走主键的SQL是怎么访问了多个数据页的?#
书接上回 :长事务、表膨胀、limit问题的一个经典案例,这篇文章有一个点没有说的很仔细:
为什么一个走主键的SQL会产生那么多shared hit?
为什么索引膨胀会导致访问多个数据页呢?页内的HOT只要一个数据页访问,页外的数据难道不可以通过访问对应的那一条索引条目来定位?
这跟索引的版本管理有关系了,其实索引还是有一点版本信息的,但不多。先温故一下pg的btree索引结构
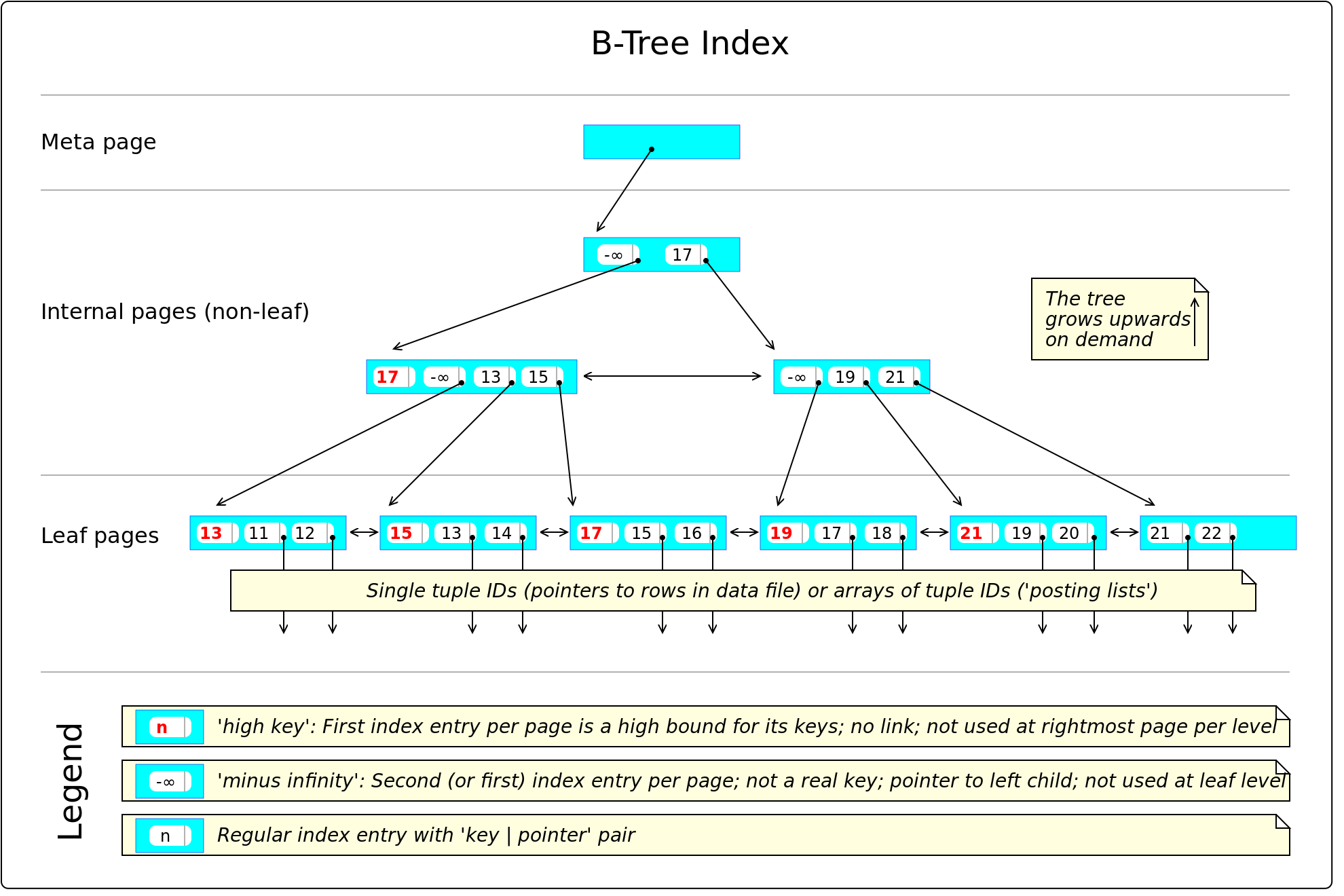 (https://en.wikibooks.org/wiki/PostgreSQL/Index_Btree)
这个pg btree wiki图其实没有解释死元组和死索引条目的访问方式,它没有版本信息。目前不用硬理解这个结构的所有细节,知道有这么个btree结构就行。
(https://en.wikibooks.org/wiki/PostgreSQL/Index_Btree)
这个pg btree wiki图其实没有解释死元组和死索引条目的访问方式,它没有版本信息。目前不用硬理解这个结构的所有细节,知道有这么个btree结构就行。
为了搞清楚btree的版本访问问题,我们来做个测试:
create table tab1(a bigserial,b char(1000));
create index idx_tab1_a on tab1(a);
alter table tab1 set (autovacuum_enabled = off); --关闭autovacuum
alter table tab1 alter column b set storage PLAIN; --关闭toastlzldb=> insert into tab1(b) values('zzzzzzzzz');
INSERT 0 1
--查看数据页上的元组信息
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 111875 | 0 | 0 | {HEAP_HASVARWIDTH,HEAP_XMAX_INVALID} | {}
--查看索引页上索引条目信息(注意索引0号页是meta页,没有数据)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------+---------+-------+------+-------------------------+------+-------+-----------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) | 仅插入一条数据,数据页page 0上只有1个元组,索引页page 1上只有一个条目指向ctid(0,1)
lzldb=> update tab1 set b='xxxxxxx' ;
UPDATE 1
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-------------------------------------------------------------------+----------------
(0,2) | 1 | LP_NORMAL | 111875 | 111876 | 0 | {HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,2) | 2 | LP_NORMAL | 111876 | 0 | 0 | {HEAP_HASVARWIDTH,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
(2 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------+---------+-------+------+-------------------------+------+-------+-----------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) | 更新一条数据,数据页page 0上有2个元组,活着的只有ctid(0,2),lp=1的元组是“死”的了,但是lp_flags还是“NORMAL”的!索引页page 1上只有一个条目指向ctid(0,1),也就是“死”元组。这个就是HOT的原理,块内更新数据时不会更新索引条目,索引通过指向死元组的ctid链去找到真正活着的数据元组。
循环更新10次,造成2个数据页和1个索引页:
DO $$
begin
FOR i IN 1..10 LOOP
update tab1 set b=md5(i::text);
END LOOP;
end $$;;更新后:
--第一个数据页
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flag
s
--------+----+-------------+--------+--------+-------+--------------------------------------------------------------------------------------+--------------
--
| 1 | LP_REDIRECT | | | | |
(0,3) | 2 | LP_NORMAL | 111876 | 111877 | 0 | {HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,4) | 3 | LP_NORMAL | 111877 | 111877 | 0 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,5) | 4 | LP_NORMAL | 111877 | 111877 | 1 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,6) | 5 | LP_NORMAL | 111877 | 111877 | 2 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(0,7) | 6 | LP_NORMAL | 111877 | 111877 | 3 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,1) | 7 | LP_NORMAL | 111877 | 111877 | 4 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
(7 rows)
--第二个数据页
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab1',1)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------------------------------------+----------------
(1,2) | 1 | LP_NORMAL | 111877 | 111877 | 5 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED} | {}
