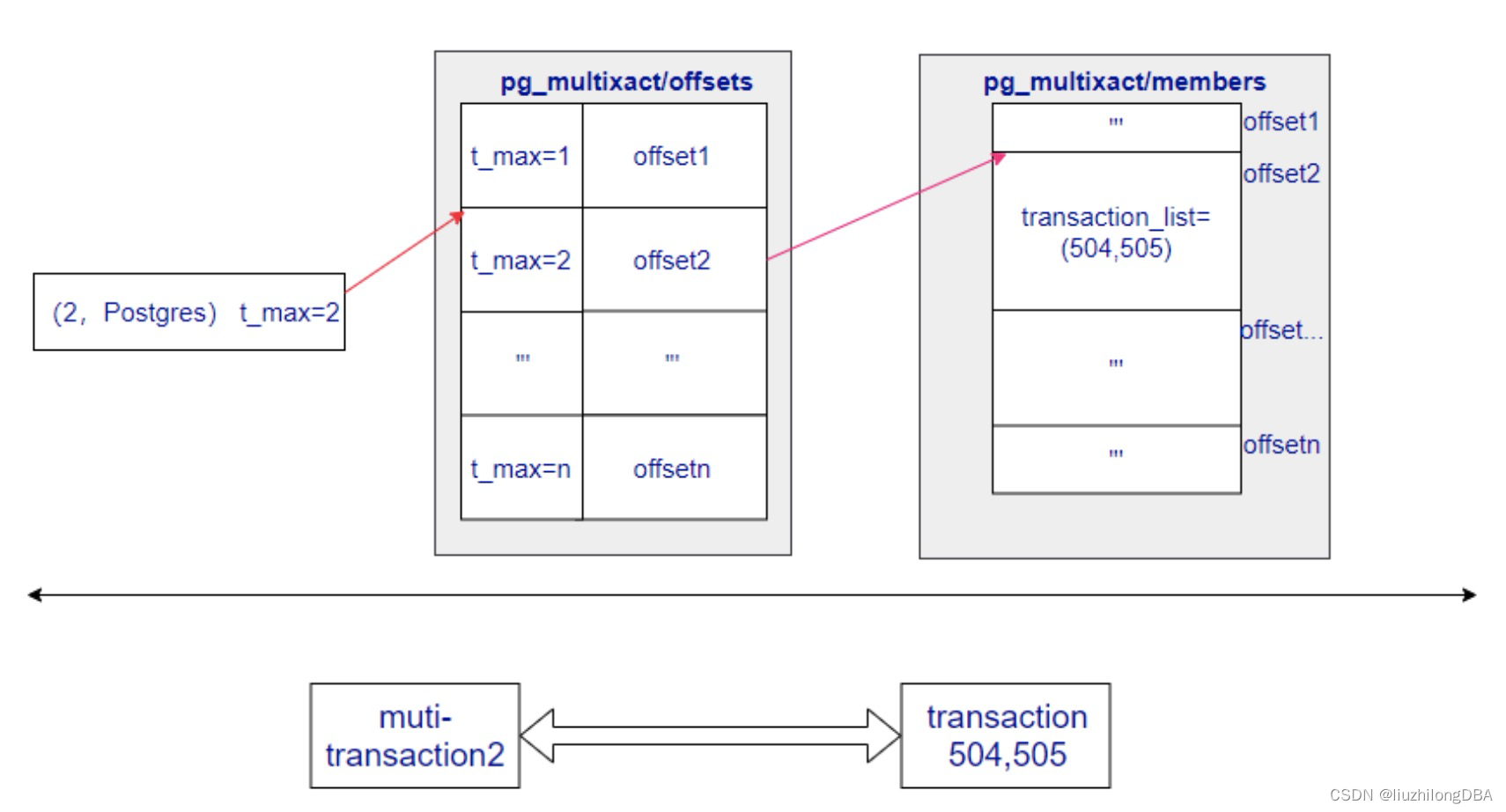
typedef struct mXactCacheEnt
{
MultiXactId multi; //一个MultiXactId
int nmembers;
dlist_node node;
MultiXactMember members[FLEXIBLE_ARRAY_MEMBER]; //多个TransactionId,如果需要,pg用MultiXactIdExpand()扩展member
} mXactCacheEnt;multixact.h中定义了MultiXactMember只是单个事务id和事务状态
typedef struct MultiXactMember
{
TransactionId xid;
MultiXactStatus status;
} MultiXactMember;multixact参考#
https://www.postgresql.org/docs/current/routine-vacuuming.html
https://pgpedia.info/m/multixact-id.html
https://www.postgresql.org/docs/15/explicit-locking.html
https://www.highgo.ca/2020/06/12/transactions-in-postgresql-and-their-mechanism/
2PC事务#
什么是2PC事务?#
事务原子性要求事务必须整体完成或者回滚。在多个联接的数据库等情况下的分布式事务中,必须为事务提供一致性状态,以满足分布式事务的原子性。与其他数据库一样,pg库也提供了 two-phase commit protocol(2PC)两阶段提交协议。
分布式事务实现方案很多,2PC是其中最基础也是最常见的。分布式事务包括原子提交、原子可见性、全局一致性,2PC只是原子提交的实现方案。
prepare transaction#
FDW可以自己处理2PC事务,pg也提供了显示使用2PC事务的方法prepare transaction。prepare transaction发起后,就不会与会话有任何关联,它状态会被保存下来。prepare transaction并不是设计为在应用或者交互式会话中使用,除非你在编写一个事务管理器,所以推荐(默认)关闭的。
语法:
PREPARE TRANSACTION transaction_id
COMMIT PREPARED transaction_id
ROLLBACK PREPARED transaction_id注意:
- 这的transaction_id不是内部事务id,只是一个声明的字符串
- PREPARE TRANSACTION 必须在事务块中,事务块以BEGIN|START STRANSATION开始
- max_prepared_transactions控制prepare事务数,默认为0关闭,需要打开才能使用prepare事务
开启一个prepare事务#
lzldb=# begin;
BEGIN
lzldb=*# PREPARE TRANSACTION 'lzl';
PREPARE TRANSACTION
lzldb=# select * from pg_prepared_xacts ;
transaction | gid | prepared | owner | database
-------------+-----+-------------------------------+-------+----------
719 | lzl | 2023-04-29 16:08:45.866022+08 | pg | lzldb
(1 row)
lzldb=# rollback prepared 'lzl';
ROLLBACK PREPARED
lzldb=# select * from pg_prepared_xacts ;
transaction | gid | prepared | owner | database
-------------+-----+----------+-------+----------
(0 rows)pg_twophase目录#
前面说过,prepare事务与会话无关,当开启一个prepare事务后,事务状态信息保存在缓存中。
为了保证事务不丢失,prepare事务也会落盘,到pg_twophase目录。
其实并不是关库才会导致prepare事务落盘,而是checkpoint
源码src/backend/access/transam/twophase.c
void
CheckPointTwoPhase(XLogRecPtr redo_horizon)
{
...
TRACE_POSTGRESQL_TWOPHASE_CHECKPOINT_START(); //checkpoint开始
...
fsync_fname(TWOPHASE_DIR, true); //调用fsync落盘
TRACE_POSTGRESQL_TWOPHASE_CHECKPOINT_DONE();//checkpoint完成
...
}于是尝试开启一个prepare事务并做checkpoint
[pg@lzl pg_twophase]$ ll
total 0
lzldb=*# PREPARE TRANSACTION 'lzl';
PREPARE TRANSACTION
