索引分裂#
索引块快写满时就会发生索引分裂,索引分裂分为两种情况,55和91:
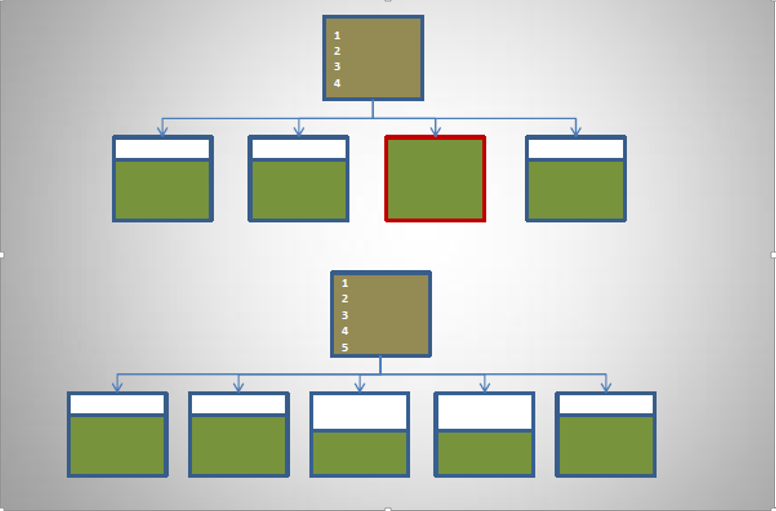
索引分裂和enq: TX - index contension等待事件的区别 无论是55还是91,都是数据增多后索引的正常行为,索引分裂是业务数据量增大导致索引增大的正常现象,索引放不下了自然要更多的索引块来存放数据,基本也没有只有表无索引的情况(在初始化数据的场景下,才会考虑先插入数据,再建索引)。索引分裂虽然有一定的资源消耗,但是在现在的oracle环境中也是可以很快完成的,索引过多的话才会影响插入效率。 而enq: TX - index contension这个等待就不是正常现象了。enq: TX - index contension等待表示SQL在等待正在发生分裂的索引块,本质上是DML并发过大且都在等待分裂的索引块。
为什么enq: TX - index contension总是发生在顺序插入的字段上? 虽然55分裂和91分裂在真实场景都是由可能的,但是enq: TX - index contension等待经常发生在91分裂的情况。因为序列、时间等字段上一般会有索引,并且经常发生顺序插入,此时最后侧的块一直都是热点块,后续的插入一直等待分裂块完成才能插入进去,此时便造成了enq: TX - index contension。UUID上一般也有索引,为什么没有造成enq: TX - index contension等待?因为UUID索引存在无序性,插入导致UUID索引分裂,也很难有后续插入的UUID值刚好也在这个分裂的索引块上。所以UUID是有索引分裂但不会形成enq等待队列从而出现enq: TX - index contension的情况。
解决办法#
注意我们要解决的是索引分裂等待enq: TX - index contension,而不是索引分裂本身。解决办法: 1.反序索引 索引顺序的存放键值,反序索引刚好相反。例如一个'1111 0001’一串数字,正序索引会将它排在'0000 0002’后面;如果是反序索引,它排在'0000 0002’前面。想象一下时间字段,本身是最右热点,反序后秒、分、时排序在前,一个索引块可能包含不同月的同一秒数据,这样最右热点块基本不存在了,反序索引可以将热点打散到索引各个块上。 局限性:需要改造索引;可能无法使用索引范围扫描。顺序增长的字段,无法用到索引范围扫描,例如时间字段。某些场景下的反序键值有可能用到,需要具体分析。 语法:
CREATE INDEX reveridx ON tablzl (name) REVERSE;2.hash分区索引 在普通表上创建hash分区索引,相当于表不变、把索引分区,这样最右的热点块打撒到各个分区上。比如建立一个8分区的hash分区索引,将索引分成8个segment,最右热点有8个,减缓了索引分裂问题 局限性:需要改造索引;会影响索引范围查询的性能,需要抉择插入热点和查询效率问题。 等值和IN可以高效使用hash分区索引,官方文档原文:
Queries involving equality and
INpredicates on index partitioning key can efficiently use global hash partitioned index to answer queries quickly
但是范围查找的效率会下降,分区越多下降越多(分区越多热点缓解越明显),这显然是一个平衡选择性问题。经测试,分区8个,范围查找逻辑读提升也接近8倍。分区后在每个分区内索引仍然是有序的,聚簇因子差别不大,扫描索引的代价差别不大,但是回表的代价加大。如果普通索引一个块内有8条数据指向1个数据块,会造成1次逻辑读,hash后分别存放在8个分区,每个分区1个索引块,会造成8次逻辑读。这就是范围扫描索引性能下降的原因。 语法:
CREATE INDEX cust_last_name_ix ON customers (cust_last_name)
GLOBAL PARTITION BY HASH (cust_last_name)
PARTITIONS 4;3.利用分区将索引打散 可以将表分区,创建本地索引从而达到打散最右热点的效果 局限性:分区键不能是索引字段(如果是索引字段就没有意义了);需要改造表;如果有SQL本身有分区字段,不会影响范围扫描的效率
4.降低并发 降低并发是终极武器。索引分裂等待本质就是并发太高了,如果没有几十个以上的并发插入一般都不会有索引分裂等待。
5.修改索引块大小 将索引块存放在16、32K的表空间中。这种情况理论上确实会有用,因为索引能存放的的数据更多了,分裂的情况就更少了。不过需要测试其性能,可能还有其他参数需要调整。
6.删掉索引 删除索引也是一个思路。根据业务情况,如果这个索引不重要可以把索引删掉;或者范围查询大小来做分区表,利用分区进行过滤而不是索引
这些情况为什么没用???#
- 增加ITL事务槽 索引块的事务槽也可能因为高并发而不够用,确实于索引分裂的情况有些相似,但是其等待为enq: TX - allocate ITL entry。如果有这个等待,能分析到是索引块的,就说明索引上有较高的并发,同样可以用反序索引、hash分区索引来缓解问题,也可考虑修改initrans来解决问题。不过这两个等待的根因还是不同的,索引分裂不一定会伴随事务槽问题。
- 调整索引块PCT_FREE PCTFREE表示一个数据块可用空间小于PCTFREE时,该数据块不在被记录在FREELIST中,即不能插入新数据。考虑两种情况:增加PCTFREE和减少PCTFREE。增加PCTFREE只能加剧索引分裂;减少PCTFREE看上去有效果,原理跟调整索引块大小类似,但是真实场景中PCTFREE默认是10%,已经很难再调小了,调整的效果不会很明显。
- 重建索引减少碎片率 这其实没什么关系,它没有解决最右热点块的问题。
参考#
https://blog.csdn.net/lihuarongaini/article/details/101299328 https://docs.oracle.com/cd/E11882_01/server.112/e41573/data_acc.htm#PFGRF94786
鸣谢:豪桑、用哥