(1,3) | 2 | LP_NORMAL | 111877 | 111877 | 6 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,4) | 3 | LP_NORMAL | 111877 | 111877 | 7 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,5) | 4 | LP_NORMAL | 111877 | 111877 | 8 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED,HEAP_HOT_UPDATED,HEAP_ONLY_TUPLE} | {}
(1,5) | 5 | LP_NORMAL | 111877 | 0 | 9 | {HEAP_HASVARWIDTH,HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}第一个数据页page 0通过LP_REDIRECT的状态可以直接判断当前数据页肯定有HOT,此时的lp1上是没有任何其他任何信息的,甚至连ctid,data、infomask都没有。无法这条lp找到最终的数据,对于索引第一个个条目来说,访问到ctid(0,1)就可以了,这个数据页里面没有想要的数据行。 但是数据页2是有没有LP_REDIRECT的,索引可以通过找到ctid(1,0)的ctid链,找到页内的活元组(1,5)。 源码对line pointer状态的解释:
/*
*lp_flags has these possible states. An UNUSED line pointer is available
*for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* unused (should always have lp_len=0) */
#define LP_NORMAL 1 /* used (should always have lp_len>0) */
#define LP_REDIRECT 2 /* HOT redirect (should have lp_len=0),其实不是HOT,而是页外的redirect标识 */
#define LP_DEAD 3 /* dead, may or may not have storage *///对LP_REDIRECT的解释
Redirecting line pointer
A line pointer that points to another line pointer and has no
associated tuple. It has the special lp_flags state LP_REDIRECT,
and lp_off is the OffsetNumber of the line pointer it links to.
This is used when a root tuple becomes dead but we cannot prune
the line pointer because there are non-dead heap-only tuples
further down the chain.再仔细回看会发现,我们认为的“死”元组的lp状态是LP_NORMAL,而不是LP_DEAD。这个很重要,因为后面还会用到这个知识点。
继续查看索引页:
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------+---------+-------+------+-------------------------+------+-------+-----------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (1,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1,1) | 因为多了一个页,HOT不再适用,此时索引被更新了,索引页只有2个条目,而且都是活的dead=f,均指向各自page的第一个元组:(0,1) 和(1,1)。 页外的更新,索引页也会更新,每个索引条目指向各自的页。请注意,此时表里只有1条数据,索引有2个条目且都是活的,这也是为什么主键扫描会访问多个数据页。
再多更新一些数据,造成索引也是多个页:
DO $$
begin
FOR i IN 1..10000 LOOP
update tab1 set b=md5(i::text);
END LOOP;
end $$;--第一个索引页
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+-------------+---------+-------+------+-------------------------+------+----------+-------------------------
1 | (1278,4097) | 24 | f | f | 01 00 00 00 00 00 00 00 | | (1277,1) |
2 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) | {"(0,1)","(1,1)"}
3 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (222,1) | {"(222,1)","(223,1)"}
4 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (444,1) | {"(444,1)","(445,1)"}
5 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (666,1) | {"(666,1)","(667,1)"}
6 | (16,8414) | 1352 | f | f | 01 00 00 00 00 00 00 00 | f | (888,1) | {"(888,1)","(889,1)"}
--第2个索引页
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',2);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+----------+---------+-------+------+-------------------------+------+----------+-----------
1 | (1278,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1278,1) |
2 | (1279,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1279,1) |
3 | (1280,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1280,1) |
4 | (1281,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1281,1) |
...