lzldb=# checkpoint;
CHECKPOINT
[pg@lzl pg_twophase]$ ll
total 4
-rw------- 1 pg pg 116 Apr 29 16:33 000002D0orphaned prepared transactions#
如果一个prepared事务没有完成(prepared事务不提交或回滚),而prepared事务又与会话无关,如果不显示结束这个事务的话,prepared事务仍然存在(会话断开后一般事务会回退),这就是orphaned prepared transactions。
orphaned prepared transactions会一直持有一些锁、元组的资源,导致vacuum无法回收和清理死元组,甚至阻止事务ID回卷。比如一个prepared事务忘记提交或者回滚了,如果没有外部事务管理机制来监控,这个parepared事务将可能不被发现并永远存在,最终导致严重的问题。所以建议max_prepared_transactions=0(默认)或者通过pg_prepared_xacts视图监控prepared事务
下面模拟一个孤儿prepared事务无限期阻塞的情况
--开启一个prepared事务并断开会话
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# PREPARE TRANSACTION 'lzl';
PREPARE TRANSACTION
lzldb=# \q
--会话断开prepared事务仍然存在
postgres=# select * from pg_prepared_xacts ;
transaction | gid | prepared | owner | database
-------------+-----+-------------------------------+-------+----------
721 | lzl | 2023-04-29 17:08:59.597678+08 | pg | lzldb
--ddl 阻塞
lzldb=# alter table lzl1 add column b int;
--查看锁的情况
lzldb=# select locktype,relation,pid,mode from pg_locks where relation=32808;
locktype | relation | pid | mode
----------+----------+-------+---------------------
relation | 32808 | 26136 | AccessExclusiveLock
relation | 32808 | | RowExclusiveLock
--结束prepared事务,ddl执行完成
lzldb=# rollback prepared 'lzl';
ROLLBACK PREPARED
lzldb=# alter table lzl1 add column b int;
ALTER TABLE2PC事务参考#
http://postgres.cn/docs/13/sql-prepare-transaction.html
https://www.highgo.ca/2020/01/28/understanding-prepared-transactions-and-handling-the-orphans/
https://wiki.postgresql.org/wiki/Atomic_Commit_of_Distributed_Transactions
子事务#
什么是子事务?#
一般事务只能整体提交或回滚,而子事务允许部分事务回滚。
SAVEPOINT p1 在事务里面打上保存点标记。不能直接提交子事务,子事务也是通过事务的提交而提交。不过可以通过ROLLBACK TO SAVEPOINT p1回滚到该保存点。
子事务在大批量数据写入的时候很有用。如果事务中存在多个子事务,而其中一小段子事务失败,只需要重做这小部分数据就行,而不需要整个事务数据全部重做。
子事务在SQL语句中的使用#
SAVEPOINT savepoint_name
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
RELEASE [ SAVEPOINT ] savepoint_name注意:
- savepoints语句必须在事务块中
- savepoint执行保存点;rollback回滚到指定保存点;release擦除保存点,不会回滚子事务数据
- cursor不会被savepoint事务影响
sql中的子事务示例:
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(0);
INSERT 0 1
lzldb=*# savepoint p1;
SAVEPOINT
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# savepoint p2;
SAVEPOINT
lzldb=*# insert into lzl1 values(2);
INSERT 0 1
lzldb=*# savepoint p3;
SAVEPOINT
lzldb=*# insert into lzl1 values(3);
INSERT 0 1
lzldb=*# rollback to savepoint p2;