152 | (1429,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1429,1) |
153 | (1430,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (1430,1) |
(153 rows)
--第3个索引页
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, data, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab1_a',3);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | some_tids
------------+----------+---------+-------+------+-------------------------+------+----------+-----------
1 | (1,0) | 8 | f | f | | | |
2 | (2,4097) | 24 | f | f | 01 00 00 00 00 00 00 00 | | (1277,1) | 总共3个索引页,page1 是root节点,page 2和page 3是叶节点。他们的索引条目的dead状态都是“f”的
此时再回到sql,用主键索引
lzldb=> explain (analyze,buffers) select * from tab1 where a=1;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tab1 (cost=4.39..56.41 rows=14 width=4012) (actual time=2.594..2.596 rows=1 loops=1)
Recheck Cond: (a = 1)
Heap Blocks: exact=1
Buffers: shared hit=1437 dirtied=1026
-> Bitmap Index Scan on idx_tab1_a (cost=0.00..4.39 rows=14 width=0) (actual time=0.152..0.153 rows=1431 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=6
Planning:
Buffers: shared hit=5
Planning Time: 0.087 ms
Execution Time: 2.614 ms此时用主键查询,shared hit有1437,跟表的page有1430是差不多对得上的。 由于索引没有版本信息,而且索引条目的dead状态没有被更新,所以pg根据所有活的索引条目去数据页中找版本信息。这就是为什么走主键索引的SQL可以很慢。
kill index item#
由于索引没有存储可见性信息(即MVCC版本信息),索引所指向的元组的可见性信息决定了索引可见性本身。这也是为什么pg中的index-only-scan还是会访问数据页。当然有vm的话,vm会保留all-visible和all-frozen的数据页是哪些,此时的index-only-scan不会访问这些数据页,因为他们都可见了。
即便没有vacuum,pg内核仍有处理此类索引膨胀问题的方法——kill index item。这个特性有时候也叫Simple deletion or index deletion(src/backend/access/nbtree/README的叫法),总之是将已经为LP_DEAD的元组所对应的索引条目标记为dead,不改变原有的索引结构。
源码函数_bt_killitems:
* _bt_killitems - set LP_DEAD state for items an indexscan caller has
* told us were killed明确说明是索引扫描触发kill item操作(也就是说select也可能触发这个操作从而更新索引)。这也很好测试。因为之前的数据已经有过索引扫描了,我们重新造数据来测试。
create table tab2(a bigserial,b char(100));
create index idx_tab2_a on tab2(a);
create index idx_tab2_b on tab2(b);
alter table tab2 set (autovacuum_enabled = off); --关闭autovacuum
alter table tab2 alter column b set storage PLAIN; --关闭toast
--插入1条数据并反复更新
insert into tab2(b) values('00000');
DO $$
begin
FOR i IN 1..10000 LOOP
update tab2 set b=i::text;
END LOOP;
end $$;--表的页
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',2)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------------+----------------
(2,2) | 1 | LP_NORMAL | 509 | 509 | 115 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,3) | 2 | LP_NORMAL | 509 | 509 | 116 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,4) | 3 | LP_NORMAL | 509 | 509 | 117 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,5) | 4 | LP_NORMAL | 509 | 509 | 118 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,6) | 5 | LP_NORMAL | 509 | 509 | 119 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,7) | 6 | LP_NORMAL | 509 | 509 | 120 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
(2,8) | 7 | LP_NORMAL | 509 | 509 | 121 | {HEAP_HASVARWIDTH,HEAP_COMBOCID,HEAP_UPDATED} | {}
...
--a索引的页
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+-----------+---------+-------+------+------+---------+-----------------------
1 | (66,4097) | 24 | f | f | | (66,6) |
2 | (16,8414) | 1352 | f | f | f | (44,5) | {"(44,5)","(44,6)"}
3 | (16,8414) | 1352 | f | f | f | (47,53) | {"(47,53)","(47,54)"}
4 | (16,8414) | 1352 | f | f | f | (51,43) | {"(51,43)","(51,44)"}
5 | (16,8414) | 1352 | f | f | f | (55,33) | {"(55,33)","(55,34)"}
6 | (16,8414) | 1352 | f | f | f | (59,23) | {"(59,23)","(59,24)"}
7 | (16,8360) | 1024 | f | f | f | (63,13) | {"(63,13)","(63,14)"}
--b索引的页
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_b',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+---------+---------+-------+------+------+---------+-----------
1 | (57,1) | 112 | f | t | | |
2 | (0,34) | 112 | f | t | f | (0,34) |
3 | (5,41) | 112 | f | t | f | (5,41) |
4 | (56,53) | 112 | f | t | f | (56,53) |
5 | (56,54) | 112 | f | t | f | (56,54) |
6 | (56,55) | 112 | f | t | f | (56,55) |
7 | (56,56) | 112 | f | t | f | (56,56) |
8 | (56,57) | 112 | f | t | f | (56,57) | 此时用全表扫描的方式查一次表,再次查看数据元组和索引条目的状态
lzldb=> explain (analyze,buffers) select * from tab2;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on tab2 (cost=0.00..204.14 rows=3114 width=412) (actual time=1.077..1.079 rows=1 loops=1)
Buffers: shared hit=173 dirtied=173
Planning Time: 0.042 ms
Execution Time: 1.090 ms
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',4)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+----------+--------+--------+-------+-----------+----------------
| 1 | LP_DEAD | | | | |
| 2 | LP_DEAD | | | | |
| 3 | LP_DEAD | | | | |
| 4 | LP_DEAD | | | | |
| 5 | LP_DEAD | | | | |
| 6 | LP_DEAD | | | | |
| 7 | LP_DEAD | | | | |
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+-----------+---------+-------+------+------+---------+-----------------------
1 | (66,4097) | 24 | f | f | | (66,6) |
2 | (16,8414) | 1352 | f | f | f | (44,5) | {"(44,5)","(44,6)"}
3 | (16,8414) | 1352 | f | f | f | (47,53) | {"(47,53)","(47,54)"}
4 | (16,8414) | 1352 | f | f | f | (51,43) | {"(51,43)","(51,44)"}
5 | (16,8414) | 1352 | f | f | f | (55,33) | {"(55,33)","(55,34)"}
6 | (16,8414) | 1352 | f | f | f | (59,23) | {"(59,23)","(59,24)"}
7 | (16,8360) | 1024 | f | f | f | (63,13) | {"(63,13)","(63,14)"}
(7 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_b',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+---------+---------+-------+------+------+---------+-----------
1 | (57,1) | 112 | f | t | | |
2 | (0,34) | 112 | f | t | f | (0,34) |
3 | (5,41) | 112 | f | t | f | (5,41) |
4 | (56,53) | 112 | f | t | f | (56,53) |
5 | (56,54) | 112 | f | t | f | (56,54) |
6 | (56,55) | 112 | f | t | f | (56,55) |
7 | (56,56) | 112 | f | t | f | (56,56) | 数据元组,除了最后一个页其他都被标记为了LP_DEAD。 索引条目,什么都没动。 再用a索引查询一次表
lzldb=> explain (analyze,buffers) select * from tab2 where a=1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Index Scan using idx_tab2_a on tab2 (cost=0.28..68.56 rows=16 width=412) (actual time=1.282..1.510 rows=1 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=190 dirtied=8
Planning Time: 0.058 ms
Execution Time: 1.525 ms
(5 rows)
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+----------+--------+--------+-------+-----------+----------------
| 1 | LP_DEAD | | | | |
| 2 | LP_DEAD | | | | |
| 3 | LP_DEAD | | | | |
| 4 | LP_DEAD | | | | |
| 5 | LP_DEAD | | | | |
| 6 | LP_DEAD | | | | |
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+-----------+---------+-------+------+------+---------+-----------------------
1 | (66,4097) | 24 | f | f | | (66,6) |
2 | (16,8414) | 1352 | f | f | t | (44,5) | {"(44,5)","(44,6)"}
3 | (16,8414) | 1352 | f | f | t | (47,53) | {"(47,53)","(47,54)"}
4 | (16,8414) | 1352 | f | f | t | (51,43) | {"(51,43)","(51,44)"}