ROLLBACK
lzldb=*# commit;
COMMIT
lzldb=# select xmin,xmax,cmin,a from lzl1;
xmin | xmax | cmin | a
------+------+------+---
731 | 0 | 0 | 0
732 | 0 | 1 | 1
(2 rows)
--回滚到p2时,p3也被回滚
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+------------------------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 731 | 0 | 0 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 732 | 0 | 1 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
(0,3) | 3 | LP_NORMAL | 733 | 0 | 2 | {HEAP_HASNULL,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,4) | 4 | LP_NORMAL | 734 | 0 | 3 | {HEAP_HASNULL,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(4 rows)
--子事务infomask跟一般事务区别不大,同一个事务中多个命令通过cid和HEAP_XMIN_INVALID等就可以判断可见性
--子事务产生写入同样会消耗transaction id,而且cid在父事务框架下增加其他场景中产生子事务#
即使不用savepoint,也有其他方法产生子事务
EXCEPTION语句会触发子事务,这在一些工具或架构中常见,也很容易被忽略。每次EXCEPTION都会产生一个子事务。
语法如:BEGIN / EXCEPTION WHEN .. / END
参考:https://fluca1978.github.io/2020/02/05/PLPGSQLExceptions.html
- PL/Python代码引用plpy.subtransaction()
子事务SLRU缓存#
子事务提交日志在pg_xact,父子对应关系在pg_subtrans存储子事务缓存subXID和父XID的映射。当PostgreSQL需要查找subXID时,它会计算这个ID驻留在哪个内存页中,然后在内存页中进行搜索。如果页面不在缓存中,它会驱逐一个页面,并将所需的页面从pg_subtrans加载到内存中。大量的子事务cache miss会消耗系统的IO和cpu。
子事务用的buffer只有32个并在源码中写死
源码src/include/access/subtrans.h
/* Number of SLRU buffers to use for subtrans */
\#define NUM_SUBTRANS_BUFFERS 32buffer默认为8k,xid是32位占4个bytes,所以
SUBTRANS_BUFFER大小为32*8k=256k
SUBTRANS_BUFFER能存储最多32*8k/4=65536个xid

通过transactionid找到子事务的在page中的位置
源码src/backend/access/transam/subtrans.c
/* We need four bytes per xact */
#define SUBTRANS_XACTS_PER_PAGE (BLCKSZ / sizeof(TransactionId))
//每个页面最多存储8k/4bytes=2048个子事务id
#define TransactionIdToPage(xid) ((xid) / (TransactionId) SUBTRANS_XACTS_PER_PAGE)
//通过子事务xid计算page号=xid/2048
#define TransactionIdToEntry(xid) ((xid) % (TransactionId) SUBTRANS_XACTS_PER_PAGE)
//通过子事务xid计算在page中的offset=xid%2048
子事务xid在page中不一定是紧凑的,一个page可能少于2048个子事务id
子事务的危害#
- PGPROC_MAX_CACHED_SUBXIDS溢出
PGPROC_MAX_CACHED_SUBXIDS不是GUI参数,在源码中写死,只能通过改源码修改该参数。
源码src/include/storage/proc.h
/*
*每个backend都有子事务cache上限PGPROC_MAX_CACHED_SUBXIDS。
*我们必须跟踪cache是否溢出(比如,事务至少有一个缓存不了的子事务)
*如果一个cache都没有溢出,我们可以确认没有在pgproc array中xid一定不是一个运行中的事务。
*(没有在任何proc,又没有溢出,说明没有跑)
*如果有溢出,我们必须查看pg_subtrans
*/
#define PGPROC_MAX_CACHED_SUBXIDS 64 /* XXX guessed-at value */
struct XidCache
{
TransactionId xids[PGPROC_MAX_CACHED_SUBXIDS];