5 | (16,8414) | 1352 | f | f | t | (55,33) | {"(55,33)","(55,34)"}
6 | (16,8414) | 1352 | f | f | t | (59,23) | {"(59,23)","(59,24)"}
7 | (16,8360) | 1024 | f | f | t | (63,13) | {"(63,13)","(63,14)"}
(7 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_b',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+---------+---------+-------+------+------+---------+-----------
1 | (57,1) | 112 | f | t | | |
2 | (0,34) | 112 | f | t | f | (0,34) |
3 | (5,41) | 112 | f | t | f | (5,41) |
4 | (56,53) | 112 | f | t | f | (56,53) |
5 | (56,54) | 112 | f | t | f | (56,54) |
6 | (56,55) | 112 | f | t | f | (56,55) |
7 | (56,56) | 112 | f | t | f | (56,56) | 索引a的死元组都被标记为了dead=t,而索引b的死元组还是dead=f,因为我们没有扫描过索引b。 此时再次通过索引a查询表
lzldb=> explain (analyze,buffers) select * from tab2 where a=1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Index Scan using idx_tab2_a on tab2 (cost=0.28..68.56 rows=16 width=412) (actual time=0.020..0.021 rows=1 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=10
Planning Time: 0.059 ms
Execution Time: 0.033 ms因为索引a上的死元组对应的索引条目都被标记为了dead=t,所以不需要再通过数据页上的版本信息来判断元组是不是“活”的。 为什么这里的shared hit=10呢,还是稍微有点多?因为kill index item只会标记死亡的索引条目,不会改变索引结构,索引页数没有减少,这10个shared hit就是10个索引页(包含meta页)。
lzldb=> analyze tab2;
ANALYZE
lzldb=> select relname,relpages,reltuples from pg_class where relname='idx_tab2_a';
relname | relpages | reltuples
------------+----------+-----------
idx_tab2_a | 10 | 1Bottom-Up deletion#
在pg14中,index deletion功能的触发条件有增强。前面已经提到,触发index deletion的条件是扫描索引,pg14中还可以在即将发生索引分裂时,触发index deletion,以找到空闲的索引空间,减少索引分裂的概率。 当然这个特性减少了索引分离,也同样减少了索引膨胀,从而缓解索引膨胀带来的问题。
具体的测试可参考:INDEX BLOAT REDUCED IN POSTGRESQL V14
index deduplication#
pg13引入了index deduplication的特性,它将GIN索引的posting list思想,引入到btree索引中,以减少btree重复索引占用的空间并缓解索引分裂问题。 原本btree索引条目只指向一个ctid(就像我们前面测试看到的那样),有了deduplicate index item,一个索引条目可以有一个posting list,一个posting list可以存放多个ctid。
The representation of posting lists is almost identical to the posting lists used by GIN
like GIN posting tree(list)(*btree的posting list不一定是这个结构,待研究):
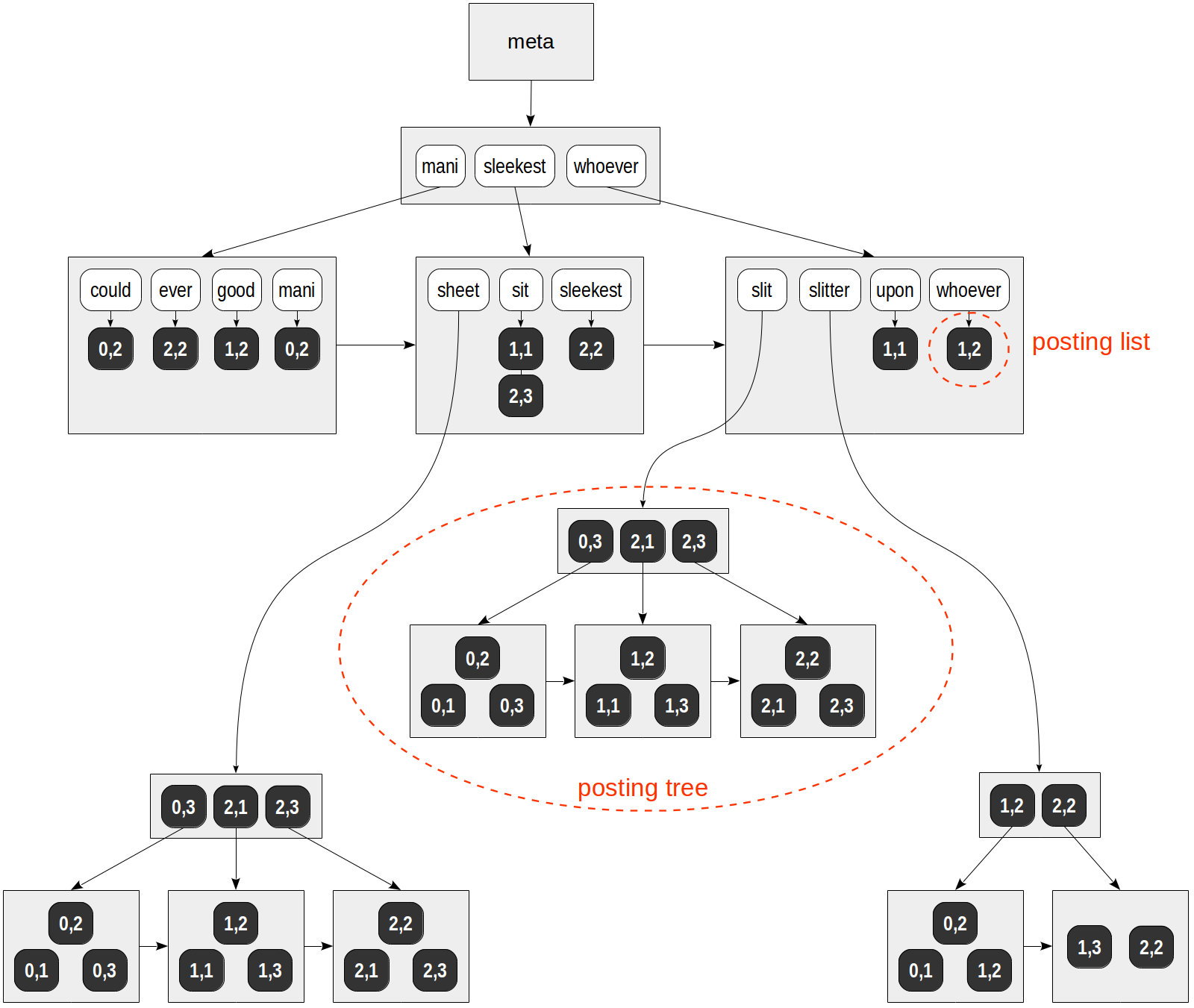 (https://postgrespro.com/blog/pgsql/4261647)
(https://postgrespro.com/blog/pgsql/4261647)
对index deduplication的测试:
create table tab3(same char(100),diff char(100));
create index idx_tab3_same on tab3(same);
create index idx_tab3_diff on tab3(diff);
insert into tab3 select 10000::text,i::text from generate_series(10000, 99999) as i;lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab3_same',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+------------+---------+-------+------+------+----------+-----------------------
1 | (104,4097) | 120 | f | t | | (104,10) |
2 | (112,8398) | 1352 | f | t | f | (69,19) | {"(69,19)","(69,20)"}
3 | (112,8398) | 1352 | f | t | f | (75,21) | {"(75,21)","(75,22)"}
4 | (112,8398) | 1352 | f | t | f | (81,23) | {"(81,23)","(81,24)"}
5 | (112,8398) | 1352 | f | t | f | (87,25) | {"(87,25)","(87,26)"}
6 | (112,8398) | 1352 | f | t | f | (93,27) | {"(93,27)","(93,28)"}
7 | (112,8344) | 1024 | f | t | f | (99,29) | {"(99,29)","(99,30)"}
(7 rows)
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab3_diff',4);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+--------+---------+-------+------+------+--------+-----------
1 | (5,1) | 112 | f | t | | |
2 | (3,23) | 112 | f | t | f | (3,23) |
3 | (3,24) | 112 | f | t | f | (3,24) |
...
62 | (5,15) | 112 | f | t | f | (5,15) |
63 | (5,16) | 112 | f | t | f | (5,16) |
(63 rows) bt_page_items函数里面的tids列其实就是posting list。上面的same字段插入的是同一个相同的数据,索引产生了deduplication;diff字段没有相同的数据,没有产生deduplication。 他们各自所占用的空间差异是非常大的:
lzldb=> select relname,relpages,reltuples from pg_class where relname like 'idx_tab3%';
relname | relpages | reltuples
---------------+----------+-----------
idx_tab3_diff | 1484 | 90000
idx_tab3_same | 81 | 90000唯一索引会产生deduplication吗?#
唯一索引没有重复数据,看上去是不会,实际上是会的。因为即便是唯一索引,在HOT满足不了更新的时候,就会产生多个索引条目。这个测试我们从本文的第一个测试用例就可以看出来。update反复更新一条记录,也会产生deduplication,它产生在delete index item之前。 另外,delete index item在删除posting list索引时,需要确保posting list下的所有ctids所对应的元组都是DEAD的。
关闭deduplication#
index deduplication是pg13引入的。该功能默认开启,可以在索引级别关闭该功能。修改索引的deduplicate_items不会直接改动现有的索引结构,只会影响新插入的数据。
alter index idx_tab3_same set (deduplicate_items=off);
create index idx_tab3_same1 on tab3(same) with (deduplicate_items=off);vacuum做了什么?#
vacuum做的事情挺多的,这里只关注表、索引膨胀和空间回收,回卷等事情就不看了。
拿刚才反复更新一条数据的tab2表来测试,已经触发过simple deletion,表和索引条目几乎都是DEAD。 直接执行vacuum
lzldb=# vacuum verbose tab2;
INFO: vacuuming "public.tab2"
INFO: scanned index "idx_tab2_a" to remove 10000 row versions
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: scanned index "idx_tab2_b" to remove 10000 row versions
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: "tab2": removed 10000 row versions in 173 pages
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: index "idx_tab2_a" now contains 1 row versions in 10 pages
DETAIL: 10000 index row versions were removed.
7 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: index "idx_tab2_b" now contains 1 row versions in 276 pages
DETAIL: 10000 index row versions were removed.
269 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: "tab2": found 24 removable, 1 nonremovable row versions in 173 out of 173 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 526
There were 0 unused item identifiers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUMidx_tab2_a索引在10个page中remove了 10000个行版本,7个index pages被delete tab2表在173个page中remove了10000个行版本。
--表的第一页
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------+----------------
| 1 | LP_UNUSED | | | | |
| 2 | LP_UNUSED | | | | |
...
| 45 | LP_UNUSED | | | | |
--表的最后一页
lzldb=> select t_ctid,lp,case lp_flags when 0 then 'LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('tab2',172)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
----------+----+-----------+--------+--------+-------+-----------------------------------------------------------------------+----------------
| 1 | LP_UNUSED | | | | |
| 2 | LP_UNUSED | | | | |
...
| 23 | LP_UNUSED | | | | |
| 24 | LP_UNUSED | | | | |
(172,25) | 25 | LP_NORMAL | 509 | 0 | 9999 | {HEAP_HASVARWIDTH,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID,HEAP_UPDATED} | {}
--索引的第一页
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',1);
NOTICE: page is deleted
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+----------------+---------+-------+------+------+------+-----------
1 | (4294967295,0) | 8 | f | f | | |
(1 row)
--索引的最后一页
lzldb=> SELECT itemoffset, ctid, itemlen, nulls, vars, dead, htid, tids[0:2] AS some_tids FROM bt_page_items('idx_tab2_a',9);
itemoffset | ctid | itemlen | nulls | vars | dead | htid | some_tids
------------+----------+---------+-------+------+------+----------+-----------
1 | (172,25) | 16 | f | f | f | (172,25) | 表的死元组所在的lp全部被标记为UNUSED,数据被清理,只剩下一条活元组在表中为NORMAL状态,表的pages还是那么多。 索引的死元组(dead=t)的全部被清理,索引活元组在索引页内被移位了(最后一页的索引元组原本的itemoffset<>1),所有被清空的索引页被标记为deleted,这些deleted的索引页其实还在,为半死状态——half dead。 nbtree README中对Deleting entire pages during VACUUM的解释(原文比较长,摘了比较重要的出来):
We consider deleting an entire page from the btree only when it’s become completely empty of items. Page deletion always begins from an empty leaf page. An internal page can only be deleted as part of deleting an entire subtree.
只有当索引页完全为空的时候才会考虑delete entire page。deleting总是从页节点开始,non-leaf节点只有在删除整个子树时才会被删除。
Deleting a leaf page is a two-stage process.
In the first stage, the page is unlinked from its parent, and marked as half-dead. In the second-stage, the half-dead leaf page is unlinked from its siblings. We first lock the left sibling (if any) of the target, the target page itself, and its right sibling (there must be one) in that order. Then we update the side-links in the siblings, and mark the target page deleted.
删除页节点有2个阶段:
- 从父节点unlink,此时的页节点为half-dead状态
- 从左右兄弟节点unlink,此时的叶节点为deleted状态
A deleted page cannot be recycled immediately, since there may be other processes waiting to reference it (ie, search processes that just left the parent, or scans moving right or left from one of the siblings). These processes must be able to observe a deleted page for some time after the deletion operation, in order to be able to at least recover from it (they recover by moving right, as with concurrent page splits). Searchers never have to worry about concurrent page recycling.