};阅读这段源码,得到两个重要信息
- 每个backend都有子事务cache为
PGPROC_MAX_CACHED_SUBXIDS,固定64个子事务 - 超过64个子事务会溢出到
pg_subtrans目录
copy大佬压测:子事务刚好超过64个的时候,性能下降。所以,每个会话的子事务最好不要超过64个
 参考:https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
参考:https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
- 子事务导致multixact异常等待
原文:https://buttondown.email/nelhage/archive/notes-on-some-postgresql-implementation-details/
for update本身是行级排他锁,本身不应该产生multixact id,但在此场景中产生了多个MultiXact等待,导致数据库性能断崖
- LWLock:MultiXactMemberControlLock
- LWLock:MultiXactOffsetControlLock
- LWLock:multixact_member
- LwLock:multixact_offset
后来发现在Django框架中有子事务语句
SELECT [some row] FOR UPDATE;
SAVEPOINT save;
UPDATE [the same row];- 从库性能急剧下降
一个长事务和一个savepoint子事务也可能造成查询库性能断崖
如果读取发生在主库的快照上,则生成的快照包含xmin,xmax,txip事务列表,subxip保存一个在进行的子事务列表。但是,无论是原数组还是快照都不会直接与从库共享,从库从WAL中读取所需的所有数据。
当存在子事务时,一个长事务的运行会使从库性能断崖式下滑
- 生产性能急剧下降
当数据库运行繁忙,又存在较多子事务时,性能可能急剧下降,并伴随子事务的等待事件。这个场景即使每个会话子事务没有超过64,而且不是在从库而是在主库上时,也会发生。
我们发现工具(OGG)中默认是50个子事务,此时我们将工具中的子事务数据量降低到10-20个时,数据库性能得到缓解。
子事务的使用建议
- 除了显示savepoint使用子事务,excetpion、框架、工具中同样会产生子事务
- 如果有从库查询业务,禁止使用子事务。
- 谨慎使用行锁。for update+子事务同样会引起multixactid的问题
- 如果仍有子事务,子事务设置不要超过64个,最好是更低
子事务已经在国内外生产环境造成了非常多问题,有许多案例和问题分析。引用一下“Subtransactions are basically cursed. Rip em out.”
子事务参考#
https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
https://www.cybertec-postgresql.com/en/subtransactions-and-performance-in-postgresql/
https://fluca1978.github.io/2020/02/05/PLPGSQLExceptions.html
https://buttondown.email/nelhage/archive/notes-on-some-postgresql-implementation-details/
reference#
books:
《postgresql指南 内幕探索》
《postgresql实战》
《postgresql技术内幕 事务处理深度探索》
《postgresql数据库内核分析》
https://edu.postgrespro.com/postgresql_internals-14_parts1-2_en.pdf
官方资料:
https://en.wikipedia.org/wiki/Concurrency_control
https://wiki.postgresql.org/wiki/Hint_Bits
https://www.postgresql.org/docs/current/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND
https://www.postgresql.org/docs/10/storage-page-layout.html
https://www.postgresql.org/docs/13/pageinspect.html3
pg事务必读文章 interdb
https://www.interdb.jp/pg/pgsql05.html
https://www.interdb.jp/pg/pgsql06.html
源码大佬
https://blog.csdn.net/Hehuyi_In/article/details/102920988
https://blog.csdn.net/Hehuyi_In/article/details/127955762
https://blog.csdn.net/Hehuyi_In/article/details/125023923
pg的快照优化性能对比
其他资料
https://brandur.org/postgres-atomicity