因为其他进程可能还在使用deleted page,vacuum不能立即回收这些索引页。
这段描述跟我们看到的现象是一致的 虽然vacuum后,索引的pages还是那么多:
relname | relpages | reltuples
------------+----------+-----------
idx_tab2_a | 10 | 1
tab2 | 173 | 1但是通过索引扫描已经不需要访问deleted page了:
lzldb=> explain (analyze,buffers) select * from tab2 where a=1; QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Index Scan using idx_tab2_a on tab2 (cost=0.12..8.14 rows=1 width=109) (actual time=0.011..0.012 rows=1 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=2
Planning Time: 0.056 ms
Execution Time: 0.025 msvacuum之前shared hit=10,vacuum后索引page数没有变,还是有10个,其中有8个pages被deleted 但是没有直接recycle,所以shared hit=2。为什么是2也很容易理解,就是“meta page” + “只有一个存活的leaf page”。
Placing deleted pages in the FSM#
Recycling a page is decoupled from page deletion. A deleted page can only be put in the FSM to be recycled once there is no possible scan or search that has a reference to it; until then, it must stay in place with its sibling links undisturbed, as a tombstone that allows concurrent searches to detect and then recover from concurrent deletions (which are rather like concurrent page splits to searchers)
什么是Placing deleted pages in the FSM?在索引页被deleted后,并没有被直接recycle,索引在分裂或新增页时,很难找到被deleted pages重复利用。Placing deleted pages in the FSM便是把这些可回收的页放在索引对应的FSM文件中,方便找到可直接利用的空闲页。 我们前面提到,首次vacuum的时候,哪些deleted pages虽然被unlink了,但是它还是在那里占用着空间,在pg14以前
We implement the technique by waiting until all active snapshots and registered snapshots as of the page deletion are gone
删除的条件之一:所有活动快照和delete pages所涉及的快照必须都必须都结束。所以长事务肯定影响placing。
Placing an already-deleted page in the FSM to be recycled when needed doesn’t actually change the state of the page. The page will be changed whenever it is subsequently taken from the FSM for reuse. The deleted page’s contents will be overwritten by the split operation (it will become the new right sibling page).
此外,把 already-deleted page放到FSM文件中不会改变页的状态,这只是为了快速找到可用空闲页。
Prior to PostgreSQL 14, VACUUM would only place old deleted pages that it encounters during its linear scan (pages deleted by a previous VACUUM operation) in the FSM. Newly deleted pages were never placed in the FSM, because that was assumed to always be unsafe. PostgreSQL 14 added the ability for VACUUM to consider if it’s possible to recycle newly deleted pages at the end of the full index scan where the page deletion took place
在PG14以前,第一次vacuum产生的deleted pages不会被放到FSM,只有“旧”的deleted pages才会被放到FSM文件中。 在PG14之后,第一次vacuum也会考虑将deleted pages放到FSM中。
测试(我的版本是pg13): 上面的tab2测试刚跑了一次vacuum,虽然已经产生了deleted pages,但是索引没有对应的FSM文件:
lzldb=> select * from pg_relation_filepath('idx_tab2_a');
pg_relation_filepath
----------------------
base/16384/16437
[postgres@lzlhost data]$ ll base/16384/16437*
-rw------- 1 postgres postgres 81920 Apr 5 11:04 base/16384/16437此时再跑一次vacuum:
lzldb=> vacuum tab2;
[postgres@lzlhost data]$ ll base/16384/16437*
-rw------- 1 postgres postgres 81920 Apr 5 11:04 base/16384/16437
-rw------- 1 postgres postgres 24576 Apr 5 15:52 base/16384/16437_fsm索引立即产生了fsm文件。
流程图:索引膨胀和清理#
请注意:
- 下图不包含表的fsm、vm信息
- 下图不包含deduplication信息
- 版本为pg13
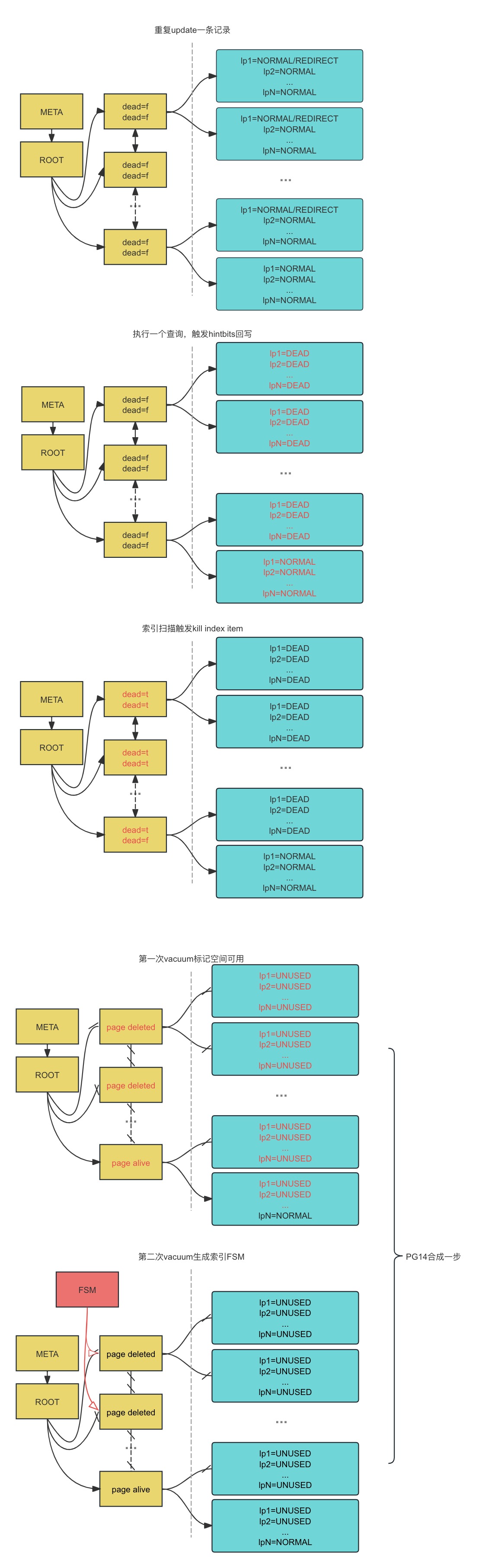
fillfactor#
以上讲了各种pg内核支持的方式以减少索引膨胀,出这些我们基本不需要参与的方式,还可以调整表和索引的fillfactor来控制膨胀问题。
fillfactor相当于表或索引的水位线,在INSERT数据时,插入到page的fillfactor线就到下一页去插入。fillfactor本身是为了给update留一定的空间,防止update频繁的去寻找新的page。
虽然表和索引都有fillfactor,他们的目的是一样的(为了update),但是具体细节有很大区别:
- 表:如果表的某个page上还有留有空间,那么update可以在这个page中进行,不需要申请新的page或者到其他有空闲空间的page上去。不仅如此,因为PG 独有的HOT特性,页内更新不会更新索引,当然也就会减缓索引膨胀
- 索引:不同的数据行或者相同数据行的页外更新,会新生成索引条目。fillfactor给索引页留下余量,会极大的减缓索引分离问题。
当然,fillfactor的设置跟业务模型是息息相关的,如果数据类似日志那样是递增且完全没有更新的,那么表和索引的fillfactor设置成100无可厚非。但是大部分业务表总是有更新的,表和索引fillfactor就不应该设置成100,如果是频繁的update,那么fillfactor应该设置得更低。 然而,pg默认的fillfactor如下:
- 表默认 fillfactor=100
- 索引默认 fillfactor=90
表fillfactor=100完全用不了HOT!只要更新立即寻找新数据页,并在索引的10%里去新增一个索引元组。最后导致update频繁的业务总是在更新索引,此时90的索引也撑不住了,最终导致update频繁造成索引分裂···
以下是对fillfactor的测试,两张表仅fillfactor不一样,更新相同量的数据,看看最终share hit的差异:
create table tab4(a bigserial,b char(100));
create index idx_tab4_a on tab4(a);
alter index idx_tab4_a set (deduplicate_items=off); --关闭索引的deduplication
alter table tab4 alter column b set storage PLAIN; --关闭toast
alter table tab4 set (autovacuum_enabled = off); --关闭autovacuum--tab5跟表tab4定义一样,除了表和索引的fillfactor更新
alter table tab5 set (fillfactor=70);
alter index idx_tab5_a set (fillfactor=80);insert into tab4(b) values('lllllllllll');
--反复更新一条记录
DO $$
begin
FOR i IN 1..10000 LOOP
update tab4 set b=md5(i::text) where a=1;
END LOOP;
end $$;;--默认fillfactor的主键查询
lzldb=> explain (analyze,buffers) select * from tab4 where a=1;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tab4 (cost=4.28..53.88 rows=16 width=412) (actual time=0.894..0.895 rows=1 loops=1)
Recheck Cond: (a = 1)
Heap Blocks: exact=1
Buffers: shared hit=174
-> Bitmap Index Scan on idx_tab4_a (cost=0.00..4.28 rows=16 width=0) (actual time=0.023..0.023 rows=173 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=1
Planning Time: 0.057 ms
Execution Time: 0.913 ms
(9 rows)
--fillfactor调低后的主键查询
lzldb=> explain (analyze,buffers) select * from tab5 where a=1;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tab5 (cost=4.39..56.41 rows=14 width=4012) (actual time=3.367..3.369 rows=1 loops=1)
Recheck Cond: (a = 1)
Heap Blocks: exact=1
Buffers: shared hit=1434
-> Bitmap Index Scan on idx_tab5_a (cost=0.00..4.39 rows=14 width=0) (actual time=0.195..0.195 rows=1429 loops=1)
Index Cond: (a = 1)
Buffers: shared hit=5
Planning Time: 0.059 ms
Execution Time: 3.390 msfillfactor调低后,shared hit的降低是非常明显的,Execution Time也有数倍提升。实际上数据页和索引页都有减少。 所以,在总是update的业务表中,设置调低表和索引的fillfactor可以缓解表膨胀问题。
总结#
虽然索引膨胀总是伴随着表膨胀,但是他们的原理不太一样。HOT不会更新索引元组,页外更新会新增索引元组。 将表和索引的fillfactor参数调低,可以减缓update频繁的业务表的膨胀问题,当然最终也减缓了主键查询等SQL变慢问题。 另外还有一些内核自带的增效索引空间的功能:
- 扫描索引时顺便清理死亡索引元组(index tuple deletion)
- 索引分裂时清理死亡索引元组(Bottom-Up index tuple deletion)
- vacuum标记全是死索引元组的页(Deleting entire pages during VACUUM)
- 快速定位以在索引分离时更快的找到回收的索引页(Placing deleted pages in the FSM)
references#
src/backend/access/nbtree/README https://mp.weixin.qq.com/s/GBN7dFQU72BfzvLSzlLmYA pg事务:事务相关元组结构 https://www.cybertec-postgresql.com/en/killed-index-tuples/ https://www.cybertec-postgresql.com/en/index-bloat-reduced-in-postgresql-v14/?spm=a2c6h.12873639.article-detail.8.2f153438mIV8JK https://www.cybertec-postgresql.com/en/b-tree-index-improvements-in-postgresql-v12/ https://www.cybertec-postgresql.com/en/b-tree-index-deduplication/